


Hammaga salom! Mening ismim Dmitriy Samsonov va men Odnoklassniki’da yetakchi tizim administratori bo‘lib ishlayman. Bizda 7 dan ortiq jismoniy serverlar, bulutda 11 ta konteyner va turli konfiguratsiyalarda 700 ta turli klasterlarni tashkil etuvchi 200 ta ilova mavjud. Serverlarning aksariyati ishlayapti CentOS 7.
2018-yil 14-avgust kuni FragmentSmack zaifligi haqida ma'lumot e'lon qilindi.
() va SegmentSmack (). Bular tarmoq hujumi vektoriga ega va ancha yuqori ball (7.5) bilan zaifliklar bo'lib, resurslarning tugashi (CPU) tufayli xizmat ko'rsatishdan bosh tortish (DoS) xavfini tug'diradi. O'sha paytda FragmentSmack uchun yadro tuzatish taklif qilinmagan edi; aslida, u zaiflik ommaga oshkor qilinganidan keyin sezilarli darajada chiqarildi. SegmentSmackni tuzatish uchun yadro yangilanishi tavsiya qilindi. Yangilanish paketining o'zi o'sha kuni chiqarildi; qolgani uni o'rnatish edi.
Yo'q, biz yadro yangilanishlariga umuman qarshi emasmiz! Biroq, ba'zi nuanslar mavjud...
Ishlab chiqarishda yadroni qanday yangilaymiz
Umuman olganda, murakkab narsa yo'q:
- Paketlarni yuklab oling;
- Ularni bir qator serverlarga (shu jumladan, bizning bulutimizni joylashtirgan serverlarga) o'rnating;
- Hech narsa buzilmaganligiga ishonch hosil qiling;
- Barcha standart yadro sozlamalari xatosiz qo'llanilganligiga ishonch hosil qiling;
- Bir necha kun kuting;
- Server ko'rsatkichlarini tekshiring;
- Yangi serverlarni joylashtirishni yangi yadroga o'tkazish;
- Ma'lumotlar markazlaridagi barcha serverlarni yangilang (muammolar yuzaga kelganda foydalanuvchilarga ta'sirni minimallashtirish uchun bir vaqtning o'zida bitta ma'lumotlar markazi);
- Barcha serverlarni qayta ishga tushiring.
Mavjud yadrolarimizning barcha shoxlari uchun takrorlang. Hozirda bu quyidagicha:
- Stok CentOS 7 3.10 - aksariyat oddiy serverlar uchun;
- Vanil 4.19 - biz uchun , chunki bizga BFQ, BBR va boshqalar kerak;
- Elrepo yadro-ml 5.2 — uchun , chunki 4.19 ilgari beqaror edi, lekin xuddi shu xususiyatlarga ehtiyoj bor.
Siz taxmin qilganingizdek, minglab serverlarni qayta ishga tushirish eng ko'p vaqtni oladi. Barcha zaifliklar barcha serverlar uchun muhim emasligi sababli, biz faqat internetdan to'g'ridan-to'g'ri kirish mumkin bo'lganlarni qayta ishga tushiramiz. Bulutda moslashuvchanlikni saqlab qolish uchun biz tashqi kirish mumkin bo'lgan konteynerlarni yangi yadro ishlaydigan alohida serverlarga qulflamaymiz, balki barcha xostlarni istisnosiz qayta ishga tushiramiz. Yaxshiyamki, bu yerda jarayon oddiy serverlarga qaraganda osonroq. Masalan, holatsiz konteynerlar qayta ishga tushirish paytida boshqa serverga o'tishi mumkin.
Biroq, hali qilinadigan ishlar ko'p va agar yangi versiya bilan bog'liq muammolar yuzaga kelsa, bu bir necha hafta yoki hatto oylar davom etishi mumkin. Hujumchilar buni yaxshi bilishadi, shuning uchun B rejasi zarur.
FragmentSmack/SegmentSmack. Vaqtinchalik yechim
Yaxshiyamki, ba'zi zaifliklar uchun vaqtinchalik yechim deb nomlangan B rejasi mavjud. Ko'pincha, bu potentsial ta'sirni minimallashtirish yoki ekspluatatsiyani butunlay oldini olish uchun yadro yoki dastur sozlamalarini o'zgartirishni o'z ichiga oladi.
