

Paket tartibli R tilidagi eng mashhur kutubxonalardan birining asosiy qismidir - tartibli.
Paketning asosiy maqsadi ma'lumotlarni toza shaklga keltirishdir.
Habré-da allaqachon mavjud ushbu paketga bag'ishlangan, lekin u 2015 yilga to'g'ri keladi. Va men uning muallifi Xedli Uikxem bir necha kun oldin e'lon qilgan eng dolzarb o'zgarishlar haqida gapirmoqchiman.
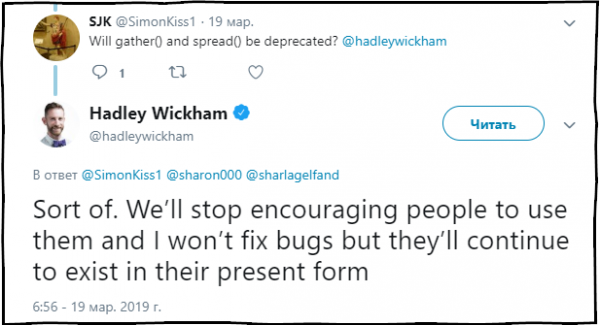
S.J.K.: gather() va spread() funksiyalari eskiradimi?
Xedli Uikxem: Qaysidir darajada. Biz endi bu funksiyalardan foydalanishni tavsiya etmaymiz va ulardagi xatolarni tuzatmaymiz, lekin ular hozirgi holatida paketda mavjud bo‘lib qoladi.
Mundarija
Agar siz ma'lumotlarni tahlil qilish bilan qiziqsangiz, meni qiziqtirishi mumkin и kanallar. Kontentning katta qismi R tiliga bag'ishlangan.
TidyData kontseptsiyasi
Maqsad tartibli — maʼlumotlaringizni toza, tartibli shakl deb ataladigan shaklda tartibga solishga yordam beradi. Aniq ma'lumotlar ma'lumotlardir, bu erda:
- Har bir o'zgaruvchi ustunda joylashgan.
- Har bir kuzatuv qatordir.
- Har bir qiymat hujayradan iborat.
Tahlil o'tkazishda tartibli ma'lumotlarga aylantirilgan ma'lumotlar bilan ishlash ancha oson va qulayroq.
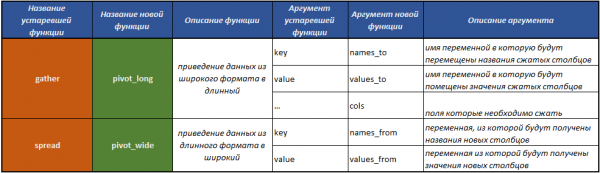
Tidyr paketiga kiritilgan asosiy funktsiyalar
tidyr jadvallarni o'zgartirish uchun mo'ljallangan funktsiyalar to'plamini o'z ichiga oladi:
fill()- ustundagi etishmayotgan qiymatlarni oldingi qiymatlar bilan to'ldirish;separate()— ajratgich yordamida bir maydonni bir nechaga ajratadi;unite()— bir nechta maydonlarni bittaga birlashtirish operatsiyasini, funksiyaning teskari harakatini bajaradiseparate();pivot_longer()— maʼlumotlarni keng formatdan uzun formatga oʻzgartiruvchi funksiya;pivot_wider()— maʼlumotlarni uzun formatdan keng formatga oʻzgartiruvchi funksiya. Amaliyot funksiya tomonidan bajariladigan amalning teskarisi hisoblanadipivot_longer().gather()eskirgan — maʼlumotlarni keng formatdan uzun formatga oʻzgartiruvchi funksiya;spread()eskirgan — maʼlumotlarni uzun formatdan keng formatga oʻzgartiruvchi funksiya. Amaliyot funksiya tomonidan bajariladigan amalning teskarisi hisoblanadigather().
Ma'lumotlarni keng formatdan uzun formatga va aksincha o'tkazish uchun yangi kontseptsiya
Ilgari bu turdagi transformatsiyalar uchun funksiyalardan foydalanilgan. gather() и spread()Yillar davomida ma'lum bo'ldiki, ko'pchilik foydalanuvchilar, shu jumladan paket muallifi uchun ushbu funktsiyalarning nomlari va ularning argumentlari unchalik aniq emas, bu ularni topish va ushbu funktsiyalardan qaysi biri ma'lumotlar ramkasini keng formatdan uzun formatga o'zgartirishini tushunishda qiyinchiliklarga olib keldi va aksincha.
Shu munosabat bilan, in tartibli Ma'lumotlar ramkalarini o'zgartirish uchun mo'ljallangan ikkita yangi, muhim funksiya qo'shildi.
Yangi xususiyatlar pivot_longer() и pivot_wider() paketdagi ba'zi xususiyatlardan ilhomlangan cdata, Jon Mount va Nina Zumel tomonidan yaratilgan.
Tidyr 0.8.3.9000 ning so'nggi versiyasini o'rnatish
Paketning eng yangi, eng joriy versiyasini o'rnatish uchun tartibli 0.8.3.9000, unda yangi xususiyatlar mavjud bo'lsa, quyidagi koddan foydalaning.
devtools::install_github("tidyverse/tidyr")
Yozish vaqtida bu funksiyalar faqat GitHub’dagi paketning ishlab chiquvchi versiyasida mavjud.
