


Kể từ năm 2008, công ty chúng tôi chủ yếu tham gia quản lý cơ sở hạ tầng và hỗ trợ kỹ thuật 400/15 cho các dự án web: chúng tôi có hơn 15 khách hàng, chiếm khoảng XNUMX% thương mại điện tử của Nga. Theo đó, một kiến trúc rất đa dạng được hỗ trợ. Nếu có thứ gì đó rơi xuống, chúng tôi có nghĩa vụ phải sửa nó trong vòng XNUMX phút. Nhưng để hiểu rằng một tai nạn đã xảy ra, bạn cần theo dõi dự án và ứng phó với các sự cố. làm như thế nào?
Tôi tin rằng có vấn đề trong việc tổ chức một hệ thống giám sát phù hợp. Nếu không có vấn đề gì thì bài phát biểu của tôi sẽ chỉ có một luận điểm: “Hãy cài đặt Prometheus + Grafana và các plugin 1, 2, 3.” Thật không may, nó không còn hoạt động theo cách đó nữa. Và vấn đề chính là mọi người vẫn tiếp tục tin vào thứ đã tồn tại từ năm 2008, về mặt thành phần phần mềm.
Về việc tổ chức hệ thống giám sát, tôi xin mạo muội nói rằng... không có dự án nào có năng lực giám sát. Và tình hình tồi tệ đến mức nếu có thứ gì đó rơi xuống, có nguy cơ nó sẽ không được chú ý - sau cùng, mọi người đều chắc chắn rằng “mọi thứ đều được giám sát”.
Có lẽ mọi thứ đang được theo dõi. Nhưng bằng cách nào?
Tất cả chúng ta đều từng gặp phải một câu chuyện như sau: một devops nào đó, một quản trị viên nào đó đang làm việc, một nhóm phát triển đến gặp họ và nói - “chúng tôi đã được phát hành, bây giờ hãy theo dõi”. Giám sát cái gì? Làm thế nào nó hoạt động?
ĐƯỢC RỒI. Chúng tôi giám sát theo cách cũ. Và nó đã thay đổi, và hóa ra là bạn đã giám sát dịch vụ A, dịch vụ này trở thành dịch vụ B, tương tác với dịch vụ C. Nhưng nhóm phát triển nói với bạn: “Hãy cài đặt phần mềm, nó sẽ giám sát mọi thứ!”
Vậy điều gì đã thay đổi? - Mọi thứ đã thay đổi!
2008 Mọi thứ đều ổn
Có một vài nhà phát triển, một máy chủ, một máy chủ cơ sở dữ liệu. Mọi chuyện bắt đầu từ đây. Chúng tôi có một số thông tin, chúng tôi cài đặt zabbix, Nagios, cacti. Sau đó, chúng tôi đặt cảnh báo rõ ràng về CPU, hoạt động của ổ đĩa và dung lượng ổ đĩa. Chúng tôi cũng thực hiện một số kiểm tra thủ công để đảm bảo rằng trang web phản hồi và các đơn đặt hàng sẽ đến cơ sở dữ liệu. Và thế là xong – chúng ta ít nhiều được bảo vệ.
Nếu chúng ta so sánh khối lượng công việc mà quản trị viên đã làm khi đó để cung cấp dịch vụ giám sát thì 98% trong số đó là tự động: người thực hiện giám sát phải hiểu cách cài đặt Zabbix, cách định cấu hình và định cấu hình cảnh báo. Và 2% - để kiểm tra bên ngoài: trang web phản hồi và đưa ra yêu cầu tới cơ sở dữ liệu, các đơn đặt hàng mới đã đến.
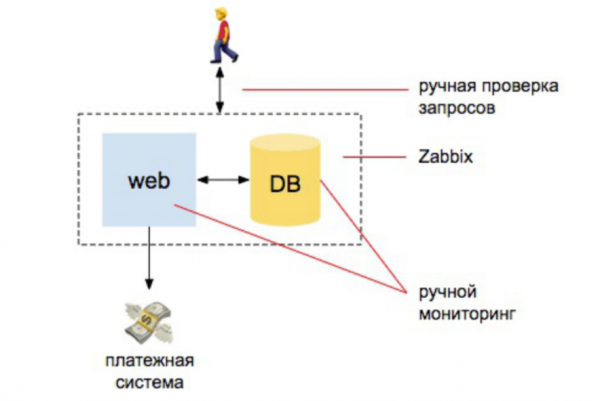
2010 Tải trọng ngày càng tăng
Chúng tôi đang bắt đầu mở rộng quy mô trang web và thêm công cụ tìm kiếm. Chúng tôi muốn đảm bảo rằng danh mục sản phẩm chứa tất cả các sản phẩm và chức năng tìm kiếm sản phẩm hoạt động tốt. Cơ sở dữ liệu hoạt động, đơn đặt hàng được xử lý, trang web phản hồi từ bên ngoài và phản hồi hai chiều. may chủ và người dùng không bị văng ra khỏi trang web trong khi trang web đang được cân bằng lại sang máy chủ khác, v.v. Số lượng thực thể tăng lên.