FragmentSmack/SegmentSmack holatida bunday vaqtinchalik yechim:
«Siz net.ipv4.ipfrag_high_thresh va net.ipv4.ipfrag_low_thresh (va ularning IPv6 hamkasblari net.ipv6.ipfrag_high_thresh va net.ipv6.ipfrag_low_thresh) da standart 4MB va 3MB qiymatlarini mos ravishda 256 kB va 192 kB yoki undan pastroqqa o'zgartirishingiz mumkin. Sinovlar apparat, sozlamalar va sharoitlarga qarab, hujum paytida protsessordan foydalanishning biroz yoki sezilarli darajada pasayishini ko'rsatmoqda. Biroq, ipfrag_high_thresh=262144 bayt tufayli ishlashga ba'zi ta'sirlar bo'lishi mumkin, chunki bir vaqtning o'zida faqat ikkita 64K fragment qayta yig'ish navbatiga sig'ishi mumkin. Masalan, katta UDP paketlari bilan ishlaydigan ilovalar ishlamay qolish xavfi mavjud.".
Parametrlarning o'zlari quyidagicha tavsiflanadi:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Bizning ishlab chiqarish xizmatlarimizda katta UDP ulanishlari yo'q. LANda parchalangan trafik yo'q va WANda ham bor, lekin bu ahamiyatli emas. Hech narsa noto'g'ri ko'rinmaydi - vaqtinchalik yechim ishga tushirishga tayyor!
FragmentSmack/SegmentSmack. Birinchi qon
Biz duch kelgan birinchi muammo shundaki, bulutli konteynerlar ba'zan yangi sozlamalarni faqat qisman qo'llagan (faqat ipfrag_low_thresh) va ba'zan ularni umuman qo'llamagan, shunchaki ishga tushirishda ishdan chiqqan. Biz muammoni ishonchli tarzda qayta tiklay olmadik (barcha sozlamalarni qo'lda qo'llash oson edi). Konteyner ishga tushirishda nima uchun ishdan chiqqanini tushunish ham oson bo'lmadi: hech qanday xato topilmadi. Bir narsa aniq edi: sozlamalarni orqaga qaytarish konteyner ishdan chiqishi muammosini hal qildi.
Nima uchun faqat Sysctl ni xostda ishlatishning o'zi yetarli emas? Konteyner o'zining maxsus tarmoq nom maydonida yashaydi, shuning uchun hech bo'lmaganda konteynerdagi ma'lumotlar xostdan farq qilishi mumkin.
Sysctl sozlamalari konteynerda qanday qo'llaniladi? Bizning konteynerlarimiz imtiyozsiz bo'lgani uchun, konteyner ichidan biron bir Sysctl sozlamalarini o'zgartirish imkonsiz - bizda shunchaki kerakli ruxsatnomalar yo'q. O'sha paytda bizning bulutimiz konteynerlarni ishga tushirish uchun Dockerdan foydalangan (hozir ). Yangi konteyner parametrlari, jumladan, kerakli Sysctl sozlamalari, API orqali Dockerga uzatildi.
Turli versiyalarni sinab ko'rgandan so'ng, Docker API barcha xatolarni qaytarmayotgani ma'lum bo'ldi (hech bo'lmaganda 1.10 versiyasida). Konteynerni "docker run" yordamida ishga tushirishga harakat qilganimizda, nihoyat bir narsani ko'rdik:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Parametr qiymati noto'g'ri. Lekin nima uchun? Va nima uchun u faqat ba'zan noto'g'ri? Ma'lum bo'lishicha, Docker Sysctl parametrlari qo'llanilish tartibini kafolatlamaydi (oxirgi tasdiqlangan versiya 1.13.1), shuning uchun ba'zida ipfrag_high_thresh uni 256K ga o'rnatishga harakat qiladi, ipfrag_low_thresh esa hali ham 3M edi. Bu yuqori chegara pastki chegaradan pastroq ekanligini anglatardi, bu esa xatoga sabab bo'ldi.
O'sha paytda bizda konteynerni ishga tushirgandan keyin qayta sozlash uchun o'z mexanizmimiz bor edi (konteynerni muzlatish) va konteyner nom maydonida buyruqlarni bajarish orqali ), va biz ushbu bo'limga Sysctl parametrlarini belgilash imkoniyatini ham qo'shdik. Muammo hal qilindi.
