


Xin chào, Habr! Tôi là Artem Karamyshev, trưởng nhóm quản trị hệ thống . Chúng tôi đã có nhiều sản phẩm mới ra mắt trong năm qua. Chúng tôi muốn đảm bảo rằng các dịch vụ API có thể dễ dàng mở rộng, có khả năng chịu lỗi và sẵn sàng cho lượng tải người dùng tăng nhanh. Nền tảng của chúng tôi được triển khai trên OpenStack và tôi muốn cho bạn biết những vấn đề về khả năng chịu lỗi thành phần nào mà chúng tôi phải giải quyết để có được một hệ thống có khả năng chịu lỗi. Tôi nghĩ điều này sẽ rất thú vị đối với những người cũng phát triển sản phẩm trên OpenStack.
Khả năng chịu lỗi tổng thể của một nền tảng bao gồm khả năng phục hồi của các thành phần của nó. Vì vậy, chúng tôi sẽ dần dần đi qua tất cả các cấp độ mà chúng tôi đã xác định được rủi ro và loại bỏ chúng.
Phiên bản video của câu chuyện này, nguồn chính là báo cáo tại hội nghị Uptime day 4, được tổ chức bởi , bạn có thể thấy .
Khả năng phục hồi của kiến trúc vật lý
Phần công khai của đám mây MCS hiện được đặt tại hai trung tâm dữ liệu Cấp III, giữa chúng có sợi tối riêng, được dành riêng ở cấp độ vật lý theo các tuyến khác nhau, với thông lượng 200 Gbit/s. Cấp III cung cấp mức độ chịu lỗi cần thiết cho cơ sở hạ tầng vật lý.
Sợi tối được dành riêng ở cả cấp độ vật lý và logic. Quá trình đặt trước kênh được lặp đi lặp lại, có vấn đề phát sinh và chúng tôi không ngừng cải thiện khả năng liên lạc giữa các trung tâm dữ liệu.
Ví dụ, cách đây không lâu, khi đang làm việc ở một cái giếng gần một trong các trung tâm dữ liệu, một chiếc máy xúc đã làm gãy một đường ống, bên trong đường ống này có cả cáp quang chính và cáp quang dự phòng. Kênh liên lạc có khả năng chịu lỗi của chúng tôi với trung tâm dữ liệu hóa ra lại dễ bị tổn thương tại một thời điểm, trong giếng. Theo đó, chúng tôi đã mất một phần cơ sở hạ tầng. Chúng tôi đã rút ra kết luận và thực hiện một số hành động, bao gồm lắp đặt thêm hệ thống quang học ở giếng liền kề.
Trong các trung tâm dữ liệu có các điểm hiện diện của các nhà cung cấp dịch vụ truyền thông mà chúng tôi phát tiền tố của mình thông qua BGP. Đối với mỗi hướng mạng, số liệu tốt nhất sẽ được chọn, cho phép các máy khách khác nhau được cung cấp chất lượng kết nối tốt nhất. Nếu liên lạc qua một nhà cung cấp bị hỏng, chúng tôi sẽ xây dựng lại định tuyến của mình thông qua các nhà cung cấp hiện có.
Nếu một nhà cung cấp không thành công, chúng tôi sẽ tự động chuyển sang nhà cung cấp tiếp theo. Trong trường hợp một trong các trung tâm dữ liệu bị lỗi, chúng tôi sẽ có một bản sao phản chiếu các dịch vụ của mình trong trung tâm dữ liệu thứ hai, đảm nhận toàn bộ tải.
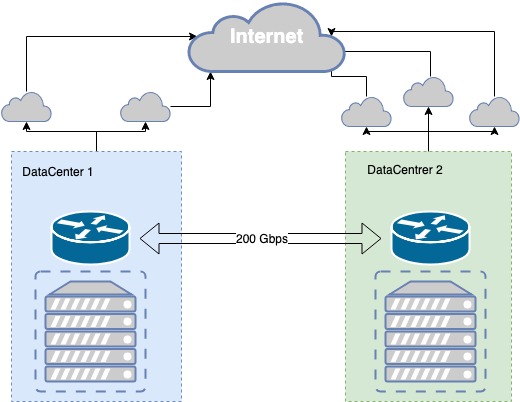
Khả năng phục hồi của cơ sở hạ tầng vật lý
Những gì chúng tôi sử dụng để khắc phục lỗi ở cấp độ ứng dụng
Dịch vụ của chúng tôi được xây dựng trên một số thành phần nguồn mở.
