

Xin chào, tôi đang tạo ứng dụng cho DBMS là một nền tảng được phát triển bởi Mail.ru Group, kết hợp DBMS hiệu suất cao và máy chủ ứng dụng bằng ngôn ngữ Lua. Đặc biệt, các giải pháp dựa trên Tarantool đạt được tốc độ cao nhờ hỗ trợ chế độ trong bộ nhớ của DBMS và khả năng thực thi logic nghiệp vụ ứng dụng trong một không gian địa chỉ duy nhất với dữ liệu. Đồng thời, tính bền vững của dữ liệu được đảm bảo bằng cách sử dụng các giao dịch ACID (nhật ký WAL được duy trì trên đĩa). Tarantool có hỗ trợ tích hợp cho việc sao chép và phân chia. Bắt đầu từ phiên bản 2.1, các truy vấn bằng ngôn ngữ SQL được hỗ trợ. Tarantool là nguồn mở và được cấp phép theo giấy phép BSD đơn giản hóa. Ngoài ra còn có phiên bản Enterprise thương mại.

Cảm nhận sức mạnh! (…hay còn gọi là thưởng thức buổi biểu diễn)
Tất cả những điều trên làm cho Tarantool trở thành một nền tảng hấp dẫn để tạo các ứng dụng tải cao hoạt động với cơ sở dữ liệu. Trong các ứng dụng như vậy, thường cần phải sao chép dữ liệu.
Như đã đề cập ở trên, Tarantool có tính năng sao chép dữ liệu tích hợp. Nguyên tắc hoạt động của nó là thực hiện tuần tự trên các bản sao tất cả các giao dịch có trong nhật ký chính (WAL). Thông thường sự sao chép như vậy (chúng ta sẽ gọi thêm nó là cấp thấp) được sử dụng để đảm bảo khả năng chịu lỗi ứng dụng và/hoặc phân phối tải đọc giữa các nút cụm.
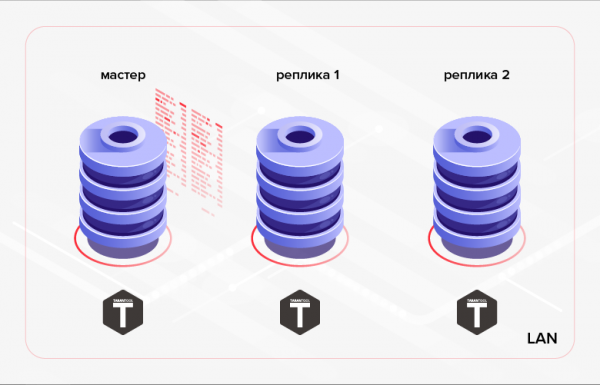
Cơm. 1. Sao chép trong một cụm
Một ví dụ về kịch bản thay thế sẽ là chuyển dữ liệu được tạo trong cơ sở dữ liệu này sang cơ sở dữ liệu khác để xử lý/giám sát. Trong trường hợp sau, một giải pháp thuận tiện hơn có thể là sử dụng cấp độ cao sao chép - sao chép dữ liệu ở cấp độ logic nghiệp vụ của ứng dụng. Những thứ kia. Chúng tôi không sử dụng giải pháp làm sẵn được tích hợp trong DBMS mà tự triển khai sao chép trong ứng dụng mà chúng tôi đang phát triển. Cách tiếp cận này có cả ưu điểm và nhược điểm. Hãy liệt kê những lợi thế.
1. Tiết kiệm lưu lượng:
- Bạn không thể chuyển tất cả dữ liệu mà chỉ chuyển một phần dữ liệu (ví dụ: bạn chỉ có thể chuyển một số bảng, một số cột hoặc bản ghi đáp ứng một tiêu chí nhất định);
- Không giống như sao chép cấp thấp, được thực hiện liên tục ở chế độ không đồng bộ (được triển khai trong phiên bản hiện tại của Tarantool - 1.10) hoặc chế độ đồng bộ (được triển khai trong các phiên bản tiếp theo của Tarantool), sao chép cấp cao có thể được thực hiện trong các phiên (tức là, trước tiên ứng dụng sẽ đồng bộ hóa dữ liệu - dữ liệu phiên trao đổi, sau đó tạm dừng sao chép, sau đó phiên trao đổi tiếp theo diễn ra, v.v.);
- nếu một bản ghi đã thay đổi nhiều lần, bạn chỉ có thể chuyển phiên bản mới nhất của nó (không giống như bản sao cấp thấp, trong đó tất cả các thay đổi được thực hiện trên bản gốc sẽ được phát lại tuần tự trên bản sao).
