


Bu bahorda biz ba'zi kirish mavzularini muhokama qildik, masalan. и . Ulardan ikkinchisida biz ZFS-da turli xil ko'p diskli topologiyalarning ishlashini o'rganishni davom ettirishga va'da berdik. Bu hozir hamma joyda tarqatilayotgan keyingi avlod fayl tizimi : .
Xo'sh, bugun ZFS, qiziquvchan o'quvchilar bilan tanishish uchun eng yaxshi kun. Bilingki, OpenZFS dasturchisi Mett Ahrensning kamtarona bahosida "bu haqiqatan ham qiyin".
Ammo raqamlarga o'tishdan oldin - va men va'da qilaman - barcha sakkiz diskli ZFS konfiguratsiya variantlari haqida gaplashishimiz kerak. qanday Umuman olganda, ZFS ma'lumotlarni diskda saqlaydi.
Zpool, vdev va qurilma
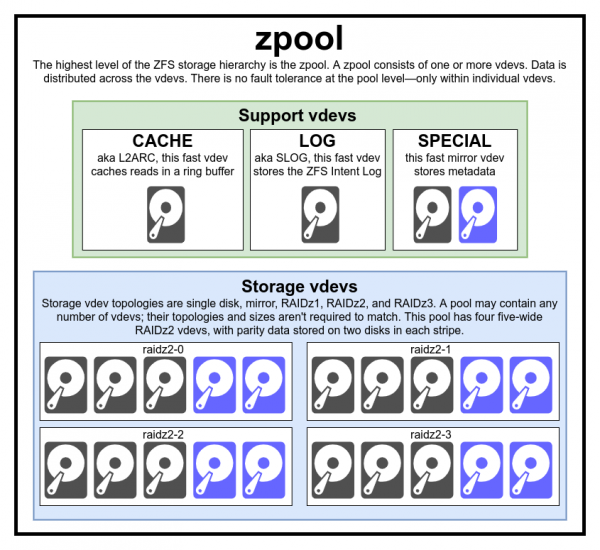
Ushbu to'liq hovuz diagrammasi uchta yordamchi vdevni, har bir sinfdan bittasini va RAIDz2 uchun to'rttasini o'z ichiga oladi.

Odatda mos kelmaydigan vdev turlari va o'lchamlari hovuzini yaratish uchun hech qanday sabab yo'q - lekin agar xohlasangiz, bunga hech narsa to'sqinlik qilmaydi.
ZFS fayl tizimini chinakam tushunish uchun uning haqiqiy tuzilishini diqqat bilan ko'rib chiqishingiz kerak. Birinchidan, ZFS an'anaviy hajm va fayl tizimini boshqarish qatlamlarini birlashtiradi. Ikkinchidan, tranzaksiyaviy nusxa ko'chirish va yozish mexanizmidan foydalanadi. Bu xususiyatlar tizimning an'anaviy fayl tizimlari va RAID massivlaridan tizimli ravishda juda farq qilishini anglatadi. Tushunish kerak bo'lgan asosiy qurilish bloklarining birinchi to'plami saqlash hovuzi (zpool), virtual qurilma (vdev) va haqiqiy qurilma (qurilma).
zpool
Zpool saqlash hovuzi ZFSning eng yuqori tuzilmasi hisoblanadi. Har bir hovuzda bir yoki bir nechta virtual qurilmalar mavjud. O'z navbatida, ularning har birida bir yoki bir nechta haqiqiy qurilmalar (qurilma) mavjud. Virtual hovuzlar o'z-o'zidan tuzilgan birliklardir. Bitta jismoniy kompyuter ikki yoki undan ortiq alohida hovuzlarni o'z ichiga olishi mumkin, ammo ularning har biri boshqalardan butunlay mustaqildir. Hovuzlar virtual qurilmalarni ulasha olmaydi.
ZFS zaxirasi hovuz darajasida emas, balki virtual qurilma darajasida. Hovuz darajasida ortiqcha ortiqcha narsa yo'q - agar vdev yoki ajratilgan vdev yo'qolsa, u bilan birga butun hovuz ham yo'qoladi.
Zamonaviy saqlash havzalari virtual qurilma keshini yoki jurnalini yo'qotishdan omon qolishi mumkin - garchi ular elektr uzilishi yoki tizimning ishdan chiqishi paytida vdev jurnalini yo'qotib qo'ysa, oz miqdordagi iflos ma'lumotlarni yo'qotishi mumkin.
ZFS "ma'lumotlar chiziqlari" butun hovuz bo'ylab yozilgan degan keng tarqalgan noto'g'ri tushuncha mavjud. Bu haqiqat emas. Zpool kulgili RAID0 emas, balki kulgiliroq murakkab o'zgaruvchan taqsimlash mexanizmi bilan.
Ko'pincha, yozuvlar mavjud virtual qurilmalar o'rtasida mavjud bo'sh joyga ko'ra taqsimlanadi, shuning uchun nazariy jihatdan ularning barchasi bir vaqtning o'zida to'ldiriladi. ZFS ning eng so'nggi versiyalari joriy vdev-dan foydalanishni (foydalanishni) hisobga oladi - agar bitta virtual qurilma boshqasidan sezilarli darajada band bo'lsa (masalan, o'qish yuki tufayli), eng yuqori bo'sh joy nisbatiga ega bo'lishiga qaramay, u vaqtinchalik yozish uchun o'tkazib yuboriladi.
Zamonaviy ZFS yozishni taqsimlash usullariga o'rnatilgan qayta ishlashni aniqlash mexanizmi g'ayrioddiy yuklanish davrida kechikishni kamaytirishi va o'tkazuvchanlikni oshirishi mumkin, ammo unday emas. kart blansh sekin HDD va tez SSD-larni bir hovuzda beixtiyor aralashtirish. Bunday tengsiz hovuz hali ham eng sekin qurilma tezligida ishlaydi, ya'ni u butunlay bunday qurilmalardan tashkil topgandek.
vdev
Har bir saqlash havzasi bir yoki bir nechta virtual qurilmalardan (vdev) iborat. O'z navbatida, har bir vdev bir yoki bir nechta haqiqiy qurilmalarni o'z ichiga oladi. Ko'pgina virtual qurilmalar oddiy ma'lumotlarni saqlash uchun ishlatiladi, lekin CACHE, LOG va SPECIAL kabi bir nechta vdev yordamchi sinflari mavjud. Ushbu vdev turlarining har biri beshta topologiyadan biriga ega bo'lishi mumkin: bitta qurilma, RAIDz1, RAIDz2, RAIDz3 yoki oyna.