Yangi xususiyatlarga o'tish
Aslida, eski skriptlarni yangi funktsiyalar bilan ishlashga aylantirish qiyin emas. Yaxshiroq tushunish uchun men eski funktsiyalarning hujjatlaridan misol keltiraman va bir xil operatsiyalar yangilari yordamida qanday bajarilishini ko'rsataman. pivot_*() funktsiyalari.
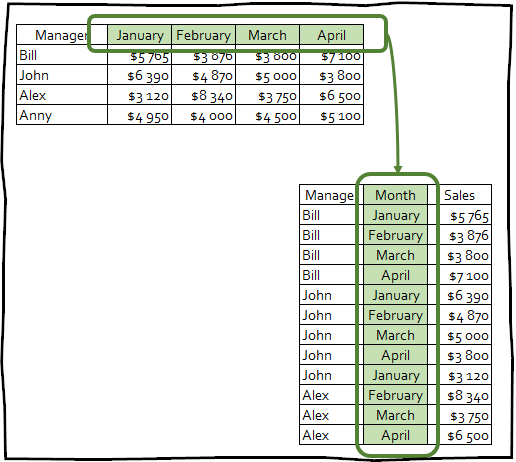
Keng formatni uzun formatga aylantirish.
To'plash funktsiyasi hujjatlaridan namuna kodi
# example
library(dplyr)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 0, 1),
Y = rnorm(10, 0, 2),
Z = rnorm(10, 0, 4)
)
# old
stocks_gather <- stocks %>% gather(key = stock,
value = price,
-time)
# new
stocks_long <- stocks %>% pivot_longer(cols = -time,
names_to = "stock",
values_to = "price")
Uzoq formatni keng formatga aylantirish.
Tarqatish funksiyasi hujjatlaridan namuna kodi
# old
stocks_spread <- stocks_gather %>% spread(key = stock,
value = price)
# new
stock_wide <- stocks_long %>% pivot_wider(names_from = "stock",
values_from = "price")
Chunki bilan ishlashning yuqoridagi misollarida pivot_longer() и pivot_wider(), asl jadvalda qimmatli qog'ozlar argumentlarda ustunlar ko'rsatilmagan nomlari_to и qiymatlari_to Ularning ismlari qo'shtirnoq ichida ko'rsatilishi kerak.
Yangi kontseptsiya bilan ishlashga qanday o'tishni eng oson tushunishga yordam beradigan jadval tartibli.
Muallifdan eslatma
Quyidagi to'liq matn moslashtirilgan, hatto bepul tarjima deyman tidyverse kutubxonasining rasmiy veb-saytidan.
Ma'lumotlarni keng formatdan uzoq formatga o'tkazishning oddiy misoli
pivot_longer () — ustunlar sonini kamaytirish va qatorlar sonini ko‘paytirish orqali ma’lumotlar to‘plamini uzunroq qiladi.
Ushbu maqolada keltirilgan misollarni ishga tushirish uchun avvalo kerakli paketlarni ulashingiz kerak:
library(tidyr)
library(dplyr)
library(readr)Aytaylik, bizda (boshqa narsalar qatorida) odamlardan ularning dini va yillik daromadlari haqida so'rovnoma natijalari bilan jadval mavjud:
#> # A tibble: 18 x 11
#> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Agnostic 27 34 60 81 76 137
#> 2 Atheist 12 27 37 52 35 70
#> 3 Buddhist 27 21 30 34 33 58
#> 4 Catholic 418 617 732 670 638 1116
#> 5 Don’t k… 15 14 15 11 10 35
#> 6 Evangel… 575 869 1064 982 881 1486
#> 7 Hindu 1 9 7 9 11 34
#> 8 Histori… 228 244 236 238 197 223
#> 9 Jehovah… 20 27 24 24 21 30
#> 10 Jewish 19 19 25 25 30 95
#> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>,
#> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>Ushbu jadvalda respondentlarning diniy ma'lumotlari qatorlar bo'yicha, daromad darajasi ustun nomlari bo'yicha tarqalgan. Har bir toifadagi respondentlar soni din va daromad darajasining kesishmasidagi hujayra qiymatlarida saqlanadi. Jadvalni toza, to'g'ri formatda tartibga solish uchun shunchaki foydalaning pivot_longer():
pew %>%
pivot_longer(cols = -religion, names_to = "income", values_to = "count")pew %>%
pivot_longer(cols = -religion, names_to = "income", values_to = "count")
#> # A tibble: 180 x 3
#> religion income count
#> <chr> <chr> <dbl>
#> 1 Agnostic <$10k 27
#> 2 Agnostic $10-20k 34
#> 3 Agnostic $20-30k 60
#> 4 Agnostic $30-40k 81
#> 5 Agnostic $40-50k 76
#> 6 Agnostic $50-75k 137
#> 7 Agnostic $75-100k 122
#> 8 Agnostic $100-150k 109
#> 9 Agnostic >150k 84
#> 10 Agnostic Don't know/refused 96
#> # … with 170 more rowsFunktsiya argumentlari pivot_longer()
- Birinchi dalil yoqalar, qaysi ustunlarni birlashtirish kerakligini tasvirlaydi. Bunday holda, barcha ustunlar bundan mustasno vaqt.