2. Không gặp khó khăn gì khi triển khai trao đổi HTTP, tính năng cho phép bạn đồng bộ hóa cơ sở dữ liệu từ xa.
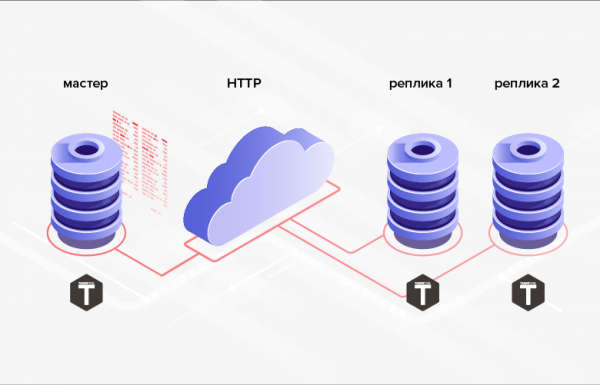
Cơm. 2. Sao chép qua HTTP
3. Cấu trúc cơ sở dữ liệu mà dữ liệu được truyền không nhất thiết phải giống nhau (hơn nữa, trong trường hợp chung, thậm chí có thể sử dụng các DBMS, ngôn ngữ lập trình, nền tảng khác nhau, v.v.).
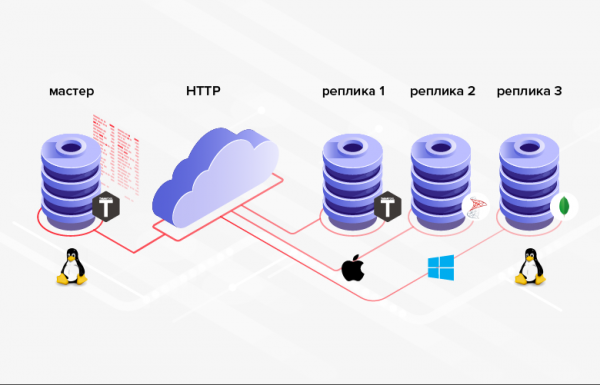
Cơm. 3. Nhân rộng trong các hệ thống không đồng nhất
Nhược điểm là, nhìn chung, việc lập trình khó hơn/tốn kém hơn so với cấu hình và thay vì tùy chỉnh chức năng tích hợp sẵn, bạn sẽ phải tự thực hiện.
Nếu trong trường hợp của bạn, những ưu điểm trên là quan trọng (hoặc là điều kiện cần thiết), thì bạn nên sử dụng bản sao cấp cao. Hãy xem xét một số cách để triển khai sao chép dữ liệu cấp cao trong DBMS Tarantool.
Giảm thiểu lưu lượng truy cập
Vì vậy, một trong những lợi ích của việc nhân rộng ở cấp độ cao là tiết kiệm lưu lượng. Để lợi thế này được phát huy hết, cần giảm thiểu lượng dữ liệu được truyền trong mỗi phiên trao đổi. Tất nhiên, chúng ta không nên quên rằng vào cuối phiên, bộ thu dữ liệu phải được đồng bộ hóa với nguồn (ít nhất là đối với phần dữ liệu liên quan đến việc sao chép).
Làm cách nào để giảm thiểu lượng dữ liệu được truyền trong quá trình sao chép cấp cao? Một giải pháp đơn giản có thể là chọn dữ liệu theo ngày và giờ. Để thực hiện việc này, bạn có thể sử dụng trường ngày giờ đã có trong bảng (nếu có). Ví dụ: tài liệu “đặt hàng” có thể có trường “thời gian thực hiện lệnh bắt buộc” - delivery_time. Vấn đề với giải pháp này là các giá trị trong trường này không nhất thiết phải theo thứ tự tương ứng với việc tạo đơn hàng. Vì vậy chúng ta không thể nhớ giá trị trường tối đa delivery_time, được truyền trong phiên trao đổi trước đó và trong phiên trao đổi tiếp theo, hãy chọn tất cả các bản ghi có giá trị trường cao hơn delivery_time. Các bản ghi có giá trị trường thấp hơn có thể đã được thêm vào giữa các phiên trao đổi delivery_time. Ngoài ra, thứ tự có thể đã trải qua những thay đổi, tuy nhiên điều này không ảnh hưởng đến lĩnh vực này delivery_time. Trong cả hai trường hợp, những thay đổi sẽ không được chuyển từ nguồn tới đích. Để giải quyết những vấn đề này, chúng ta sẽ cần truyền dữ liệu “chồng chéo”. Những thứ kia. trong mỗi phiên trao đổi chúng tôi sẽ chuyển toàn bộ dữ liệu có giá trị trường delivery_time, vượt quá một số điểm trong quá khứ (ví dụ: N giờ kể từ thời điểm hiện tại). Tuy nhiên, rõ ràng là đối với các hệ thống lớn, cách tiếp cận này rất dư thừa và có thể làm giảm mức tiết kiệm lưu lượng mà chúng ta đang nỗ lực đạt được xuống con số không. Ngoài ra, bảng đang được chuyển có thể không có trường được liên kết với ngày giờ.