RAIDz1, RAIDz2 va RAIDz3 eski odamlar qo'sh (diagonal) RAID pariteti deb ataydigan maxsus navlardir. 1, 2 va 3 har bir ma'lumot qatoriga qancha paritet bloklari ajratilganligini bildiradi. Paritetni ta'minlash uchun alohida disklarga ega bo'lish o'rniga, virtual RAIDz qurilmalari paritetni disklar bo'ylab yarim teng taqsimlaydi. RAIDz massivi paritet bloklari bo'lgan disklarni yo'qotishi mumkin; agar u boshqasini yo'qotsa, u muvaffaqiyatsiz bo'ladi va saqlash hovuzini o'zi bilan olib ketadi.
Oyna virtual qurilmalarida (mirror vdev) har bir blok vdevdagi har bir qurilmada saqlanadi. Ikki kenglikdagi nometall eng keng tarqalgan bo'lsa-da, ko'zgu har qanday o'zboshimchalik soniga ega bo'lishi mumkin - kattaroq o'rnatishlarda ko'pincha uchlik o'qish samaradorligini va xatolarga chidamliligini yaxshilash uchun ishlatiladi. vdev oynasi vdevdagi kamida bitta qurilma ishlayotgan bo'lsa, har qanday nosozlikdan omon qolishi mumkin.
Yagona vdevlar tabiatan xavflidir. Bunday virtual qurilma bitta nosozlikdan omon qolmaydi - va agar saqlash yoki maxsus vdev sifatida ishlatilsa, uning ishdan chiqishi butun hovuzning yo'q qilinishiga olib keladi. Bu erda juda ehtiyot bo'ling.
KEYSH, LOG va MAXSUS virtual qurilmalar yuqoridagi topologiyalarning har qandayida yaratilishi mumkin – lekin esda tutingki, MAXSUS virtual qurilmani yo‘qotish hovuzni yo‘qotish demakdir, shuning uchun ortiqcha topologiya tavsiya etiladi.
qurilma
Bu, ehtimol, ZFSda tushunish uchun eng oson atama - bu tom ma'noda bloklangan tasodifiy kirish qurilmasi. Esda tutingki, virtual qurilmalar alohida qurilmalardan, hovuz esa virtual qurilmalardan iborat.
Magnit yoki qattiq holatdagi disklar vdevning qurilish bloklari sifatida ishlatiladigan eng keng tarqalgan blokli qurilmalardir. Biroq, /dev-da identifikatorga ega bo'lgan har qanday qurilma buni amalga oshiradi - shuning uchun butun apparat RAID massivlari alohida qurilmalar sifatida ishlatilishi mumkin.
Oddiy xom fayl vdev-ni qurish mumkin bo'lgan eng muhim alternativ blok qurilmalardan biridir. dan sinov hovuzlari hovuz buyruqlarini tekshirish va berilgan topologiyaning hovuz yoki virtual qurilmasida qancha joy mavjudligini ko'rishning juda qulay usulidir.
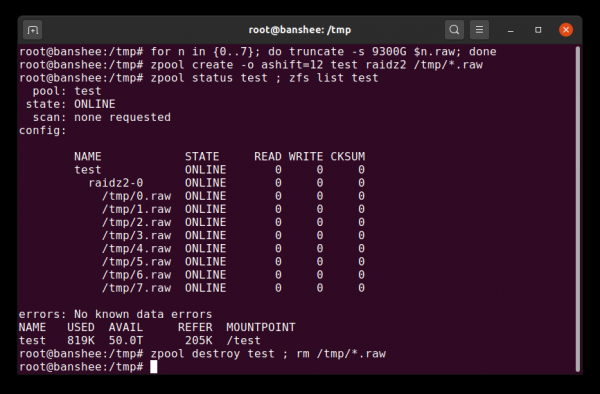
Siz bir necha soniya ichida siyrak fayllardan test hovuzini yaratishingiz mumkin, lekin keyin butun hovuzni va uning tarkibiy qismlarini oʻchirishni unutmang.
Aytaylik, siz sakkiz diskli serverga ega bo'lishni xohlaysiz va 10TB (~9300 GiB) disklardan foydalanishni rejalashtiryapsiz, lekin qaysi topologiya ehtiyojlaringizga eng mos kelishini bilmayapsiz. Yuqoridagi misolda biz bir necha soniya ichida siyrak fayllarning sinov pulini yaratamiz va endi bilamizki, sakkizta 2TB drayvdan iborat RAIDz10 vdev 50TiB foydalanish imkoniyatini beradi.
Qurilmalarning yana bir maxsus sinfi - SPARE. Hot-swap qurilmalari oddiy qurilmalardan farqli o'laroq, bitta virtual qurilmaga emas, balki butun hovuzga tegishli. Agar hovuzdagi har qanday vdev ishlamay qolsa va zaxira qurilma hovuzga ulangan va mavjud bo'lsa, u avtomatik ravishda ta'sirlangan vdevga qo'shiladi.
Ta'sir qilingan vdevga ulangandan so'ng, almashtirish qurilmasi etishmayotgan qurilmada bo'lishi kerak bo'lgan ma'lumotlarning nusxalarini yoki rekonstruksiyalarini olishni boshlaydi. An'anaviy RAIDda bu "qayta qurish" deb nomlanadi va ZFSda bu "qayta tiklash".
Shuni ta'kidlash kerakki, almashtirish qurilmalari muvaffaqiyatsiz qurilmalarni doimiy ravishda almashtirmaydi. Bu vdevning yomonlashishi uchun zarur bo'lgan vaqtni qisqartirish uchun faqat vaqtinchalik almashtirish. Administrator ishlamay qolgan vdev qurilmasini almashtirgandan so'ng, o'sha doimiy qurilmada zaxira tiklanadi va SPARE vdevdan uziladi va butun hovuz uchun zaxira bo'lib qaytadi.
Ma'lumotlar to'plamlari, bloklari va sektorlari
Bizning ZFS sayohatimizda tushunish uchun qurilish bloklarining keyingi to'plami apparatga kamroq bog'liq va ma'lumotlarning o'zi qanday tashkil etilishi va saqlanishi bilan bog'liq. Tafsilotlarni chalkashtirib yubormaslik uchun umumiy tuzilmani tushunish uchun biz bu yerda bir nechta qatlamlarni, masalan, metaslabni o'tkazib yubormoqdamiz.
