

Tiếp tục chủ đề các cuộc thi machine learning trên Habré, chúng tôi xin giới thiệu đến bạn đọc thêm hai nền tảng nữa. Chúng chắc chắn không lớn bằng kaggle, nhưng chúng chắc chắn đáng được chú ý.

Cá nhân tôi không thích kaggle quá nhiều vì nhiều lý do:
- thứ nhất, các cuộc thi ở đó thường kéo dài vài tháng và việc tham gia tích cực đòi hỏi nhiều nỗ lực;
- thứ hai, hạt nhân công cộng (giải pháp công cộng). Những người theo Kaggle khuyên nên đối xử với họ bằng sự bình tĩnh của các nhà sư Tây Tạng, nhưng trên thực tế, thật đáng xấu hổ khi thứ mà bạn đã nỗ lực trong một hoặc hai tháng đột nhiên được bày ra trên một đĩa bạc cho mọi người.
May mắn thay, các cuộc thi học máy được tổ chức trên các nền tảng khác và một số cuộc thi này sẽ được thảo luận.
| Ngôn ngữ chính thức: tiếng Anh, tổ chức: Yandex, Sberbank, HSE | Ngôn ngữ chính thức của Nga, nhà tổ chức: Tập đoàn Mail.ru |
| Vòng trực tuyến: 15/11 – 2019/XNUMX/XNUMX; Trận chung kết tại chỗ: ngày 4-6 tháng 2019 năm XNUMX | trực tuyến - từ ngày 7 tháng 15 đến ngày XNUMX tháng XNUMX; ngoại tuyến - từ ngày 30 tháng 1 đến ngày XNUMX tháng XNUMX. |
| Sử dụng một bộ dữ liệu nhất định về một hạt trong Máy Va chạm Hadron Lớn (quỹ đạo, động lượng và các thông số vật lý khá phức tạp khác), xác định xem nó có phải là muon hay không Từ tuyên bố này, 2 nhiệm vụ đã được xác định: — trong một trường hợp bạn chỉ cần gửi dự đoán của mình, - và mặt khác - mã và mô hình hoàn chỉnh để dự đoán và việc thực thi phải tuân theo các hạn chế khá nghiêm ngặt về thời gian chạy và sử dụng bộ nhớ | Đối với cuộc thi SNA Hackathon, nhật ký hiển thị nội dung từ các nhóm mở trong nguồn cấp tin tức của người dùng từ tháng 2018 đến tháng XNUMX năm XNUMX đã được thu thập. Bộ thử nghiệm chứa tuần rưỡi cuối cùng của tháng Ba. Mỗi mục trong nhật ký chứa thông tin về nội dung được hiển thị và cho ai, cũng như cách người dùng phản ứng với nội dung này: xếp hạng, nhận xét, bỏ qua hoặc ẩn nội dung đó khỏi nguồn cấp dữ liệu. Bản chất của nhiệm vụ SNA Hackathon là xếp hạng nguồn cấp dữ liệu của mỗi người dùng mạng xã hội Odnoklassniki, nâng cao nhất có thể những bài đăng sẽ nhận được “đẳng cấp”. Ở giai đoạn trực tuyến, nhiệm vụ được chia thành 3 phần: 1. xếp hạng bài viết theo các đặc điểm hợp tác khác nhau 2. xếp hạng bài viết dựa trên hình ảnh chứa trong đó 3. xếp hạng bài viết theo nội dung chứa trong đó |
| Số liệu tùy chỉnh phức tạp, giống như ROC-AUC | ROC-AUC trung bình theo người dùng |