FragmentSmack/SegmentSmack. Birinchi qon 2
Foydalanuvchilardan dastlabki shikoyatlarni qabul qila boshlaganimizda, bulutda vaqtinchalik yechimni joriy etish bilan deyarli tanishib bo'lmadik. O'sha paytda, vaqtinchalik yechim birinchi serverlarda joylashtirilganidan beri bir necha hafta o'tdi. Dastlabki tekshiruv shuni ko'rsatdiki, shikoyatlar ushbu xizmatlardagi barcha serverlardan emas, balki ma'lum xizmatlardan kelayotgan edi. Muammo yana juda noaniq bo'lib qoldi.
Avvalo, biz Sysctl sozlamalarini orqaga qaytarishga harakat qildik, ammo bu hech qanday natija bermadi. Server va dastur sozlamalarini turli xil manipulyatsiya qilish ham yordam bermadi. Qayta ishga tushirish yordam berdi. Qayta ishga tushirish uchun Linux bilan ishlash uchun odatiy holat bo'lgani kabi, g'ayritabiiy ham edi Windows Qadimgi kunlarda. Lekin u ish berardi va biz yangi Sysctl sozlamalarini qo'llashda buni "yadrodagi nosozlik" deb atardik. Biz qanchalik ahmoqmiz...
Uch hafta o'tgach, muammo yana takrorlandi. Ushbu serverlarning konfiguratsiyasi juda oddiy edi: Nginx proksi/balansator rejimida. Trafik kam edi. Yangi ma'lumotlar: mijozlardagi 504 ta xato soni kun sayin ortib borardi.Grafikda ushbu xizmat uchun kuniga 504 ta xatolik soni ko'rsatilgan:
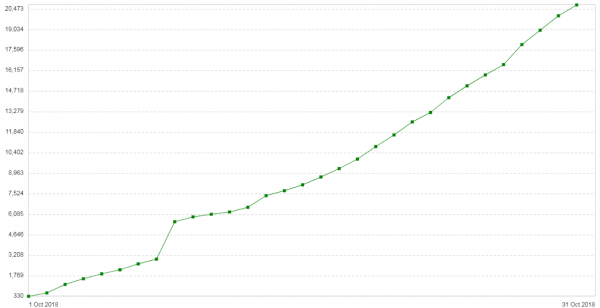
Barcha xatolar bir xil orqa qism bilan bog'liq edi - bulutda joylashgan. Ushbu orqa qismdagi paket fragmentlari uchun xotira sarfi grafigi quyidagicha ko'rinardi:
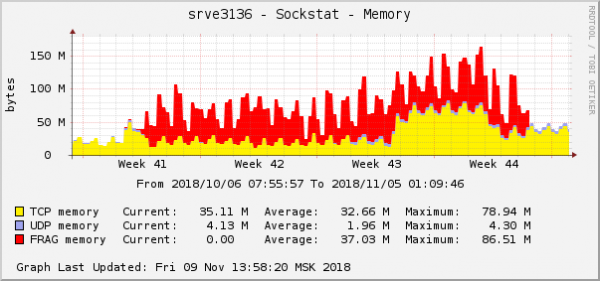
Bu operatsion tizim grafiklaridagi muammoning eng aniq ko'rinishlaridan biridir. Bulutda QoS (Trafikni boshqarish) sozlamalari bilan bog'liq yana bir tarmoq muammosi bir vaqtning o'zida hal qilindi. Bu paket fragmenti xotirasi iste'moli grafigida aynan shunday ko'rinardi:
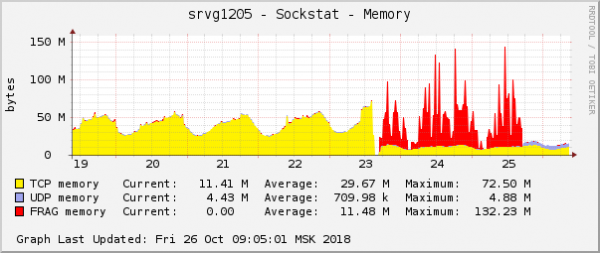
Taxmin oddiy edi: agar ular grafiklarda bir xil ko'rinsa, demak, ularning sababi bir xil. Bundan tashqari, bu turdagi xotira bilan bog'liq muammolar juda kam uchraydi.