Ma'lumotlar to'plami
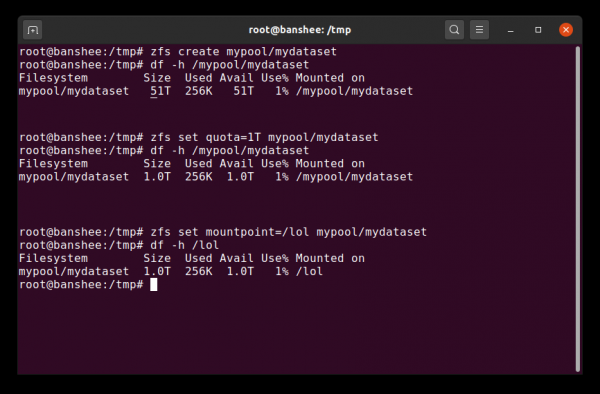
Biz birinchi marta ma'lumotlar to'plamini yaratganimizda, u barcha mavjud hovuz maydonini ko'rsatadi. Keyin biz kvotani o'rnatamiz - va o'rnatish nuqtasini o'zgartiramiz. Sehrli!
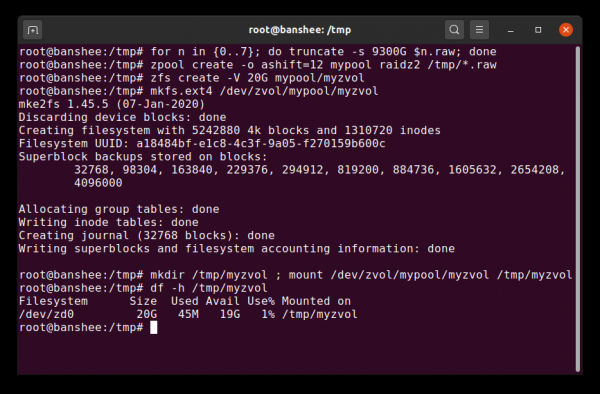
Zvol asosan fayl tizimi qatlamidan tozalangan ma'lumotlar to'plami bo'lib, biz bu erda butunlay oddiy ext4 fayl tizimi bilan almashtiramiz.
ZFS ma'lumotlar to'plami standart o'rnatilgan fayl tizimi bilan taxminan bir xil. Oddiy fayl tizimi kabi, u birinchi qarashda "boshqa papka" kabi ko'rinadi. Oddiy o'rnatilgan fayl tizimlari singari, har bir ZFS ma'lumotlar to'plami o'zining asosiy xususiyatlariga ega.
Birinchidan, ma'lumotlar to'plami tayinlangan kvotaga ega bo'lishi mumkin. Agar o'rnatsangiz zfs set quota=100G poolname/datasetname, keyin siz o'rnatilgan jildga yoza olmaysiz /poolname/datasetname 100 Gb dan ortiq.
Har bir satr boshida qiyshiq chiziq borligi va yo'qligiga e'tibor bering? Har bir ma'lumotlar to'plami ZFS ierarxiyasida ham, tizim o'rnatish ierarxiyasida ham o'z o'rniga ega. ZFS ierarxiyasida bosh chiziq yo'q - siz hovuz nomidan boshlaysiz, so'ngra bir ma'lumot to'plamidan ikkinchisiga o'tadigan yo'l. Masalan, pool/parent/child nomli ma'lumotlar to'plami uchun child asosiy ma'lumotlar to'plami ostida parent ijodiy nomga ega hovuzda pool.
Odatiy bo'lib, ma'lumotlar to'plamining o'rnatish nuqtasi ZFS ierarxiyasidagi uning nomiga ekvivalent bo'ladi, bosh slash - hovuz nomidagi pool sifatida o'rnatilgan /pool, ma'lumotlar to'plami parent ichiga o'rnatilgan /pool/parent, va bola ma'lumotlar to'plami child ichiga o'rnatilgan /pool/parent/child. Biroq, ma'lumotlar to'plamining tizimni o'rnatish nuqtasini o'zgartirish mumkin.
Agar ko'rsatsak zfs set mountpoint=/lol pool/parent/child, keyin ma'lumotlar to'plami pool/parent/child sifatida tizimga o'rnatiladi /lol.
Ma'lumotlar to'plamiga qo'shimcha ravishda biz hajmlarni (zvols) eslatib o'tishimiz kerak. Hajm taxminan ma'lumotlar to'plami bilan bir xil, faqat uning fayl tizimi mavjud emas - bu shunchaki blokli qurilma. Siz, masalan, yaratishingiz mumkin zvol Ism bilan mypool/myzvol, keyin uni ext4 fayl tizimi bilan formatlang va keyin oʻsha fayl tizimini oʻrnating – endi sizda ext4 fayl tizimi bor, lekin ZFS ning barcha xavfsizlik xususiyatlari bilan! Bu bitta kompyuterda ahmoqona tuyulishi mumkin, lekin iSCSI qurilmasini eksport qilishda backend sifatida ancha mantiqiyroq bo'ladi.
Bloklar
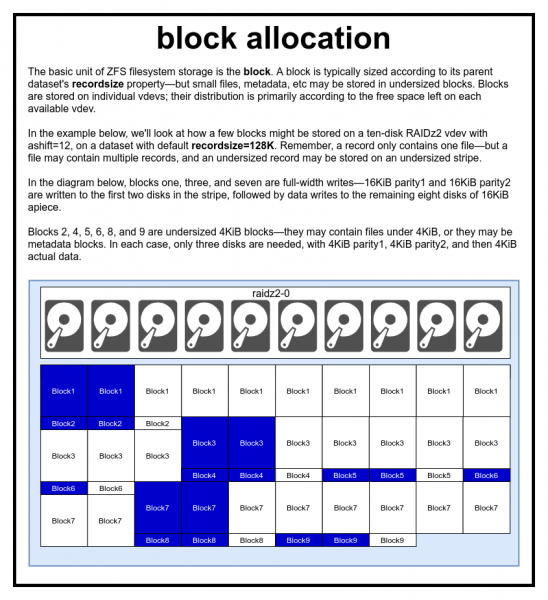
Fayl bir yoki bir nechta bloklar bilan ifodalanadi. Har bir blok bitta virtual qurilmada saqlanadi. Blok hajmi odatda parametrga teng rekord o'lcham, lekin ga qisqartirish mumkin 2^ashift, agar u metadata yoki kichik faylni o'z ichiga olgan bo'lsa.

Biz, albatta albatta Ashiftni juda past o'rnatgan bo'lsangiz, unumdorlikning katta jazosi haqida hazillashayotganimiz yo'q
ZFS hovuzida barcha ma'lumotlar, shu jumladan metama'lumotlar bloklarda saqlanadi. Har bir ma'lumot to'plami uchun maksimal blok hajmi xususiyatda aniqlanadi recordsize (rekord hajmi). Yozuv o'lchami o'zgarishi mumkin, ammo bu ma'lumotlar to'plamiga allaqachon yozilgan bloklarning o'lchamini yoki joylashishini o'zgartirmaydi - bu faqat yangi bloklarga yozilganidek ta'sir qiladi.
