

Người dùng của chúng tôi viết tin nhắn cho nhau mà không biết mệt mỏi.

Đó là khá nhiều. Nếu bạn bắt đầu đọc tất cả tin nhắn của tất cả người dùng thì sẽ mất hơn 150 nghìn năm. Với điều kiện bạn là người đọc khá nâng cao và dành không quá một giây cho mỗi tin nhắn.
Với khối lượng dữ liệu như vậy, điều quan trọng là logic để lưu trữ và truy cập dữ liệu đó phải được xây dựng một cách tối ưu. Nếu không, trong một khoảnh khắc không mấy tuyệt vời, có thể rõ ràng rằng mọi thứ sẽ sớm trở nên sai lầm.
Đối với chúng tôi, khoảnh khắc này đã đến cách đây một năm rưỡi. Làm thế nào chúng tôi đạt được điều này và cuối cùng điều gì đã xảy ra - chúng tôi sẽ kể cho bạn theo thứ tự.
hồ sơ lịch sử
Trong lần triển khai đầu tiên, các tin nhắn VKontakte hoạt động trên sự kết hợp giữa chương trình phụ trợ PHP và MySQL. Đây là giải pháp hoàn toàn bình thường đối với một website sinh viên nhỏ. Tuy nhiên, trang web này phát triển không kiểm soát và bắt đầu yêu cầu tối ưu hóa cấu trúc dữ liệu cho chính nó.
Vào cuối năm 2009, kho lưu trữ công cụ văn bản đầu tiên đã được viết và vào năm 2010, các tin nhắn đã được chuyển sang kho lưu trữ đó.
Trong công cụ văn bản, tin nhắn được lưu trữ trong danh sách - một loại “hộp thư”. Mỗi danh sách như vậy được xác định bởi một uid - người dùng sở hữu tất cả các tin nhắn này. Một tin nhắn có một tập hợp các thuộc tính: mã định danh người đối thoại, văn bản, tệp đính kèm, v.v. Mã định danh tin nhắn bên trong “hộp” là local_id, nó không bao giờ thay đổi và được gán tuần tự cho các tin nhắn mới. Các “hộp” này độc lập và không được đồng bộ hóa với nhau bên trong công cụ; giao tiếp giữa chúng xảy ra ở cấp độ PHP. Bạn có thể xem cấu trúc dữ liệu và khả năng của công cụ văn bản từ bên trong .
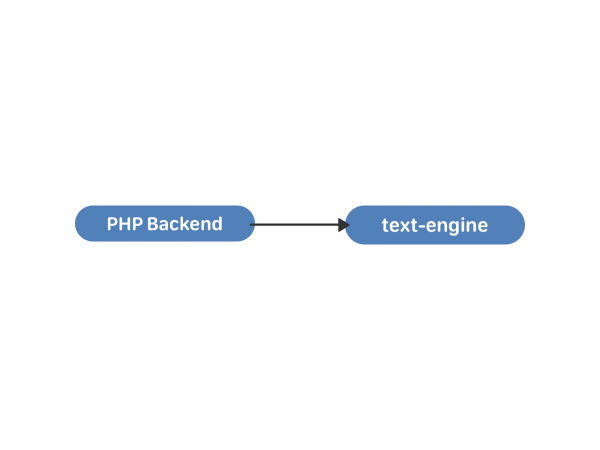
Điều này là khá đủ cho sự trao đổi thư từ giữa hai người dùng. Đoán xem chuyện gì xảy ra tiếp theo?
Vào tháng 2011 năm XNUMX, VKontakte đã giới thiệu các cuộc trò chuyện với một số người tham gia—trò chuyện nhiều lần. Để làm việc với họ, chúng tôi đã tạo ra hai cụm mới - cuộc trò chuyện của thành viên và thành viên trò chuyện. Cái đầu tiên lưu trữ dữ liệu về cuộc trò chuyện của người dùng, cái thứ hai lưu trữ dữ liệu về người dùng theo cuộc trò chuyện. Ngoài các danh sách, chẳng hạn như danh sách này còn bao gồm người dùng được mời và thời gian họ được thêm vào cuộc trò chuyện.