Biz hal qilgan muammo shundaki, biz QoS uchun fq paket rejalashtiruvchisidan standart sozlamalar bilan foydalanayotgan edik. Odatiy bo'lib, u har bir ulanish uchun 100 ta paketni navbatga qo'yishga imkon beradi va ba'zi ulanishlar o'tkazish qobiliyati past bo'lganda navbatni to'ldirishni boshlaydi. Bu holda, paketlar o'chirib tashlanadi. Buni tc statistikasida ko'rish mumkin (tc -s qdisc):
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
"464545 flows_plimit" bitta ulanish uchun navbat chegarasidan oshib ketganligi sababli tushib ketgan paketlarni anglatadi va "464545 tushib ketdi" bu rejalashtiruvchi uchun barcha tushib ketgan paketlarning yig'indisidir. Navbat uzunligini 1 ga oshirib, konteynerlarni qayta ishga tushirgandan so'ng, muammo yo'qoldi. Endi orqaga o'tirib, smuzi ichish vaqti keldi.
FragmentSmack/SegmentSmack. Oxirgi qon
Birinchidan, yadro zaifliklari e'lon qilinganidan bir necha oy o'tgach, FragmentSmack uchun tuzatish nihoyat chiqarildi (esingizda bo'lsin, avgust oyida e'lon qilinganida faqat SegmentSmack uchun tuzatish chiqarilgan edi), bu bizga Workovernmentdan voz kechish imkoniyatini berdi, bu bizga ancha muammolar tug'dirdi. Biz bu vaqt ichida ba'zi serverlarni yangi yadroga ko'chirgan edik va endi noldan boshlashimiz kerak edi. Nima uchun FragmentSmack tuzatishini kutmasdan yadroni yangiladik? Gap shundaki, bu zaifliklardan himoya qilish jarayoni Workovernmentning o'zini yangilash jarayoni bilan bir vaqtga to'g'ri keldi (va birlashdi). CentOS (bu faqat yadroni yangilashdan ham ko'proq vaqt talab etadi). Bundan tashqari, SegmentSmack xavfliroq zaiflik bo'lib, uni tuzatish darhol mavjud edi, shuning uchun baribir mantiqan to'g'ri keldi. Biroq, shunchaki yadroni yangilash CentOS davomida paydo bo'lgan FragmentSmack zaifligi tufayli biz buni qila olmadik CentOS 7.5 versiyasi faqat 7.6 versiyasida tuzatildi, shuning uchun biz 7.5 versiyasiga yangilanishni to'xtatib, 7.6 versiyasiga yangilanish bilan hammasini qaytadan boshlashimiz kerak bo'ldi. Bu ham sodir bo'ladi.
Ikkinchidan, biz muammolar haqida kamdan-kam foydalanuvchi shikoyatlarini qabul qila boshladik. Endi biz ularning barchasi mijozlardan ba'zi serverlarimizga fayllarni yuklash bilan bog'liqligini aniq bilamiz. Bundan tashqari, ushbu serverlar yuklashlar umumiy sonining juda kichik foizini tashkil etdi.
Yuqoridagi hikoyadan esimizga tushganidek, Sysctlni qayta tiklash yordam bermadi. Qayta ishga tushirish yordam berdi, lekin vaqtinchalik.
Sysctl hali ham shubhali edi, ammo bu safar iloji boricha ko'proq ma'lumot to'plash juda muhim edi. Shuningdek, nima bo'layotganini aniqroq tekshirish uchun mijozda yuklash muammosini qayta yaratish imkoniyati juda zarur edi.
Mavjud barcha statistika va jurnallarni tahlil qilish bizni nima bo'layotganini tushunishga yaqinlashtirmadi. Biz muammoni qayta tiklash va aniq ulanishni tekshirish usuliga juda muhtoj edik. Nihoyat, ishlab chiquvchilar Wi-Fi orqali ulanganda ilovaning maxsus versiyasidan foydalangan holda muammolarni sinov qurilmasida ishonchli tarzda qayta yaratishga muvaffaq bo'lishdi. Bu tergovda katta yutuq bo'ldi. Mijoz Nginx-ga ulandi, bu bizning Java ilovamiz bo'lgan orqa qismga proksi-server orqali ulanish imkonini berdi.
