

Các ý tưởng và cuộc họp về những quy trình khác có thể được tự động hóa nảy sinh hàng ngày ở các doanh nghiệp thuộc nhiều quy mô khác nhau. Nhưng ngoài việc có thể tốn rất nhiều thời gian cho việc tạo mô hình, bạn cần dành thời gian đó để đánh giá nó và kiểm tra xem kết quả thu được có phải là ngẫu nhiên hay không. Sau khi thực hiện, bất kỳ mô hình nào cũng phải được theo dõi và kiểm tra định kỳ.
Và đây là tất cả các giai đoạn cần phải hoàn thành ở bất kỳ công ty nào, bất kể quy mô của nó. Nếu chúng ta đang nói về quy mô và di sản của Sberbank, số lượng tinh chỉnh sẽ tăng lên đáng kể. Tính đến cuối năm 2019, Sber đã sử dụng hơn 2000 mẫu. Chỉ phát triển một mô hình thôi là chưa đủ mà cần phải tích hợp với các hệ thống công nghiệp, phát triển siêu thị dữ liệu để xây dựng mô hình và đảm bảo kiểm soát hoạt động của nó trên cụm.
Nhóm của chúng tôi đang phát triển nền tảng Sber.DS. Nó cho phép bạn giải quyết các vấn đề về học máy, tăng tốc quá trình kiểm tra các giả thuyết, về nguyên tắc đơn giản hóa quá trình phát triển và xác nhận các mô hình, đồng thời kiểm soát kết quả của mô hình trong PROM.
Để không đánh lừa sự mong đợi của bạn, tôi muốn nói trước rằng bài đăng này là một bài giới thiệu và dưới phần giới thiệu, đối với những người mới bắt đầu, chúng tôi nói về những gì, về nguyên tắc, nằm dưới nền tảng Sber.DS. Chúng tôi sẽ kể câu chuyện về vòng đời của mô hình từ khi tạo ra đến khi triển khai một cách riêng biệt.
Sber.DS bao gồm một số thành phần, thành phần chính là thư viện, hệ thống phát triển và hệ thống thực thi mô hình.

Thư viện kiểm soát vòng đời của mô hình từ thời điểm ý tưởng phát triển mô hình xuất hiện cho đến khi triển khai nó trong PROM, giám sát và ngừng hoạt động. Nhiều khả năng của thư viện được quy định bởi các quy tắc quản lý, ví dụ như báo cáo và lưu trữ các mẫu đào tạo và xác nhận. Trên thực tế, đây là sổ đăng ký tất cả các mẫu xe của chúng tôi.
Hệ thống phát triển được thiết kế để phát triển trực quan các mô hình và kỹ thuật xác nhận. Các mô hình đã phát triển trải qua quá trình xác thực ban đầu và được cung cấp cho hệ thống thực thi để thực hiện các chức năng kinh doanh của chúng. Ngoài ra, trong hệ thống thời gian chạy, mô hình có thể được đặt trên màn hình nhằm mục đích khởi chạy định kỳ các kỹ thuật xác thực để giám sát hoạt động của nó.
Có một số loại nút trong hệ thống. Một số được thiết kế để kết nối với nhiều nguồn dữ liệu khác nhau, một số khác được thiết kế để chuyển đổi dữ liệu nguồn và làm phong phú thêm dữ liệu đó (đánh dấu). Có nhiều nút để xây dựng các mô hình khác nhau và các nút để xác thực chúng. Nhà phát triển có thể tải dữ liệu từ bất kỳ nguồn nào, chuyển đổi, lọc, trực quan hóa dữ liệu trung gian và chia dữ liệu thành nhiều phần.
Nền tảng này cũng chứa các mô-đun làm sẵn có thể kéo và thả vào khu vực thiết kế. Tất cả các hành động được thực hiện bằng giao diện trực quan. Trên thực tế, bạn có thể giải quyết vấn đề mà không cần một dòng mã nào.
Nếu khả năng tích hợp không đủ, hệ thống sẽ cung cấp khả năng tạo nhanh các mô-đun của riêng bạn. Chúng tôi đã thực hiện một chế độ phát triển tích hợp dựa trên dành cho những người tạo mô-đun mới từ đầu.
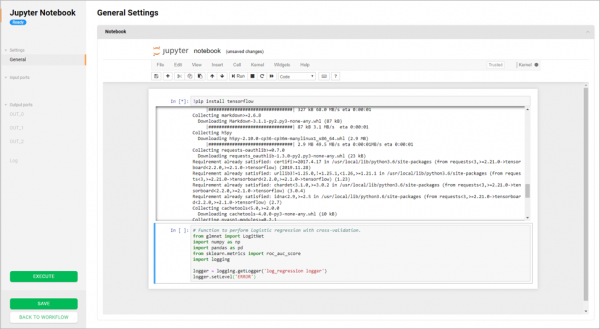
Kiến trúc của Sber.DS được xây dựng trên microservice. Có nhiều ý kiến về microservice là gì. Một số người cho rằng việc chia mã nguyên khối thành nhiều phần là đủ, nhưng đồng thời họ vẫn đi đến cùng một cơ sở dữ liệu. Microservice của chúng tôi chỉ được giao tiếp với một microservice khác thông qua REST API. Không có cách giải quyết nào để truy cập trực tiếp vào cơ sở dữ liệu.