“PHP, hãy gửi tin nhắn tới cuộc trò chuyện,” người dùng nói.
“Nào, {tên người dùng},” PHP nói.
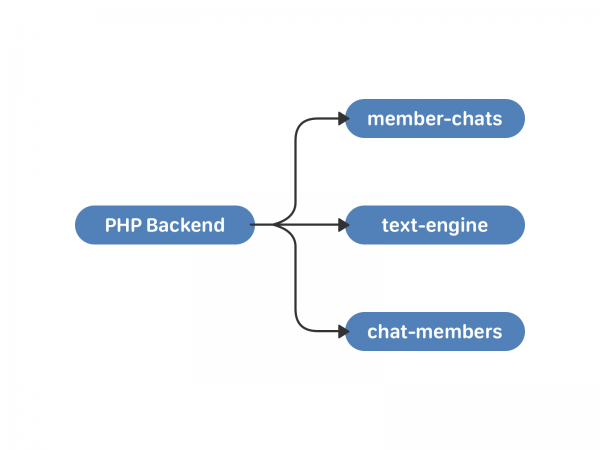
Có những nhược điểm của kế hoạch này. Đồng bộ hóa vẫn là trách nhiệm của PHP. Các cuộc trò chuyện lớn và những người dùng đồng thời gửi tin nhắn cho họ là một câu chuyện nguy hiểm. Vì phiên bản công cụ văn bản phụ thuộc vào uid nên những người tham gia trò chuyện có thể nhận được cùng một tin nhắn vào những thời điểm khác nhau. Người ta có thể sống chung với điều này nếu tiến độ vẫn đứng yên. Nhưng điều đó sẽ không xảy ra.
Vào cuối năm 2015, chúng tôi đã triển khai các thông báo cộng đồng và vào đầu năm 2016, chúng tôi đã triển khai API cho họ. Với sự ra đời của các chatbot lớn trong cộng đồng, người ta có thể quên đi việc phân phối tải đồng đều.
Một bot tốt tạo ra vài triệu tin nhắn mỗi ngày - ngay cả những người dùng nói nhiều nhất cũng không thể tự hào về điều này. Điều này có nghĩa là một số phiên bản của công cụ văn bản mà các bot như vậy hoạt động trên đó đã bắt đầu bị ảnh hưởng nặng nề nhất.
Công cụ nhắn tin trong năm 2016 có 100 trường hợp thành viên trò chuyện và trò chuyện thành viên và 8000 công cụ văn bản. Chúng được lưu trữ trên một nghìn máy chủ, mỗi máy chủ có bộ nhớ 64 GB. Là biện pháp khẩn cấp đầu tiên, chúng tôi đã tăng thêm bộ nhớ thêm 32 GB. Chúng tôi đã ước tính các dự báo. Nếu không có những thay đổi mạnh mẽ, điều này sẽ đủ cho khoảng một năm nữa. Bạn cần nắm giữ phần cứng hoặc tự tối ưu hóa cơ sở dữ liệu.
Do tính chất của kiến trúc, việc tăng phần cứng theo bội số chỉ có ý nghĩa. Tức là ít nhất phải tăng gấp đôi số lượng ô tô - rõ ràng đây là một con đường khá tốn kém. Chúng tôi sẽ tối ưu hóa.
Khái niệm mới
Bản chất trung tâm của cách tiếp cận mới là trò chuyện. Một cuộc trò chuyện có một danh sách các tin nhắn liên quan đến nó. Người dùng có một danh sách các cuộc trò chuyện.
Yêu cầu tối thiểu là hai cơ sở dữ liệu mới:
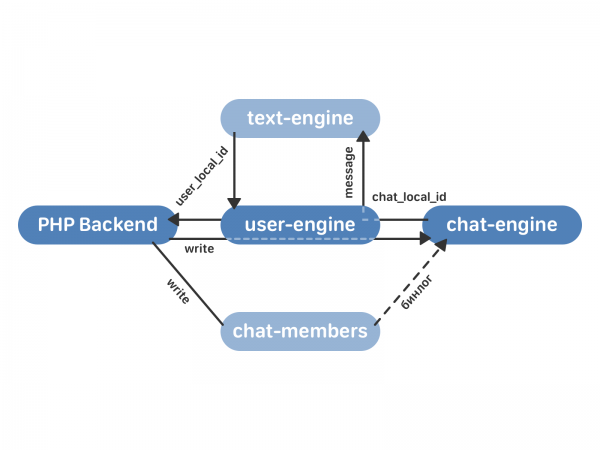
- công cụ trò chuyện. Đây là một kho lưu trữ các vectơ trò chuyện. Mỗi cuộc trò chuyện có một vectơ tin nhắn liên quan đến nó. Mỗi tin nhắn có một văn bản và mã nhận dạng tin nhắn duy nhất bên trong cuộc trò chuyện - chat_local_id.