Agar boshqacha belgilanmagan bo'lsa, joriy standart kirish hajmi 128 KiB. Bu qandaydir og'ir savdo bo'lib, unda ishlash mukammal bo'lmaydi, lekin ko'p hollarda bu dahshatli bo'lmaydi. Recordsize 4K dan 1M gacha bo'lgan istalgan qiymatga o'rnatilishi mumkin (qo'shimcha sozlamalar bilan recordsize siz ko'proq o'rnatishingiz mumkin, lekin bu kamdan-kam hollarda yaxshi fikr).
Har qanday blok faqat bitta faylning ma'lumotlariga ishora qiladi - ikkita turli faylni bitta blokga siqib bo'lmaydi. Har bir fayl hajmiga qarab bir yoki bir nechta bloklardan iborat. Agar fayl hajmi rekord o'lchamdan kichikroq bo'lsa, u kichikroq blokda saqlanadi - masalan, 2KiB faylni o'z ichiga olgan blok diskda faqat bitta 4KiB sektorni egallaydi.
Agar fayl bir nechta bloklarni talab qiladigan darajada katta bo'lsa, u holda ushbu faylga kiritilgan barcha yozuvlar o'lchamda bo'ladi recordsize - asosiy qismi bo'lishi mumkin bo'lgan oxirgi yozuvni o'z ichiga oladi .
zvol hajmlari mulkka ega emas recordsize - o'rniga ular ekvivalent xususiyatga ega volblocksize.
Sektorlar
Oxirgi, eng asosiy qurilish bloki bu sektordir. Bu xost qurilmasiga yozish yoki undan o'qish mumkin bo'lgan eng kichik jismoniy birlikdir. Bir necha o'n yillar davomida aksariyat disklar 512 baytli sektorlardan foydalangan. Bugungi kunda ko'pchilik drayvlar 4KiB sektorlari uchun sozlangan va ba'zilari, ayniqsa SSD'lar - 8KiB yoki undan ham kattaroq sektorlar uchun tuzilgan.
ZFS sektor o'lchamini qo'lda sozlash imkonini beruvchi xususiyatga ega. Bu mulk ashift. Bir oz chalkashlik bilan, ashift ikkining kuchidir. Masalan, ashift=9 sektor hajmi 2^9 yoki 512 baytni bildiradi.
ZFS operatsion tizimdan yangi vdevga qo'shilganda har bir blok qurilmasi haqida batafsil ma'lumot so'raydi va nazariy jihatdan, ushbu ma'lumotlarga asoslanib, avtomatik ravishda ashift ni mos ravishda o'rnatadi. Afsuski, ko'plab drayvlar moslikni saqlab qolish uchun sektor hajmi haqida yolg'on gapirishadi. Windows XP (turli sektor o'lchamlariga ega disklarni tushuna olmadi).
Bu shuni anglatadiki, ZFS ma'muriga o'z qurilmalarining haqiqiy sektor hajmini bilishi va qo'lda sozlash tavsiya etiladi. ashift. Agar ashift juda kichik o'rnatilgan bo'lsa, o'qish/yozish operatsiyalari soni astronomik darajada oshadi. Shunday qilib, haqiqiy 512KiB sektoriga 4 baytlik "sektorlarni" yozish birinchi "sektorni" yozish, keyin 4KiB sektorini o'qish, uni ikkinchi 512 baytlik "sektor bilan o'zgartirish", uni yangi 4KiB sektoriga qaytarish kerak degan ma'noni anglatadi. , va hokazo. har bir kirish uchun.
Haqiqiy dunyoda bunday jazo Samsung EVO SSD-larga ta'sir qiladi, buning uchun u qo'llanilishi kerak ashift=13, lekin bu SSD'lar ularning sektor o'lchamlari haqida yolg'on gapiradi va shuning uchun sukut bo'yicha o'rnatiladi ashift=9. Tajribali tizim ma'muri ushbu sozlamani o'zgartirmasa, bu SSD ishlaydi Sekinroq oddiy magnit HDD.
Taqqoslash uchun, juda kattaligi uchun ashift penalti deyarli yo'q. Haqiqiy samaradorlik yo'q va foydalanilmagan maydonning o'sishi cheksizdir (yoki siqish yoqilgan bo'lsa, nolga teng). Shuning uchun, hatto 512 baytli sektorlardan foydalanadigan disklarni ham o'rnatishni tavsiya qilamiz ashift=12 yoki hatto ashift=13kelajakka ishonch bilan qarash.
Mulk ashift Har bir virtual qurilma vdev uchun o'rnatiladi va basseyn uchun emas, ko'pchilik noto'g'ri deb o'ylaydi va o'rnatishdan keyin o'zgarmaydi. Agar siz tasodifan urib qolsangiz ashift Hovuzga yangi vdev qo'shsangiz, siz o'sha hovuzni past unumdor qurilma bilan qaytarib bo'lmaydigan darajada ifloslantirdingiz va qoida tariqasida, hovuzni yo'q qilish va qaytadan boshlashdan boshqa iloji yo'q. Hatto vdevni o'chirish ham sizni buzilgan sozlamalardan qutqarmaydi ashift!
Yozishda nusxa ko'chirish mexanizmi
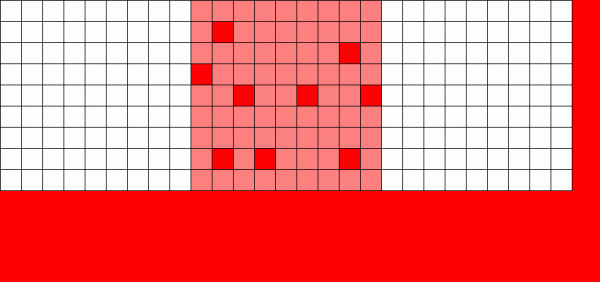
Oddiy fayl tizimi ma'lumotlarni qayta yozishi kerak bo'lsa, u joylashgan har bir blokni o'zgartiradi
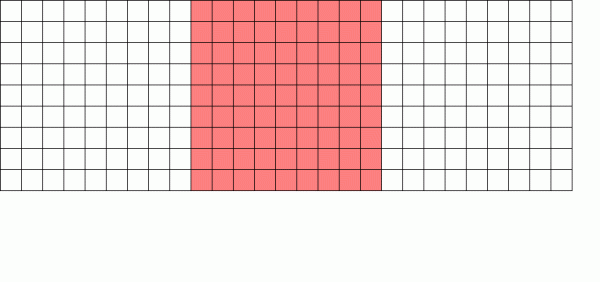
Yozishda nusxa ko'chirish fayl tizimi blokning yangi versiyasini yozadi va keyin eski versiyani qulfdan chiqaradi

Xulosa qilib aytganda, agar biz bloklarning haqiqiy jismoniy joylashishini e'tiborsiz qoldiradigan bo'lsak, bizning "ma'lumotlar kometasi" mavjud bo'shliq xaritasi bo'ylab chapdan o'ngga harakatlanadigan "ma'lumotlar qurti" ga soddalashadi.

