

Mening ishimning tabiatiga ko'ra, men ishlab chiquvchi so'rov yozadigan va o'ylaydigan vaziyatlarni hal qilishim kerak "Baza aqlli, u hamma narsani o'zi hal qiladi!«
Ba'zi hollarda (qisman ma'lumotlar bazasining imkoniyatlarini bilmaslik, qisman muddatidan oldin optimallashtirish tufayli) bu yondashuv "Frankenshteynlar" ning paydo bo'lishiga olib keladi.
Birinchidan, bunday so'rovga misol keltiraman:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;So'rov sifatini ob'ektiv baholash uchun tasodifiy ma'lumotlar to'plamini yarataylik:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
Ma'lum bo'lishicha, shunday ekan ma'lumotlarni o'qish umumiy vaqtning chorak qismidan kamroq vaqtni oldi so'rovning bajarilishi:
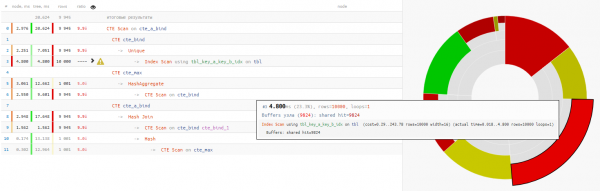
Keling, uni qismlarga bo'lib ajratamiz
Keling, so'rovni batafsil ko'rib chiqaylik va hayron qolamiz:
- Agar rekursiv CTElar bo'lmasa, nima uchun WITH RECURSIVE bu erda?
- Nima uchun min/maksimal qiymatlarni alohida CTEda guruhlash kerak, agar ular asl namunaga bog'langan bo'lsa?
+25% vaqt - Nima uchun so'zsiz "SELECT * FROM" orqali oldingi CTE ni qayta o'qish kerak?
+14% vaqt
Bunday holda, ulanish uchun Nested Loop emas, balki Hash Join tanlangani biz uchun juda omadli edi, o'shandan beri biz bitta CTE Scan yo'llanmasini emas, balki 10K ni olgan bo'lardik!
CTE Scan haqida bir ozBu erda biz buni eslashimiz kerak CTE Scan Seq Scanning analogidir - ya'ni indekslash yo'q, faqat to'liq ro'yxatga olish kerak bo'ladi 10K x 0.3ms = 3000ms cte_max orqali velosipedda harakatlanayotganda yoki 1K x 1.5ms = 1500ms cte_bind tomonidan aylanish paytida!
Aslida, natijada nimani olishni xohladingiz? Ha, bu odatda "uch qavatli" so'rovlarni tahlil qilishning 5-daqiqasida paydo bo'ladigan savol.
Biz har bir noyob kalit juftligi uchun chiqishni xohladik key_a tomonidan guruhdan min/maks.
Shunday qilib, keling, buning uchun foydalanaylik :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 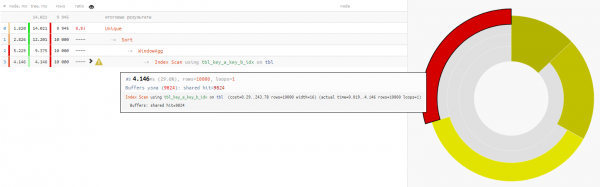
Ikkala variantda ham ma'lumotlarni o'qish bir xil taxminan 4-5 ms davom etganligi sababli, vaqt o'tishi bilan bizning butun daromadimiz -32% - bu eng sof shaklda CPU bazasidan yuk olib tashlangan, agar bunday so'rov etarlicha tez-tez bajarilsa.
Umuman olganda, asosiy narsalarni "yumaloq narsalarni kiyish, kvadrat narsalarni aylantirish" ga majburlashning hojati yo'q.
Manba: www.habr.com