ExaBGP là một dịch vụ thực hiện một số chức năng sử dụng giao thức định tuyến động dựa trên BGP. Chúng tôi tích cực sử dụng nó để quảng cáo các địa chỉ IP được đưa vào danh sách cho phép của mình thông qua đó người dùng truy cập API.
HAProxy là bộ cân bằng tải cao cho phép bạn định cấu hình các quy tắc cân bằng lưu lượng rất linh hoạt ở các cấp độ khác nhau của mô hình OSI. Chúng tôi sử dụng nó để cân bằng trước tất cả các dịch vụ: cơ sở dữ liệu, môi giới tin nhắn, dịch vụ API, dịch vụ web, các dự án nội bộ của chúng tôi - mọi thứ đều đằng sau HAProxy.
Ứng dụng API — một ứng dụng web được viết bằng python, trong đó người dùng quản lý cơ sở hạ tầng và dịch vụ của mình.
Đơn xin việc của công nhân (sau đây gọi đơn giản là nhân viên) - trong các dịch vụ OpenStack, đây là một daemon cơ sở hạ tầng cho phép bạn truyền các lệnh API đến cơ sở hạ tầng. Ví dụ: quá trình tạo đĩa xảy ra trong trình chạy và yêu cầu tạo đĩa xảy ra trong API ứng dụng.
Kiến trúc ứng dụng OpenStack tiêu chuẩn
Hầu hết các dịch vụ được phát triển cho OpenStack đều cố gắng tuân theo một mô hình duy nhất. Một dịch vụ thường bao gồm 2 phần: API và công nhân (người thực thi phụ trợ). Theo quy định, API là một ứng dụng WSGI trong python, được khởi chạy dưới dạng một quy trình độc lập (daemon) hoặc sử dụng máy chủ web Nginx hoặc Apache được tạo sẵn. API xử lý yêu cầu của người dùng và chuyển các hướng dẫn tiếp theo đến ứng dụng Worker để thực thi. Việc chuyển tiền diễn ra bằng cách sử dụng một nhà môi giới tin nhắn, thường là RabbitMQ, những nhà môi giới khác được hỗ trợ kém. Khi tin nhắn đến nhà môi giới, chúng sẽ được nhân viên xử lý và nếu cần, sẽ trả lời phản hồi.
Mô hình này liên quan đến các điểm lỗi chung riêng biệt: RabbitMQ và cơ sở dữ liệu. Nhưng RabbitMQ được tách biệt trong một dịch vụ và về mặt lý thuyết, có thể riêng lẻ cho từng dịch vụ. Vì vậy, tại MCS, chúng tôi tách biệt các dịch vụ này càng nhiều càng tốt; đối với mỗi dự án riêng lẻ, chúng tôi tạo một cơ sở dữ liệu riêng, một RabbitMQ riêng. Cách tiếp cận này tốt vì trong trường hợp xảy ra tai nạn ở một số điểm dễ bị tổn thương, không phải toàn bộ dịch vụ bị hỏng mà chỉ một phần của nó bị hỏng.
Số lượng ứng dụng công nhân là không giới hạn, do đó API có thể dễ dàng mở rộng quy mô theo chiều ngang phía sau bộ cân bằng để tăng hiệu suất và khả năng chịu lỗi.