Một giải pháp khác, phức tạp hơn về mặt thực hiện, là xác nhận việc nhận dữ liệu. Trong trường hợp này, trong mỗi phiên trao đổi, tất cả dữ liệu được truyền đi mà việc nhận dữ liệu đó chưa được người nhận xác nhận. Để thực hiện điều này, bạn sẽ cần thêm một cột Boolean vào bảng nguồn (ví dụ: is_transferred). Nếu người nhận xác nhận đã nhận bản ghi thì trường tương ứng sẽ nhận giá trị true, sau đó mục này không còn tham gia trao đổi nữa. Tùy chọn triển khai này có những nhược điểm sau. Đầu tiên, đối với mỗi bản ghi được chuyển đi, một xác nhận phải được tạo và gửi đi. Nói một cách đại khái, điều này có thể so sánh với việc tăng gấp đôi lượng dữ liệu được truyền và dẫn đến tăng gấp đôi số lượt khứ hồi. Thứ hai, không có khả năng gửi cùng một bản ghi cho nhiều người nhận (người nhận đầu tiên nhận sẽ xác nhận việc nhận cho chính họ và cho tất cả những người khác).
Một phương pháp không có nhược điểm nêu trên là thêm một cột vào bảng được chuyển để theo dõi những thay đổi trong các hàng của nó. Cột như vậy có thể thuộc loại ngày giờ và phải được ứng dụng đặt/cập nhật theo thời gian hiện tại mỗi lần các bản ghi được thêm/thay đổi (về mặt nguyên tử với việc bổ sung/thay đổi). Ví dụ, hãy gọi cột update_time. Bằng cách lưu giá trị trường tối đa của cột này cho các bản ghi được chuyển, chúng ta có thể bắt đầu phiên trao đổi tiếp theo với giá trị này (chọn các bản ghi có giá trị trường update_time, vượt quá giá trị được lưu trữ trước đó). Vấn đề với cách tiếp cận thứ hai là những thay đổi dữ liệu có thể xảy ra theo đợt. Là kết quả của các giá trị trường trong cột update_time có thể không phải là duy nhất. Do đó, cột này không thể được sử dụng để xuất dữ liệu theo từng trang (theo từng trang). Để hiển thị dữ liệu theo từng trang, bạn sẽ phải phát minh ra các cơ chế bổ sung mà rất có thể sẽ có hiệu quả rất thấp (ví dụ: truy xuất từ cơ sở dữ liệu tất cả các bản ghi có giá trị update_time cao hơn một giá trị nhất định và tạo ra một số lượng bản ghi nhất định, bắt đầu từ một khoảng chênh lệch nhất định tính từ đầu mẫu).
Bạn có thể cải thiện hiệu quả truyền dữ liệu bằng cách cải thiện một chút phương pháp trước đó. Để thực hiện việc này, chúng tôi sẽ sử dụng loại số nguyên (số nguyên dài) làm giá trị trường cột để theo dõi các thay đổi. Hãy đặt tên cho cột row_ver. Giá trị trường của cột này vẫn phải được đặt/cập nhật mỗi khi bản ghi được tạo/sửa đổi. Nhưng trong trường hợp này, trường sẽ không được chỉ định ngày giờ hiện tại mà giá trị của một số bộ đếm sẽ tăng thêm một. Kết quả là cột row_ver sẽ chứa các giá trị duy nhất và có thể được sử dụng không chỉ để hiển thị dữ liệu “delta” (dữ liệu được thêm/thay đổi kể từ khi kết thúc phiên trao đổi trước đó) mà còn để chia nhỏ nó thành các trang một cách đơn giản và hiệu quả.