- người dùng-động cơ. Đây là nơi lưu trữ vectơ người dùng - liên kết đến người dùng. Mỗi người dùng có một vectơ ngang hàng (người đối thoại - người dùng khác, nhiều cuộc trò chuyện hoặc cộng đồng) và một vectơ tin nhắn. Mỗi ngang hàng có một vectơ thông báo liên quan đến nó. Mỗi tin nhắn có một chat_local_id và một ID tin nhắn duy nhất cho người dùng đó - user_local_id.
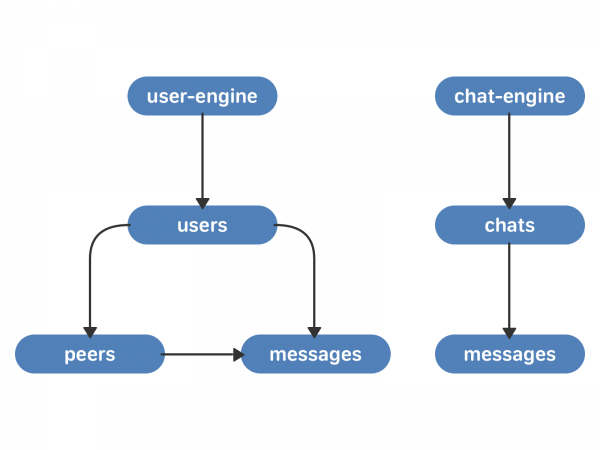
Các cụm mới liên lạc với nhau bằng TCP - điều này đảm bảo rằng thứ tự yêu cầu không thay đổi. Bản thân các yêu cầu và xác nhận đối với chúng được ghi lại trên ổ cứng - vì vậy chúng tôi có thể khôi phục trạng thái hàng đợi bất kỳ lúc nào sau khi động cơ bị lỗi hoặc khởi động lại. Vì công cụ người dùng và công cụ trò chuyện có 4 nghìn phân đoạn mỗi công cụ, nên hàng đợi yêu cầu giữa các cụm sẽ được phân bổ đồng đều (nhưng trên thực tế không có phân đoạn nào cả - và nó hoạt động rất nhanh).
Làm việc với đĩa trong cơ sở dữ liệu của chúng tôi trong hầu hết các trường hợp dựa trên sự kết hợp của nhật ký thay đổi nhị phân (binlog), ảnh chụp nhanh tĩnh và một phần hình ảnh trong bộ nhớ. Các thay đổi trong ngày được ghi vào nhật ký binlog và ảnh chụp nhanh về trạng thái hiện tại được tạo định kỳ. Ảnh chụp nhanh là tập hợp các cấu trúc dữ liệu được tối ưu hóa cho mục đích của chúng tôi. Nó bao gồm một tiêu đề (metaindex của hình ảnh) và một tập hợp các metafile. Tiêu đề được lưu trữ vĩnh viễn trong RAM và cho biết nơi tìm dữ liệu từ ảnh chụp nhanh. Mỗi siêu tệp bao gồm dữ liệu có thể cần thiết tại các thời điểm gần nhau—ví dụ: liên quan đến một người dùng. Khi bạn truy vấn cơ sở dữ liệu bằng tiêu đề ảnh chụp nhanh, siêu tệp bắt buộc sẽ được đọc và sau đó những thay đổi trong binlog xảy ra sau khi tạo ảnh chụp nhanh sẽ được tính đến. Bạn có thể đọc thêm về lợi ích của phương pháp này .