Một số dịch vụ yêu cầu sự phối hợp trong dịch vụ khi các hoạt động tuần tự phức tạp diễn ra giữa API và trình chạy. Trong trường hợp này, một trung tâm điều phối duy nhất được sử dụng, một hệ thống cụm như Redis, Memcache, v.v., cho phép một công nhân nói với người khác rằng nhiệm vụ này được giao cho anh ta (“vui lòng không nhận nó”). Chúng tôi sử dụng vvd. Theo quy định, công nhân tích cực giao tiếp với cơ sở dữ liệu, viết và đọc thông tin từ đó. Chúng tôi sử dụng mariadb làm cơ sở dữ liệu nằm trong cụm multimaster.
Dịch vụ đơn lẻ cổ điển này được tổ chức theo cách được chấp nhận chung cho OpenStack. Nó có thể được coi là một hệ thống khép kín, trong đó các phương pháp mở rộng quy mô và khả năng chịu lỗi khá rõ ràng. Ví dụ: đối với khả năng chịu lỗi của API, việc đặt một bộ cân bằng trước chúng là đủ. Công nhân mở rộng quy mô đạt được bằng cách tăng số lượng của họ.
Điểm yếu trong toàn bộ sơ đồ là RabbitMQ và MariaDB. Kiến trúc của họ xứng đáng có một bài viết riêng, trong bài viết này tôi muốn tập trung vào khả năng chịu lỗi của API.
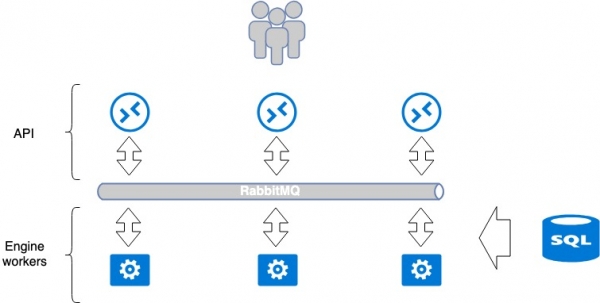
Kiến trúc ứng dụng Openstack. Cân bằng và khả năng chịu lỗi của nền tảng đám mây
Làm cho bộ cân bằng HAProxy có khả năng chịu lỗi bằng ExaBGP
Để làm cho các API của chúng tôi có thể mở rộng, nhanh chóng và có khả năng chịu lỗi, chúng tôi đặt một bộ cân bằng tải trước chúng. Chúng tôi đã chọn HAProxy. Theo tôi, nó có tất cả các đặc điểm cần thiết cho nhiệm vụ của chúng tôi: cân bằng ở một số cấp độ OSI, giao diện quản lý, tính linh hoạt và khả năng mở rộng, một số lượng lớn các phương pháp cân bằng, hỗ trợ các bảng phiên.
Vấn đề đầu tiên cần giải quyết là khả năng chịu lỗi của chính bộ cân bằng. Việc chỉ cài đặt bộ cân bằng cũng tạo ra điểm không thành công: bộ cân bằng bị hỏng và dịch vụ gặp sự cố. Để ngăn điều này xảy ra, chúng tôi đã sử dụng HAProxy kết hợp với ExaBGP.
ExaBGP cho phép bạn triển khai cơ chế kiểm tra trạng thái của dịch vụ. Chúng tôi đã sử dụng cơ chế này để kiểm tra chức năng của HAProxy và trong trường hợp có sự cố, hãy tắt dịch vụ HAProxy khỏi BGP.
Sơ đồ ExaBGP+HAProxy
- Chúng tôi cài đặt phần mềm cần thiết, ExaBGP và HAProxy, trên ba máy chủ.
- Chúng tôi tạo giao diện loopback trên mỗi máy chủ.
- Trên cả ba máy chủ, chúng tôi gán cùng một địa chỉ IP màu trắng cho giao diện này.
- Địa chỉ IP màu trắng được quảng cáo trên Internet thông qua ExaBGP.
Khả năng chịu lỗi đạt được bằng cách quảng cáo cùng một địa chỉ IP từ cả ba máy chủ. Từ quan điểm mạng, cùng một địa chỉ có thể được truy cập từ ba bước nhảy tiếp theo khác nhau. Bộ định tuyến nhìn thấy ba tuyến giống hệt nhau, chọn mức ưu tiên cao nhất trong số chúng dựa trên số liệu riêng của nó (đây thường là cùng một tùy chọn) và lưu lượng truy cập chỉ đến một trong các máy chủ.