Đối với tôi, phương pháp được đề xuất cuối cùng nhằm giảm thiểu lượng dữ liệu được truyền trong khuôn khổ sao chép cấp cao dường như là phương pháp tối ưu và phổ biến nhất. Chúng ta hãy xem xét nó chi tiết hơn.
Truyền dữ liệu bằng bộ đếm phiên bản hàng
Triển khai phần máy chủ/chính
Trong MS SQL Server, có một loại cột đặc biệt để triển khai phương pháp này - rowversion. Mỗi cơ sở dữ liệu có một bộ đếm tăng lên mỗi lần một bản ghi được thêm/thay đổi trong bảng có một cột như rowversion. Giá trị của bộ đếm này được tự động gán cho trường của cột này trong bản ghi được thêm/thay đổi. Tarantool DBMS không có cơ chế tích hợp tương tự. Tuy nhiên, trong Tarantool không khó để thực hiện thủ công. Chúng ta hãy xem làm thế nào điều này được thực hiện.
Đầu tiên, hãy tìm hiểu một chút về thuật ngữ: các bảng trong Tarantool được gọi là khoảng trắng và các bản ghi được gọi là bộ dữ liệu. Trong Tarantool bạn có thể tạo các chuỗi. Các chuỗi không có gì khác hơn là các trình tạo được đặt tên của các giá trị số nguyên có thứ tự. Những thứ kia. đây chính xác là những gì chúng ta cần cho mục đích của mình. Dưới đây chúng tôi sẽ tạo ra một chuỗi như vậy.
Trước khi thực hiện bất kỳ thao tác cơ sở dữ liệu nào trong Tarantool, bạn cần chạy lệnh sau:
box.cfg{}Do đó, Tarantool sẽ bắt đầu ghi ảnh chụp nhanh cơ sở dữ liệu và nhật ký giao dịch vào thư mục hiện tại.
Hãy tạo một chuỗi row_version:
box.schema.sequence.create('row_version',
{ if_not_exists = true })
Lựa chọn if_not_exists cho phép tập lệnh tạo được thực thi nhiều lần: nếu đối tượng tồn tại, Tarantool sẽ không cố tạo lại nó. Tùy chọn này sẽ được sử dụng trong tất cả các lệnh DDL tiếp theo.
Hãy tạo một không gian làm ví dụ.
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
},
{
name = 'row_ver',
type = 'unsigned'
}
},
if_not_exists = true
})
Ở đây chúng tôi đặt tên của không gian (goods), tên trường và loại của chúng.
Các trường tăng tự động trong Tarantool cũng được tạo bằng cách sử dụng các chuỗi. Hãy tạo khóa chính tăng tự động theo trường id:
box.schema.sequence.create('goods_id',
{ if_not_exists = true })
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})Tarantool hỗ trợ một số loại chỉ mục. Các chỉ mục được sử dụng phổ biến nhất là loại TREE và HASH, dựa trên cấu trúc tương ứng với tên. TREE là loại chỉ mục linh hoạt nhất. Nó cho phép bạn truy xuất dữ liệu một cách có tổ chức. Nhưng để lựa chọn bình đẳng thì HASH phù hợp hơn. Theo đó, nên sử dụng HASH cho khóa chính (đó là những gì chúng tôi đã làm).
Để sử dụng cột row_ver để truyền dữ liệu đã thay đổi, bạn cần liên kết các giá trị chuỗi với các trường của cột này row_ver. Nhưng không giống như khóa chính, giá trị trường cột row_ver sẽ tăng thêm một không chỉ khi thêm bản ghi mới mà còn khi thay đổi bản ghi hiện có. Bạn có thể sử dụng trình kích hoạt cho việc này. Tarantool có hai loại kích hoạt không gian: before_replace и on_replace. Trình kích hoạt được kích hoạt bất cứ khi nào dữ liệu trong không gian thay đổi (đối với mỗi bộ dữ liệu bị ảnh hưởng bởi các thay đổi, chức năng kích hoạt sẽ được khởi chạy). không giống on_replace, before_replace-triggers cho phép bạn sửa đổi dữ liệu của bộ mà trigger được thực thi. Theo đó, loại kích hoạt cuối cùng phù hợp với chúng tôi.
box.space.goods:before_replace(function(old, new)
return box.tuple.new({new[1], new[2], new[3],
box.sequence.row_version:next()})
end)
Trình kích hoạt sau sẽ thay thế giá trị trường row_ver được lưu trữ tuple vào giá trị tiếp theo của chuỗi row_version.
