

Gần đây tôi đã nói với bạn cách sử dụng công thức nấu ăn tiêu chuẩn từ cơ sở dữ liệu PostgreSQL. Hôm nay chúng ta sẽ nói về cách ghi âm có thể được thực hiện hiệu quả hơn trong cơ sở dữ liệu mà không cần sử dụng bất kỳ “xoắn” nào trong cấu hình - chỉ bằng cách tổ chức chính xác các luồng dữ liệu.

#1. Phân chia
Một bài viết về cách thức và lý do nó đáng được tổ chức đã có, ở đây chúng ta sẽ nói về thực tiễn áp dụng một số phương pháp tiếp cận trong .
"Chuyện ngày xưa..."
Ban đầu, giống như bất kỳ MVP nào, dự án của chúng tôi bắt đầu với tải khá nhẹ - việc giám sát chỉ được thực hiện đối với mười máy chủ quan trọng nhất, tất cả các bảng đều tương đối nhỏ gọn... Nhưng theo thời gian, số lượng máy chủ được giám sát ngày càng nhiều , và một lần nữa chúng tôi cố gắng làm điều gì đó với một trong những bảng có kích thước 1.5TB, chúng tôi nhận ra rằng dù có thể tiếp tục sống như thế này nhưng cũng rất bất tiện.
Thời đại gần giống như thời kỳ hoành tráng, các phiên bản khác nhau của PostgreSQL 9.x đều có liên quan, vì vậy tất cả việc phân vùng phải được thực hiện “thủ công” - thông qua kế thừa bảng và kích hoạt định tuyến với động EXECUTE.
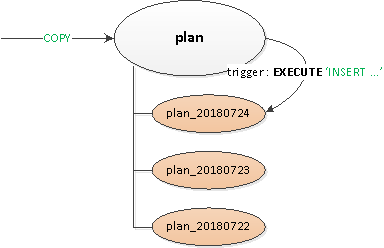
Giải pháp thu được hóa ra lại đủ phổ quát để có thể dịch nó sang tất cả các bảng:
- Một bảng cha mẹ “tiêu đề” trống đã được khai báo, mô tả tất cả các chỉ mục và kích hoạt cần thiết.
- Bản ghi theo quan điểm của khách hàng được tạo trong bảng “root” và sử dụng nội bộ kích hoạt định tuyến
BEFORE INSERTbản ghi đã được chèn “vật lý” vào phần được yêu cầu. Nếu chưa có thứ đó, chúng tôi đã gặp một ngoại lệ và... - … bằng cách sử dụng được tạo dựa trên mẫu của bảng cha phần có hạn chế về ngày mong muốnđể khi dữ liệu được lấy ra, việc đọc chỉ được thực hiện trong đó.
PG10: lần thử đầu tiên
Nhưng việc phân vùng thông qua tính kế thừa về mặt lịch sử không phù hợp lắm để xử lý luồng ghi đang hoạt động hoặc một số lượng lớn các phân vùng con. Ví dụ: bạn có thể nhớ lại rằng thuật toán chọn phần bắt buộc có độ phức tạp bậc hai, nó hoạt động với hơn 100 phần, bản thân bạn cũng hiểu...
Trong PG10, tình huống này đã được tối ưu hóa rất nhiều bằng cách triển khai hỗ trợ . Vì vậy, chúng tôi đã ngay lập tức thử áp dụng nó ngay sau khi di chuyển bộ nhớ, nhưng...
Hóa ra sau khi xem qua hướng dẫn, bảng được phân vùng nguyên bản trong phiên bản này là:
- không hỗ trợ mô tả chỉ mục
- không hỗ trợ kích hoạt trên đó
- không thể là “hậu duệ” của bất kỳ ai
- không hỗ trợ
INSERT ... ON CONFLICT - không thể tự động tạo một phần
Sau khi nhận một cú cào đau đớn vào trán, chúng tôi nhận ra rằng không thể làm được nếu không sửa đổi đơn đăng ký và đã hoãn nghiên cứu thêm trong sáu tháng.
PG10: cơ hội thứ hai
Vì vậy, chúng tôi bắt đầu giải quyết từng vấn đề nảy sinh:
- Bởi vì các yếu tố kích hoạt và
ON CONFLICTChúng tôi nhận thấy rằng chúng tôi vẫn cần chúng ở chỗ này chỗ kia, vì vậy chúng tôi đã tạo ra một giai đoạn trung gian để giải quyết chúng. bảng proxy. - Đã thoát khỏi "định tuyến" trong trình kích hoạt - nghĩa là từ
EXECUTE. - Họ lấy nó ra riêng bảng mẫu với tất cả các chỉ mụcđể chúng thậm chí không có mặt trong bảng proxy.