Trong trường hợp xảy ra sự cố với hoạt động của HAProxy hoặc lỗi máy chủ, ExaBGP sẽ ngừng thông báo tuyến đường và lưu lượng truy cập sẽ chuyển sang máy chủ khác một cách suôn sẻ.
Vì vậy, chúng tôi đã đạt được khả năng chịu lỗi của bộ cân bằng.
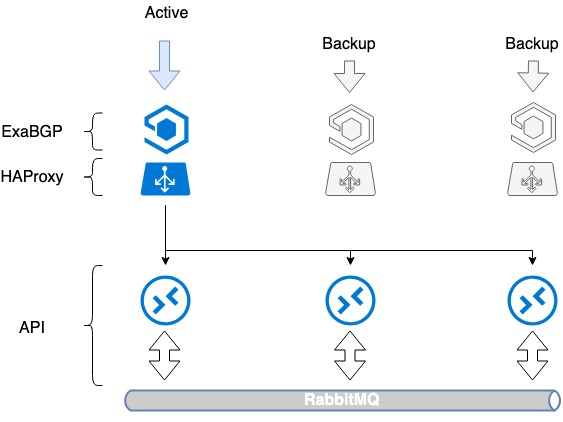
Khả năng chịu lỗi của bộ cân bằng HAProxy
Kế hoạch hóa ra không hoàn hảo: chúng tôi đã học cách đặt trước HAProxy nhưng không học cách phân phối tải trong các dịch vụ. Do đó, chúng tôi đã mở rộng sơ đồ này một chút: chúng tôi chuyển sang cân bằng giữa một số địa chỉ IP màu trắng.
Cân bằng dựa trên DNS cộng với BGP
Vấn đề cân bằng tải cho HAProxy của chúng tôi vẫn chưa được giải quyết. Tuy nhiên, nó có thể được giải quyết khá đơn giản, như chúng tôi đã làm ở đây.
Để cân bằng ba máy chủ, bạn sẽ cần 3 địa chỉ IP màu trắng và DNS cũ tốt. Mỗi địa chỉ này được xác định trên giao diện loopback của mỗi HAProxy và được quảng bá trên Internet.
Trong OpenStack, để quản lý tài nguyên, một thư mục dịch vụ được sử dụng để chỉ định API điểm cuối của một dịch vụ cụ thể. Trong thư mục này, chúng tôi đăng ký một tên miền - public.infra.mail.ru, được phân giải qua DNS bằng ba địa chỉ IP khác nhau. Kết quả là chúng tôi nhận được phân phối tải giữa ba địa chỉ thông qua DNS.
Nhưng vì khi công bố địa chỉ IP màu trắng chúng ta không kiểm soát được mức độ ưu tiên lựa chọn máy chủ nên điều này vẫn chưa cân bằng. Thông thường, chỉ một máy chủ sẽ được chọn dựa trên thâm niên địa chỉ IP và hai máy chủ còn lại sẽ không hoạt động vì không có số liệu nào được chỉ định trong BGP.
Chúng tôi bắt đầu gửi các tuyến đường qua ExaBGP với các số liệu khác nhau. Mỗi bộ cân bằng quảng cáo cả ba địa chỉ IP màu trắng, nhưng một trong số đó, địa chỉ chính cho bộ cân bằng này, được quảng cáo với số liệu tối thiểu. Vì vậy, trong khi cả ba bộ cân bằng đều hoạt động, các cuộc gọi đến địa chỉ IP đầu tiên sẽ chuyển đến bộ cân bằng đầu tiên, các cuộc gọi đến bộ cân bằng thứ hai đến bộ cân bằng thứ hai và các cuộc gọi đến bộ cân bằng thứ ba đến bộ cân bằng thứ ba.