- dalil nomlari_to biz birlashtirgan ustunlar nomlaridan yaratiladigan o'zgaruvchining nomini beradi.
- qiymatlari_to birlashtirilgan ustunlarning hujayra qiymatlarida saqlanadigan ma'lumotlardan yaratiladigan o'zgaruvchining nomini beradi.
Texnik xususiyatlari
Bu paketning yangi xususiyati. tartibli, bu eski funksiyalar bilan ishlashda ilgari mavjud bo'lmagan.
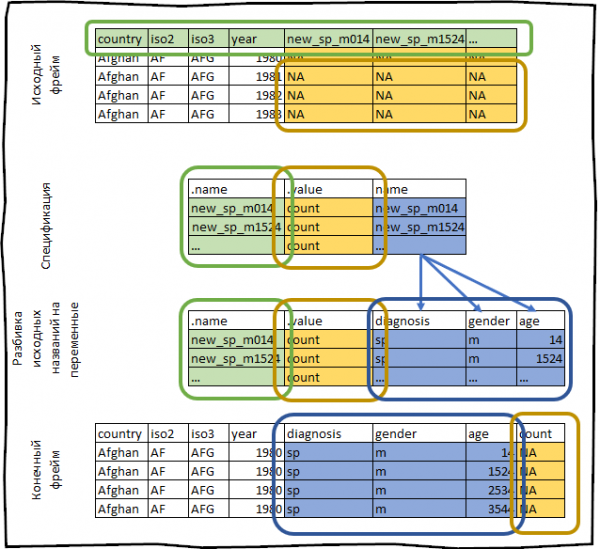
Spetsifikatsiya ma'lumotlar ramkasi bo'lib, uning har bir satri yangi chiqish ma'lumotlari ramkasidagi bitta ustunga va ikkita maxsus ustunga to'g'ri keladi:
- .Tashkilot nomi asl ustun nomini o'z ichiga oladi.
- .qiymat hujayra qiymatlarini o'z ichiga olgan ustun nomini o'z ichiga oladi.
Spetsifikatsiyaning qolgan ustunlari siqilgan ustunlar nomi yangi ustunda qanday ko'rsatilishini aks ettiradi .Tashkilot nomi.
Spetsifikatsiya ustun nomida saqlangan metamaʼlumotlarni tavsiflaydi, har bir ustun uchun bitta satr va har bir oʻzgaruvchi uchun bitta ustun ustun nomi bilan birlashtiriladi, bu hozir chalkash tuyulishi mumkin, biroq bir nechta misollarni koʻrib chiqqandan soʻng u yanada aniqroq boʻladi.
Spetsifikatsiyaning mohiyati shundaki, siz o'zgartirilayotgan dataframe uchun yangi metama'lumotlarni ajratib olishingiz, o'zgartirishingiz va o'rnatishingiz mumkin.
Jadvalni keng formatdan uzun formatga o'tkazishda spetsifikatsiyalar bilan ishlash uchun funksiyadan foydalaning pivot_longer_spec().
Ushbu funktsiya qanday ishlaydi, u har qanday ma'lumot ramkasini oladi va yuqorida tavsiflangan tarzda o'zining metama'lumotlarini yaratadi.
Misol tariqasida paket bilan birga kelgan who ma'lumotlar to'plamini olaylik. tartibliUshbu ma'lumotlar to'plami Jahon sog'liqni saqlash tashkiloti tomonidan taqdim etilgan sil kasalligi bo'yicha ma'lumotlarni o'z ichiga oladi.
who
#> # A tibble: 7,240 x 60
#> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534
#> <chr> <chr> <chr> <int> <int> <int> <int>
#> 1 Afghan… AF AFG 1980 NA NA NA
#> 2 Afghan… AF AFG 1981 NA NA NA
#> 3 Afghan… AF AFG 1982 NA NA NA
#> 4 Afghan… AF AFG 1983 NA NA NA
#> 5 Afghan… AF AFG 1984 NA NA NA
#> 6 Afghan… AF AFG 1985 NA NA NA
#> 7 Afghan… AF AFG 1986 NA NA NA
#> 8 Afghan… AF AFG 1987 NA NA NA
#> 9 Afghan… AF AFG 1988 NA NA NA
#> 10 Afghan… AF AFG 1989 NA NA NA
#> # … with 7,230 more rows, and 53 more variablesKeling, uning spetsifikatsiyasini tuzamiz.
spec <- who %>%
pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")#> # A tibble: 56 x 3
#> .name .value name
#> <chr> <chr> <chr>
#> 1 new_sp_m014 count new_sp_m014
#> 2 new_sp_m1524 count new_sp_m1524
#> 3 new_sp_m2534 count new_sp_m2534
#> 4 new_sp_m3544 count new_sp_m3544
#> 5 new_sp_m4554 count new_sp_m4554
#> 6 new_sp_m5564 count new_sp_m5564
#> 7 new_sp_m65 count new_sp_m65
#> 8 new_sp_f014 count new_sp_f014
#> 9 new_sp_f1524 count new_sp_f1524
#> 10 new_sp_f2534 count new_sp_f2534
#> # … with 46 more rowssohalar mamlakat, isoxnumx, isoxnumx allaqachon o'zgaruvchilardir. Bizning vazifamiz ustunlarni teskari aylantirishdir new_sp_m014 haqida newrel_f65.