Đồng thời, dữ liệu trên ổ cứng chỉ thay đổi một lần mỗi ngày - vào đêm khuya ở Moscow, khi tải ở mức tối thiểu. Nhờ điều này (biết rằng cấu trúc trên đĩa không đổi suốt cả ngày), chúng ta có thể thay thế các vectơ bằng các mảng có kích thước cố định - và do đó, tăng được bộ nhớ.
Gửi tin nhắn trong sơ đồ mới trông như thế này:
- Phần phụ trợ PHP liên hệ với công cụ người dùng với yêu cầu gửi tin nhắn.
- công cụ người dùng ủy quyền yêu cầu đến phiên bản công cụ trò chuyện mong muốn, phiên bản này sẽ trả về chat_local_id của công cụ người dùng - mã định danh duy nhất của tin nhắn mới trong cuộc trò chuyện này. Chat_engine sau đó sẽ phát tin nhắn tới tất cả người nhận trong cuộc trò chuyện.
- user-engine nhận chat_local_id từ chat-engine và trả về user_local_id cho PHP - một mã định danh tin nhắn duy nhất cho người dùng này. Ví dụ: mã định danh này sau đó được sử dụng để làm việc với các tin nhắn thông qua API.
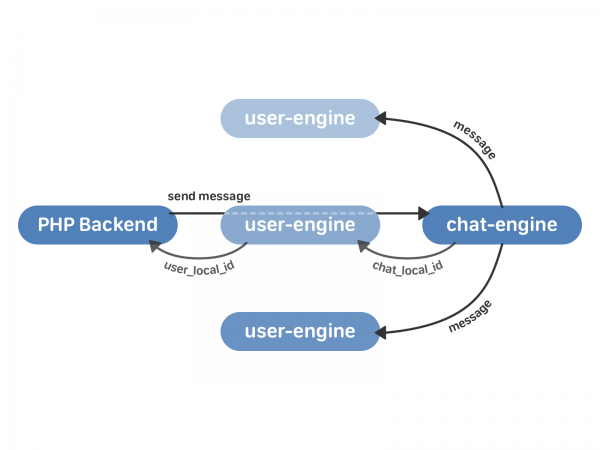
Nhưng ngoài việc thực sự gửi tin nhắn, bạn cần triển khai một số điều quan trọng hơn:
- Ví dụ: Danh sách phụ là những tin nhắn gần đây nhất mà bạn nhìn thấy khi mở danh sách cuộc trò chuyện. Tin nhắn chưa đọc, tin nhắn có thẻ (“Quan trọng”, “Thư rác”, v.v.).
- Nén tin nhắn trong công cụ trò chuyện
- Lưu tin nhắn vào bộ nhớ đệm trong công cụ người dùng
- Tìm kiếm (thông qua tất cả các hộp thoại và trong một hộp thoại cụ thể).
- Cập nhật theo thời gian thực (Longpolling).
- Lưu lịch sử để triển khai bộ nhớ đệm trên máy khách di động.
Tất cả các danh sách phụ đều có cấu trúc thay đổi nhanh chóng. Để làm việc với họ, chúng tôi sử dụng . Lựa chọn này được giải thích bởi thực tế là ở phần trên cùng của cây, đôi khi chúng tôi lưu trữ toàn bộ đoạn tin nhắn từ một ảnh chụp nhanh - ví dụ: sau khi lập chỉ mục lại hàng đêm, cây bao gồm một phần trên cùng chứa tất cả các tin nhắn của danh sách phụ. Cây Splay giúp bạn dễ dàng chèn vào giữa một đỉnh như vậy mà không cần phải suy nghĩ đến việc cân bằng. Ngoài ra, Splay không lưu trữ những dữ liệu không cần thiết, giúp chúng ta tiết kiệm bộ nhớ.
Tin nhắn chứa một lượng lớn thông tin, chủ yếu là văn bản, có thể nén lại rất hữu ích. Điều quan trọng là chúng tôi có thể hủy lưu trữ chính xác ngay cả một thư riêng lẻ. Dùng để nén tin nhắn bằng phương pháp phỏng đoán của riêng chúng tôi - chẳng hạn, chúng tôi biết rằng trong tin nhắn, các từ xen kẽ với "không phải từ" - dấu cách, dấu chấm câu - và chúng tôi cũng ghi nhớ một số đặc thù của việc sử dụng các ký hiệu cho tiếng Nga.