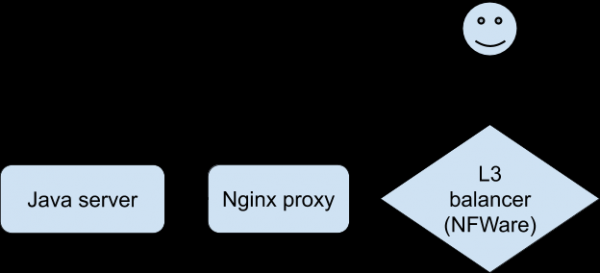
Muammolar paytida dialog quyidagicha edi (Nginx proksi tomonida yozib olingan):
- Mijoz: faylni yuklab olish tugallanganligi haqida ma'lumot olish uchun so'rov.
- Java serveri: javob.
- Mijoz: Fayl bilan POST.
- Java serveri: xato.
Java serveri mijozdan 0 bayt ma'lumot qabul qilinganligini qayd etadi, Nginx proksi-serveri esa so'rov 30 soniyadan ko'proq vaqt olganligini qayd etadi (30 soniya mijoz ilovasining kutish vaqti). Nima uchun kutish vaqti va nima uchun 0 bayt? HTTP nuqtai nazaridan hamma narsa kutilganidek ishlaydi, lekin fayl bilan POST tarmoqdan yo'qolib ketadi. Bundan tashqari, u mijoz va Nginx o'rtasida yo'qoladi. Tcpdump-ni olish vaqti keldi! Lekin avval tarmoq konfiguratsiyasini tushunishimiz kerak. Nginx proksi-serveri L3 yuk balanslashtiruvchisi orqasida joylashgan. Tunnellash L3 yuk balanslashtiruvchisidan serverga paketlarni yetkazib berish uchun ishlatiladi, server esa paketlarga o'z sarlavhalarini qo'shadi:
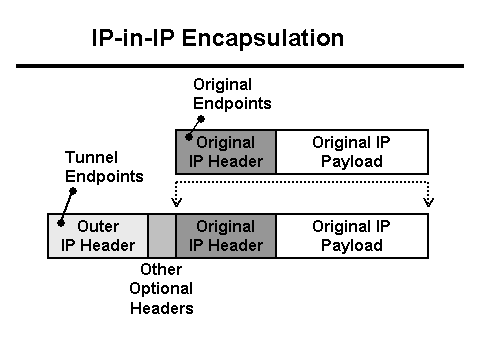
Bu holda, tarmoq ushbu serverga VLAN-yorliqli trafik shaklida keladi, bu ham paketlarga o'z maydonlarini qo'shadi:
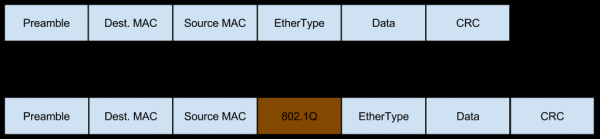
Ushbu trafik ham parchalanishi mumkin (biz vaqtinchalik xavfni baholashda muhokama qilgan kiruvchi parchalangan trafikning o'sha kichik foizi), bu ham sarlavhalar tarkibini o'zgartiradi:
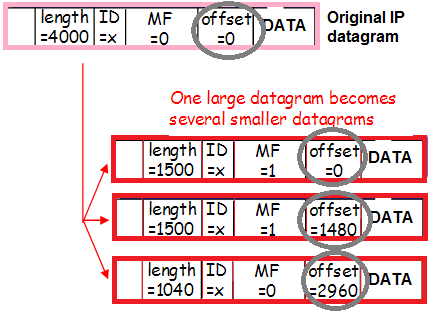
Yana bir bor: paketlar VLAN yorlig'i bilan kapsulalanadi, tunnel bilan kapsulalanadi va parchalanadi. Bu qanday sodir bo'lishini yaxshiroq tushunish uchun paketning mijozdan Nginx proksi-serverigacha bo'lgan yo'nalishini kuzatib boraylik.