Hơn nữa, thực thể liên quan đến cơ sở hạ tầng vẫn là thực thể lớn nhất trong đầu người quản lý. Trong đầu tôi vẫn có ý tưởng rằng người thực hiện giám sát là người sẽ cài đặt zabbix và có khả năng cấu hình nó.
Nhưng đồng thời, xuất hiện công việc tiến hành kiểm tra bên ngoài, tạo một tập lệnh truy vấn của bộ chỉ mục tìm kiếm, một tập lệnh để kiểm tra xem tìm kiếm có thay đổi trong quá trình lập chỉ mục hay không, một tập lệnh kiểm tra xem hàng hóa có được chuyển đến dịch vụ giao hàng, vv và như thế.
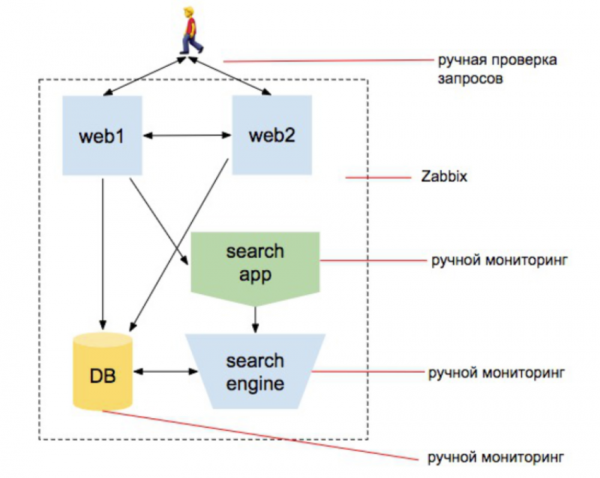
Lưu ý: Tôi đã viết “một bộ kịch bản” 3 lần. Nghĩa là, người chịu trách nhiệm giám sát không còn là người chỉ cài đặt zabbix nữa. Đây là người bắt đầu viết mã. Nhưng vẫn chưa có gì thay đổi trong suy nghĩ của cả đội.
Nhưng thế giới đang thay đổi, ngày càng trở nên phức tạp hơn. Một lớp ảo hóa và một số hệ thống mới được thêm vào. Họ bắt đầu tương tác với nhau. Ai nói “có mùi giống như microservices?” Nhưng mỗi dịch vụ vẫn trông giống như một trang web riêng lẻ. Chúng ta có thể sử dụng nó và hiểu rằng nó cung cấp thông tin cần thiết và tự hoạt động. Và nếu bạn là quản trị viên thường xuyên tham gia vào một dự án đã phát triển trong 5-7-10 năm, kiến thức này sẽ tích lũy: một cấp độ mới xuất hiện - bạn đã nhận ra nó, một cấp độ khác xuất hiện - bạn đã nhận ra nó...
Nhưng hiếm có ai đồng hành cùng một dự án suốt 10 năm.
Sơ yếu lý lịch của giám sát viên
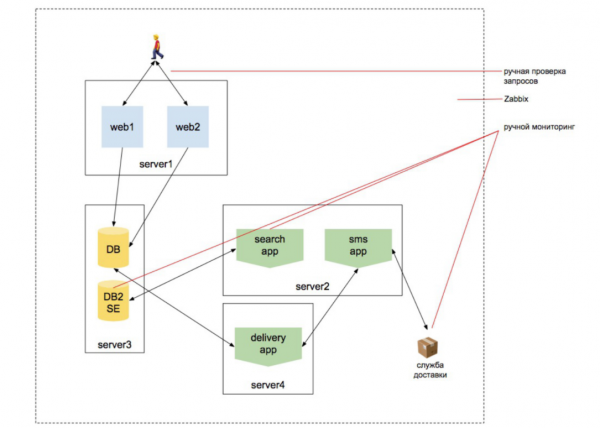
Giả sử bạn đến với một công ty khởi nghiệp mới và ngay lập tức thuê 20 nhà phát triển, viết 15 dịch vụ vi mô và bạn là quản trị viên được thông báo: “Xây dựng CI/CD. Vui lòng." Bạn đã xây dựng CI/CD và đột nhiên bạn nghe thấy: “Thật khó để chúng tôi làm việc sản xuất trong một “khối lập phương” mà không hiểu ứng dụng sẽ hoạt động như thế nào trong đó. Hãy tạo cho chúng tôi một hộp cát trong cùng một “khối lập phương”.
Bạn tạo một hộp cát trong khối này. Họ ngay lập tức nói với bạn: “Chúng tôi muốn một cơ sở dữ liệu giai đoạn được cập nhật hàng ngày từ quá trình sản xuất, để chúng tôi hiểu rằng nó hoạt động trên cơ sở dữ liệu, nhưng đồng thời không làm hỏng cơ sở dữ liệu sản xuất”.
