

Trước khi bắt đầu khóa học đã chuẩn bị cho bạn một bản dịch của một tài liệu hữu ích khác.
Mã hóa Huffman là một thuật toán nén dữ liệu hình thành ý tưởng cơ bản về nén tệp. Trong bài viết này, chúng ta sẽ nói về mã hóa có độ dài cố định và thay đổi, mã có thể giải mã duy nhất, quy tắc tiền tố và xây dựng cây Huffman.
Chúng tôi biết rằng mỗi ký tự được lưu trữ dưới dạng một chuỗi 0 và 1 và chiếm 8 bit. Đây được gọi là mã hóa độ dài cố định vì mỗi ký tự sử dụng cùng một số bit cố định để lưu trữ.
Giả sử chúng ta được cung cấp văn bản. Làm cách nào chúng tôi có thể giảm dung lượng cần thiết để lưu trữ một ký tự?
Ý tưởng chính là mã hóa độ dài thay đổi. Chúng ta có thể sử dụng thực tế là một số ký tự trong văn bản xuất hiện thường xuyên hơn những ký tự khác () để phát triển một thuật toán sẽ biểu diễn cùng một chuỗi ký tự trong ít bit hơn. Trong mã hóa độ dài thay đổi, chúng tôi gán cho các ký tự một số lượng bit thay đổi, tùy thuộc vào tần suất chúng xuất hiện trong một văn bản nhất định. Cuối cùng, một số ký tự có thể mất ít nhất là 1 bit, trong khi những ký tự khác có thể mất 2 bit, 3 hoặc nhiều hơn. Vấn đề với mã hóa độ dài thay đổi chỉ là giải mã tiếp theo của chuỗi.
Làm thế nào, khi biết chuỗi bit, giải mã nó một cách rõ ràng?
Xem xét dòng "abcdab". Nó có 8 ký tự và khi mã hóa một độ dài cố định, nó sẽ cần 64 bit để lưu trữ. Lưu ý rằng tần số ký hiệu "a", "b", "c" и "NS" lần lượt bằng 4, 2, 1, 1. Hãy thử tưởng tượng "abcdab" ít bit hơn, sử dụng thực tế là "đến" xảy ra thường xuyên hơn "NS"Và "NS" xảy ra thường xuyên hơn "c" и "NS". Hãy bắt đầu bằng cách viết mã "đến" với một bit bằng 0, "NS" chúng tôi sẽ gán mã hai bit 11 và sử dụng ba bit 100 và 011, chúng tôi sẽ mã hóa "c" и "NS".
Kết quả là, chúng ta sẽ nhận được:
a
0
b
11
c
100
d
011
Vì vậy, dòng "abcdab" chúng tôi sẽ mã hóa như 00110100011011 (0|0|11|0|100|011|0|11)sử dụng các mã trên. Tuy nhiên, vấn đề chính sẽ nằm ở việc giải mã. Khi chúng tôi cố gắng giải mã chuỗi 00110100011011, chúng tôi nhận được một kết quả mơ hồ, vì nó có thể được biểu diễn dưới dạng:
0|011|0|100|011|0|11 adacdab
0|0|11|0|100|0|11|011 aabacabd
0|011|0|100|0|11|0|11 adacabab
...
vv
Để tránh sự mơ hồ này, chúng tôi phải đảm bảo rằng mã hóa của chúng tôi đáp ứng một khái niệm như quy tắc tiền tố, điều này ngụ ý rằng các mã chỉ có thể được giải mã theo một cách duy nhất. Quy tắc tiền tố đảm bảo rằng không có mã nào là tiền tố của mã khác. Theo mã, chúng tôi muốn nói đến các bit được sử dụng để biểu thị một ký tự cụ thể. Trong ví dụ trên 0 là tiền tố 011, vi phạm quy tắc tiền tố. Vì vậy, nếu mã của chúng tôi đáp ứng quy tắc tiền tố, thì chúng tôi có thể giải mã duy nhất (và ngược lại).
Hãy xem lại ví dụ trên. Lần này chúng ta sẽ gán cho các ký hiệu "a", "b", "c" и "NS" mã thỏa mãn quy tắc tiền tố.
a
0
b
10
c
110
d
111
Với mã hóa này, chuỗi "abcdab" sẽ được mã hóa thành 00100100011010 (0|0|10|0|100|011|0|10). Tuy nhiên, 00100100011010 chúng tôi đã có thể giải mã rõ ràng và quay lại chuỗi ban đầu của mình "abcdab".