Để có thể trích xuất dữ liệu từ không gian goods theo cột row_ver, hãy tạo một chỉ mục:
box.space.goods:create_index('row_ver', {
parts = { 'row_ver' },
unique = true,
type = 'TREE',
if_not_exists = true
})
Loại chỉ mục - cây (TREE), bởi vì chúng ta sẽ cần trích xuất dữ liệu theo thứ tự tăng dần của các giá trị trong cột row_ver.
Hãy thêm một số dữ liệu vào không gian:
box.space.goods:insert{nil, 'pen', 123}
box.space.goods:insert{nil, 'pencil', 321}
box.space.goods:insert{nil, 'brush', 100}
box.space.goods:insert{nil, 'watercolour', 456}
box.space.goods:insert{nil, 'album', 101}
box.space.goods:insert{nil, 'notebook', 800}
box.space.goods:insert{nil, 'rubber', 531}
box.space.goods:insert{nil, 'ruler', 135}
Bởi vì Trường đầu tiên là bộ đếm tăng tự động; thay vào đó chúng ta chuyển số nil. Tarantool sẽ tự động thay thế giá trị tiếp theo. Tương tự, với giá trị của các trường cột row_ver bạn có thể chuyển số không - hoặc không chỉ định giá trị nào cả, bởi vì cột này chiếm vị trí cuối cùng trong không gian.
Hãy kiểm tra kết quả chèn:
tarantool> box.space.goods:select()
---
- - [1, 'pen', 123, 1]
- [2, 'pencil', 321, 2]
- [3, 'brush', 100, 3]
- [4, 'watercolour', 456, 4]
- [5, 'album', 101, 5]
- [6, 'notebook', 800, 6]
- [7, 'rubber', 531, 7]
- [8, 'ruler', 135, 8]
...
Như bạn có thể thấy, trường đầu tiên và trường cuối cùng được điền tự động. Bây giờ bạn sẽ dễ dàng viết một hàm để tải lên các thay đổi về không gian theo từng trang goods:
local page_size = 5
local function get_goods(row_ver)
local index = box.space.goods.index.row_ver
local goods = {}
local counter = 0
for _, tuple in index:pairs(row_ver, {
iterator = 'GT' }) do
local obj = tuple:tomap({ names_only = true })
table.insert(goods, obj)
counter = counter + 1
if counter >= page_size then
break
end
end
return goods
end
Hàm lấy tham số là giá trị row_ver, bắt đầu từ đó cần phải dỡ bỏ các thay đổi và trả về một phần dữ liệu đã thay đổi.
Việc lấy mẫu dữ liệu trong Tarantool được thực hiện thông qua các chỉ mục. Chức năng get_goods sử dụng một trình vòng lặp theo chỉ mục row_ver để nhận dữ liệu đã thay đổi. Kiểu lặp là GT (Lớn hơn, lớn hơn). Điều này có nghĩa là iterator sẽ tuần tự duyệt qua các giá trị chỉ mục bắt đầu từ key được truyền (giá trị trường row_ver).
Trình vòng lặp trả về các bộ dữ liệu. Để sau đó có thể truyền dữ liệu qua HTTP, cần phải chuyển đổi các bộ dữ liệu thành cấu trúc thuận tiện cho việc tuần tự hóa tiếp theo. Ví dụ sử dụng hàm tiêu chuẩn cho việc này tomap. Thay vì sử dụng tomap bạn có thể viết chức năng của riêng bạn. Ví dụ: chúng ta có thể muốn đổi tên một trường name, không vượt qua sân code và thêm một trường comment:
local function unflatten_goods(tuple)
local obj = {}
obj.id = tuple.id
obj.goods_name = tuple.name
obj.comment = 'some comment'
obj.row_ver = tuple.row_ver
return obj
end
Kích thước trang của dữ liệu đầu ra (số lượng bản ghi trong một phần) được xác định bởi biến page_size. Trong ví dụ giá trị page_size là 5. Trong một chương trình thực, kích thước trang thường quan trọng hơn. Nó phụ thuộc vào kích thước trung bình của bộ không gian. Kích thước trang tối ưu có thể được xác định theo kinh nghiệm bằng cách đo thời gian truyền dữ liệu. Kích thước trang càng lớn thì số lượng vòng quay giữa bên gửi và bên nhận càng nhỏ. Bằng cách này, bạn có thể giảm tổng thời gian tải xuống các thay đổi. Tuy nhiên, nếu kích thước trang quá lớn, chúng tôi sẽ mất quá nhiều thời gian cho máy chủ sắp xếp mẫu. Do đó, có thể có sự chậm trễ trong việc xử lý các yêu cầu khác đến máy chủ. Tham số page_size có thể được tải từ tập tin cấu hình. Đối với mỗi không gian được truyền, bạn có thể đặt giá trị riêng của nó. Tuy nhiên, đối với hầu hết các khoảng trắng, giá trị mặc định (ví dụ: 100) có thể phù hợp.