Endi biz “Yozishda nusxa ko‘chirish” suratlari qanday ishlashi haqida yaxshi tasavvurga ega bo‘lishimiz mumkin – har bir blok bir nechta suratga tegishli bo‘lishi mumkin va barcha tegishli suratlar yo‘q qilinmaguncha saqlanib qoladi.
Copy on Write (CoW) mexanizmi ZFSni shunday ajoyib tizimga aylantiradigan asosiy asosdir. Asosiy tushuncha oddiy - agar siz an'anaviy fayl tizimidan faylni o'zgartirishni so'rasangiz, u aynan siz so'ragan narsani bajaradi. Agar siz "Yozishda nusxa ko'chirish" fayl tizimidan xuddi shunday qilishni so'rasangiz, u "yaxshi" deb javob beradi - lekin u sizga yolg'on gapiradi.
Buning o'rniga, yozishga nusxa ko'chirish fayl tizimi o'zgartirilgan blokning yangi versiyasini yozadi va keyin eski blokni ajratish va uni siz yozgan yangi blok bilan bog'lash uchun faylning metama'lumotlarini yangilaydi.
Eski blokni ochish va yangisini ulash bitta operatsiyada amalga oshiriladi, shuning uchun uni to'xtatib bo'lmaydi - agar bu sodir bo'lgandan keyin quvvatni qayta o'rnatsangiz, faylning yangi versiyasiga ega bo'lasiz va agar siz avval quvvatni qayta o'rnatgan bo'lsangiz, unda sizda bo'ladi. eski versiya. Qanday bo'lmasin, fayl tizimida hech qanday nizolar bo'lmaydi.
ZFS da nusxa ko'chirish faqat fayl tizimi darajasida emas, balki diskni boshqarish darajasida ham sodir bo'ladi. Bu ZFS yozuvdagi bo'shliqqa sezgir emasligini anglatadi () - tizimning ishdan chiqishidan oldin chiziq qisman qayd etilgan va qayta ishga tushirilgandan so'ng massivga zarar yetkazilgan hodisa. Bu erda chiziq atomik tarzda yoziladi, vdev har doim ketma-ket va .
ZIL: ZFS niyatlar jurnali
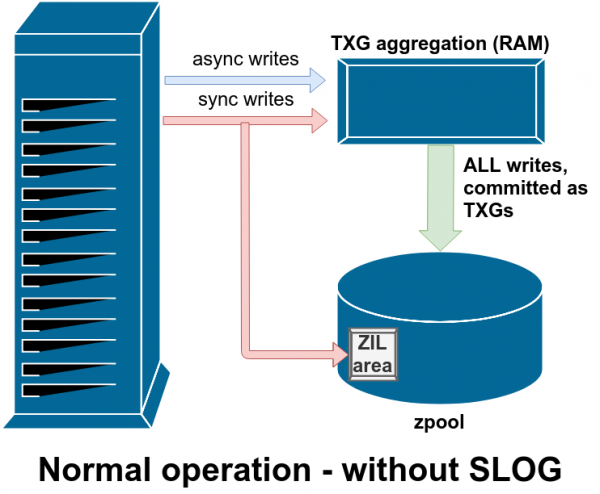
ZFS sinxron yozishni maxsus usulda boshqaradi - u ularni vaqtincha, lekin asinxron yozishlar bilan birga doimiy ravishda yozishdan oldin darhol ZILda saqlaydi.
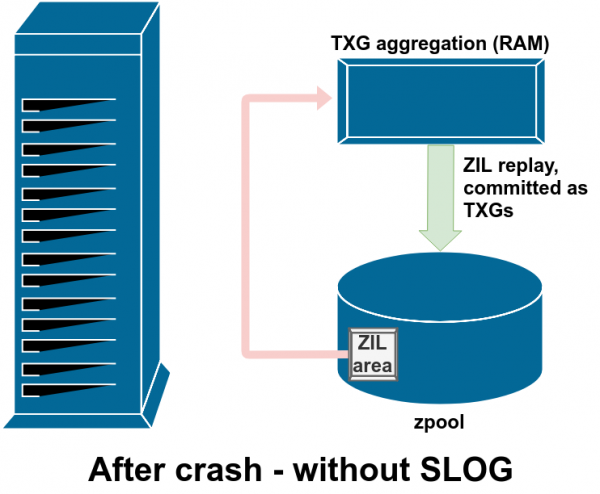
Odatda, ZIL-ga yozilgan ma'lumotlar hech qachon qayta o'qilmaydi. Ammo bu tizimning ishdan chiqishidan keyin mumkin
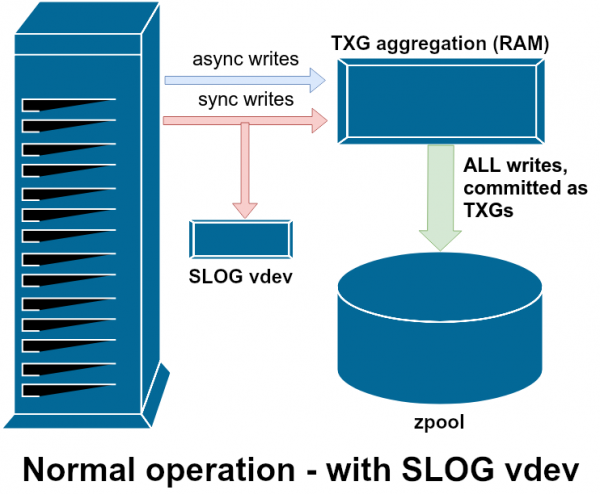
SLOG yoki ikkilamchi LOG qurilmasi oddiygina maxsus va afzalroq juda tez vdev bo'lib, u erda ZIL asosiy xotiradan alohida saqlanishi mumkin.