Điều gì xảy ra khi một trong những chiếc cân rơi xuống? Nếu bất kỳ bộ cân bằng nào bị lỗi, địa chỉ chính của nó vẫn được quảng cáo từ hai bộ cân bằng còn lại và lưu lượng truy cập sẽ được phân phối lại giữa chúng. Do đó, chúng tôi cung cấp cho người dùng một số địa chỉ IP cùng một lúc thông qua DNS. Bằng cách cân bằng theo DNS và các số liệu khác nhau, chúng tôi có được sự phân bổ tải đồng đều trên cả ba bộ cân bằng. Và đồng thời chúng tôi không mất đi khả năng chịu lỗi.
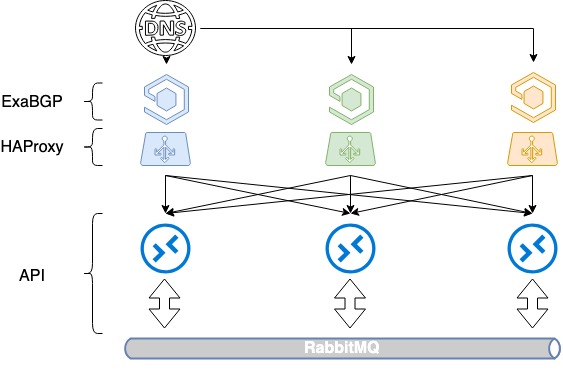
Cân bằng HAProxy dựa trên DNS + BGP
Tương tác giữa ExaBGP và HAProxy
Vì vậy, chúng tôi đã triển khai khả năng chịu lỗi trong trường hợp máy chủ rời đi, dựa trên việc dừng thông báo các tuyến đường. Nhưng HAProxy có thể tắt vì những lý do khác ngoài lỗi máy chủ: lỗi quản trị, lỗi trong dịch vụ. Chúng tôi cũng muốn loại bỏ bộ cân bằng bị hỏng dưới tải trong những trường hợp này và chúng tôi cần một cơ chế khác.
Do đó, để mở rộng sơ đồ trước đó, chúng tôi đã triển khai nhịp tim giữa ExaBGP và HAProxy. Đây là phần mềm triển khai tương tác giữa ExaBGP và HAProxy, khi ExaBGP sử dụng các tập lệnh tùy chỉnh để kiểm tra trạng thái của ứng dụng.
Để thực hiện việc này, bạn cần định cấu hình trình kiểm tra tình trạng trong cấu hình ExaBGP, trình kiểm tra này có thể kiểm tra trạng thái của HAProxy. Trong trường hợp của chúng tôi, chúng tôi đã định cấu hình phần phụ trợ tình trạng trong HAProxy và từ phía ExaBGP, chúng tôi kiểm tra bằng một yêu cầu GET đơn giản. Nếu thông báo ngừng xảy ra thì rất có thể HAProxy không hoạt động và không cần phải quảng cáo.
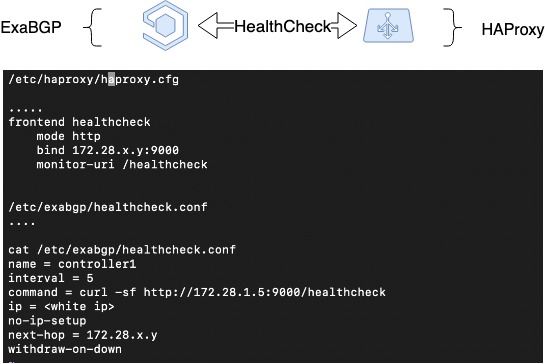
Kiểm tra sức khỏe HAProxy
HAProxy ngang hàng: đồng bộ hóa phiên
Điều tiếp theo cần làm là đồng bộ hóa các phiên. Khi làm việc thông qua các bộ cân bằng phân tán, rất khó để tổ chức lưu trữ thông tin về các phiên khách hàng. Nhưng HAProxy là một trong số ít bộ cân bằng có thể thực hiện được điều này nhờ chức năng Peers - khả năng chuyển bảng phiên giữa các quy trình HAProxy khác nhau.