Vì có ít người dùng hơn nhiều so với cuộc trò chuyện nên để lưu các yêu cầu đĩa truy cập ngẫu nhiên trong công cụ trò chuyện, chúng tôi lưu vào bộ nhớ đệm các tin nhắn trong công cụ người dùng.
Tìm kiếm tin nhắn được triển khai dưới dạng truy vấn chéo từ công cụ người dùng đến tất cả các phiên bản công cụ trò chuyện có chứa các cuộc trò chuyện của người dùng này. Các kết quả được kết hợp trong chính công cụ người dùng.
Chà, tất cả các chi tiết đã được tính đến, tất cả những gì còn lại là chuyển sang một sơ đồ mới - và tốt nhất là người dùng không nhận ra điều đó.
Di chuyển dữ liệu
Vì vậy, chúng tôi có một công cụ văn bản lưu trữ tin nhắn của người dùng và hai cụm trò chuyện thành viên và cuộc trò chuyện thành viên lưu trữ dữ liệu về các phòng trò chuyện nhiều người và người dùng trong đó. Làm cách nào để chuyển từ công cụ này sang công cụ người dùng và công cụ trò chuyện mới?
cuộc trò chuyện thành viên trong sơ đồ cũ được sử dụng chủ yếu để tối ưu hóa. Chúng tôi nhanh chóng chuyển dữ liệu cần thiết từ nó đến các thành viên trò chuyện và sau đó nó không còn tham gia vào quá trình di chuyển nữa.
Hàng đợi cho các thành viên trò chuyện. Nó bao gồm 100 trường hợp, trong khi công cụ trò chuyện có 4 nghìn trường hợp. Để truyền dữ liệu, bạn cần phải tuân thủ dữ liệu - đối với điều này, các thành viên trò chuyện được chia thành 4 nghìn bản giống nhau và sau đó việc đọc binlog của các thành viên trò chuyện được bật trong công cụ trò chuyện.
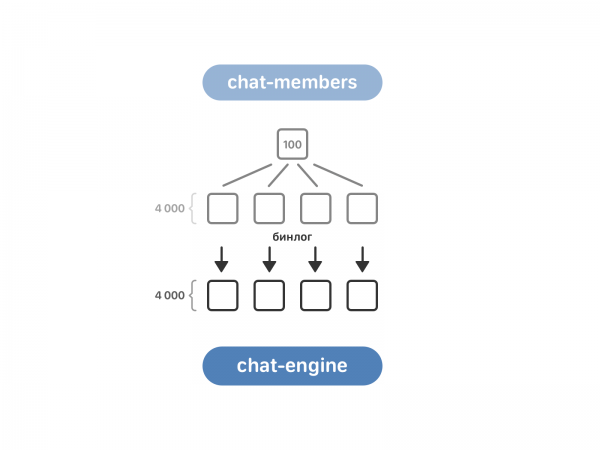
Bây giờ công cụ trò chuyện biết về tính năng trò chuyện nhiều lần từ các thành viên trò chuyện, nhưng nó vẫn chưa biết gì về cuộc đối thoại với hai người đối thoại. Những cuộc đối thoại như vậy được đặt trong công cụ văn bản có tham chiếu đến người dùng. Ở đây, chúng tôi đã lấy dữ liệu “trực tiếp”: mỗi phiên bản công cụ trò chuyện sẽ hỏi tất cả các phiên bản công cụ văn bản xem họ có đoạn hội thoại cần thiết hay không.
Tuyệt vời - công cụ trò chuyện biết có những cuộc trò chuyện nhiều cuộc trò chuyện nào và biết có những cuộc đối thoại nào.