| Giải thưởng cho giai đoạn đầu tiên - Áo phông cho N vị trí, vào giai đoạn thứ hai, nơi chi trả chỗ ở và bữa ăn trong suốt cuộc thi Giai đoạn thứ hai - ??? (Vì một số lý do nhất định, tôi đã không có mặt tại lễ trao giải và không thể tìm hiểu xem cuối cùng giải thưởng là gì). Họ hứa tặng máy tính xách tay cho tất cả các thành viên của đội chiến thắng | Giải thưởng cho chặng đầu tiên - Áo phông dành cho 100 người tham gia xuất sắc nhất, lọt vào chặng thứ hai, nơi đi đến Moscow, chỗ ở và bữa ăn trong suốt cuộc thi đã được thanh toán. Ngoài ra, khi kết thúc giai đoạn đầu tiên, giải thưởng đã được công bố cho người xuất sắc nhất trong 3 nhiệm vụ ở giai đoạn 1: mọi người đều giành được một card màn hình RTX 2080 TI! Giai đoạn 2 là vòng thi đồng đội, các đội từ 5 đến XNUMX người, giải thưởng: Vị trí số 1 - 300 rúp Vị trí số 2 - 200 rúp Vị trí số 3 - 100 rúp giải thưởng của ban giám khảo - 100 rúp |
| Nhóm telegram chính thức, ~190 người tham gia, giao tiếp bằng tiếng Anh, thắc mắc phải đợi vài ngày mới có câu trả lời | Nhóm chính thức trên telegram, ~1500 người tham gia, thảo luận tích cực về nhiệm vụ giữa người tham gia và người tổ chức |
| Ban tổ chức đưa ra hai giải pháp cơ bản, đơn giản và nâng cao. Đơn giản yêu cầu RAM dưới 16 GB và bộ nhớ nâng cao không vừa với 16 GB. Đồng thời, nhìn về phía trước một chút, những người tham gia không thể vượt trội hơn đáng kể so với giải pháp tiên tiến. Không có khó khăn gì trong việc đưa ra các giải pháp này. Cần lưu ý rằng trong ví dụ nâng cao có một nhận xét kèm theo gợi ý về nơi bắt đầu cải thiện giải pháp. | Các giải pháp sơ khai cơ bản được cung cấp cho từng nhiệm vụ mà người tham gia dễ dàng vượt qua. Trong những ngày đầu của cuộc thi, những người tham gia gặp phải một số khó khăn: thứ nhất, dữ liệu được cung cấp ở định dạng Apache Parquet và không phải tất cả sự kết hợp giữa Python và gói parquet đều hoạt động mà không có lỗi. Khó khăn thứ hai là tải ảnh từ đám mây thư; hiện tại không có cách nào dễ dàng để tải xuống một lượng lớn dữ liệu cùng một lúc. Kết quả là những vấn đề này đã khiến người tham gia bị trì hoãn trong vài ngày. |
IDAO. Giai đoạn đầu
Nhiệm vụ là phân loại các hạt muon/không muon theo đặc tính của chúng. Đặc điểm chính của nhiệm vụ này là sự hiện diện của một cột trọng số trong dữ liệu huấn luyện, mà chính ban tổ chức hiểu là sự tin cậy vào câu trả lời cho dòng này. Vấn đề là có khá nhiều hàng chứa trọng số âm.
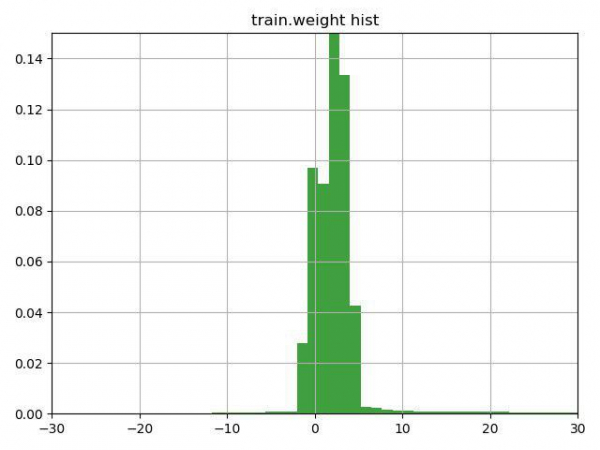
Sau khi suy nghĩ vài phút về dòng có gợi ý (gợi ý chỉ đơn giản thu hút sự chú ý đến đặc điểm này của cột trọng số) và xây dựng biểu đồ này, chúng tôi quyết định kiểm tra 3 tùy chọn:
1) đảo ngược mục tiêu của các dòng có trọng số âm (và trọng số tương ứng)
2) chuyển trọng số về giá trị tối thiểu để chúng bắt đầu từ 0
3) không sử dụng trọng lượng chuỗi
Phương án thứ ba hóa ra là tệ nhất, nhưng hai phương án đầu tiên đã cải thiện kết quả, tốt nhất là phương án số 1, ngay lập tức đưa chúng tôi đến vị trí thứ hai hiện tại trong nhiệm vụ đầu tiên và hạng nhất trong nhiệm vụ thứ hai.

Bước tiếp theo của chúng tôi là xem xét dữ liệu để tìm các giá trị còn thiếu. Ban tổ chức đã cung cấp cho chúng tôi dữ liệu đã được tổng hợp sẵn, trong đó có khá nhiều giá trị bị thiếu và chúng được thay thế bằng -9999.