Mã hóa Huffman
Bây giờ chúng ta đã xử lý mã hóa có độ dài thay đổi và quy tắc tiền tố, hãy nói về mã hóa Huffman.
Phương pháp này dựa trên việc tạo ra các cây nhị phân. Trong đó, nút có thể là cuối cùng hoặc bên trong. Ban đầu, tất cả các nút được coi là lá (thiết bị đầu cuối), đại diện cho chính biểu tượng và trọng số của nó (tức là tần suất xuất hiện). Các nút bên trong chứa trọng số của ký tự và đề cập đến hai nút con cháu. Theo thỏa thuận chung, bit «0» đại diện theo nhánh trái, và «1» - Phía bên phải. trong cây đầy đủ N lá và N-1 các nút bên trong. Khuyến nghị rằng khi xây dựng cây Huffman, các ký hiệu không sử dụng sẽ bị loại bỏ để có được mã có độ dài tối ưu.
Chúng tôi sẽ sử dụng hàng đợi ưu tiên để xây dựng cây Huffman, trong đó nút có tần suất thấp nhất sẽ được ưu tiên cao nhất. Các bước xây dựng được mô tả dưới đây:
- Tạo một nút lá cho mỗi ký tự và thêm chúng vào hàng đợi ưu tiên.
- Trong khi có nhiều trang tính trong hàng đợi, hãy làm như sau:
- Xóa hai nút có mức ưu tiên cao nhất (tần suất thấp nhất) khỏi hàng đợi;
- Tạo một nút bên trong mới, trong đó hai nút này sẽ là nút con và tần suất xuất hiện sẽ bằng tổng tần số của hai nút này.
- Thêm một nút mới vào hàng đợi ưu tiên.
- Nút duy nhất còn lại sẽ là gốc và điều này sẽ hoàn thành việc xây dựng cây.
Hãy tưởng tượng rằng chúng ta có một số văn bản chỉ bao gồm các ký tự "A B C D" и "và", và tần suất xuất hiện của chúng lần lượt là 15, 7, 6, 6 và 5. Dưới đây là hình minh họa phản ánh các bước của thuật toán.
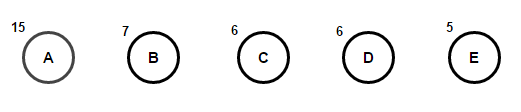
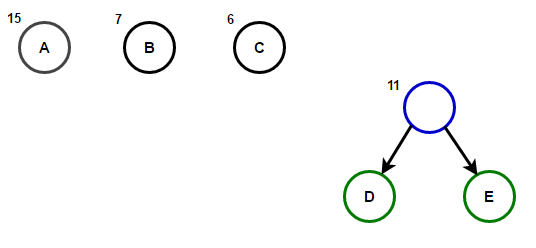
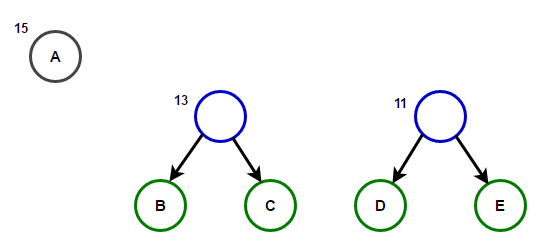
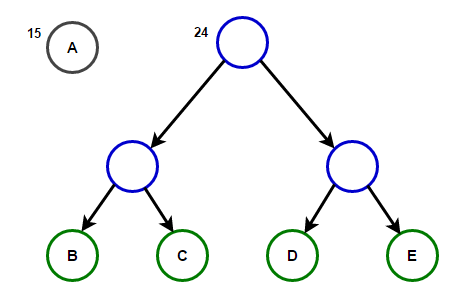
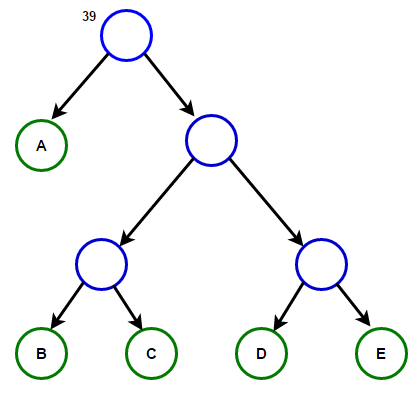
Một đường dẫn từ gốc đến bất kỳ nút cuối nào sẽ lưu trữ mã tiền tố tối ưu (còn được gọi là mã Huffman) tương ứng với ký tự được liên kết với nút cuối đó.