Ushbu ustunlar nomlarida quyidagi ma'lumotlar saqlanadi:
- Prefiks
new_ustunda sil kasalligining yangi holatlari to'g'risidagi ma'lumotlar mavjudligini ko'rsatadi; joriy ma'lumotlar ramkasi faqat yangi holatlar haqida ma'lumotni o'z ichiga oladi, shuning uchun bu prefiks joriy kontekstda hech qanday semantik ma'noga ega emas. sp/rel/sp/epkasallikni aniqlash usulini tavsiflaydi.m/fbemorning jinsi.014/1524/2535/3544/4554/65bemorning yosh oralig'i.
Funktsiyadan foydalanib, bu ustunlarni ajratishimiz mumkin extract(), muntazam ifoda yordamida.
spec <- spec %>%
extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")#> # A tibble: 56 x 5
#> .name .value diagnosis gender age
#> <chr> <chr> <chr> <chr> <chr>
#> 1 new_sp_m014 count sp m 014
#> 2 new_sp_m1524 count sp m 1524
#> 3 new_sp_m2534 count sp m 2534
#> 4 new_sp_m3544 count sp m 3544
#> 5 new_sp_m4554 count sp m 4554
#> 6 new_sp_m5564 count sp m 5564
#> 7 new_sp_m65 count sp m 65
#> 8 new_sp_f014 count sp f 014
#> 9 new_sp_f1524 count sp f 1524
#> 10 new_sp_f2534 count sp f 2534
#> # … with 46 more rowsIltimos, ustunga e'tibor bering .Tashkilot nomi o'zgarishsiz qolishi kerak, chunki bu bizning asl ma'lumotlar to'plamining ustun nomlaridagi indeksimiz.
Jins va yosh (ustunlar jinsi и yosh) qat'iy va ma'lum qiymatlarga ega, shuning uchun bu ustunlarni omillarga aylantirish tavsiya etiladi:
spec <- spec %>%
mutate(
gender = factor(gender, levels = c("f", "m")),
age = factor(age, levels = unique(age), ordered = TRUE)
) Nihoyat, biz yaratgan spetsifikatsiyani asl ma'lumotlar ramkasiga qo'llash uchun kim argumentdan foydalanishimiz kerak spec funktsiyada pivot_longer().
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8
#> country iso2 iso3 year diagnosis gender age count
#> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int>
#> 1 Afghanistan AF AFG 1980 sp m 014 NA
#> 2 Afghanistan AF AFG 1980 sp m 1524 NA
#> 3 Afghanistan AF AFG 1980 sp m 2534 NA
#> 4 Afghanistan AF AFG 1980 sp m 3544 NA
#> 5 Afghanistan AF AFG 1980 sp m 4554 NA
#> 6 Afghanistan AF AFG 1980 sp m 5564 NA
#> 7 Afghanistan AF AFG 1980 sp m 65 NA
#> 8 Afghanistan AF AFG 1980 sp f 014 NA
#> 9 Afghanistan AF AFG 1980 sp f 1524 NA
#> 10 Afghanistan AF AFG 1980 sp f 2534 NA
#> # … with 405,430 more rowsBiz qilgan barcha ishlarni sxematik tarzda quyidagicha tasvirlash mumkin:
Bir nechta qiymatlardan foydalangan holda spetsifikatsiya (.value)
Yuqoridagi misolda spetsifikatsiya ustuni .qiymat faqat bitta qiymatni o'z ichiga olgan, aksariyat hollarda shunday bo'ladi.
Ammo vaqti-vaqti bilan siz ustunlardagi qiymatlarni turli xil ma'lumotlar turlari bilan birlashtirishingiz kerak bo'lishi mumkin. Eskirgan funksiyadan foydalanish spread() Buni qilish ancha qiyin bo'lardi.
Quyidagi misol dan olingan paketga ma'lumotlar jadvali.
Keling, o'quv ma'lumotlar ramkasini yarataylik.
family <- tibble::tribble(
~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2,
1L, "1998-11-26", "2000-01-29", 1L, 2L,
2L, "1996-06-22", NA, 2L, NA,
3L, "2002-07-11", "2004-04-05", 2L, 2L,
4L, "2004-10-10", "2009-08-27", 1L, 1L,
5L, "2000-12-05", "2005-02-28", 2L, 1L,
)
family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)#> # A tibble: 5 x 5
#> family dob_child1 dob_child2 gender_child1 gender_child2
#> <int> <date> <date> <int> <int>
#> 1 1 1998-11-26 2000-01-29 1 2
#> 2 2 1996-06-22 NA 2 NA
#> 3 3 2002-07-11 2004-04-05 2 2
#> 4 4 2004-10-10 2009-08-27 1 1
#> 5 5 2000-12-05 2005-02-28 2 1Yaratilgan ma'lumotlar ramkasi bitta oilaning har bir qatoridagi bolalar haqidagi ma'lumotlarni o'z ichiga oladi. Oilalar bir yoki ikki farzandli bo'lishi mumkin. Har bir bola uchun tug'ilgan sana va jinsi ko'rsatilgan, har bir bola uchun ma'lumotlar alohida ustunlarda keltirilgan. Bizning vazifamiz ushbu ma'lumotlarni tahlil qilish uchun to'g'ri formatlashdir.