Bạn sống trong tất cả những điều này. Còn 2 tuần nữa là đến ngày phát hành, họ nói với bạn: “Bây giờ hãy theo dõi tất cả những điều này…” Tức là vậy. giám sát cơ sở hạ tầng cụm, giám sát kiến trúc microservice, giám sát công việc với các dịch vụ bên ngoài...
Và các đồng nghiệp của tôi loại bỏ kế hoạch thông thường ra khỏi đầu họ và nói: “Chà, mọi thứ ở đây đều rõ ràng! Cài đặt một chương trình sẽ giám sát tất cả điều này.” Có, vâng: Prometheus + Grafana + plugin.
Và họ nói thêm: “Bạn có hai tuần, hãy đảm bảo mọi thứ đều an toàn.”
Trong rất nhiều dự án mà chúng tôi thấy, chỉ có một người được giao nhiệm vụ giám sát. Hãy tưởng tượng rằng chúng tôi muốn thuê một người làm công việc giám sát trong 2 tuần và chúng tôi viết sơ yếu lý lịch cho anh ta. Người này nên có những kỹ năng gì dựa trên tất cả những gì chúng ta đã nói cho đến nay?
- Anh ta phải hiểu rõ việc giám sát và các chi tiết cụ thể về hoạt động của cơ sở hạ tầng sắt.
- Anh ta phải hiểu các chi tiết cụ thể của việc giám sát Kubernetes (và mọi người đều muốn đi đến “khối lập phương”, bởi vì bạn có thể trừu tượng hóa mọi thứ, ẩn đi, vì quản trị viên sẽ giải quyết phần còn lại) - chính nó, cơ sở hạ tầng của nó và hiểu cách giám sát các ứng dụng bên trong.
- Anh ta phải hiểu rằng các dịch vụ giao tiếp với nhau theo những cách đặc biệt và biết chi tiết cụ thể về cách các dịch vụ tương tác với nhau. Hoàn toàn có thể thấy một dự án trong đó một số dịch vụ giao tiếp đồng bộ vì không có cách nào khác. Ví dụ: phần phụ trợ đi qua REST, qua gRPC đến dịch vụ danh mục, nhận danh sách các sản phẩm và trả lại. Bạn không thể đợi ở đây. Và với các dịch vụ khác, nó hoạt động không đồng bộ. Chuyển đơn hàng đến dịch vụ giao hàng, gửi thư, v.v.
Có lẽ bạn đã bơi khỏi tất cả những điều này? Và quản trị viên, người cần theo dõi việc này, lại càng bối rối hơn. - Anh ta phải có khả năng lập kế hoạch và lập kế hoạch một cách chính xác - khi công việc ngày càng nhiều.
- Do đó, anh ta phải tạo ra một chiến lược từ dịch vụ đã tạo để hiểu cách giám sát cụ thể nó. Anh ta cần hiểu biết về kiến trúc của dự án và sự phát triển của nó + hiểu biết về các công nghệ được sử dụng trong quá trình phát triển.
Hãy nhớ một trường hợp hoàn toàn bình thường: một số dịch vụ bằng PHP, một số dịch vụ bằng Go, một số dịch vụ bằng JS. Họ bằng cách nào đó làm việc với nhau. Đây là nơi xuất phát thuật ngữ “microservice”: có rất nhiều hệ thống riêng lẻ mà các nhà phát triển không thể hiểu được toàn bộ dự án. Một phần của nhóm viết các dịch vụ trong JS tự hoạt động và không biết phần còn lại của hệ thống hoạt động như thế nào. Phần còn lại viết các dịch vụ bằng Python và không can thiệp vào cách các dịch vụ khác hoạt động; chúng được tách biệt trong khu vực riêng của chúng. Cách thứ ba là viết dịch vụ bằng PHP hoặc thứ gì khác.
Tất cả 20 người này được chia thành 15 dịch vụ và chỉ có một quản trị viên phải hiểu tất cả những điều này. Dừng lại! chúng tôi chỉ chia hệ thống thành 15 vi dịch vụ vì 20 người không thể hiểu được toàn bộ hệ thống.
Nhưng nó cần được theo dõi bằng cách nào đó...
Kết quả là gì? Kết quả là, có một người nghĩ ra mọi thứ mà cả nhóm nhà phát triển không thể hiểu được, đồng thời anh ta cũng phải biết và có thể làm được những gì chúng tôi đã chỉ ra ở trên - cơ sở hạ tầng phần cứng, cơ sở hạ tầng Kubernetes, v.v.
Tôi có thể nói gì đây... Houston, chúng ta có vấn đề.
