

Tiếp tục chủ đề ghi lại luồng dữ liệu lớn được đưa ra bởi , trong phần này chúng ta sẽ xem xét những cách mà bạn có thể giảm kích thước “vật lý” của dữ liệu được lưu trữ trong PostgreSQL và tác động của chúng đến hiệu suất máy chủ.
Chúng ta sẽ nói về Cài đặt TOAST và căn chỉnh dữ liệu. “Trung bình,” các phương pháp này sẽ không tiết kiệm quá nhiều tài nguyên nhưng hoàn toàn không sửa đổi mã ứng dụng.

Tuy nhiên, kinh nghiệm của chúng tôi hóa ra lại rất hiệu quả trong vấn đề này, vì bản chất của việc lưu trữ hầu hết mọi hoạt động giám sát là rất khó khăn. chủ yếu chỉ nối thêm về mặt dữ liệu được ghi lại. Và nếu bạn đang tự hỏi làm thế nào bạn có thể hướng dẫn cơ sở dữ liệu ghi vào đĩa thay thế 200MB / s một nửa - xin vui lòng dưới con mèo.
Bí mật nhỏ của dữ liệu lớn
Theo hồ sơ công việc , họ thường xuyên bay đến chỗ anh ta từ hang ổ gói văn bản.
Và kể từ khi cơ sở dữ liệu mà chúng tôi giám sát là một sản phẩm đa thành phần có cấu trúc dữ liệu phức tạp, sau đó truy vấn cho hiệu suất tối đa hóa ra khá giống thế này . Vì vậy, khối lượng của từng phiên bản riêng lẻ của một yêu cầu hoặc kế hoạch thực hiện kết quả trong nhật ký đến với chúng tôi hóa ra là “trung bình” khá lớn.
Chúng ta hãy xem cấu trúc của một trong các bảng mà chúng ta ghi dữ liệu "thô" vào đó - nghĩa là đây là văn bản gốc từ mục nhật ký:
CREATE TABLE rawdata_orig(
pack -- PK
uuid NOT NULL
, recno -- PK
smallint NOT NULL
, dt -- ключ секции
date
, data -- самое главное
text
, PRIMARY KEY(pack, recno)
);Một dấu hiệu điển hình (tất nhiên là đã được phân chia nên đây là mẫu phần), trong đó điều quan trọng nhất là văn bản. Đôi khi khá đồ sộ.
Hãy nhớ lại rằng kích thước “vật lý” của một bản ghi trong PG không thể chiếm nhiều hơn một trang dữ liệu, nhưng kích thước “logic” lại là một vấn đề hoàn toàn khác. Để ghi giá trị thể tích (varchar/text/bytea) vào một trường, hãy sử dụng :
PostgreSQL sử dụng kích thước trang cố định (thường là 8 KB) và không cho phép các bộ dữ liệu trải dài trên nhiều trang. Vì vậy, không thể lưu trữ trực tiếp các giá trị trường rất lớn. Để khắc phục hạn chế này, các giá trị trường lớn được nén và/hoặc chia thành nhiều dòng vật lý. Điều này xảy ra mà người dùng không nhận thấy và ít ảnh hưởng đến hầu hết mã máy chủ. Phương pháp này được gọi là TOAST...
Trên thực tế, đối với mỗi bảng có các trường "có thể lớn", sẽ tự động mỗi bản ghi “lớn” trong các phân đoạn 2KB:
TOAST(
chunk_id
integer
, chunk_seq
integer
, chunk_data
bytea
, PRIMARY KEY(chunk_id, chunk_seq)
);
Nghĩa là, nếu chúng ta phải viết một chuỗi có giá trị “lớn” data, thì việc ghi âm thực sự sẽ diễn ra không chỉ với bảng chính và PK của nó mà còn với TOAST và PK của nó.
Giảm ảnh hưởng của TOAST
Nhưng hầu hết kỷ lục của chúng ta vẫn chưa lớn đến thế, nên vừa với 8KB - Làm thế nào tôi có thể tiết kiệm tiền cho việc này?..
