


komanda takliflar Clairvoyant kompaniyasidan muhandis Rahul Bhatiya katta ma'lumotlarda qanday fayl formatlari borligi, Hadoop formatlarining eng keng tarqalgan xususiyatlari qanday va qaysi formatdan foydalanish yaxshiroq ekanligi haqida.
Nima uchun turli xil fayl formatlari kerak?
MapReduce va Spark kabi HDFS-ni qo'llab-quvvatlaydigan ilovalar uchun asosiy ishlash muammosi ma'lumotlarni qidirish, o'qish va yozish uchun ketadigan vaqtdir. Ushbu muammolar katta ma'lumotlar to'plamlarini boshqarishda qiyinchilik bilan murakkablashadi, agar bizda barqaror emas, balki rivojlanayotgan sxema bo'lsa yoki ba'zi saqlash cheklovlari mavjud bo'lsa.
Katta ma'lumotlarni qayta ishlash saqlash quyi tizimidagi yukni oshiradi - Hadoop nosozliklarga chidamliligiga erishish uchun ma'lumotlarni ortiqcha saqlaydi. Disklardan tashqari protsessor, tarmoq, kiritish/chiqarish tizimi va boshqalar yuklanadi. Ma'lumotlar hajmining o'sishi bilan ularni qayta ishlash va saqlash xarajatlari oshadi.
Turli xil fayl formatlari aynan shu muammolarni hal qilish uchun ixtiro qilingan. Tegishli fayl formatini tanlash ba'zi muhim afzalliklarni berishi mumkin:
- Tezroq o'qish vaqti.
- Tezroq yozib olish vaqti.
- Umumiy fayllar.
- Sxema evolyutsiyasini qo'llab-quvvatlash.
- Kengaytirilgan siqish yordami.
Ba'zi fayl formatlari umumiy foydalanish uchun mo'ljallangan, boshqalari aniqroq foydalanish uchun, ba'zilari esa ma'lum ma'lumotlar xususiyatlariga javob berish uchun mo'ljallangan. Shunday qilib, tanlov haqiqatan ham juda katta.
Avro fayl formati
uchun ma'lumotlarni ketma-ketlashtirish Avro keng qo'llaniladi - bu qatorga asoslangan, ya'ni Hadoop-da string ma'lumotlarni saqlash formati. U sxemani JSON formatida saqlaydi va har qanday dastur tomonidan o'qish va sharhlashni osonlashtiradi. Ma'lumotlarning o'zi ikkilik formatda, ixcham va samarali.
Avroning serializatsiya tizimi til neytral hisoblanadi. Fayllar C, C++, C#, Java, Python va Ruby kabi turli tillarda qayta ishlanishi mumkin.
Avro ning asosiy xususiyati uning vaqt o'tishi bilan o'zgarib turadigan, ya'ni rivojlanib boruvchi ma'lumotlar sxemalarini mustahkam qo'llab-quvvatlashidir. Avro sxema o'zgarishlarini tushunadi - maydonlarni o'chirish, qo'shish yoki o'zgartirish.
Avro turli xil ma'lumotlar tuzilmalarini qo'llab-quvvatlaydi. Masalan, siz massiv, sanab o'tilgan turdagi va pastki yozuvni o'z ichiga olgan yozuvni yaratishingiz mumkin.
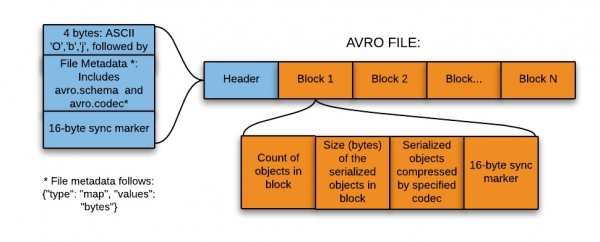
Ushbu format ma'lumotlar ko'lining qo'nish (o'tish) zonasiga yozish uchun idealdir (, yoki ma'lumotlar ko'li - to'g'ridan-to'g'ri ma'lumotlar manbalariga qo'shimcha ravishda har xil turdagi ma'lumotlarni saqlash uchun misollar to'plami).