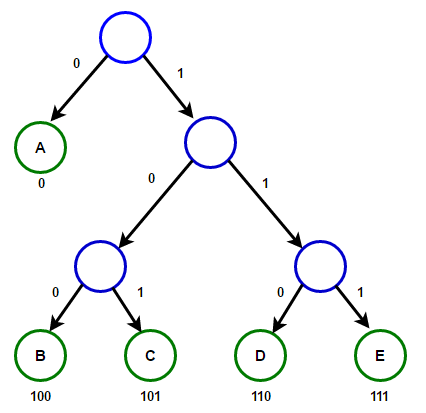
cây huffman
Dưới đây bạn sẽ tìm thấy cách triển khai thuật toán nén Huffman trong C++ và Java:
#include <iostream>
#include <string>
#include <queue>
#include <unordered_map>
using namespace std;
// A Tree node
struct Node
{
char ch;
int freq;
Node *left, *right;
};
// Function to allocate a new tree node
Node* getNode(char ch, int freq, Node* left, Node* right)
{
Node* node = new Node();
node->ch = ch;
node->freq = freq;
node->left = left;
node->right = right;
return node;
}
// Comparison object to be used to order the heap
struct comp
{
bool operator()(Node* l, Node* r)
{
// highest priority item has lowest frequency
return l->freq > r->freq;
}
};
// traverse the Huffman Tree and store Huffman Codes
// in a map.
void encode(Node* root, string str,
unordered_map<char, string> &huffmanCode)
{
if (root == nullptr)
return;
// found a leaf node
if (!root->left && !root->right) {
huffmanCode[root->ch] = str;
}
encode(root->left, str + "0", huffmanCode);
encode(root->right, str + "1", huffmanCode);
}
// traverse the Huffman Tree and decode the encoded string
void decode(Node* root, int &index, string str)
{
if (root == nullptr) {
return;
}
// found a leaf node
if (!root->left && !root->right)
{
cout << root->ch;
return;
}
index++;
if (str[index] =='0')
decode(root->left, index, str);
else
decode(root->right, index, str);
}
// Builds Huffman Tree and decode given input text
void buildHuffmanTree(string text)
{
// count frequency of appearance of each character
// and store it in a map
unordered_map<char, int> freq;
for (char ch: text) {
freq[ch]++;
}
// Create a priority queue to store live nodes of
// Huffman tree;
priority_queue<Node*, vector<Node*>, comp> pq;
// Create a leaf node for each character and add it
// to the priority queue.
for (auto pair: freq) {
pq.push(getNode(pair.first, pair.second, nullptr, nullptr));
}
// do till there is more than one node in the queue
while (pq.size() != 1)
{
// Remove the two nodes of highest priority
// (lowest frequency) from the queue
Node *left = pq.top(); pq.pop();
Node *right = pq.top(); pq.pop();
// Create a new internal node with these two nodes
// as children and with frequency equal to the sum
// of the two nodes' frequencies. Add the new node
// to the priority queue.
int sum = left->freq + right->freq;
pq.push(getNode(' ', sum, left, right));
}
// root stores pointer to root of Huffman Tree
Node* root = pq.top();
// traverse the Huffman Tree and store Huffman Codes
// in a map. Also prints them
unordered_map<char, string> huffmanCode;
encode(root, "", huffmanCode);
cout << "Huffman Codes are :n" << 'n';
for (auto pair: huffmanCode) {
cout << pair.first << " " << pair.second << 'n';
}
cout << "nOriginal string was :n" << text << 'n';
// print encoded string
string str = "";
for (char ch: text) {
str += huffmanCode[ch];
}
cout << "nEncoded string is :n" << str << 'n';
// traverse the Huffman Tree again and this time
// decode the encoded string
int index = -1;
cout << "nDecoded string is: n";
while (index < (int)str.size() - 2) {
decode(root, index, str);
}
}
// Huffman coding algorithm
int main()
{
string text = "Huffman coding is a data compression algorithm.";
buildHuffmanTree(text);
return 0;
}import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
// A Tree node
class Node
{
char ch;
int freq;
Node left = null, right = null;
Node(char ch, int freq)
{
this.ch = ch;
this.freq = freq;
}
public Node(char ch, int freq, Node left, Node right) {
this.ch = ch;
this.freq = freq;
this.left = left;
this.right = right;
}
};
class Huffman
{
// traverse the Huffman Tree and store Huffman Codes
// in a map.