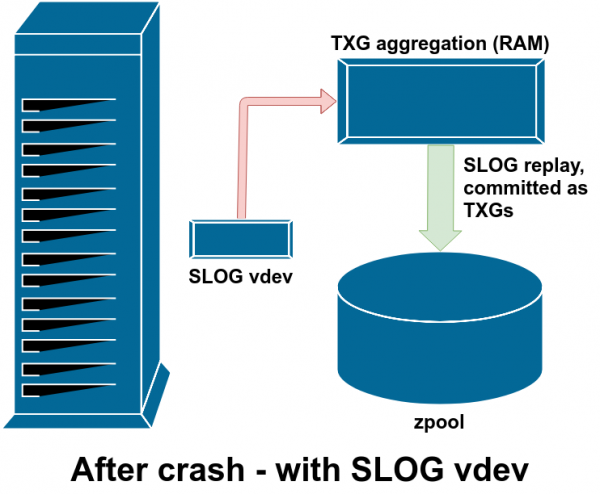
Avariyadan so'ng, ZIL-dagi barcha iflos ma'lumotlar qayta o'ynaladi - bu holda, ZIL SLOG-da, shuning uchun u o'sha erda qayta o'ynaladi.
Yozishning ikkita asosiy toifasi mavjud - sinxron (sinxron) va asinxron (asinxron). Aksariyat ish yuklari uchun yozishlarning katta qismi asinxrondir - fayl tizimi ularni birlashtirish va partiyalarda chiqarish imkonini beradi, bu esa parchalanishni kamaytiradi va o'tkazish qobiliyatini sezilarli darajada oshiradi.
Sinxron yozuvlar butunlay boshqa masala. Ilova sinxron yozishni so'raganda, u fayl tizimiga aytadi: "Siz buni doimiy xotiraga topshirishingiz kerak. hozir, va shu paytgacha men boshqa hech narsa qila olmayman." Shuning uchun sinxron yozishni zudlik bilan diskka o'tkazish kerak - va agar bu parchalanishni kuchaytirsa yoki o'tkazish qobiliyatini kamaytirsa, shunday bo'lsin.
ZFS sinxron yozishni oddiy fayl tizimlaridan farqli ravishda boshqaradi - ularni darhol oddiy saqlashga o'tkazish o'rniga, ZFS ularni ZFS Intent Log yoki ZIL deb nomlangan maxsus saqlash maydoniga joylashtiradi. Ayyorlik shundaki, bu yozuvlar Shuningdek, xotirada qoladi, odatdagi asinxron yozish so'rovlari bilan birga yig'iladi va keyinchalik butunlay oddiy TXG (Tranzaktsiya guruhlari) sifatida saqlashga o'tkaziladi.
Oddiy ish paytida ZIL yoziladi va boshqa hech qachon o'qilmaydi. Bir necha daqiqadan so'ng, ZIL-dagi yozuvlar RAMdan oddiy TXG-larda asosiy saqlashga topshirilganda, ular ZIL-dan ajratiladi. Hovuzni import qilishda ZIL-dan biror narsa o'qiladigan yagona vaqt.
Agar ZFS ishdan chiqishi sodir bo'lsa - operatsion tizim ishdan chiqishi yoki elektr quvvati uzilishi - ZILda ma'lumotlar mavjud bo'lsa, bu ma'lumotlar keyingi hovuz importi paytida o'qiladi (masalan, buzilish tizimi qayta ishga tushirilganda). ZILda bo'lgan narsa o'qiladi, TXGlarga guruhlanadi, asosiy do'konga topshiriladi va import jarayonida ZILdan ajratiladi.
Vdev yordamchi sinflaridan biri LOG yoki SLOG, ikkinchi darajali LOG qurilmasi deb ataladi. Uning bitta maqsadi bor - asosiy vdev xotirasida ZILni saqlash o'rniga, ZILni saqlash uchun alohida va afzalroq tezroq, juda yozishga chidamli vdev qurilmasi bilan hovuzni ta'minlash. ZILning o'zi saqlash joyidan qat'i nazar, xuddi shunday harakat qiladi, lekin agar LOG bilan vdev juda yuqori yozish qobiliyatiga ega bo'lsa, sinxron yozish tezroq bo'ladi.
Hovuzga LOG bilan vdevni qo'shish ishlamaydi bo'lishi mumkin emas asinxron yozish samaradorligini oshirish - agar siz ZIL ga barcha yozishni majburlasangiz ham zfs set sync=always, ular baribir TXG-dagi asosiy xotiraga jurnalsiz bir xil tarzda va bir xil tezlikda ulanadi. To'g'ridan-to'g'ri ishlashning yagona yaxshilanishi sinxron yozish kechikishidir (chunki yuqori jurnal tezligi operatsiyalarni tezlashtiradi sync).
Biroq, ko'p sinxron yozishni talab qiladigan muhitda vdev LOG bilvosita asinxron yozishni va keshlanmagan o'qishni tezlashtirishi mumkin. ZIL yozuvlarini alohida vdev LOG-ga tushirish birlamchi xotirada IOPS uchun kamroq tortishuvni anglatadi, bu esa barcha o'qish va yozishlarning ishlashini ma'lum darajada yaxshilaydi.
Suratlar
Yozuvga nusxa ko'chirish mexanizmi ZFS atomik suratlari va asta-sekin asinxron replikatsiya uchun zarur asosdir. Faol fayl tizimida joriy ma'lumotlar bilan barcha yozuvlarni belgilovchi ko'rsatkich daraxti mavjud - siz suratga olganingizda, shunchaki ko'rsatkich daraxtining nusxasini yaratasiz.
Yozuv faol fayl tizimiga yozilsa, ZFS birinchi navbatda blokning yangi versiyasini foydalanilmagan maydonga yozadi. Keyin blokning eski versiyasini joriy fayl tizimidan ajratadi. Ammo agar ba'zi bir surat eski blokga ishora qilsa, u hali ham o'zgarishsiz qoladi. Qadimgi blok aslida bo'sh joy sifatida tiklanmaydi, toki ushbu blokga tegishli barcha suratlar yo'q qilinadi!
Replikatsiya
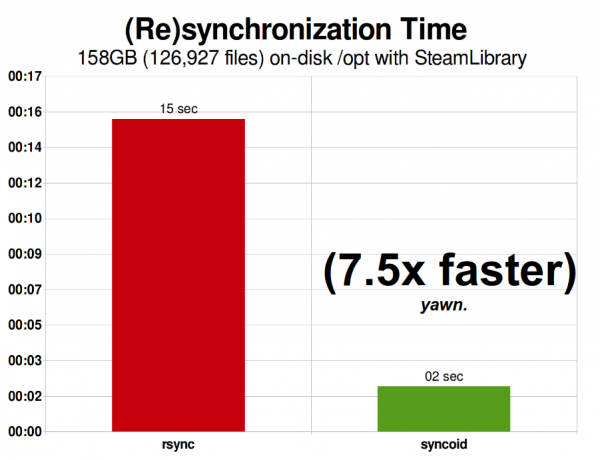
Mening Steam kutubxonam 2015 yilda 158 GiB bo'lib, 126 927 faylni o'z ichiga olgan. Bu rsync uchun optimal holatga juda yaqin - tarmoq orqali ZFS replikatsiyasi "faqat" 750% tezroq edi.