E'tibor bering, bizda har bir bola haqida ma'lumotga ega ikkita o'zgaruvchi mavjud: ularning jinsi va tug'ilgan sanasi (prefiksli ustunlar) dop tug'ilgan sana, prefiksli ustunlar mavjud jinsi bolaning jinsini o'z ichiga oladi). Kutilgan natijada ular alohida ustunlarga o'tishlari kerak. Buni ustun joylashgan spetsifikatsiyani yaratish orqali amalga oshirishimiz mumkin .value ikki xil ma'noga ega bo'ladi.
spec <- family %>%
pivot_longer_spec(-family) %>%
separate(col = name, into = c(".value", "child"))%>%
mutate(child = parse_number(child))
#> # A tibble: 4 x 3
#> .name .value child
#> <chr> <chr> <dbl>
#> 1 dob_child1 dob 1
#> 2 dob_child2 dob 2
#> 3 gender_child1 gender 1
#> 4 gender_child2 gender 2Shunday qilib, keling, yuqoridagi kod bajaradigan qadamlarni ajratamiz.
pivot_longer_spec(-family)— biz oila ustunidan tashqari barcha mavjud ustunlarni siqib chiqaradigan spetsifikatsiyani yaratamiz.separate(col = name, into = c(".value", "child"))- ustunni ajrating .Tashkilot nomi, unda pastki chiziq bilan ajratilgan manba maydonlarining nomlari mavjud va biz olingan qiymatlarni ustunlarga kiritamiz .qiymat и Bola.mutate(child = parse_number(child))- maydon qiymatlarini o'zgartirish Bola matndan raqamli ma'lumotlar turiga.
Endi biz olingan spetsifikatsiyani asl dataframega qo'llashimiz va jadvalni kerakli shaklga keltirishimiz mumkin.
family %>%
pivot_longer(spec = spec, na.rm = T)#> # A tibble: 9 x 4
#> family child dob gender
#> <int> <dbl> <date> <int>
#> 1 1 1 1998-11-26 1
#> 2 1 2 2000-01-29 2
#> 3 2 1 1996-06-22 2
#> 4 3 1 2002-07-11 2
#> 5 3 2 2004-04-05 2
#> 6 4 1 2004-10-10 1
#> 7 4 2 2009-08-27 1
#> 8 5 1 2000-12-05 2
#> 9 5 2 2005-02-28 1Biz argumentdan foydalanamiz na.rm = TRUE, chunki joriy ma'lumotlar formati mavjud bo'lmagan kuzatishlar uchun qo'shimcha qatorlar yaratishga majbur qiladi. 2-oilada faqat bitta farzand bor ekan, na.rm = TRUE 2-oila chiqishda bitta qatorga ega bo'lishini ta'minlaydi.
Ma'lumotlar ramkalarini uzun formatdan keng formatga o'tkazish
pivot_wider() — bu teskari transformatsiyadir va aksincha qatorlar sonini kamaytirish orqali maʼlumotlar ramkasining ustunlar sonini oshiradi.
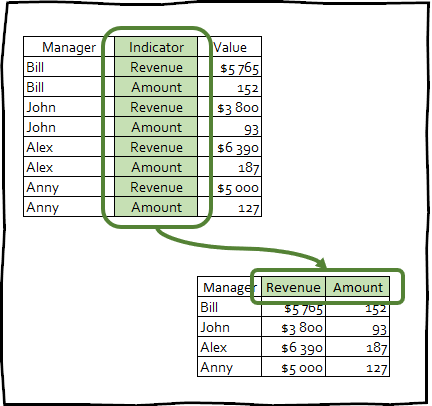
Ushbu turdagi transformatsiya ma'lumotlarni toza shaklga keltirish uchun juda kamdan-kam qo'llaniladi; ammo, bu usul taqdimotlarda ishlatiladigan pivot jadvallarini yaratish yoki boshqa vositalar bilan integratsiya qilish uchun foydali bo'lishi mumkin.
Aslida, funktsiyalar pivot_longer() и pivot_wider() nosimmetrikdir va bir-biriga qarama-qarshi harakatlar hosil qiladi, ya'ni: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) и df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) asl df ni qaytaradi.
Jadvalni keng formatga o'tkazishning eng oddiy misoli
Funktsiya qanday ishlashini ko'rsatish uchun pivot_wider() ma'lumotlar to'plamidan foydalanamiz baliq_uchrashuvlari, bu turli stantsiyalar daryo bo'ylab baliqlarning harakatini qanday qayd etishi haqidagi ma'lumotlarni saqlaydi.