Giám sát một dự án phần mềm hiện đại bản thân nó là một dự án phần mềm
Từ niềm tin sai lầm rằng việc giám sát là phần mềm, chúng ta phát triển niềm tin vào những điều kỳ diệu. Nhưng than ôi, điều kỳ diệu đã không xảy ra. Bạn không thể cài đặt zabbix và mong đợi mọi thứ hoạt động. Chẳng ích gì khi cài đặt Grafana và hy vọng rằng mọi thứ sẽ ổn. Phần lớn thời gian sẽ được dành cho việc tổ chức kiểm tra hoạt động của các dịch vụ và sự tương tác của chúng với nhau, kiểm tra cách hoạt động của các hệ thống bên ngoài. Trên thực tế, 90% thời gian sẽ không dành cho việc viết kịch bản mà là phát triển phần mềm. Và nó phải được xử lý bởi một nhóm hiểu rõ công việc của dự án.
Nếu trong tình huống này, một người bị đưa vào tầm giám sát thì thảm họa sẽ xảy ra. Đó là những gì xảy ra ở khắp mọi nơi.
Ví dụ: có một số dịch vụ liên lạc với nhau thông qua Kafka. Đơn hàng đã đến, chúng tôi gửi tin nhắn về đơn hàng cho Kafka. Có dịch vụ lắng nghe thông tin đơn hàng và vận chuyển hàng hóa. Có một dịch vụ lắng nghe thông tin về đơn hàng và gửi thư cho người dùng. Và sau đó, một loạt dịch vụ khác xuất hiện và chúng ta bắt đầu bối rối.
Và nếu bạn cũng đưa cái này cho quản trị viên và nhà phát triển ở giai đoạn chỉ còn một thời gian ngắn trước khi phát hành, người đó sẽ cần phải hiểu toàn bộ giao thức này. Những thứ kia. Một dự án ở quy mô này cần một lượng thời gian đáng kể và điều này cần được tính đến trong quá trình phát triển hệ thống.
Nhưng rất thường xuyên, đặc biệt là ở các công ty khởi nghiệp, chúng tôi thấy việc giám sát bị trì hoãn cho đến sau này. “Bây giờ chúng tôi sẽ tạo ra Bằng chứng về Khái niệm, chúng tôi sẽ phóng cùng nó, để nó rơi - chúng tôi sẵn sàng hy sinh. Và sau đó chúng tôi sẽ theo dõi tất cả.” Khi (hoặc nếu) dự án bắt đầu kiếm tiền, doanh nghiệp muốn bổ sung thêm nhiều tính năng hơn nữa - vì nó đã bắt đầu hoạt động nên cần phải triển khai thêm! Và bạn đang ở thời điểm mà trước tiên bạn cần theo dõi mọi thứ trước đó, việc này không chỉ chiếm 1% thời gian mà còn nhiều hơn thế. Và nhân tiện, sẽ cần có các nhà phát triển để giám sát và việc để họ làm việc trên các tính năng mới sẽ dễ dàng hơn. Kết quả là, các tính năng mới được viết ra, mọi thứ trở nên rối tung và bạn rơi vào tình trạng bế tắc vô tận.
Vậy làm thế nào để giám sát một dự án ngay từ đầu và phải làm gì nếu bạn nhận được một dự án cần được giám sát nhưng không biết bắt đầu từ đâu?
Đầu tiên, bạn cần lập kế hoạch.
Lạc đề trữ tình: họ thường bắt đầu bằng việc giám sát cơ sở hạ tầng. Ví dụ: chúng ta có Kubernetes. Hãy bắt đầu bằng cách cài đặt Prometheus với Grafana, cài đặt các plugin để theo dõi “khối lập phương”. Không chỉ các nhà phát triển mà cả các quản trị viên cũng có một thực tế đáng tiếc là: “Chúng tôi sẽ cài đặt plugin này, nhưng plugin đó có thể biết cách thực hiện”. Mọi người thích bắt đầu với những việc đơn giản và dễ hiểu hơn là những hành động quan trọng. Và giám sát cơ sở hạ tầng là dễ dàng.
Đầu tiên, hãy quyết định xem bạn muốn giám sát nội dung và cách thức, sau đó chọn một công cụ vì người khác không thể nghĩ thay bạn. Và họ có nên làm vậy không? Những người khác tự nghĩ về một hệ thống phổ quát - hoặc hoàn toàn không nghĩ gì khi plugin này được viết. Và chỉ vì plugin này có 5 nghìn người dùng không có nghĩa là nó có tác dụng gì. Có lẽ bạn sẽ trở thành người thứ 5001 đơn giản vì trước đó đã có 5000 người rồi.
Nếu bạn bắt đầu giám sát cơ sở hạ tầng và phần phụ trợ của ứng dụng ngừng phản hồi, tất cả người dùng sẽ mất kết nối với ứng dụng di động. Một lỗi sẽ xuất hiện. Họ sẽ đến gặp bạn và nói "Ứng dụng không hoạt động, bạn đang làm gì ở đây?" - “Chúng tôi đang theo dõi.” — “Làm thế nào để bạn giám sát nếu bạn không thấy ứng dụng không hoạt động?!”
- Tôi tin rằng bạn cần bắt đầu theo dõi chính xác từ điểm vào của người dùng. Nếu người dùng không thấy ứng dụng đang hoạt động thì đó là lỗi. Và hệ thống giám sát nên cảnh báo về điều này trước tiên.