- Paket L3 yuk balanslashtiruvchisiga yetib keladi. Ma'lumotlar markazida to'g'ri marshrutizatsiyani ta'minlash uchun paket tunnelga joylashtiriladi va tarmoq kartasiga yuboriladi.
- Paket + tunnel sarlavhalari MTUga mos kelmaganligi sababli, paket bo'laklarga bo'linadi va tarmoqqa yuboriladi.
- L3 balanseridan keyingi kommutator paketni qabul qilgandan so'ng unga VLAN yorlig'ini qo'shadi va uni yana uzatadi.
- Nginx proksi-serverining oldidagi kommutator (port sozlamalariga asoslanib) server VLAN bilan kapsulalangan paketni kutayotganini ko'radi, shuning uchun uni VLAN yorlig'ini olib tashlamasdan yuboradi.
- Linux alohida paketlarning parchalarini oladi va ularni bitta katta paketga yopishtiradi.
- Keyin, paket VLAN interfeysiga o'tadi, u yerda birinchi qatlam - VLAN kapsulasiyasi - olib tashlanadi.
- so'ng Linux uni Tunnel interfeysiga yuboradi, u yerda undan yana bir qatlam - Tunnel kapsulasiyasi olib tashlanadi.
Qiyinchilik shundaki, bularning barchasini tcpdump ga parametr sifatida uzatishda.
Oxiridan boshlaylik: mijozlardan VLAN va tunnel kapsulasiyasi olib tashlangan toza (keraksiz sarlavhalarsiz) IP paketlar bormi?
tcpdump host <ip клиента>
Yo'q, serverda bunday paketlar yo'q edi. Demak, muammo avvalroq mavjud bo'lgan bo'lishi kerak. Faqat VLAN kapsulasi olib tashlangan paketlar bormi?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx - bu mijozning hex formatidagi IP-manzili.
32:4 — Tunnel paketida SCR IP yozilgan maydonning manzili va uzunligi.
Internetda 40, 44, 50 va 54 deb ko'rsatilgani uchun manzil maydonini qo'pol ravishda to'ldirishim kerak edi, lekin IP-manzil yo'q edi. Shuningdek, hexdagi paketlardan birini (tcpdumpdagi -xx yoki -XX parametri) ko'rib chiqishingiz va qaysi manzil ma'lum IP-manzilga mos kelishini aniqlashingiz mumkin.
Vlan va Tunnel kapsulasini olib tashlamagan paket fragmentlari bormi?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Bu sehr bizga barcha parchalarni, shu jumladan oxirgisini ham ko'rsatadi. Xuddi shu narsani IP orqali filtrlash mumkin bo'lishi mumkin, lekin men bunday paketlar ko'p emasligi va menga kerak bo'lganlarini umumiy oqimda topish oson bo'lgani uchun harakat qilmadim. Mana ular:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 00:de:ff:1a:94:11 da ethertype IPv4 (0x0800), uzunligi 62: (tos 0x0, ttl 63, ID 53652, ofset 1480, bayroqlar [yo'q], proto IPIP (4), uzunlik 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 .........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(...?...f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
Bular bir xil paketning ikkita fragmenti (bir xil ID 53652) va fotosurati (Exif so'zi birinchi paketda ko'rinadi). Paketlar shu darajada mavjud bo'lganligi sababli, lekin birlashtirilgan dumplarda emas, shuning uchun yig'ishda aniq muammo bor. Nihoyat, ba'zi hujjatlashtirilgan tasdiqlar mavjud!
Paket dekoderi yig'ilishga xalaqit beradigan hech qanday muammoni aniqlamadi. Men buni bu yerda sinab ko'rdim: Dastlab, unga biror narsa kiritishga urinayotganda, dekoder paket formatini yoqtirmadi. Ma'lum bo'lishicha, Srcmac va Ethertype o'rtasida ikkita qo'shimcha oktet bor edi (fragment ma'lumotlari bilan bog'liq emas). Ularni olib tashlagandan so'ng, dekoder ishladi. Biroq, u hech qanday muammo ko'rsatmadi.