Đây là lúc thuộc tính này hỗ trợ chúng ta tại cột bảng:
- ĐA THẾ HỆ cho phép cả nén và lưu trữ riêng biệt. Cái này tùy chọn tiêu chuẩn cho hầu hết các loại dữ liệu tuân thủ TOAST. Đầu tiên nó cố gắng thực hiện nén, sau đó lưu nó ra ngoài bảng nếu hàng vẫn quá lớn.
- CHỦ YẾU cho phép nén nhưng không lưu trữ riêng biệt. (Trên thực tế, việc lưu trữ riêng vẫn sẽ được thực hiện cho các cột như vậy nhưng chỉ như một phương sách cuối cùng, khi không có cách nào khác để thu nhỏ chuỗi sao cho vừa với trang.)
Trên thực tế, đây chính xác là những gì chúng ta cần cho văn bản - nén nó lại càng nhiều càng tốt, nếu không vừa thì cho vào TOAST. Việc này có thể được thực hiện trực tiếp nhanh chóng bằng một lệnh:
ALTER TABLE rawdata_orig ALTER COLUMN data SET STORAGE MAIN;Cách đánh giá hiệu quả
Vì luồng dữ liệu thay đổi hàng ngày nên chúng ta không thể so sánh số tuyệt đối mà phải so sánh ở dạng tương đối chia sẻ nhỏ hơn Chúng tôi đã viết nó ra trong TOAST - càng nhiều càng tốt. Nhưng có một mối nguy hiểm ở đây - khối lượng “vật lý” của mỗi bản ghi riêng lẻ càng lớn thì chỉ mục càng trở nên “rộng hơn”, bởi vì chúng ta phải bao gồm nhiều trang dữ liệu hơn.
Mục trước những thay đổi:
heap = 37GB (39%)
TOAST = 54GB (57%)
PK = 4GB ( 4%)
Mục sau khi thay đổi:
heap = 37GB (67%)
TOAST = 16GB (29%)
PK = 2GB ( 4%)Trên thực tế, chúng tôi bắt đầu viết vào TOAST ít thường xuyên hơn 2 lần, không chỉ tải đĩa mà còn cả CPU:
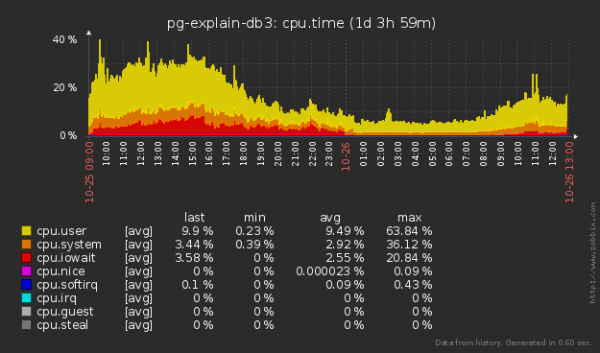
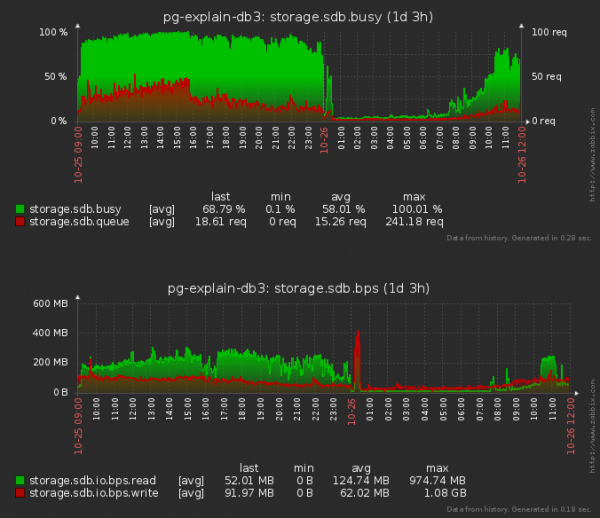
Tôi sẽ lưu ý rằng chúng ta cũng đã trở nên nhỏ hơn trong việc “đọc” đĩa chứ không chỉ “ghi” - vì khi chèn một bản ghi vào bảng, chúng ta cũng phải “đọc” một phần cây của mỗi chỉ mục để xác định nó vị trí tương lai của họ.