Shunday qilib, ushbu format quyidagi sabablarga ko'ra ma'lumotlar ko'lining qo'nish zonasiga yozish uchun eng mos keladi:
- Ushbu zonadan olingan ma'lumotlar odatda quyi oqim tizimlari tomonidan keyingi ishlov berish uchun to'liq o'qiladi - va bu holda qatorga asoslangan format samaraliroq bo'ladi.
- Pastki oqim tizimlari fayllardan sxema jadvallarini osongina olishi mumkin - sxemalarni tashqi meta-xotirada alohida saqlash shart emas.
- Asl sxemaga har qanday o'zgartirish osonlik bilan qayta ishlanadi (sxema evolyutsiyasi).
Parket fayl formati
Parket - bu saqlaydigan Hadoop uchun ochiq kodli fayl formati tekis ustunli formatdagi ichki ma'lumotlar tuzilmalari.
An'anaviy qatorli yondashuv bilan solishtirganda, Parket saqlash va ishlash jihatidan ancha samarali.
Bu, ayniqsa, keng (ko'p ustunli) jadvaldan ma'lum ustunlarni o'qiydigan so'rovlar uchun foydalidir. Fayl formati tufayli faqat kerakli ustunlar o'qiladi, shuning uchun kiritish-chiqarish minimal darajada saqlanadi.
Kichkina tushuntirish va tushuntirish: Hadoop-da Parket fayl formatini yaxshiroq tushunish uchun, keling, ustunga asoslangan, ya'ni ustunli format nima ekanligini ko'rib chiqamiz. Ushbu format har bir ustun uchun o'xshash qiymatlarni birga saqlaydi.
, yozuv ID, Ism va Bo'lim maydonlarini o'z ichiga oladi. Bunday holda, barcha identifikator ustun qiymatlari nom ustuni qiymatlari kabi birga saqlanadi va hokazo. Jadval shunday ko'rinishga ega bo'ladi:
ID
Ism
Bo'lim
1
em1
d1
2
em2
d2
3
em3
d3
String formatida ma'lumotlar quyidagicha saqlanadi:
1
em1
d1
2
em2
d2
3
em3
d3
Ustunli fayl formatida bir xil ma'lumotlar quyidagicha saqlanadi:
1
2
3
em1
em2
em3
d1
d2
d3
Jadvaldan bir nechta ustunlarni so'rash kerak bo'lganda ustunli format samaraliroq bo'ladi. U faqat kerakli ustunlarni o'qiydi, chunki ular qo'shni. Shunday qilib, kiritish-chiqarish operatsiyalari minimal darajaga tushiriladi.
Masalan, sizga faqat NAME ustuni kerak. IN Ma'lumotlar to'plamidagi har bir yozuvni yuklash, maydon bo'yicha tahlil qilish va keyin NAME ma'lumotlarini chiqarish kerak. Ustun formati to'g'ridan-to'g'ri Ism ustuniga o'tish imkonini beradi, chunki bu ustun uchun barcha qiymatlar birga saqlanadi. Siz butun yozuvni skanerlashingiz shart emas.
Shunday qilib, ustunli format so'rovlar ishlashini yaxshilaydi, chunki u kerakli ustunlarga o'tish uchun kamroq qidirish vaqtini talab qiladi va kiritish-chiqarish operatsiyalari sonini kamaytiradi, chunki faqat kerakli ustunlar o'qiladi.
O'ziga xos xususiyatlardan biri bu formatda bo'lishi mumkin ichki o'rnatilgan tuzilmalar bilan ma'lumotlarni saqlash. Bu shuni anglatadiki, Parket faylida hatto ichki o'rnatilgan maydonlar ham ichki o'rnatilgan strukturadagi barcha maydonlarni o'qimasdan alohida o'qilishi mumkin. Parket o'rnatilgan tuzilmalarni saqlash uchun maydalash va yig'ish algoritmidan foydalanadi.