- Và chỉ khi đó chúng ta mới có thể giám sát cơ sở hạ tầng. Hoặc làm song song. Nó dễ dàng hơn với cơ sở hạ tầng - ở đây cuối cùng chúng ta cũng có thể cài đặt zabbix.
- Và bây giờ bạn cần đi sâu vào phần gốc của ứng dụng để hiểu mọi thứ không hoạt động ở đâu.
Ý tưởng chính của tôi là việc giám sát nên đi song song với quá trình phát triển. Nếu bạn đánh lạc hướng nhóm giám sát để thực hiện các nhiệm vụ khác (tạo CI/CD, sandboxing, tổ chức lại cơ sở hạ tầng), việc giám sát sẽ bắt đầu tụt hậu và bạn có thể không bao giờ bắt kịp sự phát triển (hoặc sớm hay muộn bạn sẽ phải dừng nó lại).
Mọi thứ theo cấp độ
Đây là cách tôi nhìn nhận việc tổ chức một hệ thống giám sát.
1) Cấp độ ứng dụng:
- giám sát logic kinh doanh của ứng dụng;
- theo dõi số liệu sức khỏe của dịch vụ;
- giám sát hội nhập.
2) Cấp độ cơ sở hạ tầng:
- giám sát mức độ điều phối;
- giám sát phần mềm hệ thống;
- giám sát mức độ sắt.
3) Một lần nữa ở cấp độ ứng dụng - nhưng với tư cách là một sản phẩm kỹ thuật:
- thu thập và giám sát nhật ký ứng dụng;
- APM;
- truy tìm.
4) Cảnh báo:
- tổ chức hệ thống cảnh báo;
- tổ chức hệ thống nhiệm vụ;
- tổ chức “cơ sở tri thức” và quy trình làm việc để xử lý sự cố.
Điều quan trọng là: chúng tôi nhận được cảnh báo không phải sau đó mà ngay lập tức! Không cần thiết phải triển khai giám sát và “bằng cách nào đó sau” sẽ tìm ra ai sẽ nhận được cảnh báo. Suy cho cùng, nhiệm vụ của giám sát là gì: để hiểu có vấn đề gì đó đang xảy ra sai sót ở đâu trong hệ thống và thông báo cho đúng người về vấn đề đó. Nếu bạn để điều này đến cuối cùng thì những người phù hợp sẽ biết rằng có điều gì đó không ổn chỉ bằng cách nói rằng “không có gì hiệu quả với chúng tôi”.
Lớp ứng dụng - Giám sát logic nghiệp vụ
Ở đây chúng ta đang nói về việc kiểm tra xem ứng dụng có hoạt động tốt cho người dùng hay không.
Mức độ này nên được thực hiện trong giai đoạn phát triển. Ví dụ: chúng ta có một Prometheus có điều kiện: nó đi đến máy chủ thực hiện kiểm tra, lấy điểm cuối và điểm cuối đi kiểm tra API.
Khi thường được yêu cầu giám sát trang chủ để đảm bảo trang web đang hoạt động, các lập trình viên sẽ đưa ra một tay cầm có thể kéo ra mỗi khi họ cần để đảm bảo rằng API đang hoạt động. Và các lập trình viên tại thời điểm này vẫn lấy và viết /api/test/helloworld
Cách duy nhất để đảm bảo mọi thứ hoạt động? - KHÔNG!
- Tạo các kiểm tra như vậy về cơ bản là nhiệm vụ của các nhà phát triển. Các bài kiểm tra đơn vị nên được viết bởi các lập trình viên viết mã. Bởi vì nếu bạn tiết lộ nó cho quản trị viên, “Anh bạn, đây là danh sách các giao thức API cho tất cả 25 chức năng, vui lòng theo dõi mọi thứ!” - sẽ không có việc gì đâu.
- Nếu bạn in “hello world”, sẽ không ai biết rằng API sẽ hoạt động. Mọi thay đổi API đều phải dẫn đến thay đổi về kiểm tra.
- Nếu bạn đã gặp phải vấn đề như vậy, hãy dừng các tính năng và chỉ định các nhà phát triển sẽ viết các kiểm tra này hoặc chấp nhận thua lỗ, chấp nhận rằng không có gì được kiểm tra và sẽ thất bại.
Mẹo kỹ thuật:
- Đảm bảo tổ chức một máy chủ bên ngoài để tổ chức kiểm tra - bạn phải chắc chắn rằng dự án của bạn có thể truy cập được với thế giới bên ngoài.
- Tổ chức kiểm tra trên toàn bộ giao thức API, không chỉ các điểm cuối riêng lẻ.
- Tạo điểm cuối prometheus với kết quả kiểm tra.
Lớp ứng dụng - theo dõi số liệu sức khỏe
Bây giờ chúng ta đang nói về các thước đo sức khỏe bên ngoài của dịch vụ.