Hãy thực hiện chức năng get_goods:
tarantool> get_goods(0)
---
- - row_ver: 1
code: 123
name: pen
id: 1
- row_ver: 2
code: 321
name: pencil
id: 2
- row_ver: 3
code: 100
name: brush
id: 3
- row_ver: 4
code: 456
name: watercolour
id: 4
- row_ver: 5
code: 101
name: album
id: 5
...
Hãy lấy giá trị trường row_ver từ dòng cuối cùng và gọi lại hàm:
tarantool> get_goods(5)
---
- - row_ver: 6
code: 800
name: notebook
id: 6
- row_ver: 7
code: 531
name: rubber
id: 7
- row_ver: 8
code: 135
name: ruler
id: 8
...Một lần nữa:
tarantool> get_goods(8)
---
- []
...
Như bạn có thể thấy, khi sử dụng theo cách này, hàm sẽ trả về tất cả các bản ghi khoảng trắng theo từng trang goods. Trang cuối cùng được theo sau bởi một lựa chọn trống.
Hãy thực hiện thay đổi cho không gian:
box.space.goods:update(4, {{'=', 6, 'copybook'}})
box.space.goods:insert{nil, 'clip', 234}
box.space.goods:insert{nil, 'folder', 432}
Chúng tôi đã thay đổi giá trị trường name cho một mục và thêm hai mục mới.
Hãy lặp lại lệnh gọi hàm cuối cùng:
tarantool> get_goods(8)
---
- - row_ver: 9
code: 800
name: copybook
id: 6
- row_ver: 10
code: 234
name: clip
id: 9
- row_ver: 11
code: 432
name: folder
id: 10
...
Hàm trả về các bản ghi đã thay đổi và được thêm vào. Vì vậy chức năng get_goods cho phép bạn nhận dữ liệu đã thay đổi kể từ lần gọi cuối cùng, đây là cơ sở của phương pháp sao chép đang được xem xét.
Chúng tôi sẽ để việc đưa ra kết quả qua HTTP dưới dạng JSON nằm ngoài phạm vi của bài viết này. Bạn có thể đọc về điều này ở đây:
Triển khai phần client/slave
Chúng ta hãy xem việc triển khai của bên nhận trông như thế nào. Hãy tạo một khoảng trống ở phía nhận để lưu trữ dữ liệu đã tải xuống:
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
}
},
if_not_exists = true
})
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})
Cấu trúc của không gian giống với cấu trúc của không gian trong nguồn. Nhưng vì chúng ta sẽ không chuyển dữ liệu nhận được đi bất kỳ nơi nào khác nên cột row_ver không có trong không gian của người nhận. Trong lĩnh vực id định danh nguồn sẽ được ghi lại. Do đó, về phía người nhận không cần thiết phải tự động tăng.
Ngoài ra chúng ta cần một khoảng trống để lưu giá trị row_ver:
box.schema.space.create('row_ver', {
format = {
{
name = 'space_name',
type = 'string'
},
{
name = 'value',
type = 'string'
}
},
if_not_exists = true
})
box.space.row_ver:create_index('primary', {
parts = { 'space_name' },
unique = true,
type = 'HASH',
if_not_exists = true
})
Đối với mỗi không gian được tải (trường space_name) chúng tôi sẽ lưu giá trị được tải cuối cùng ở đây row_ver (cánh đồng value). Cột đóng vai trò là khóa chính space_name.