Chúng tôi đã tìm thấy các giá trị bị thiếu trong các cột MatchedHit_{X,Y,Z[N] và MatchedHit_D{X,Y,Z[N] và chỉ khi N=2 hoặc 3. Theo chúng tôi hiểu, một số hạt không vượt qua tất cả 4 máy dò và dừng lại ở tấm thứ 3 hoặc thứ 4. Dữ liệu cũng chứa các cột Lextra_{X,Y[N], dường như mô tả điều tương tự như MatchedHit_{X,Y,Z[N], nhưng sử dụng một số loại ngoại suy. Những phỏng đoán ít ỏi này gợi ý rằng Lextra_{X,Y[N] có thể được thay thế cho các giá trị còn thiếu trong MatchedHit_{X,Y,Z[N] (chỉ dành cho tọa độ X và Y). MatchedHit_Z[N] được lấp đầy bằng số trung vị. Những thao tác này đã cho phép chúng tôi đạt được vị trí trung gian số 1 trong cả hai nhiệm vụ.

Cho rằng họ không đưa ra bất cứ điều gì để giành chiến thắng ở chặng đầu tiên, lẽ ra chúng tôi có thể dừng lại ở đó, nhưng chúng tôi vẫn tiếp tục, vẽ một số bức tranh đẹp và nghĩ ra những tính năng mới.
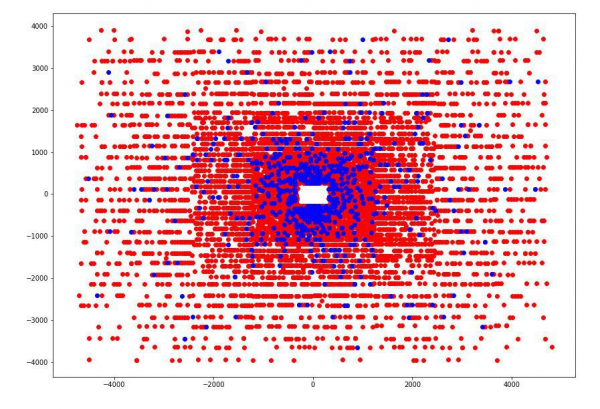
Ví dụ: chúng tôi thấy rằng nếu chúng tôi vẽ các điểm giao nhau của một hạt với mỗi trong số bốn tấm máy dò, chúng tôi có thể thấy rằng các điểm trên mỗi tấm được nhóm thành 5 hình chữ nhật với tỷ lệ khung hình từ 4 đến 5 và tập trung vào điểm (0,0) và trong Không có điểm nào trong hình chữ nhật đầu tiên.
| Số tấm/kích thước hình chữ nhật | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Tấm 1 | 500h625 | 1000h1250 | 2000h2500 | 4000h5000 | 8000h10000 |
| Tấm 2 | 520h650 | 1040h1300 | 2080h2600 | 4160h5200 | 8320h10400 |
| Tấm 3 | 560h700 | 1120h1400 | 2240h2800 | 4480h5600 | 8960h11200 |
| Tấm 4 | 600h750 | 1200h1500 | 2400h3000 | 4800h6000 | 9600h12000 |
Sau khi xác định các kích thước này, chúng tôi đã thêm 4 đặc điểm phân loại mới cho mỗi hạt - số hình chữ nhật mà nó giao nhau với mỗi tấm.
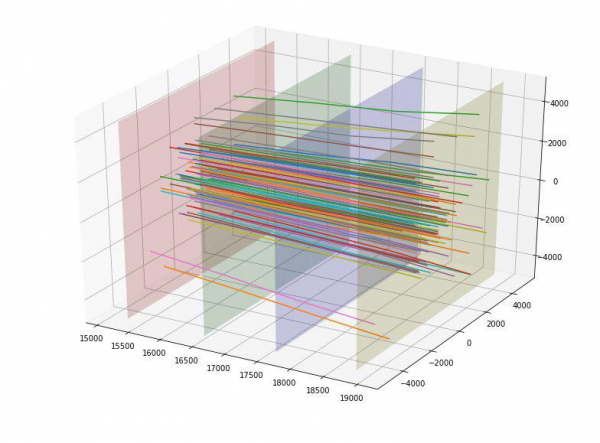
Chúng tôi cũng nhận thấy rằng các hạt dường như phân tán sang hai bên tính từ tâm và nảy sinh ý tưởng bằng cách nào đó đánh giá “chất lượng” của sự tán xạ này. Lý tưởng nhất là có thể nghĩ ra một loại parabol “lý tưởng” nào đó tùy thuộc vào điểm cất cánh và ước tính độ lệch so với điểm đó, nhưng chúng tôi tự giới hạn ở đường thẳng “lý tưởng”. Sau khi xây dựng những đường thẳng lý tưởng như vậy cho mỗi điểm đi vào, chúng tôi có thể tính được độ lệch chuẩn của quỹ đạo của từng hạt so với đường thẳng này. Vì độ lệch trung bình của mục tiêu = 1 là 152 và đối với mục tiêu = 0 là 390, nên chúng tôi tạm đánh giá tính năng này là tốt. Và thực sự, tính năng này ngay lập tức lọt vào top những tính năng hữu ích nhất.