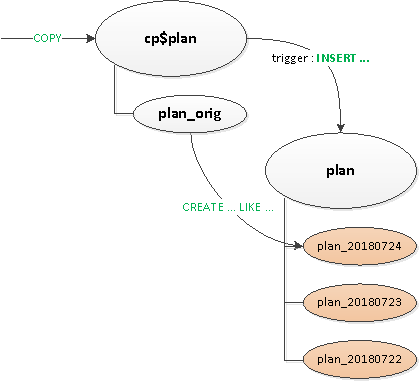
Cuối cùng, sau tất cả những điều này, chúng tôi đã phân vùng bảng chính một cách nguyên bản. Việc tạo ra một phần mới vẫn thuộc về lương tâm của ứng dụng.
Từ điển “cưa”
Như trong bất kỳ hệ thống phân tích nào, chúng tôi cũng có "sự thật" và "cắt giảm" (từ điển). Trong trường hợp của chúng tôi, với tư cách này, họ đã hành động, chẳng hạn, các truy vấn chậm tương tự hoặc nội dung của chính truy vấn đó.
“Sự thật” đã được phân chia theo ngày từ lâu rồi nên chúng tôi bình tĩnh xóa những phần lỗi thời và chúng không làm phiền chúng tôi (nhật ký!). Nhưng có một vấn đề với từ điển...
Không phải nói rằng có rất nhiều trong số họ, nhưng khoảng 100 TB “sự kiện” tạo ra từ điển 2.5 TB. Bạn không thể xóa bất cứ thứ gì khỏi một bảng như vậy một cách thuận tiện, bạn không thể nén nó trong thời gian thích hợp và việc ghi vào bảng dần dần trở nên chậm hơn.
Giống như một cuốn từ điển... trong đó, mỗi mục phải được trình bày chính xác một lần... và điều này đúng, nhưng!.. Không ai ngăn cản chúng ta có một từ điển riêng cho mỗi ngày! Có, điều này mang lại sự dư thừa nhất định, nhưng nó cho phép:
- viết/đọc nhanh hơn do kích thước phần nhỏ hơn
- tiêu thụ ít bộ nhớ hơn bằng cách làm việc với các chỉ mục nhỏ gọn hơn
- lưu trữ ít dữ liệu hơn nhờ khả năng loại bỏ nhanh chóng lỗi thời
Là kết quả của toàn bộ các biện pháp phức tạp Tải CPU giảm ~30%, tải đĩa ~50%:
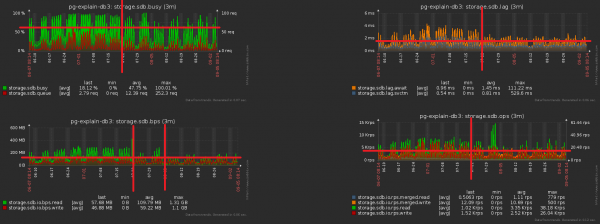
Đồng thời, chúng tôi tiếp tục ghi chính xác nội dung tương tự vào cơ sở dữ liệu, chỉ với tải ít hơn.
#2. Phát triển và tái cấu trúc cơ sở dữ liệu
Vì vậy chúng tôi đã quyết định những gì chúng tôi có mỗi ngày có phần riêng với dữ liệu. Thực ra, CHECK (dt = '2018-10-12'::date) — và có khóa phân vùng và điều kiện để bản ghi rơi vào một phần cụ thể.
Vì tất cả các báo cáo trong dịch vụ của chúng tôi đều được xây dựng trong bối cảnh của một ngày cụ thể nên các chỉ mục cho chúng kể từ "thời gian không phân vùng" đều có tất cả các loại (Máy chủ, Ngày, Mẫu kế hoạch), (Máy chủ, Ngày, Nút kế hoạch), (Ngày, Lớp lỗi, Máy chủ), ...
Nhưng bây giờ họ sống trên mọi khu vực bản sao của bạn mỗi chỉ mục như vậy... Và trong mỗi phần ngày là một hằng số... Hóa ra bây giờ chúng ta đang ở trong mỗi chỉ mục như vậy chỉ cần nhập một hằng số là một trong những trường làm tăng cả khối lượng và thời gian tìm kiếm nhưng không mang lại bất kỳ kết quả nào. Họ để lại cái cào cho mình, ôi...

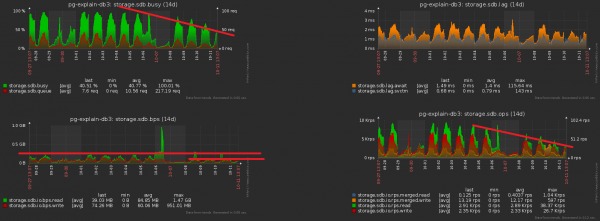
Hướng tối ưu hóa rõ ràng - đơn giản xóa trường ngày khỏi tất cả các chỉ mục trên các bảng được phân vùng. Với khối lượng của chúng tôi, mức tăng là khoảng 1TB/tuần!