Chúng tôi quyết định rằng chúng tôi giám sát tất cả các “tay cầm” của ứng dụng bằng cách sử dụng các kiểm tra bên ngoài mà chúng tôi gọi từ hệ thống giám sát bên ngoài. Nhưng đây là những “tay cầm” mà người dùng “nhìn thấy”. Chúng tôi muốn chắc chắn rằng các dịch vụ của chúng tôi hoạt động. Có một câu chuyện hay hơn ở đây: K8s có các cuộc kiểm tra tình trạng, để ít nhất bản thân “khối lập phương” có thể được thuyết phục rằng dịch vụ này đang hoạt động. Nhưng một nửa số séc tôi từng thấy đều có dòng chữ in “hello world”. Những thứ kia. Vì vậy, anh ấy kéo một lần sau khi triển khai, anh ấy trả lời rằng mọi thứ đều ổn - chỉ vậy thôi. Và dịch vụ, nếu cung cấp API riêng, sẽ có một số lượng lớn điểm truy cập cho cùng một API đó, điều này cũng cần được theo dõi vì chúng tôi muốn biết rằng nó hoạt động. Và chúng tôi đã theo dõi nó bên trong.
Cách triển khai điều này một cách chính xác về mặt kỹ thuật: mỗi dịch vụ hiển thị điểm cuối về hiệu suất hiện tại của nó và trong biểu đồ của Grafana (hoặc bất kỳ ứng dụng nào khác), chúng ta thấy trạng thái của tất cả các dịch vụ.
- Mọi thay đổi API đều phải dẫn đến thay đổi về kiểm tra.
- Tạo ngay một dịch vụ mới với các chỉ số sức khỏe.
- Quản trị viên có thể đến gặp nhà phát triển và yêu cầu “thêm cho tôi một số tính năng để tôi hiểu mọi thứ và thêm thông tin về vấn đề này vào hệ thống giám sát của mình”. Nhưng các nhà phát triển thường trả lời: “Chúng tôi sẽ không thêm bất cứ thứ gì vào hai tuần trước khi phát hành”.
Hãy để những người quản lý phát triển biết rằng sẽ có những tổn thất như vậy, hãy để ban lãnh đạo của những người quản lý phát triển cũng biết. Vì khi mọi thứ sụp đổ thì vẫn sẽ có người gọi điện yêu cầu giám sát “dịch vụ rớt liên tục” (c) - Nhân tiện, hãy phân công các nhà phát triển viết plugin cho Grafana - đây sẽ là một trợ giúp tốt cho quản trị viên.
Lớp ứng dụng - Giám sát tích hợp
Giám sát tích hợp tập trung vào giám sát thông tin liên lạc giữa các hệ thống quan trọng trong kinh doanh.
Ví dụ: có 15 dịch vụ liên lạc với nhau. Đây không còn là những trang web riêng biệt nữa. Những thứ kia. chúng tôi không thể tự mình kéo dịch vụ, nhận /helloworld và hiểu rằng dịch vụ đang chạy. Vì dịch vụ web đặt hàng phải gửi thông tin về đơn hàng đến xe buýt - từ xe buýt nên dịch vụ kho hàng phải nhận được thông báo này và xử lý thêm. Và dịch vụ phân phối email phải xử lý việc này thêm nữa, v.v.
Theo đó, chúng ta không thể hiểu được khi chọc vào từng dịch vụ riêng lẻ rằng tất cả đều hoạt động. Bởi vì chúng ta có một chiếc xe buýt nhất định mà qua đó mọi thứ đều giao tiếp và tương tác.
Vì vậy, giai đoạn này cần đánh dấu giai đoạn thử nghiệm các dịch vụ về khả năng tương tác với các dịch vụ khác. Không thể tổ chức giám sát liên lạc bằng cách giám sát nhà môi giới tin nhắn. Nếu có dịch vụ phát hành dữ liệu và dịch vụ nhận dữ liệu thì khi theo dõi nhà môi giới chúng ta sẽ chỉ thấy dữ liệu chuyển từ bên này sang bên kia. Ngay cả khi bằng cách nào đó chúng tôi quản lý để theo dõi sự tương tác của dữ liệu này trong nội bộ - rằng một nhà sản xuất nào đó đăng dữ liệu, ai đó đọc dữ liệu đó, luồng này vẫn tiếp tục chuyển đến Kafka - điều này vẫn sẽ không cung cấp cho chúng tôi thông tin nếu một dịch vụ gửi tin nhắn trong một phiên bản , còn dịch vụ kia không mong đợi phiên bản này nên đã bỏ qua. Chúng tôi sẽ không biết về điều này vì các dịch vụ sẽ cho chúng tôi biết rằng mọi thứ đều hoạt động.
Những gì tôi khuyên bạn nên làm:
- Đối với giao tiếp đồng bộ: điểm cuối đưa ra yêu cầu tới các dịch vụ liên quan. Những thứ kia. chúng tôi lấy điểm cuối này, kéo một tập lệnh bên trong dịch vụ, đi đến tất cả các điểm và nói "Tôi có thể kéo đến đó và kéo đến đó, tôi có thể kéo đến đó..."