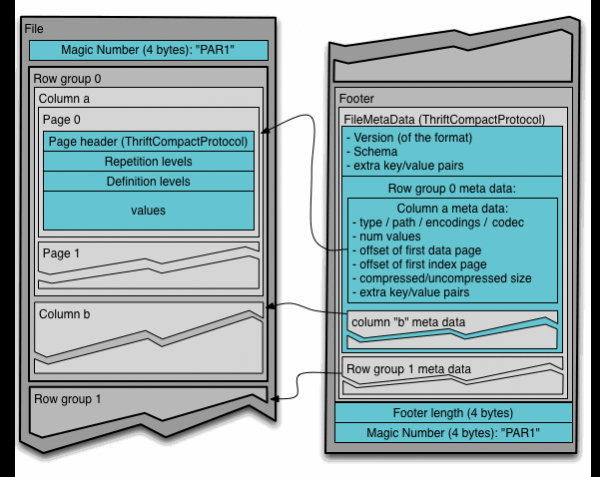
Hadoop-da Parket fayl formatini tushunish uchun siz quyidagi shartlarni bilishingiz kerak:
- Satrlar guruhi (qator guruhi): ma'lumotlarning qatorlarga mantiqiy gorizontal bo'linishi. Satrlar guruhi ma'lumotlar to'plamidagi har bir ustunning bir qismidan iborat.
- Ustun bo'lagi (ustun qismi): Muayyan ustunning bo'lagi. Ushbu ustun bo'laklari ma'lum bir qatorlar guruhida yashaydi va faylda qo'shni bo'lishi kafolatlanadi.
- bet (sahifa): Ustun bo'laklari birin-ketin yozilgan sahifalarga bo'linadi. Sahifalar umumiy sarlavhaga ega, shuning uchun o'qish paytida keraksizlarni o'tkazib yuborishingiz mumkin.
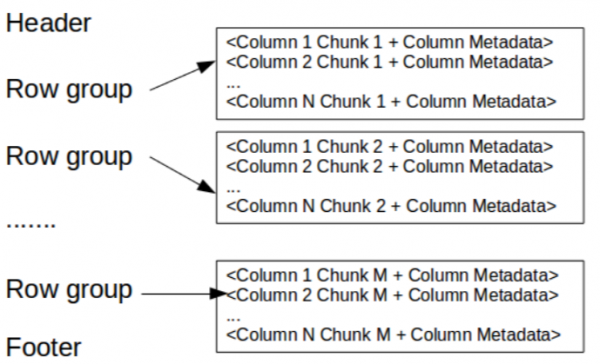
Bu erda sarlavha faqat sehrli raqamni o'z ichiga oladi PAR1 (4 bayt) bu faylni Parket fayli sifatida belgilaydi.
Altbilgida quyidagilar aytiladi:
- Har bir ustun metamaʼlumotlarining boshlangʻich koordinatalarini oʻz ichiga olgan fayl metamaʼlumotlari. O'qiyotganda, qiziqtirgan barcha ustun qismlarini topish uchun avval faylning metama'lumotlarini o'qib chiqishingiz kerak. Keyin ustun qismlarini ketma-ket o'qish kerak. Boshqa metadata format versiyasini, sxemasini va har qanday qo'shimcha kalit-qiymat juftligini o'z ichiga oladi.
- Metadata uzunligi (4 bayt).
- Sehrli raqam PAR1 (4 bayt).
ORC fayl formati
Optimallashtirilgan satr-ustun fayl formati (Optimallashtirilgan qator ustuni, ) ma'lumotlarni saqlashning juda samarali usulini taklif qiladi va boshqa formatlarning cheklovlarini engib o'tish uchun mo'ljallangan. Ma'lumotlarni mukammal ixcham shaklda saqlaydi, bu sizga keraksiz tafsilotlarni o'tkazib yuborishga imkon beradi - katta, murakkab yoki qo'lda saqlanadigan indekslarni qurishni talab qilmasdan.
ORC formatining afzalliklari:
- Bitta fayl har bir vazifaning chiqishi bo'lib, bu NameNode (nom tugun) ga yukni kamaytiradi.
- Hive ma'lumotlar turlarini qo'llab-quvvatlash, jumladan, DateTime, o'nlik va murakkab ma'lumotlar turlari (struktura, ro'yxat, xarita va birlashma).
- Turli RecordReader jarayonlari tomonidan bir xil faylni bir vaqtda o'qish.
- Markerlarni skanerlamasdan fayllarni bo'lish qobiliyati.