Hãy tạo một hàm để tải dữ liệu không gian goods thông qua HTTP. Để làm điều này, chúng ta cần một thư viện triển khai ứng dụng khách HTTP. Dòng sau tải thư viện và khởi tạo ứng dụng khách HTTP:
local http_client = require('http.client').new()Chúng tôi cũng cần một thư viện để giải tuần tự hóa json:
local json = require('json')Điều này là đủ để tạo chức năng tải dữ liệu:
local function load_data(url, row_ver)
local url = ('%s?rowVer=%s'):format(url,
tostring(row_ver))
local body = nil
local data = http_client:request('GET', url, body, {
keepalive_idle = 1,
keepalive_interval = 1
})
return json.decode(data.body)
end
Hàm thực thi một yêu cầu HTTP tới địa chỉ url và gửi nó row_ver dưới dạng tham số và trả về kết quả đã được giải tuần tự hóa của yêu cầu.
Chức năng lưu dữ liệu đã nhận trông như thế này:
local function save_goods(goods)
local n = #goods
box.atomic(function()
for i = 1, n do
local obj = goods[i]
box.space.goods:put(
obj.id, obj.name, obj.code)
end
end)
end
Chu kỳ lưu dữ liệu vào không gian goods được đặt trong một giao dịch (chức năng này được sử dụng cho việc này box.atomic) để giảm số lượng thao tác trên đĩa.
Cuối cùng, chức năng đồng bộ hóa không gian cục bộ goods với một nguồn bạn có thể triển khai nó như thế này:
local function sync_goods()
local tuple = box.space.row_ver:get('goods')
local row_ver = tuple and tuple.value or 0
—— set your url here:
local url = 'http://127.0.0.1:81/test/goods/list'
while true do
local goods = load_goods(url, row_ver)
local count = #goods
if count == 0 then
return
end
save_goods(goods)
row_ver = goods[count].rowVer
box.space.row_ver:put({'goods', row_ver})
end
end
Đầu tiên chúng ta đọc giá trị đã lưu trước đó row_ver cho không gian goods. Nếu thiếu (phiên trao đổi đầu tiên) thì chúng tôi coi là row_ver số không. Tiếp theo trong chu trình, chúng tôi thực hiện tải xuống từng trang dữ liệu đã thay đổi từ nguồn tại url được chỉ định. Ở mỗi lần lặp, chúng tôi lưu dữ liệu nhận được vào không gian cục bộ thích hợp và cập nhật giá trị row_ver (trong không gian row_ver và trong biến row_ver) - lấy giá trị row_ver từ dòng cuối cùng của dữ liệu được tải.
Để bảo vệ khỏi việc lặp lại ngẫu nhiên (trong trường hợp có lỗi trong chương trình), vòng lặp while có thể được thay thế bằng for:
for _ = 1, max_req do ...
Kết quả của việc thực hiện chức năng sync_goods không gian goods máy thu sẽ chứa các phiên bản mới nhất của tất cả các bản ghi không gian goods trong nguồn.
Rõ ràng, việc xóa dữ liệu không thể được phát sóng theo cách này. Nếu có nhu cầu như vậy, bạn có thể sử dụng dấu xóa. Thêm vào không gian goods trường boolean is_deleted và thay vì xóa bản ghi một cách vật lý, chúng tôi sử dụng tính năng xóa logic - chúng tôi đặt giá trị trường is_deleted thành ý nghĩa true. Đôi khi thay vì trường boolean is_deleted sẽ thuận tiện hơn khi sử dụng trường này deleted, nơi lưu trữ ngày-thời gian xóa bản ghi theo logic. Sau khi thực hiện xóa logic, bản ghi được đánh dấu xóa sẽ được chuyển từ nguồn đến đích (theo logic đã thảo luận ở trên).
Sự nối tiếp row_ver có thể được sử dụng để truyền dữ liệu từ các không gian khác: không cần tạo một chuỗi riêng cho từng không gian được truyền.
Chúng tôi đã xem xét một cách sao chép dữ liệu cấp cao hiệu quả trong các ứng dụng sử dụng Tarantool DBMS.
Những phát hiện
- Tarantool DBMS là một sản phẩm hấp dẫn, đầy hứa hẹn để tạo các ứng dụng có tải trọng cao.
- Sao chép dữ liệu cấp cao có một số lợi thế so với sao chép cấp thấp.
- Phương pháp sao chép cấp cao được thảo luận trong bài viết cho phép bạn giảm thiểu lượng dữ liệu được truyền bằng cách chỉ truyền những bản ghi đã thay đổi kể từ phiên trao đổi cuối cùng.
Nguồn: www.habr.com