Bạn cần kết hợp các tin nhắn trong các cuộc trò chuyện nhiều cuộc trò chuyện để có được danh sách tin nhắn trong mỗi cuộc trò chuyện. Đầu tiên, chat-engine lấy từ text-engine tất cả tin nhắn của người dùng từ cuộc trò chuyện này. Trong một số trường hợp, có khá nhiều trong số chúng (lên tới hàng trăm triệu), nhưng với những trường hợp ngoại lệ rất hiếm, trò chuyện hoàn toàn nằm gọn trong RAM. Chúng tôi có các tin nhắn không có thứ tự, mỗi tin nhắn có nhiều bản sao - xét cho cùng, chúng đều được lấy từ các phiên bản công cụ văn bản khác nhau tương ứng với người dùng. Mục đích là sắp xếp thư và loại bỏ các bản sao chiếm dung lượng không cần thiết.
Mỗi tin nhắn có dấu thời gian chứa thời gian gửi và nội dung. Chúng tôi sử dụng thời gian để sắp xếp - chúng tôi đặt con trỏ tới các tin nhắn cũ nhất của những người tham gia nhiều cuộc trò chuyện và so sánh các giá trị băm từ văn bản của các bản sao dự định, tiến tới tăng dấu thời gian. Điều hợp lý là các bản sao sẽ có cùng hàm băm và dấu thời gian, nhưng trên thực tế, điều này không phải lúc nào cũng đúng. Như bạn nhớ, việc đồng bộ hóa trong sơ đồ cũ được thực hiện bởi PHP - và trong một số trường hợp hiếm hoi, thời gian gửi cùng một tin nhắn là khác nhau giữa những người dùng khác nhau. Trong những trường hợp này, chúng tôi cho phép mình chỉnh sửa dấu thời gian - thường trong vòng một giây. Vấn đề thứ hai là thứ tự gửi tin nhắn khác nhau cho những người nhận khác nhau. Trong những trường hợp như vậy, chúng tôi đã cho phép tạo thêm một bản sao với các tùy chọn đặt hàng khác nhau cho những người dùng khác nhau.
Sau đó, dữ liệu về tin nhắn trong multichat sẽ được gửi đến công cụ người dùng. Và đây là một tính năng khó chịu của tin nhắn được nhập. Trong hoạt động bình thường, các tin nhắn đến công cụ được sắp xếp theo thứ tự tăng dần theo user_local_id. Thư được nhập từ công cụ cũ vào công cụ người dùng đã mất thuộc tính hữu ích này. Đồng thời, để thuận tiện cho việc kiểm tra, bạn cần có khả năng truy cập nhanh vào chúng, tìm kiếm thứ gì đó trong đó và thêm cái mới.
Chúng tôi sử dụng cấu trúc dữ liệu đặc biệt để lưu trữ tin nhắn đã nhập.
Nó đại diện cho một vectơ có kích thước  mọi người đâu rồi
mọi người đâu rồi  - khác nhau và được sắp xếp theo thứ tự giảm dần, với thứ tự đặc biệt của các phần tử. Trong mỗi phân đoạn có chỉ số
- khác nhau và được sắp xếp theo thứ tự giảm dần, với thứ tự đặc biệt của các phần tử. Trong mỗi phân đoạn có chỉ số  các phần tử được sắp xếp. Việc tìm kiếm một phần tử trong cấu trúc như vậy cần có thời gian
các phần tử được sắp xếp. Việc tìm kiếm một phần tử trong cấu trúc như vậy cần có thời gian  xuyên qua
xuyên qua  tìm kiếm nhị phân. Việc bổ sung thêm một phần tử được khấu hao theo
tìm kiếm nhị phân. Việc bổ sung thêm một phần tử được khấu hao theo  .
.
Vì vậy, chúng tôi đã tìm ra cách chuyển dữ liệu từ động cơ cũ sang động cơ mới. Nhưng quá trình này mất vài ngày - và khó có khả năng trong những ngày này, người dùng của chúng ta sẽ từ bỏ thói quen viết thư cho nhau. Để không bị mất tin nhắn trong thời gian này, chúng tôi chuyển sang sơ đồ làm việc sử dụng cả cụm cũ và cụm mới.