Có nhiều phương pháp cân bằng khác nhau: những phương pháp đơn giản như và được mở rộng khi phiên của khách hàng được ghi nhớ và mỗi lần anh ta kết thúc trên cùng một máy chủ như trước. Chúng tôi muốn thực hiện tùy chọn thứ hai.
HAProxy sử dụng bảng dính để lưu phiên khách của cơ chế này. Chúng lưu địa chỉ IP gốc của khách hàng, địa chỉ đích đã chọn (phụ trợ) và một số thông tin dịch vụ. Thông thường, bảng dính được sử dụng để lưu trữ cặp nguồn-IP + đích-IP, điều này đặc biệt hữu ích cho các ứng dụng không thể chuyển ngữ cảnh phiên người dùng khi chuyển sang bộ cân bằng khác, chẳng hạn như ở chế độ cân bằng RoundRobin.
Nếu một bảng dính được dạy cách di chuyển giữa các quy trình HAProxy khác nhau (giữa quá trình cân bằng xảy ra), bộ cân bằng của chúng tôi sẽ có thể hoạt động với một nhóm bảng dính. Điều này sẽ giúp có thể chuyển đổi liền mạch mạng của khách hàng nếu một trong các bộ cân bằng bị lỗi; công việc với các phiên khách hàng sẽ tiếp tục trên cùng các chương trình phụ trợ đã được chọn trước đó.
Để hoạt động bình thường, vấn đề về địa chỉ IP nguồn của bộ cân bằng mà phiên được thiết lập phải được giải quyết. Trong trường hợp của chúng tôi, đây là địa chỉ động trên giao diện loopback.
Công việc đúng đắn của các đồng nghiệp chỉ đạt được trong những điều kiện nhất định. Nghĩa là, thời gian chờ của TCP phải đủ lớn hoặc chuyển mạch phải đủ nhanh để phiên TCP không có thời gian kết thúc. Tuy nhiên, nó cho phép chuyển đổi liền mạch.
Trong IaaS, chúng tôi có một dịch vụ được xây dựng bằng công nghệ tương tự. Cái này , được gọi là Octavia. Nó dựa trên hai quy trình HAProxy và ban đầu bao gồm hỗ trợ cho các đồng nghiệp. Họ đã chứng tỏ mình xuất sắc trong dịch vụ này.
Hình ảnh dưới dạng sơ đồ cho thấy chuyển động của các bảng ngang hàng giữa ba phiên bản HAProxy, một cấu hình được đề xuất về cách cấu hình điều này:
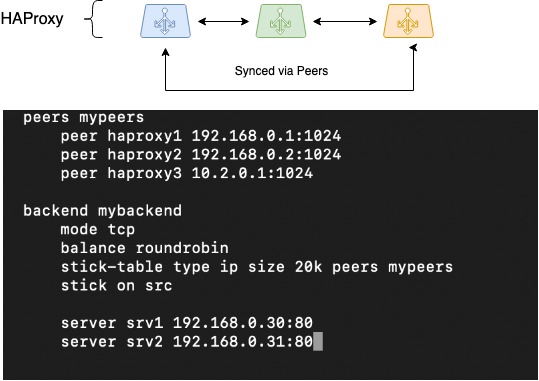
HAProxy Peers (đồng bộ hóa phiên)
Nếu bạn thực hiện cùng một sơ đồ, hoạt động của nó phải được kiểm tra cẩn thận. Thực tế không phải là nó sẽ hoạt động theo cách tương tự 100%. Nhưng ít nhất bạn sẽ không bị mất bảng Stick khi cần nhớ IP nguồn của client.
Giới hạn số lượng yêu cầu đồng thời từ cùng một khách hàng
Bất kỳ dịch vụ nào được cung cấp công khai, bao gồm cả API của chúng tôi, đều có thể phải đối mặt với hàng loạt yêu cầu. Nguyên nhân của chúng có thể hoàn toàn khác nhau, từ lỗi của người dùng cho đến các cuộc tấn công có chủ đích. Chúng tôi bị DDoSed định kỳ theo địa chỉ IP. Khách hàng thường mắc lỗi trong tập lệnh của họ và gửi cho chúng tôi các DDoS nhỏ.