Qanday qarasangiz ham, Sysctl parametrlaridan boshqa hech narsa topilmadi. Faqat muammoli serverlarni aniqlash, masshtabni tushunish va keyingi harakatlar to'g'risida qaror qabul qilish qoldi. Kerakli hisoblagich juda tez topildi:
netstat -s | grep "packet reassembles failed”
Shuningdek, u snmpd da OID=1.3.6.1.2.1.4.31.1.1.16.1 ostida joylashgan ().
"IP qayta yig'ish algoritmi tomonidan aniqlangan nosozliklar soni (nima sababdan bo'lsa ham: vaqt tugashi, xatolar va boshqalar)."
O'rganilgan serverlar orasida bu hisoblagich ikkitasida tezroq, ikkitasida sekinroq va ikkitasida umuman oshmadi. Ushbu hisoblagichning dinamikasini Java serveridagi HTTP xatolarining dinamikasi bilan taqqoslash o'zaro bog'liqlikni aniqladi. Bu hisoblagichni kuzatish mumkinligini anglatadi.
Sysctl qayta tiklash yordam berayotganini aniq aniqlash uchun ishonchli muammo indikatoriga ega bo'lish juda muhimdir, chunki oldingi muhokamadan bilib olganimizdek, bu dasturdan darhol ko'rinmaydi. Ushbu indikator bizga foydalanuvchilar ularni aniqlamasdan oldin ishlab chiqarishdagi barcha muammoli sohalarni aniqlash imkonini beradi.
Sysctlni orqaga qaytargandan so'ng, monitoring xatolari to'xtadi, shuning uchun muammolarning sababi, shuningdek, orqaga qaytarish yordam berishi isbotlandi.
Yangi monitoring ishga tushgan boshqa serverlarda parchalanish sozlamalarini qaytarib oldik va ba'zi joylarda hatto fragmentatsiyalarga avvalgi standartdan ko'ra ko'proq xotira ajratdik (bu UDP statistikasi uchun edi, uning qisman yo'qolishi umumiy kontekstda sezilmadi).
Eng muhim savollar
Nima uchun bizning L3 yuklama balanslagichimizda paketlar parchalanmoqda? Foydalanuvchilardan yuklama balanslagichlariga keladigan paketlarning aksariyati SYN va ACK. Bu paketlar kichik. Biroq, bunday paketlar juda katta ulushni tashkil qilganligi sababli, biz parchalanayotgan katta paketlarni sezmadik.
Buning sababi buzilgan konfiguratsiya skripti edi. VLAN interfeyslariga ega serverlarda (o'sha paytda ishlab chiqarishda yorliqlangan trafikka ega serverlar juda kam edi). Advmss bizga mijozga yo'naltirilgan paketlar kichikroq bo'lishi kerakligi haqida xabar berish imkonini beradi, shunda ular tunnel sarlavhalarini qo'shgandan keyin parchalanib ketmasligi kerak.
Nima uchun Sysctl ni orqaga qaytarish yordam bermadi, lekin qayta ishga tushirish yordam berdi? Sysctl ni orqaga qaytarish paketlarni birlashtirish uchun mavjud bo'lgan xotira hajmini o'zgartirdi. Bundan tashqari, fragmentlar uchun xotira to'la bo'lganligi ulanishlarning sekinlashishiga olib kelgan ko'rinadi, bu esa fragmentlarning navbatda uzoq vaqt ushlab turilishiga olib keldi. Boshqacha qilib aytganda, jarayon tsiklda qolib ketdi.
Qayta ishga tushirish xotirani tozaladi va hamma narsa o'z joyiga qaytdi.
Vaqtinchalik yechimdan qochish mumkinmidi? Ha, lekin hujum sodir bo'lgan taqdirda foydalanuvchilarni xizmatsiz qoldirish xavfi yuqori edi. Vaqtinchalik yechimdan foydalanish turli muammolarga, jumladan, xizmatlardan birining foydalanuvchilari uchun sekinlashuvga olib kelgan bo'lsa-da, biz shunga qaramay, choralar oqlangan deb hisoblaymiz.
Andrey Timofeevga katta rahmat () tergov o'tkazishda yordam bergani uchun, shuningdek, Aleksey Krenevga () - yangilashning ulkan ishi uchun Centos va server yadrolari. Bu holda, jarayonni bir necha marta qayta boshlash kerak bo'ldi, natijada ko'p oylar davom etdi.
Manba: www.habr.com