#> # A tibble: 114 x 3
#> fish station seen
#> <fct> <fct> <int>
#> 1 4842 Release 1
#> 2 4842 I80_1 1
#> 3 4842 Lisbon 1
#> 4 4842 Rstr 1
#> 5 4842 Base_TD 1
#> 6 4842 BCE 1
#> 7 4842 BCW 1
#> 8 4842 BCE2 1
#> 9 4842 BCW2 1
#> 10 4842 MAE 1
#> # … with 104 more rowsKo'pgina hollarda, agar siz har bir stantsiya uchun ma'lumotni alohida ustunda taqdim etsangiz, ushbu jadval yanada ma'lumotli bo'ladi va undan foydalanish osonroq bo'ladi.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
#> # A tibble: 19 x 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE
#> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
#> 1 4842 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 NA NA NA NA NA
#> 5 4847 1 1 1 NA NA NA NA NA NA NA
#> 6 4848 1 1 1 1 NA NA NA NA NA NA
#> 7 4849 1 1 NA NA NA NA NA NA NA NA
#> 8 4850 1 1 NA 1 1 1 1 NA NA NA
#> 9 4851 1 1 NA NA NA NA NA NA NA NA
#> 10 4854 1 1 NA NA NA NA NA NA NA NA
#> # … with 9 more rows, and 1 more variable: MAW <int>Ushbu ma'lumotlar to'plami faqat stansiya tomonidan baliq aniqlanganda ma'lumotlarni yozib oladi. Agar baliq stansiya tomonidan aniqlanmagan bo'lsa, jadvalda bu ma'lumotlar bo'lmaydi. Bu shuni anglatadiki, chiqish NA bilan to'ldiriladi.
Biroq, bu holatda biz bilamizki, rekordning yo'qligi baliq ko'rilmaganligini anglatadi, shuning uchun biz argumentdan foydalanishimiz mumkin. qadriyatlarni_to'ldirish funktsiyada pivot_wider() va ushbu etishmayotgan qiymatlarni nol bilan to'ldiring:
fish_encounters %>% pivot_wider(
names_from = station,
values_from = seen,
values_fill = list(seen = 0)
)#> # A tibble: 19 x 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE
#> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
#> 1 4842 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 0 0 0 0 0
#> 5 4847 1 1 1 0 0 0 0 0 0 0
#> 6 4848 1 1 1 1 0 0 0 0 0 0
#> 7 4849 1 1 0 0 0 0 0 0 0 0
#> 8 4850 1 1 0 1 1 1 1 0 0 0
#> 9 4851 1 1 0 0 0 0 0 0 0 0
#> 10 4854 1 1 0 0 0 0 0 0 0 0
#> # … with 9 more rows, and 1 more variable: MAW <int>Bir nechta manba o'zgaruvchilardan ustun nomini yaratish
Tasavvur qiling, bizda mahsulot, mamlakat va yil kombinatsiyasini o'z ichiga olgan jadval mavjud. Sinov ma'lumotlari ramkasini yaratish uchun biz quyidagi kodni ishga tushirishimiz mumkin:
df <- expand_grid(
product = c("A", "B"),
country = c("AI", "EI"),
year = 2000:2014
) %>%
filter((product == "A" & country == "AI") | product == "B") %>%
mutate(value = rnorm(nrow(.)))#> # A tibble: 45 x 4
#> product country year value
#> <chr> <chr> <int> <dbl>
#> 1 A AI 2000 -2.05
#> 2 A AI 2001 -0.676
#> 3 A AI 2002 1.60
#> 4 A AI 2003 -0.353
#> 5 A AI 2004 -0.00530
#> 6 A AI 2005 0.442
#> 7 A AI 2006 -0.610
#> 8 A AI 2007 -2.77
#> 9 A AI 2008 0.899
#> 10 A AI 2009 -0.106
#> # … with 35 more rowsMaqsadimiz bitta ustunda har bir mahsulot va mamlakat kombinatsiyasi uchun ma'lumotlar bo'lishi uchun ma'lumotlar doirasini kengaytirishdir. Buning uchun oddiygina argumentga o'ting nomlari_dan birlashtiriladigan maydonlar nomlarini o'z ichiga olgan vektor.
df %>% pivot_wider(names_from = c(product, country),
values_from = "value")#> # A tibble: 15 x 4
#> year A_AI B_AI B_EI
#> <int> <dbl> <dbl> <dbl>
#> 1 2000 -2.05 0.607 1.20
#> 2 2001 -0.676 1.65 -0.114
#> 3 2002 1.60 -0.0245 0.501
#> 4 2003 -0.353 1.30 -0.459
#> 5 2004 -0.00530 0.921 -0.0589
#> 6 2005 0.442 -1.55 0.594
#> 7 2006 -0.610 0.380 -1.28
#> 8 2007 -2.77 0.830 0.637
#> 9 2008 0.899 0.0175 -1.30
#> 10 2009 -0.106 -0.195 1.03
#> # … with 5 more rowsFunktsiyaga spetsifikatsiyalarni ham qo'llashingiz mumkin. pivot_wider()Lekin murojaat qilganda pivot_wider() spetsifikatsiya teskari transformatsiyani amalga oshiradi pivot_longer(): da ko'rsatilgan ustunlar yaratiladi .Tashkilot nomidan qiymatlardan foydalanish .qiymat va boshqa ustunlar.