Bằng cách này hay cách khác, sự bảo vệ bổ sung phải được cung cấp. Giải pháp rõ ràng là hạn chế số lượng yêu cầu API và không lãng phí thời gian của CPU khi xử lý các yêu cầu độc hại.
Để thực hiện những hạn chế như vậy, chúng tôi sử dụng giới hạn tỷ lệ, được tổ chức trên cơ sở HAProxy, sử dụng cùng một bảng thanh. Việc thiết lập giới hạn khá đơn giản và cho phép bạn giới hạn người dùng theo số lượng yêu cầu tới API. Thuật toán ghi nhớ IP nguồn từ đó các yêu cầu được thực hiện và giới hạn số lượng yêu cầu đồng thời từ một người dùng. Tất nhiên, chúng tôi đã tính toán cấu hình tải API trung bình cho từng dịch vụ và đặt giới hạn ≈ 10 lần giá trị này. Chúng tôi tiếp tục theo dõi chặt chẽ tình hình và theo dõi nhịp đập.
Điều này trông như thế nào trong thực tế? Chúng tôi có những khách hàng luôn sử dụng API tự động tính toán của chúng tôi. Họ tạo ra khoảng hai đến ba trăm máy ảo vào buổi sáng và xóa chúng vào buổi tối. Đối với OpenStack, việc tạo một máy ảo cũng bằng các dịch vụ PaaS yêu cầu ít nhất 1000 yêu cầu API vì sự tương tác giữa các dịch vụ cũng xảy ra thông qua API.
Việc chuyển nhiệm vụ như vậy gây ra tải khá lớn. Chúng tôi đã đánh giá tải này, thu thập mức cao nhất hàng ngày, tăng chúng lên gấp XNUMX lần và điều này đã trở thành giới hạn tốc độ của chúng tôi. Chúng tôi giữ ngón tay của mình trên mạch. Chúng tôi thường thấy các bot và máy quét đang cố gắng nhìn vào chúng tôi để xem liệu chúng tôi có tập lệnh CGA nào có thể chạy được hay không, chúng tôi đang tích cực cắt chúng.
Cách cập nhật cơ sở mã của bạn mà người dùng không nhận thấy
Chúng tôi cũng triển khai khả năng chịu lỗi ở cấp độ quy trình triển khai mã. Có thể có trục trặc trong quá trình triển khai nhưng tác động của chúng đến tính khả dụng của dịch vụ có thể được giảm thiểu.
Chúng tôi liên tục cập nhật các dịch vụ của mình và phải đảm bảo rằng cơ sở mã được cập nhật mà không ảnh hưởng đến người dùng. Chúng tôi đã giải quyết được vấn đề này bằng cách sử dụng khả năng quản lý của HAProxy và triển khai Graceful Shutdown trong các dịch vụ của chúng tôi.
Để giải quyết vấn đề này, cần đảm bảo kiểm soát bộ cân bằng và tắt dịch vụ “chính xác”:
- Trong trường hợp HAProxy, việc kiểm soát được thực hiện thông qua tệp thống kê, về cơ bản là một ổ cắm và được xác định trong cấu hình HAProxy. Bạn có thể gửi lệnh tới nó thông qua stdio. Nhưng công cụ kiểm soát cấu hình chính của chúng tôi là ansible nên nó có một mô-đun tích hợp để quản lý HAProxy. Mà chúng tôi tích cực sử dụng.
- Hầu hết các dịch vụ API và Engine của chúng tôi đều hỗ trợ các công nghệ tắt máy nhẹ nhàng: khi tắt, chúng đợi tác vụ hiện tại hoàn thành, có thể là yêu cầu http hoặc một số tác vụ dịch vụ. Điều tương tự cũng xảy ra với người công nhân. Nó biết tất cả các nhiệm vụ nó đang làm và kết thúc khi nó đã hoàn thành xuất sắc mọi việc.