public static void encode(Node root, String str,
Map<Character, String> huffmanCode)
{
if (root == null)
return;
// found a leaf node
if (root.left == null && root.right == null) {
huffmanCode.put(root.ch, str);
}
encode(root.left, str + "0", huffmanCode);
encode(root.right, str + "1", huffmanCode);
}
// traverse the Huffman Tree and decode the encoded string
public static int decode(Node root, int index, StringBuilder sb)
{
if (root == null)
return index;
// found a leaf node
if (root.left == null && root.right == null)
{
System.out.print(root.ch);
return index;
}
index++;
if (sb.charAt(index) == '0')
index = decode(root.left, index, sb);
else
index = decode(root.right, index, sb);
return index;
}
// Builds Huffman Tree and huffmanCode and decode given input text
public static void buildHuffmanTree(String text)
{
// count frequency of appearance of each character
// and store it in a map
Map<Character, Integer> freq = new HashMap<>();
for (int i = 0 ; i < text.length(); i++) {
if (!freq.containsKey(text.charAt(i))) {
freq.put(text.charAt(i), 0);
}
freq.put(text.charAt(i), freq.get(text.charAt(i)) + 1);
}
// Create a priority queue to store live nodes of Huffman tree
// Notice that highest priority item has lowest frequency
PriorityQueue<Node> pq = new PriorityQueue<>(
(l, r) -> l.freq - r.freq);
// Create a leaf node for each character and add it
// to the priority queue.
for (Map.Entry<Character, Integer> entry : freq.entrySet()) {
pq.add(new Node(entry.getKey(), entry.getValue()));
}
// do till there is more than one node in the queue
while (pq.size() != 1)
{
// Remove the two nodes of highest priority
// (lowest frequency) from the queue
Node left = pq.poll();
Node right = pq.poll();
// Create a new internal node with these two nodes as children
// and with frequency equal to the sum of the two nodes
// frequencies. Add the new node to the priority queue.
int sum = left.freq + right.freq;
pq.add(new Node(' ', sum, left, right));
}
// root stores pointer to root of Huffman Tree
Node root = pq.peek();
// traverse the Huffman tree and store the Huffman codes in a map
Map<Character, String> huffmanCode = new HashMap<>();
encode(root, "", huffmanCode);
// print the Huffman codes
System.out.println("Huffman Codes are :n");
for (Map.Entry<Character, String> entry : huffmanCode.entrySet()) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
System.out.println("nOriginal string was :n" + text);
// print encoded string
StringBuilder sb = new StringBuilder();
for (int i = 0 ; i < text.length(); i++) {
sb.append(huffmanCode.get(text.charAt(i)));
}
System.out.println("nEncoded string is :n" + sb);
// traverse the Huffman Tree again and this time
// decode the encoded string
int index = -1;
System.out.println("nDecoded string is: n");
while (index < sb.length() - 2) {
index = decode(root, index, sb);
}
}
public static void main(String[] args)
{
String text = "Huffman coding is a data compression algorithm.";
buildHuffmanTree(text);
}
}Lưu ý: bộ nhớ được sử dụng bởi chuỗi đầu vào là 47 * 8 = 376 bit và chuỗi được mã hóa chỉ là 194 bit tức là dữ liệu được nén khoảng 48%. Trong chương trình C++ ở trên, chúng ta sử dụng lớp string để lưu trữ chuỗi đã mã hóa giúp chương trình có thể đọc được.
Bởi vì cấu trúc dữ liệu hàng đợi ưu tiên hiệu quả yêu cầu mỗi lần chèn O (log (N)) thời gian, nhưng trong một cây nhị phân hoàn chỉnh với N lá hiện tại 2N-1 các nút và cây Huffman là một cây nhị phân hoàn chỉnh, thì thuật toán sẽ chạy trong O(Nlog(N)) thời gian, ở đâu N - Nhân vật.
Nguồn:
Nguồn: www.habr.com