- Đối với giao tiếp không đồng bộ: tin nhắn đến - điểm cuối kiểm tra bus để tìm tin nhắn kiểm tra và hiển thị trạng thái xử lý.
- Đối với giao tiếp không đồng bộ: tin nhắn gửi đi - điểm cuối gửi tin nhắn kiểm tra tới xe buýt.
Như thường lệ: chúng tôi có một dịch vụ đưa dữ liệu vào xe buýt. Chúng tôi đến với dịch vụ này và yêu cầu bạn cho chúng tôi biết về tình trạng tích hợp của nó. Và nếu dịch vụ cần tạo thông báo ở đâu đó xa hơn (WebApp), thì dịch vụ sẽ tạo thông báo thử nghiệm này. Và nếu chúng tôi chạy một dịch vụ ở phía OrderProcessing, trước tiên nó sẽ đăng những gì nó có thể đăng độc lập và nếu có một số thứ phụ thuộc thì nó sẽ đọc một tập hợp các tin nhắn kiểm tra từ xe buýt, hiểu rằng nó có thể xử lý chúng, báo cáo và , nếu cần, hãy đăng thêm chúng, và anh ấy nói về điều này - mọi thứ đều ổn, tôi còn sống.
Chúng tôi rất thường xuyên nghe thấy câu hỏi "làm cách nào chúng tôi có thể kiểm tra điều này trên dữ liệu chiến đấu?" Ví dụ, chúng ta đang nói về cùng một dịch vụ đặt hàng. Lệnh gửi tin nhắn đến nhà kho nơi hàng hóa bị xóa sổ: chúng tôi không thể kiểm tra điều này trên dữ liệu chiến đấu, bởi vì “hàng hóa của tôi sẽ bị xóa sổ!” Giải pháp: Lập kế hoạch cho toàn bộ bài kiểm tra này ngay từ đầu. Bạn cũng có các bài kiểm tra đơn vị để tạo ra các bản mô phỏng. Vì vậy, hãy làm ở mức độ sâu hơn khi bạn có kênh liên lạc không gây tổn hại đến hoạt động của doanh nghiệp.
Lớp cơ sở hạ tầng
Giám sát cơ sở hạ tầng là thứ từ lâu đã được coi là giám sát.
- Giám sát cơ sở hạ tầng có thể và nên được triển khai như một quy trình riêng biệt.
- Bạn không nên bắt đầu bằng việc giám sát cơ sở hạ tầng trong một dự án đang chạy, ngay cả khi bạn thực sự muốn. Đây là một nỗi đau cho tất cả các devops. “Đầu tiên tôi sẽ giám sát cụm, tôi sẽ giám sát cơ sở hạ tầng” – tức là. Đầu tiên, nó sẽ giám sát những gì nằm bên dưới, nhưng sẽ không đi vào ứng dụng. Bởi vì ứng dụng là một thứ khó hiểu đối với các devops. Nó đã bị rò rỉ cho anh ấy và anh ấy không hiểu nó hoạt động như thế nào. Và anh ấy hiểu cơ sở hạ tầng và bắt đầu với nó. Nhưng không - bạn luôn cần theo dõi ứng dụng trước.
- Đừng quá nhiệt tình với số lượng cảnh báo. Xem xét sự phức tạp của các hệ thống hiện đại, các cảnh báo liên tục xuất hiện và bằng cách nào đó bạn phải sống chung với hàng loạt cảnh báo này. Và người trực điện thoại, sau khi xem hàng trăm cảnh báo tiếp theo, sẽ quyết định “Tôi không muốn nghĩ về điều đó”. Cảnh báo chỉ nên thông báo về những điều quan trọng.
Cấp độ ứng dụng như một đơn vị kinh doanh
Những điểm chính:
- ELK. Đây là tiêu chuẩn của ngành. Nếu vì lý do nào đó mà bạn không tổng hợp nhật ký, hãy bắt đầu thực hiện ngay lập tức.
- APM. APM bên ngoài như một cách để nhanh chóng đóng tính năng giám sát ứng dụng (NewRelic, BlackFire, Datadog). Bạn có thể tạm thời cài đặt thứ này để ít nhất bằng cách nào đó hiểu được chuyện gì đang xảy ra với mình.