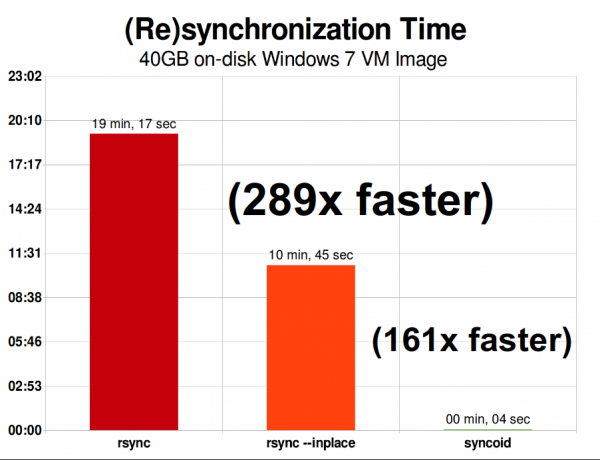
Xuddi shu tarmoqda, bitta 40 gigabaytli virtual mashina tasvir faylining replikatsiyasi Windows 7 butunlay boshqacha hikoya. ZFS replikatsiyasi rsyncga qaraganda 289 marta tezroq yoki agar siz --inplace tugmasi yordamida rsyncni chaqira oladigan darajada bilimli bo'lsangiz, "faqat" 161 marta tezroq.
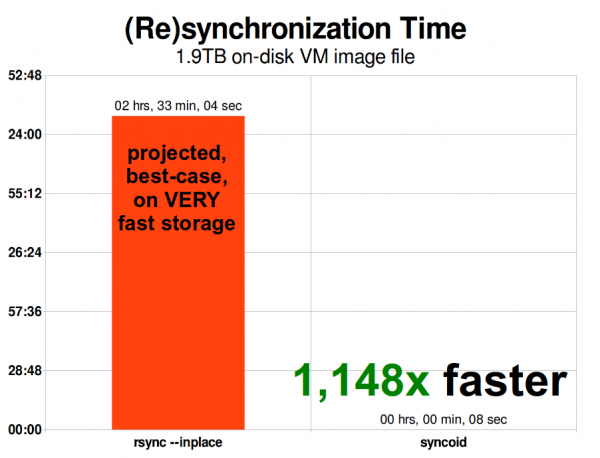
VM tasviri masshtablanganda, rsync u bilan masshtablash muammosi. 1,9 TiB o‘lchami zamonaviy VM tasviri uchun unchalik katta emas – lekin u qadar kattaki, ZFS replikatsiyasi rsync-dan 1148 marta tezroq, hatto rsync – inplace argumentida ham.
Snapshotlar qanday ishlashini tushunganingizdan so'ng, replikatsiyaning mohiyatini tushunish oson bo'ladi. Snapshot shunchaki rekord ko'rsatkichlar daraxti bo'lgani uchun, agar shunday qilsak, shunday bo'ladi zfs send snapshot, keyin biz ushbu daraxtni va u bilan bog'liq barcha yozuvlarni yuboramiz. Biz buni o'tkazganimizda zfs send в zfs receive maqsadli ob'ektda u blokning haqiqiy mazmunini ham, bloklarni maqsadli ma'lumotlar to'plamiga havola qiluvchi ko'rsatkichlar daraxtini ham yozadi.
Ikkinchisida narsalar yanada qiziqarli bo'ladi zfs send. Endi bizda ikkita tizim mavjud, ularning har biri o'z ichiga oladi poolname/datasetname@1, va siz yangi suratga olasiz poolname/datasetname@2. Shuning uchun, sizda mavjud manba hovuzida datasetname@1 и datasetname@2, va maqsadli hovuzda faqat birinchi oniy rasm mavjud datasetname@1.
Chunki manba va maqsad o'rtasida biz umumiy suratga egamiz datasetname@1, biz qila olamiz ortib boruvchi zfs send uning ustiga. Tizimga aytganimizda zfs send -i poolname/datasetname@1 poolname/datasetname@2, u ikkita ko'rsatkich daraxtini taqqoslaydi. Faqat ichida mavjud bo'lgan har qanday ko'rsatkichlar @2, shubhasiz, yangi bloklarga murojaat qiling - shuning uchun bizga ushbu bloklarning mazmuni kerak bo'ladi.
Masofaviy tizimda ishlov berish bosqichma-bosqich send xuddi oddiy. Avval biz oqimga kiritilgan barcha yangi yozuvlarni yozamiz send, va keyin ushbu bloklarga ko'rsatgichlar qo'shing. Voila, bizda bor @2 yangi tizimda!
ZFS asinxron incremental replikatsiyasi rsync kabi oldingi suratga asoslanmagan usullarga nisbatan katta yaxshilanishdir. Ikkala holatda ham faqat o'zgartirilgan ma'lumotlar uzatiladi - lekin birinchi navbatda rsync kerak o'qing yig'indini tekshirish va solishtirish uchun har ikki tomondagi barcha ma'lumotlarni diskdan. Bundan farqli o'laroq, ZFS replikatsiyasi ko'rsatkich daraxtlari va umumiy rasmda ko'rsatilmagan bloklardan boshqa hech narsani o'qimaydi.
O'rnatilgan siqish
Yozishda nusxa ko'chirish mexanizmi o'rnatilgan siqish tizimini ham soddalashtiradi. An'anaviy fayl tizimida siqish muammoli - o'zgartirilgan ma'lumotlarning eski versiyasi ham, yangi versiyasi ham bir xil bo'shliqda joylashgan.
Agar siz faylning o'rtasida 0x00000000 va shunga o'xshash nollardan iborat megabayt sifatida boshlanadigan ma'lumot qismini ko'rib chiqsangiz, uni diskdagi bitta sektorga siqish juda oson. Ammo agar biz ushbu megabayt nollarni JPEG yoki psevdo-tasodifiy shovqin kabi siqilmaydigan ma'lumotlarning megabayti bilan almashtirsak nima bo'ladi? To'satdan, bu megabayt ma'lumotlar bir emas, balki 256 4KiB sektorni talab qiladi va bu disk maydonida faqat bitta sektor ajratilgan.
ZFSda bunday muammo yo'q, chunki o'zgartirilgan yozuvlar har doim foydalanilmagan joyga yoziladi - asl blok faqat bitta 4 KiB sektorni egallaydi, lekin yangi yozish 256 ni egallaydi, lekin bu muammo emas - yaqinda o'zgartirilgan bo'lak " faylning o'rtasi, uning hajmi o'zgargan yoki o'zgarmaganligidan qat'i nazar, foydalanilmagan maydonga yozilgan bo'lar edi, shuning uchun bu ZFS uchun mutlaqo normal holat.