Ai có thể sống tốt trên PostgreSQL 11
Sau khi cập nhật lên PG11, chúng tôi quyết định tiếp tục “tinh chỉnh” TOAST và nhận thấy rằng bắt đầu từ phiên bản này tham số :
Mã xử lý TOAST chỉ kích hoạt khi giá trị hàng được lưu trong bảng lớn hơn TOAST_TUPLE_THRESHOLD byte (thường là 2 KB). Mã TOAST sẽ nén và/hoặc di chuyển các giá trị trường ra khỏi bảng cho đến khi giá trị hàng nhỏ hơn TOAST_TUPLE_TARGET byte (giá trị biến, cũng thường là 2 KB) hoặc không thể giảm kích thước.
Chúng tôi quyết định rằng dữ liệu chúng tôi thường có là “rất ngắn” hoặc “rất dài”, vì vậy chúng tôi quyết định giới hạn ở giá trị tối thiểu có thể:
ALTER TABLE rawplan_orig SET (toast_tuple_target = 128);Hãy xem các cài đặt mới ảnh hưởng đến việc tải đĩa như thế nào sau khi cấu hình lại:

Không tệ! Trung bình hàng đợi vào đĩa đã giảm khoảng 1.5 lần và đĩa “bận” là 20 phần trăm! Nhưng có lẽ điều này bằng cách nào đó đã ảnh hưởng đến CPU?

Ít nhất nó đã không trở nên tồi tệ hơn. Mặc dù vậy, thật khó để đánh giá liệu ngay cả những khối lượng như vậy vẫn không thể tăng tải CPU trung bình cao hơn 5%.
Bằng cách thay đổi vị trí của các số hạng, tổng... thay đổi!
Như bạn đã biết, một xu tiết kiệm được một đồng rúp và với khối lượng lưu trữ của chúng tôi thì khoảng 10TB/tháng ngay cả một chút tối ưu hóa cũng có thể mang lại lợi nhuận tốt. Do đó, chúng tôi chú ý đến cấu trúc vật lý của dữ liệu - chính xác thì các trường “xếp chồng” bên trong bản ghi mỗi bàn.
Bởi vì vì điều này là thẳng về phía trước :
Nhiều kiến trúc cung cấp sự liên kết dữ liệu trên ranh giới từ máy. Ví dụ: trên hệ thống x32 86 bit, các số nguyên (loại số nguyên, 4 byte) sẽ được căn chỉnh trên ranh giới từ 4 byte, cũng như các số dấu phẩy động có độ chính xác sẽ tăng gấp đôi (dấu phẩy động có độ chính xác gấp đôi, 8 byte). Và trên hệ thống 64 bit, các giá trị kép sẽ được căn chỉnh theo ranh giới từ 8 byte. Đây là một lý do khác cho sự không tương thích.
Do căn chỉnh nên kích thước của một hàng trong bảng phụ thuộc vào thứ tự của các trường. Thông thường hiệu ứng này không đáng chú ý lắm, nhưng trong một số trường hợp, nó có thể dẫn đến kích thước tăng lên đáng kể. Ví dụ: nếu bạn kết hợp các trường char(1) và trường số nguyên, thông thường sẽ có 3 byte bị lãng phí giữa chúng.
Hãy bắt đầu với các mô hình tổng hợp:
SELECT pg_column_size(ROW(
'0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
, '2019-01-01'::date
));
-- 48 байт
SELECT pg_column_size(ROW(
'2019-01-01'::date
, '0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
));
-- 46 байтMột vài byte bổ sung đến từ đâu trong trường hợp đầu tiên? Thật đơn giản - Smallint 2 byte được căn chỉnh trên ranh giới 4 byte trước trường tiếp theo và khi là trường cuối cùng thì không có gì và không cần căn chỉnh.
Về lý thuyết thì mọi thứ đều ổn và bạn có thể sắp xếp lại các trường theo ý muốn. Hãy kiểm tra nó trên dữ liệu thực bằng cách sử dụng ví dụ về một trong các bảng, phần hàng ngày chiếm 10-15GB.