- Truy tìm. Trong hàng chục vi dịch vụ, bạn phải theo dõi mọi thứ vì yêu cầu không còn tồn tại nữa. Rất khó để bổ sung sau, vì vậy tốt hơn hết bạn nên lập lịch truy tìm ngay lập tức trong quá trình phát triển - đây là công việc và tiện ích của các nhà phát triển. Nếu bạn chưa thực hiện nó, hãy thực hiện nó! Xem Jaeger/Zipkin
Cảnh báo
- Tổ chức hệ thống thông báo: trong điều kiện giám sát nhiều thứ thì cần có hệ thống gửi thông báo thống nhất. Bạn có thể ở Grafana. Ở phương Tây, mọi người đều sử dụng PagerDuty. Cảnh báo phải rõ ràng (ví dụ: chúng đến từ đâu...). Và nên kiểm soát việc nhận được thông báo nào
- Tổ chức hệ thống trực: không được gửi cảnh báo cho mọi người (hoặc mọi người sẽ phản ứng trong đám đông hoặc không ai phản ứng). Các nhà phát triển cũng cần phải trực: đảm bảo xác định các lĩnh vực trách nhiệm, đưa ra hướng dẫn rõ ràng và viết chính xác ai sẽ gọi vào Thứ Hai và Thứ Tư, và ai sẽ gọi vào Thứ Ba và Thứ Sáu (nếu không họ sẽ không gọi cho bất kỳ ai ngay cả trong nếu có vấn đề lớn - họ sẽ sợ đánh thức bạn hoặc làm phiền: mọi người thường không thích gọi điện và đánh thức người khác, đặc biệt là vào ban đêm). Và giải thích rằng việc yêu cầu giúp đỡ không phải là dấu hiệu của sự kém cỏi (“Tôi yêu cầu giúp đỡ, điều đó có nghĩa là tôi là một nhân viên tồi”), hãy khuyến khích yêu cầu giúp đỡ.
- Tổ chức “cơ sở kiến thức” và quy trình làm việc để xử lý sự cố: đối với mỗi sự cố nghiêm trọng, cần lập kế hoạch khám nghiệm tử thi và ghi lại các hành động sẽ giải quyết sự cố như một biện pháp tạm thời. Và biến việc cảnh báo lặp đi lặp lại là một tội lỗi; chúng cần được sửa chữa trong mã hoặc công việc cơ sở hạ tầng.
ngăn xếp công nghệ
Hãy tưởng tượng rằng ngăn xếp của chúng tôi như sau:
- thu thập dữ liệu - Prometheus + Grafana;
- phân tích nhật ký - ELK;
- cho APM hoặc Truy tìm - Jaeger (Zipkin).

Việc lựa chọn các phương án không quan trọng. Bởi vì nếu ngay từ đầu bạn đã hiểu cách giám sát hệ thống và viết ra kế hoạch thì bạn mới bắt đầu lựa chọn các công cụ phù hợp với yêu cầu của mình. Câu hỏi đặt ra là bạn đã chọn giám sát điều gì ngay từ đầu. Bởi có lẽ công cụ bạn chọn lúc đầu không phù hợp với yêu cầu của bạn chút nào.
Một số điểm kỹ thuật mà tôi thấy ở khắp mọi nơi gần đây:
Prometheus đang bị đẩy vào bên trong Kubernetes - ai đã nghĩ ra điều này?! Nếu cụm của bạn gặp sự cố, bạn sẽ làm gì? Nếu bạn có một cụm phức tạp bên trong thì cần có một số loại hệ thống giám sát bên trong cụm và một số bên ngoài sẽ thu thập dữ liệu từ bên trong cụm.
Bên trong cụm, chúng tôi thu thập nhật ký và mọi thứ khác. Nhưng hệ thống giám sát phải ở bên ngoài. Rất thường xuyên, trong một cụm nơi Promtheus được cài đặt nội bộ, cũng có những hệ thống thực hiện kiểm tra bên ngoài về hoạt động của trang web. Điều gì sẽ xảy ra nếu kết nối của bạn với thế giới bên ngoài bị ngắt và ứng dụng không hoạt động? Hóa ra mọi thứ bên trong đều ổn, nhưng nó không làm mọi việc dễ dàng hơn cho người dùng.
Những phát hiện
- Giám sát quá trình phát triển không phải là việc cài đặt các tiện ích mà là việc phát triển một sản phẩm phần mềm. 98% hoạt động giám sát ngày nay là mã hóa. Mã hóa trong các dịch vụ, mã hóa các kiểm tra bên ngoài, kiểm tra các dịch vụ bên ngoài, v.v.
- Đừng lãng phí thời gian của nhà phát triển vào việc giám sát: việc này có thể chiếm tới 30% công việc của họ nhưng rất đáng giá.
- Các Devops, đừng lo lắng rằng bạn không thể giám sát điều gì đó, bởi vì một số thứ có cách suy nghĩ hoàn toàn khác. Bạn không phải là lập trình viên và giám sát công việc chính xác là công việc của họ.
- Nếu dự án đang chạy và chưa được giám sát (và bạn là người quản lý), hãy phân bổ nguồn lực để giám sát.
- Nếu sản phẩm đã được sản xuất và bạn là một nhà phát triển được yêu cầu “thiết lập giám sát” - hãy cố gắng giải thích cho ban quản lý những gì tôi đã viết tất cả những điều này.
Đây là phiên bản mở rộng của báo cáo tại hội nghị Saint Highload++.
Nếu bạn quan tâm đến ý tưởng và suy nghĩ của tôi về nó cũng như các chủ đề liên quan, thì tại đây bạn có thể ????
Nguồn: www.habr.com