Bây giờ hãy lưu ý rằng terabyte này vẫn phải được ghi lại bằng cách nào đó. Tức là chúng tôi cũng đĩa bây giờ sẽ tải ít hơn! Bức ảnh này cho thấy rõ ràng hiệu quả thu được từ việc làm sạch mà chúng tôi đã dành một tuần để thực hiện:
#3. “Trải” phụ tải đỉnh điểm
Một trong những vấn đề lớn của hệ thống có tải là đồng bộ hóa dự phòng một số thao tác không yêu cầu. Đôi khi “vì họ không để ý”, đôi khi “như thế thì dễ dàng hơn”, nhưng sớm hay muộn bạn cũng phải loại bỏ nó.
Hãy phóng to hình ảnh trước đó và thấy rằng chúng ta có một cái đĩa “máy bơm” dưới tải với biên độ gấp đôi giữa các mẫu liền kề, điều này rõ ràng không nên xảy ra về mặt “thống kê” với một số thao tác như vậy:
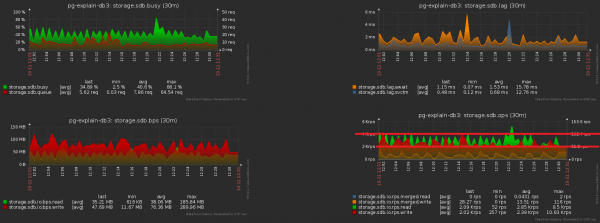
Điều này khá dễ dàng để đạt được. Chúng tôi đã bắt đầu theo dõi gần 1000 máy chủ, mỗi luồng được xử lý bởi một luồng logic riêng biệt và mỗi luồng sẽ đặt lại thông tin tích lũy sẽ được gửi đến cơ sở dữ liệu ở một tần số nhất định, đại loại như sau:
setInterval(sendToDB, interval)Vấn đề ở đây chính xác nằm ở chỗ tất cả các chủ đề bắt đầu gần như cùng một lúc, vì vậy thời gian gửi của họ hầu như luôn trùng khớp “đến mức”. Rất tiếc #2...
May mắn thay, điều này khá dễ khắc phục, thêm một lần chạy "ngẫu nhiên" theo thời gian:
setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))#4. Chúng tôi lưu trữ những gì chúng tôi cần
Vấn đề tải trọng truyền thống thứ ba là không có bộ nhớ đệm anh ấy ở đâu có thể được.
Ví dụ: chúng tôi có thể phân tích theo các nút kế hoạch (tất cả những điều này Seq Scan on users), nhưng ngay lập tức nghĩ rằng phần lớn chúng giống nhau - họ đã quên.
Không, tất nhiên là không có gì được ghi vào cơ sở dữ liệu nữa, điều này sẽ tắt trình kích hoạt bằng INSERT ... ON CONFLICT DO NOTHING. Nhưng dữ liệu này vẫn đến cơ sở dữ liệu và không cần thiết đọc để kiểm tra xung đột phải làm. Rất tiếc #3...
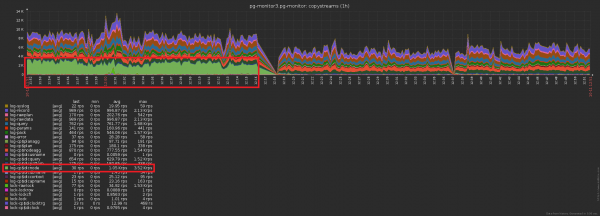
Sự khác biệt về số lượng bản ghi được gửi đến cơ sở dữ liệu trước/sau khi bật bộ nhớ đệm là rõ ràng:
Và đây là mức giảm tải lưu trữ kèm theo:
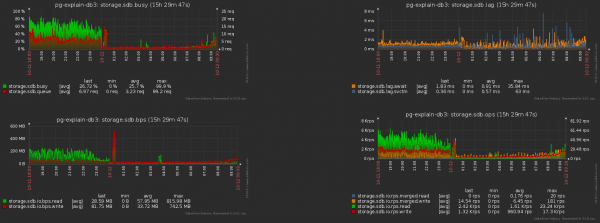
trong tổng số
“Terabyte mỗi ngày” nghe có vẻ đáng sợ. Nếu bạn làm mọi thứ đúng thì đây chỉ là 2^40 byte/86400 giây = ~12.5MB/sthậm chí còn giữ được cả ốc vít IDE trên máy tính để bàn. 🙂
Nhưng nghiêm túc mà nói, ngay cả với mức tải “độ lệch” gấp XNUMX lần trong ngày, bạn vẫn có thể dễ dàng đáp ứng được khả năng của ổ SSD hiện đại.

Nguồn: www.habr.com