Cấu trúc ban đầu:
CREATE TABLE public.plan_20190220
(
-- Унаследована from table plan: pack uuid NOT NULL,
-- Унаследована from table plan: recno smallint NOT NULL,
-- Унаследована from table plan: host uuid,
-- Унаследована from table plan: ts timestamp with time zone,
-- Унаследована from table plan: exectime numeric(32,3),
-- Унаследована from table plan: duration numeric(32,3),
-- Унаследована from table plan: bufint bigint,
-- Унаследована from table plan: bufmem bigint,
-- Унаследована from table plan: bufdsk bigint,
-- Унаследована from table plan: apn uuid,
-- Унаследована from table plan: ptr uuid,
-- Унаследована from table plan: dt date,
CONSTRAINT plan_20190220_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190220_dt_check CHECK (dt = '2019-02-20'::date)
)
INHERITS (public.plan)Phần sau khi thay đổi thứ tự cột - chính xác các trường giống nhau, chỉ khác thứ tự:
CREATE TABLE public.plan_20190221
(
-- Унаследована from table plan: dt date NOT NULL,
-- Унаследована from table plan: ts timestamp with time zone,
-- Унаследована from table plan: pack uuid NOT NULL,
-- Унаследована from table plan: recno smallint NOT NULL,
-- Унаследована from table plan: host uuid,
-- Унаследована from table plan: apn uuid,
-- Унаследована from table plan: ptr uuid,
-- Унаследована from table plan: bufint bigint,
-- Унаследована from table plan: bufmem bigint,
-- Унаследована from table plan: bufdsk bigint,
-- Унаследована from table plan: exectime numeric(32,3),
-- Унаследована from table plan: duration numeric(32,3),
CONSTRAINT plan_20190221_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190221_dt_check CHECK (dt = '2019-02-21'::date)
)
INHERITS (public.plan)
Tổng khối lượng của phần được xác định bởi số lượng "sự kiện" và chỉ phụ thuộc vào các quy trình bên ngoài, vì vậy hãy chia kích thước của heap (pg_relation_size) theo số lượng bản ghi trong đó - nghĩa là chúng ta nhận được kích thước trung bình của bản ghi được lưu trữ thực tế:
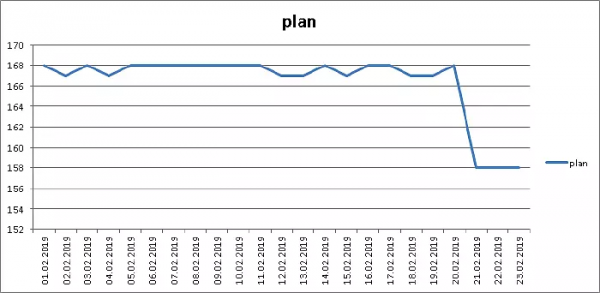
Âm lượng âm 6%, Tuyệt vời!
Nhưng tất nhiên, mọi thứ không hề màu hồng như vậy - xét cho cùng, trong các chỉ mục, chúng tôi không thể thay đổi thứ tự của các trường, và do đó “nói chung” (pg_total_relation_size) ...
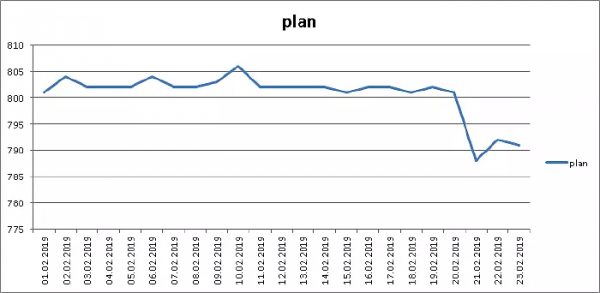
...vẫn còn ở đây đã tiết kiệm được 1.5%mà không thay đổi một dòng mã nào. Vâng vâng!

Tôi lưu ý rằng tùy chọn sắp xếp các trường ở trên không phải là thực tế là nó tối ưu nhất. Bởi vì bạn không muốn “xé nát” một số khối trường vì lý do thẩm mỹ - ví dụ như một cặp đôi (pack, recno), đó là PK cho bảng này.
Nhìn chung, việc xác định cách sắp xếp “tối thiểu” của các trường là một nhiệm vụ khá đơn giản. Do đó, bạn có thể nhận được kết quả thậm chí còn tốt hơn từ dữ liệu của mình so với dữ liệu của chúng tôi - hãy thử nó!
Nguồn: www.habr.com