Chúng tôi cố gắng đảm bảo rằng các dịch vụ không trở nên quá lớn và vụng về: một phiên bản không được tiêu tốn quá 4-8 gigabyte RAM và phải cung cấp khả năng mở rộng quy mô yêu cầu theo chiều ngang bằng cách khởi chạy các phiên bản mới. Mỗi dịch vụ chỉ giao tiếp với người khác thông qua API REST (). Nhóm chịu trách nhiệm về dịch vụ được yêu cầu giữ cho API tương thích ngược cho đến khi khách hàng cuối cùng sử dụng nó.
Cốt lõi của ứng dụng được viết bằng Java sử dụng Spring Framework. Giải pháp ban đầu được thiết kế để triển khai nhanh chóng trên cơ sở hạ tầng đám mây, do đó ứng dụng được xây dựng bằng hệ thống container hóa (). Nền tảng này không ngừng phát triển, cả về chức năng kinh doanh ngày càng tăng (các trình kết nối mới, AutoML đang được bổ sung) và về hiệu quả công nghệ.
Một trong những tính năng của nền tảng của chúng tôi là chúng tôi có thể chạy mã được phát triển trong giao diện trực quan trên bất kỳ hệ thống thực thi mô hình Sberbank nào. Bây giờ đã có hai trong số chúng: một trên Hadoop, một trên OpenShift (Docker). Chúng tôi không dừng lại ở đó và tạo các mô-đun tích hợp để chạy mã trên bất kỳ cơ sở hạ tầng nào, bao gồm cả tại chỗ và trên đám mây. Về khả năng tích hợp hiệu quả vào hệ sinh thái Sberbank, chúng tôi cũng có kế hoạch hỗ trợ hoạt động với các môi trường thực thi hiện có. Trong tương lai, giải pháp này có thể được tích hợp linh hoạt “ngay lập tức” vào bất kỳ bối cảnh nào của bất kỳ tổ chức nào.
Những người đã từng cố gắng hỗ trợ giải pháp chạy Python trên Hadoop trong PROM đều biết rằng việc chuẩn bị và cung cấp môi trường người dùng Python cho mỗi nút dữ liệu là chưa đủ. Số lượng lớn các thư viện C/C++ dành cho máy học sử dụng các mô-đun Python sẽ không cho phép bạn yên tâm. Chúng ta phải nhớ cập nhật các gói khi thêm thư viện hoặc máy chủ mới, đồng thời duy trì khả năng tương thích ngược với mã mô hình đã được triển khai.
Có một số cách tiếp cận để làm điều này. Ví dụ: chuẩn bị trước một số thư viện được sử dụng thường xuyên và triển khai chúng trong PROM. Trong bản phân phối Hadoop của Cloudera, họ thường sử dụng . Ngoài ra bây giờ trong Hadoop có thể chạy -hộp đựng. Trong một số trường hợp đơn giản, có thể gửi mã cùng với gói hàng .
Ngân hàng rất coi trọng vấn đề bảo mật khi chạy mã nguồn của bên thứ ba, vì vậy chúng tôi tận dụng tối đa các tính năng mới của nhân hệ điều hành. Linux, trong đó quy trình đang chạy trong một môi trường biệt lập. , chẳng hạn, bạn có thể giới hạn quyền truy cập vào mạng và đĩa cục bộ, điều này làm giảm đáng kể khả năng của mã độc. Các vùng dữ liệu của mỗi bộ phận được bảo vệ và chỉ có chủ sở hữu dữ liệu này mới có thể truy cập được. Nền tảng đảm bảo rằng dữ liệu từ một khu vực chỉ có thể đến khu vực khác thông qua quy trình xuất bản dữ liệu với sự kiểm soát ở tất cả các giai đoạn từ truy cập vào nguồn đến đưa dữ liệu đến mặt tiền cửa hàng mục tiêu.
Năm nay, chúng tôi dự định hoàn thành MVP về việc khởi chạy các mô hình được viết bằng Python/R/Java trên Hadoop. Chúng tôi đã đặt cho mình nhiệm vụ đầy tham vọng là học cách chạy bất kỳ môi trường tùy chỉnh nào trên Hadoop, để không giới hạn người dùng nền tảng của chúng tôi theo bất kỳ cách nào.
Ngoài ra, hóa ra, nhiều chuyên gia DS rất xuất sắc về toán học và thống kê, tạo ra các mô hình thú vị nhưng không thành thạo lắm trong việc chuyển đổi dữ liệu lớn và họ cần sự trợ giúp của các kỹ sư dữ liệu của chúng tôi để chuẩn bị các mẫu đào tạo. Chúng tôi quyết định giúp đỡ các đồng nghiệp của mình và tạo ra các mô-đun tiện lợi để chuyển đổi tiêu chuẩn và chuẩn bị các tính năng cho các mẫu xe trên động cơ Spark. Điều này sẽ cho phép bạn dành nhiều thời gian hơn để phát triển các mô hình và không phải đợi các kỹ sư dữ liệu chuẩn bị tập dữ liệu mới.
Chúng tôi tuyển dụng những người có kiến thức chuyên môn trong nhiều lĩnh vực khác nhau: Linux và DevOps, Hadoop và Spark, Java và Spring, Scala và Akka, OpenShift và Kubernetes. Lần tới, chúng ta sẽ nói về thư viện mô hình, cách một mô hình trải qua vòng đời trong một công ty, và cách thức xác thực và triển khai diễn ra.
Nguồn: www.habr.com