Nhờ hai điểm này mà thuật toán an toàn cho việc triển khai của chúng ta trông như thế này.
- Nhà phát triển tập hợp một gói mã mới (đối với chúng tôi đây là RPM), kiểm tra nó trong môi trường nhà phát triển, kiểm tra nó trong giai đoạn và để nó trong kho lưu trữ giai đoạn.
- Nhà phát triển đặt nhiệm vụ triển khai với mô tả chi tiết nhất về “tạo phẩm”: phiên bản của gói mới, mô tả về chức năng mới và các chi tiết khác về việc triển khai nếu cần.
- Quản trị viên hệ thống bắt đầu cập nhật. Khởi chạy Playbook Ansible, sau đó Playbook sẽ thực hiện những việc sau:
- Lấy một gói từ kho lưu trữ giai đoạn và sử dụng gói đó để cập nhật phiên bản của gói trong kho lưu trữ sản phẩm.
- Biên soạn danh sách các chương trình phụ trợ của dịch vụ được cập nhật.
- Tắt dịch vụ đầu tiên được cập nhật trong HAProxy và đợi các quá trình của nó chạy xong. Nhờ quá trình tắt máy nhẹ nhàng, chúng tôi tin tưởng rằng tất cả các yêu cầu hiện tại của khách hàng sẽ hoàn tất thành công.
- Sau khi API và công nhân bị dừng hoàn toàn và HAProxy bị tắt, mã sẽ được cập nhật.
- Ansible chạy các dịch vụ.
- Đối với mỗi dịch vụ, một số "tay cầm" nhất định sẽ được kéo để thực hiện kiểm tra đơn vị trên một số kiểm tra chính được xác định trước. Quá trình kiểm tra cơ bản của mã mới diễn ra.
- Nếu không tìm thấy lỗi ở bước trước, phần phụ trợ sẽ được kích hoạt.
- Hãy chuyển sang phần phụ trợ tiếp theo.
- Sau khi tất cả các chương trình phụ trợ được cập nhật, các thử nghiệm chức năng sẽ được khởi chạy. Nếu chúng bị thiếu, nhà phát triển sẽ xem xét mọi chức năng mới mà mình đã tạo.
Điều này hoàn thành việc triển khai.
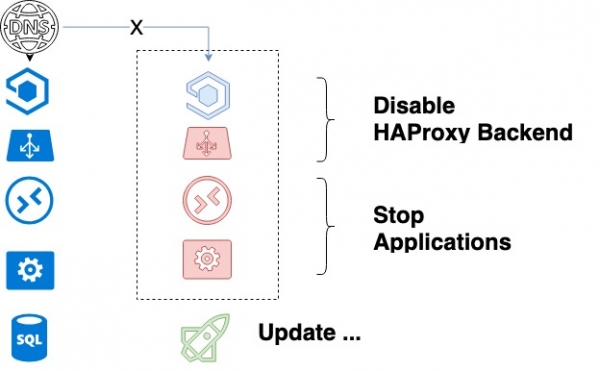
Chu kỳ cập nhật dịch vụ
Kế hoạch này sẽ không hoạt động nếu chúng ta không có một quy tắc. Chúng tôi hỗ trợ cả phiên bản cũ và mới trong trận chiến. Trước đó, ở giai đoạn phát triển phần mềm, người ta đã quy định rằng ngay cả khi có những thay đổi trong cơ sở dữ liệu dịch vụ, chúng sẽ không phá vỡ mã trước đó. Kết quả là cơ sở mã được cập nhật dần dần.
Kết luận
Chia sẻ suy nghĩ của riêng tôi về kiến trúc WEB có khả năng chịu lỗi, một lần nữa tôi muốn lưu ý những điểm chính của nó:
- khả năng chịu lỗi vật lý;
- khả năng chịu lỗi mạng (bộ cân bằng, BGP);
- khả năng chịu lỗi của phần mềm được sử dụng và phát triển.
Thời gian hoạt động ổn định nhé mọi người!
Nguồn: www.habr.com