Ushbu ma'lumotlar to'plami uchun siz har bir mumkin bo'lgan mamlakat va mahsulot kombinatsiyasi faqat ma'lumotlarda mavjud bo'lganlar emas, balki o'z ustuniga ega bo'lishini istasangiz, maxsus spetsifikatsiyani yaratishingiz mumkin:
spec <- df %>%
expand(product, country, .value = "value") %>%
unite(".name", product, country, remove = FALSE)#> # A tibble: 4 x 4
#> .name product country .value
#> <chr> <chr> <chr> <chr>
#> 1 A_AI A AI value
#> 2 A_EI A EI value
#> 3 B_AI B AI value
#> 4 B_EI B EI valuedf %>% pivot_wider(spec = spec) %>% head()#> # A tibble: 6 x 5
#> year A_AI A_EI B_AI B_EI
#> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 2000 -2.05 NA 0.607 1.20
#> 2 2001 -0.676 NA 1.65 -0.114
#> 3 2002 1.60 NA -0.0245 0.501
#> 4 2003 -0.353 NA 1.30 -0.459
#> 5 2004 -0.00530 NA 0.921 -0.0589
#> 6 2005 0.442 NA -1.55 0.594Yangi tidyr kontseptsiyasi bilan ishlashning ba'zi ilg'or misollari
Ma'lumotlarni to'g'rilash: AQShda aholini ro'yxatga olish bo'yicha daromadlar va ijara ma'lumotlar to'plamini o'rganish
Maʼlumotlar toʻplami us_rent_daromed 2017 yil uchun AQShdagi har bir shtat uchun o'rtacha daromad va ijara haqidagi ma'lumotlarni o'z ichiga oladi (ma'lumotlar to'plami paketda mavjud ro'yxatga olish).
us_rent_income
#> # A tibble: 104 x 5
#> GEOID NAME variable estimate moe
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 01 Alabama income 24476 136
#> 2 01 Alabama rent 747 3
#> 3 02 Alaska income 32940 508
#> 4 02 Alaska rent 1200 13
#> 5 04 Arizona income 27517 148
#> 6 04 Arizona rent 972 4
#> 7 05 Arkansas income 23789 165
#> 8 05 Arkansas rent 709 5
#> 9 06 California income 29454 109
#> 10 06 California rent 1358 3
#> # … with 94 more rowsMa'lumotlar to'plamida ma'lumotlar saqlanadigan shaklda us_rent_daromed Ular bilan ishlash juda noqulay, shuning uchun biz ustunlar bilan ma'lumotlar to'plamini yaratmoqchimiz: ijara, rent_moe, kelib, daromad_moeUshbu spetsifikatsiyani yaratishning ko'plab usullari mavjud, ammo asosiysi biz o'zgaruvchan qiymatlarning har bir kombinatsiyasini yaratishimiz kerak. taxmin/moe, va keyin ustun nomini yarating.
spec <- us_rent_income %>%
expand(variable, .value = c("estimate", "moe")) %>%
mutate(
.name = paste0(variable, ifelse(.value == "moe", "_moe", ""))
)#> # A tibble: 4 x 3
#> variable .value .name
#> <chr> <chr> <chr>
#> 1 income estimate income
#> 2 income moe income_moe
#> 3 rent estimate rent
#> 4 rent moe rent_moeUshbu spetsifikatsiyani taqdim etish pivot_wider() Biz izlayotgan natijani beradi:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6
#> GEOID NAME income income_moe rent rent_moe
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 01 Alabama 24476 136 747 3
#> 2 02 Alaska 32940 508 1200 13
#> 3 04 Arizona 27517 148 972 4
#> 4 05 Arkansas 23789 165 709 5
#> 5 06 California 29454 109 1358 3
#> 6 08 Colorado 32401 109 1125 5
#> 7 09 Connecticut 35326 195 1123 5
#> 8 10 Delaware 31560 247 1076 10
#> 9 11 District of Columbia 43198 681 1424 17
#> 10 12 Florida 25952 70 1077 3
#> # … with 42 more rowsJahon banki
Ba'zan kerakli shaklga ma'lumotlar to'plamini olish bir necha bosqichlarni talab qiladi.
Maʼlumotlar toʻplami world_bank_pop Jahon bankining 2000-2018 yillardagi har bir mamlakat aholisi haqidagi maʼlumotlarini oʻz ichiga oladi.
#> # A tibble: 1,056 x 20
#> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006`
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4
#> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2
#> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5
#> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1
#> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6
#> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0
#> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7
#> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0
#> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7
#> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0
#> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>,
#> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>,
#> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>Bizning maqsadimiz har bir o'zgaruvchi alohida ustunda joylashgan aniq ma'lumotlar to'plamini yaratishdir. Aynan qanday qadamlar talab qilinishi aniq emas, lekin biz eng aniq muammodan boshlaymiz: yil bir nechta ustunlar bo'ylab taqsimlanadi.