- Fayl altbilgisidagi ma'lumotlarga asoslanib, o'qish/yozish jarayonlari uchun maksimal mumkin bo'lgan yig'ma xotirani ajratishni baholash.
- Metadata Protocol Buffers ikkilik ketma-ketlashtirish formatida saqlanadi, bu maydonlarni qo'shish va o'chirish imkonini beradi.
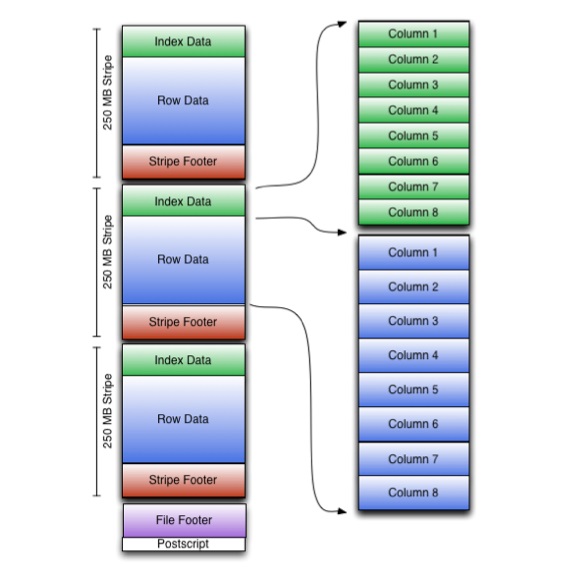
ORC satrlar to'plamini bitta faylda saqlaydi va to'plam ichida satr ma'lumotlari ustunli formatda saqlanadi.
ORC faylida chiziqlar deb ataladigan qatorlar guruhlari va faylning pastki qismidagi yordamchi ma'lumotlar saqlanadi. Fayl oxiridagi Postscript siqish parametrlarini va siqilgan altbilgi hajmini o'z ichiga oladi.
Standart chiziq hajmi 250 MB. Bunday katta chiziqlar tufayli HDFS dan o'qish yanada samarali amalga oshiriladi: katta qo'shni bloklarda.
Fayl altbilgisi fayldagi qatorlar ro'yxatini, har bir qatordagi qatorlar sonini va har bir ustunning ma'lumotlar turini yozadi. Har bir ustun uchun count, min, max va summaning natijaviy qiymati ham shu yerda yoziladi.
Chiziqning pastki qismida oqim joylari katalogi mavjud.
Jadvallarni skanerlashda qator ma'lumotlaridan foydalaniladi.
Indeks ma'lumotlari har bir ustun uchun minimal va maksimal qiymatlarni va har bir ustundagi satrlarning o'rnini o'z ichiga oladi. ORC indekslari so'rovlarga javob berish uchun emas, faqat chiziqlar va qator guruhlarini tanlash uchun ishlatiladi.
Turli xil fayl formatlarini taqqoslash
Avro Parket bilan solishtirganda
- Avro qator saqlash formatidir, Parket esa ma'lumotlarni ustunlarda saqlaydi.
- Parket analitik so'rovlar uchun ko'proq mos keladi, ya'ni o'qish operatsiyalari va so'rov ma'lumotlari yozishdan ko'ra ancha samaralidir.
- Avroda yozish operatsiyalari Parketga qaraganda samaraliroq bajariladi.
- Avro sxemalar evolyutsiyasi bilan yanada etukroq shug'ullanadi. Parket faqat sxema qo'shishni qo'llab-quvvatlaydi, Avro esa ko'p funksiyali evolyutsiyani, ya'ni ustunlarni qo'shish yoki o'zgartirishni qo'llab-quvvatlaydi.
- Parket ko'p ustunli jadvaldagi ustunlar to'plamini so'rash uchun ideal. Avro biz barcha ustunlarni so'raydigan ETL operatsiyalari uchun javob beradi.
ORC va parket
- Parket ichki ma'lumotlarni yaxshiroq saqlaydi.
- ORC predikatsiyani pastga tushirish uchun yaxshiroq mos keladi.
- ORC ACID xususiyatlarini qo'llab-quvvatlaydi.
- ORC ma'lumotlarni yaxshiroq siqadi.
Mavzu bo'yicha yana nimani o'qish kerak:
- .
- .
- .
Manba: www.habr.com