ZFS-ning o'rnatilgan siqilishi sukut bo'yicha o'chirilgan va tizim ulanadigan algoritmlarni taklif qiladi - hozirda LZ4, gzip (1-9), LZJB va ZLE.
- LZ4 juda tez siqishni va dekompressiyani va ko'p foydalanish holatlarida, hatto juda sekin protsessorlarda ham ishlash afzalliklarini taklif qiluvchi oqim algoritmidir.
- GZIP Bu barcha Unix foydalanuvchilari biladigan va sevadigan hurmatli algoritmdir. U 1-darajaga yaqinlashganda siqishni nisbati va protsessordan foydalanish ortib borishi bilan 9-9 siqish darajalari bilan amalga oshirilishi mumkin. Algoritm barcha matnli (yoki yuqori darajada siqiladigan) foydalanish holatlari uchun juda mos keladi, lekin ko‘pincha protsessor bilan bog‘liq muammolarga olib keladi. ehtiyotkorlik bilan, ayniqsa yuqori darajalarda.
- LZJB - ZFS da original algoritm. U eskirgan va endi ishlatilmasligi kerak, LZ4 har tomonlama ustundir.
- YOMON — nol darajali kodlash, nol darajali kodlash. Oddiy ma'lumotlarga umuman tegmaydi, lekin u nollarning katta ketma-ketligini siqib chiqaradi. To'liq siqilmaydigan ma'lumotlar to'plamlari (JPEG, MP4 yoki boshqa allaqachon siqilgan formatlar kabi) uchun foydalidir, chunki u siqilmaydigan ma'lumotlarni e'tiborsiz qoldiradi, lekin natijada olingan yozuvlarda foydalanilmagan bo'sh joyni siqadi.
Biz deyarli barcha foydalanish holatlari uchun LZ4 siqishni tavsiya qilamiz; siqilmaydigan ma'lumotlar bilan ishlashda ishlash jazosi juda kichik va o'sish Odatdagi ma'lumotlarning ishlashga ta'siri sezilarli. Yangi operatsion tizim o'rnatilishi uchun virtual mashina tasvirini nusxalash Windows (yangi o'rnatilgan OS, hali ichkarida ma'lumotlar yo'q) compression=lz4 bilan solishtirganda 27% tezroq o'tdi compression=none, in .
ARC - Adaptiv almashtirish keshi
ZFS biz bilgan yagona zamonaviy fayl tizimi bo'lib, u operativ xotirada yaqinda o'qilgan bloklarning nusxalarini saqlash uchun operatsion tizim sahifa keshiga tayanmasdan, o'zining o'qishni keshlash mexanizmidan foydalanadi.
Mahalliy kesh muammosiz bo'lmasa ham - ZFS yangi xotira ajratish so'rovlariga yadro kabi tez javob bera olmaydi, shuning uchun yangi qo'ng'iroq malloc() Xotirani ajratish, agar u hozirda ARC tomonidan ishg'ol qilingan RAMni talab qilsa, muvaffaqiyatsiz bo'lishi mumkin. Lekin hech bo'lmaganda hozircha o'z keshingizdan foydalanish uchun yaxshi sabablar bor.
MacOS kabi barcha ma'lum zamonaviy operatsion tizimlar, Windows, Linux va BSD sahifa keshini amalga oshirish uchun LRU (Eng kam ishlatilgan) algoritmidan foydalanadi. Bu har bir o'qishdan keyin keshlangan blokni "navbatning yuqori qismiga" ko'chiradigan va yangi kesh xatolarini (keshdan emas, balki diskdan o'qilishi kerak bo'lgan bloklar) yuqori qismga qo'shish uchun kerak bo'lganda bloklarni "navbatning pastki qismiga" chiqarib yuboradigan ibtidoiy algoritmdir.
Odatda algoritm yaxshi ishlaydi, lekin katta ishlaydigan ma'lumotlar to'plamlari bo'lgan tizimlarda LRU osonlikcha parchalanishga olib keladi - keshdan hech qachon o'qilmaydigan bloklarga joy ochish uchun tez-tez kerakli bloklarni chiqarib tashlaydi.
juda kam sodda algoritm bo'lib, uni "vaznli" kesh deb hisoblash mumkin. Har safar keshlangan blok o'qilganda, u biroz "og'irroq" bo'ladi va uni chiqarib yuborish qiyinroq bo'ladi - hatto blok chiqarib tashlangandan keyin ham kuzatilgan ma'lum bir vaqt oralig'ida. O'chirilgan, lekin keyin yana keshga o'qilishi kerak bo'lgan blok ham og'irlashadi.
Bularning barchasining yakuniy natijasi ancha yuqori urish nisbati bo'lgan keshdir - kesh urishi (keshdan o'qiladi) va o'tkazib yuborilgan (diskdan o'qiladi) o'rtasidagi nisbat. Bu juda muhim statistik ko'rsatkich - nafaqat kesh hitlarining o'z-o'zidan kattaroq buyurtmalarga xizmat ko'rsatishi, balki kesh o'tkazib yuborilishiga ham tezroq xizmat ko'rsatish mumkin, chunki kesh xitlar qancha ko'p bo'lsa, diskka bir vaqtda so'rovlar shunchalik kam bo'ladi va qolgan o'tkazib yuborilganlar uchun kechikishlar shunchalik past bo'ladi. disk bilan xizmat ko'rsatish kerak.
xulosa
Endi biz ZFS ning asosiy semantikasini - yozishda nusxa ko'chirish qanday ishlashini, shuningdek, saqlash havzalari, virtual qurilmalar, bloklar, sektorlar va fayllar o'rtasidagi munosabatlarni ko'rib chiqdik - biz haqiqiy dunyo ishlashini muhokama qilishga tayyormiz. haqiqiy raqamlar.
Keyingi bo'limda biz aks ettirilgan vdevlar va RAIDzli basseynlarning haqiqiy ishlashini bir-biri bilan, shuningdek, an'anaviy yadro RAID topologiyalari bilan taqqoslab ko'rib chiqamiz. Linuxbiz tadqiq qilgan .
Avvaliga biz faqat asoslarni - ZFS topologiyalarining o'zlarini qamrab olishni xohladik, lekin keyin bunday Biz ZFS-ning yanada rivojlangan konfiguratsiyasi va sozlashi, shu jumladan L2ARC, SLOG va Maxsus ajratish kabi yordamchi vdev turlaridan foydalanish haqida gapirishga tayyor bo'lamiz.
Manba: www.habr.com