Buni tuzatish uchun siz funktsiyadan foydalanishingiz kerak pivot_longer().
pop2 <- world_bank_pop %>%
pivot_longer(`2000`:`2017`, names_to = "year")#> # A tibble: 19,008 x 4
#> country indicator year value
#> <chr> <chr> <chr> <dbl>
#> 1 ABW SP.URB.TOTL 2000 42444
#> 2 ABW SP.URB.TOTL 2001 43048
#> 3 ABW SP.URB.TOTL 2002 43670
#> 4 ABW SP.URB.TOTL 2003 44246
#> 5 ABW SP.URB.TOTL 2004 44669
#> 6 ABW SP.URB.TOTL 2005 44889
#> 7 ABW SP.URB.TOTL 2006 44881
#> 8 ABW SP.URB.TOTL 2007 44686
#> 9 ABW SP.URB.TOTL 2008 44375
#> 10 ABW SP.URB.TOTL 2009 44052
#> # … with 18,998 more rowsKeyingi qadam indikator o'zgaruvchisiga qarashdir.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2
#> indicator n
#> <chr> <int>
#> 1 SP.POP.GROW 4752
#> 2 SP.POP.TOTL 4752
#> 3 SP.URB.GROW 4752
#> 4 SP.URB.TOTL 4752Bu erda SP.POP.GROW aholining o'sishi, SP.POP.TOTL umumiy aholi soni va SP.URB.* bir xil, ammo shaharlar uchun. Keling, ushbu qiymatlarni ikkita o'zgaruvchiga ajratamiz: maydon (jami yoki shahar) va haqiqiy ma'lumotlarni o'z ichiga olgan o'zgaruvchi (aholi yoki o'sish):
pop3 <- pop2 %>%
separate(indicator, c(NA, "area", "variable"))#> # A tibble: 19,008 x 5
#> country area variable year value
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 ABW URB TOTL 2000 42444
#> 2 ABW URB TOTL 2001 43048
#> 3 ABW URB TOTL 2002 43670
#> 4 ABW URB TOTL 2003 44246
#> 5 ABW URB TOTL 2004 44669
#> 6 ABW URB TOTL 2005 44889
#> 7 ABW URB TOTL 2006 44881
#> 8 ABW URB TOTL 2007 44686
#> 9 ABW URB TOTL 2008 44375
#> 10 ABW URB TOTL 2009 44052
#> # … with 18,998 more rowsEndi biz qilishimiz kerak bo'lgan yagona narsa o'zgaruvchini ikkita ustunga bo'lishdir:
pop3 %>%
pivot_wider(names_from = variable, values_from = value)#> # A tibble: 9,504 x 5
#> country area year TOTL GROW
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 ABW URB 2000 42444 1.18
#> 2 ABW URB 2001 43048 1.41
#> 3 ABW URB 2002 43670 1.43
#> 4 ABW URB 2003 44246 1.31
#> 5 ABW URB 2004 44669 0.951
#> 6 ABW URB 2005 44889 0.491
#> 7 ABW URB 2006 44881 -0.0178
#> 8 ABW URB 2007 44686 -0.435
#> 9 ABW URB 2008 44375 -0.698
#> 10 ABW URB 2009 44052 -0.731
#> # … with 9,494 more rowsKontaktlar ro'yxati
Oxirgi misol, sizda veb-saytdan nusxa ko'chirgan va qo'ygan kontaktlar ro'yxati borligini tasavvur qiling:
contacts <- tribble(
~field, ~value,
"name", "Jiena McLellan",
"company", "Toyota",
"name", "John Smith",
"company", "google",
"email", "john@google.com",
"name", "Huxley Ratcliffe"
)Ushbu ro'yxatni jadvalga aylantirish juda qiyin, chunki qaysi ma'lumotlar qaysi kontaktga tegishli ekanligini aniqlaydigan o'zgaruvchi yo'q. Buni har bir yangi kontakt uchun ma'lumotlar nomdan boshlanishini ta'kidlash orqali tuzatishimiz mumkin, shuning uchun biz noyob identifikator yaratishimiz va maydon ustunida "nom" qiymati har safar paydo bo'lganda uni bittaga oshirishimiz mumkin:
contacts <- contacts %>%
mutate(
person_id = cumsum(field == "name")
)
contacts#> # A tibble: 6 x 3
#> field value person_id
#> <chr> <chr> <int>
#> 1 name Jiena McLellan 1
#> 2 company Toyota 1
#> 3 name John Smith 2
#> 4 company google 2
#> 5 email john@google.com 2
#> 6 name Huxley Ratcliffe 3Endi bizda har bir kontakt uchun noyob identifikator bor, biz maydon va qiymatni ustunlarga aylantirishimiz mumkin:
contacts %>%
pivot_wider(names_from = field, values_from = value)#> # A tibble: 3 x 4
#> person_id name company email
#> <int> <chr> <chr> <chr>
#> 1 1 Jiena McLellan Toyota <NA>
#> 2 2 John Smith google john@google.com
#> 3 3 Huxley Ratcliffe <NA> <NA>xulosa
Mening shaxsiy fikrim shuki, yangi kontseptsiya tartibli Bu haqiqatan ham intuitivroq va eskirgan funktsiyalardan sezilarli darajada ustundir. spread() и gather()Umid qilamanki, ushbu maqola sizga tushunishga yordam berdi pivot_longer() и pivot_wider().
Manba: www.habr.com