Dữ liệu được ghi vào các thành viên trò chuyện và công cụ người dùng (chứ không phải vào công cụ văn bản, như trong hoạt động bình thường theo sơ đồ cũ). công cụ người dùng ủy quyền yêu cầu tới công cụ trò chuyện - và ở đây hành vi phụ thuộc vào việc cuộc trò chuyện này đã được hợp nhất hay chưa. Nếu cuộc trò chuyện chưa được hợp nhất, công cụ trò chuyện sẽ không ghi tin nhắn cho chính nó và quá trình xử lý nó chỉ diễn ra trong công cụ văn bản. Nếu cuộc trò chuyện đã được hợp nhất vào công cụ trò chuyện, thì cuộc trò chuyện đó sẽ trả về chat_local_id cho công cụ người dùng và gửi tin nhắn đến tất cả người nhận. công cụ người dùng ủy quyền tất cả dữ liệu cho công cụ văn bản - để nếu có điều gì xảy ra, chúng tôi luôn có thể quay lại, có tất cả dữ liệu hiện tại trong công cụ cũ. công cụ văn bản trả về user_local_id, công cụ người dùng này lưu trữ và trả về phần phụ trợ.
Kết quả là, quá trình chuyển đổi trông như thế này: chúng tôi kết nối các cụm công cụ người dùng và công cụ trò chuyện trống. chat-engine đọc toàn bộ binlog của thành viên trò chuyện, sau đó quá trình ủy quyền bắt đầu theo sơ đồ được mô tả ở trên. Chúng tôi chuyển dữ liệu cũ và nhận được hai cụm đồng bộ (cũ và mới). Tất cả những gì còn lại là chuyển cách đọc từ công cụ văn bản sang công cụ người dùng và tắt tính năng ủy quyền.
Những phát hiện
Nhờ cách tiếp cận mới, tất cả các chỉ số hiệu suất của động cơ đã được cải thiện và các vấn đề về tính nhất quán của dữ liệu đã được giải quyết. Giờ đây, chúng tôi có thể nhanh chóng triển khai các tính năng mới trong tin nhắn (và đã bắt đầu thực hiện việc này - chúng tôi đã tăng số lượng người tham gia trò chuyện tối đa, triển khai tìm kiếm các tin nhắn được chuyển tiếp, khởi chạy các tin nhắn được ghim và tăng giới hạn về tổng số tin nhắn cho mỗi người dùng) .
Những thay đổi về logic thực sự rất lớn. Và tôi muốn lưu ý rằng điều này không phải lúc nào cũng có nghĩa là phải mất cả năm phát triển bởi một đội ngũ khổng lồ và vô số dòng mã. chat-engine và user-engine cùng với tất cả các câu chuyện bổ sung như Huffman để nén tin nhắn, cây Splay và cấu trúc cho tin nhắn đã nhập có ít hơn 20 nghìn dòng mã. Và chúng được viết bởi 3 nhà phát triển chỉ trong 10 tháng (tuy nhiên, cần lưu ý rằng - vô địch thế giới ).
Hơn nữa, thay vì tăng gấp đôi số lượng máy chủ, chúng tôi đã giảm một nửa số lượng máy chủ - hiện công cụ người dùng và công cụ trò chuyện tồn tại trên 500 máy vật lý, trong khi sơ đồ mới có khoảng trống lớn để tải. Chúng tôi đã tiết kiệm được rất nhiều tiền mua thiết bị - khoảng 5 triệu USD + 750 nghìn USD chi phí vận hành mỗi năm.
Chúng tôi cố gắng tìm ra giải pháp tốt nhất cho những vấn đề phức tạp và có quy mô lớn nhất. Chúng tôi có rất nhiều người trong số họ - và đó là lý do tại sao chúng tôi đang tìm kiếm các nhà phát triển tài năng trong bộ phận cơ sở dữ liệu. Nếu bạn yêu thích và biết cách giải quyết những vấn đề như vậy, có kiến thức tốt về thuật toán và cấu trúc dữ liệu, chúng tôi mời bạn tham gia nhóm. Liên hệ với chúng tôi để biết chi tiết.
Ngay cả khi câu chuyện này không phải về bạn, xin lưu ý rằng chúng tôi coi trọng các đề xuất. Kể cho một người bạn về , và nếu anh ta hoàn thành xuất sắc thời gian thử việc, bạn sẽ nhận được tiền thưởng 100 nghìn rúp.
Nguồn: www.habr.com