Chúng tôi rất vui mừng và đã thêm độ lệch của cả 4 điểm giao nhau cho mỗi hạt so với đường thẳng lý tưởng dưới dạng 4 tính năng bổ sung (và chúng cũng hoạt động tốt).
Các liên kết đến các bài báo khoa học về chủ đề của cuộc thi do ban tổ chức cung cấp cho chúng tôi đã gợi lên ý tưởng rằng chúng tôi không phải là người đầu tiên giải quyết vấn đề này và có lẽ có một số loại phần mềm chuyên dụng. Sau khi phát hiện ra một kho lưu trữ trên github nơi các phương thức IsMuonSimple, IsMuon, IsMuonLoose được triển khai, chúng tôi đã chuyển chúng sang trang web của mình với một số sửa đổi nhỏ. Bản thân các phương pháp này rất đơn giản: ví dụ, nếu năng lượng nhỏ hơn một ngưỡng nhất định thì đó không phải là muon, nếu không thì đó là muon. Các tính năng đơn giản như vậy rõ ràng không thể làm tăng trường hợp sử dụng tính năng tăng cường độ dốc, vì vậy chúng tôi đã thêm một “khoảng cách” đáng kể khác vào ngưỡng. Những tính năng này cũng đã được cải thiện một chút. Có lẽ, bằng cách phân tích kỹ hơn các phương pháp hiện có, người ta có thể tìm ra những phương pháp mạnh hơn và bổ sung chúng vào các dấu hiệu.
Kết thúc cuộc thi, chúng tôi điều chỉnh lại một chút cách giải “nhanh” cho bài toán thứ XNUMX, cuối cùng nó khác với đường cơ sở ở những điểm sau:
- Trong các hàng có trọng số âm, mục tiêu đã bị đảo ngược
- Điền các giá trị còn thiếu trong MatchedHit_{X,Y,Z[N]
- Giảm độ sâu xuống 7
- Giảm tỷ lệ học xuống 0.1 (là 0.19)
Do đó, chúng tôi đã thử nhiều tính năng hơn (không thành công lắm), các tham số đã chọn và catboost, lightgbm và xgboost đã được huấn luyện, đã thử các cách kết hợp dự đoán khác nhau và trước khi mở riêng tư, chúng tôi đã tự tin giành chiến thắng trong nhiệm vụ thứ hai và trong nhiệm vụ đầu tiên, chúng tôi nằm trong số những người các nhà lãnh đạo.
Sau khi mở riêng tư, chúng tôi đứng ở vị trí thứ 10 cho nhiệm vụ đầu tiên và thứ 1 cho nhiệm vụ thứ hai. Tất cả các nhà lãnh đạo đều bối rối, và tốc độ ở phần riêng tư cao hơn trên bảng lib. Có vẻ như dữ liệu được phân tầng kém (hoặc ví dụ: không có hàng nào có trọng số âm ở phần riêng tư) và điều này hơi khó chịu.
SNA Hackathon 2019 - Văn bản. Giai đoạn đầu
Nhiệm vụ là xếp hạng các bài đăng của người dùng trên mạng xã hội Odnoklassniki dựa trên văn bản chứa trong đó; ngoài văn bản, còn có thêm một số đặc điểm của bài đăng (ngôn ngữ, chủ sở hữu, ngày và giờ tạo, ngày và giờ xem). ).
Theo các phương pháp cổ điển để làm việc với văn bản, tôi sẽ nêu bật hai tùy chọn:
- Ánh xạ mỗi từ vào một không gian vectơ n chiều sao cho các từ giống nhau có vectơ giống nhau (đọc thêm trong ), sau đó tìm từ trung bình cho văn bản hoặc sử dụng các cơ chế có tính đến vị trí tương đối của các từ (CNN, LSTM/GRU).
- Sử dụng các mô hình có thể hoạt động ngay lập tức với toàn bộ câu. Ví dụ như Bert. Về lý thuyết, cách tiếp cận này sẽ hoạt động tốt hơn.
Vì đây là trải nghiệm đầu tiên của tôi với kinh văn nên sẽ là sai lầm nếu dạy ai đó, nên tôi sẽ tự dạy mình. Đây là những lời khuyên tôi sẽ đưa ra cho mình khi bắt đầu cuộc thi:
- Trước khi bạn bắt đầu dạy điều gì đó, hãy nhìn vào dữ liệu! Ngoài văn bản, dữ liệu còn có một số cột và tôi có thể khai thác được nhiều cột hơn tôi. Điều đơn giản nhất là thực hiện mã hóa mục tiêu trung bình cho một số cột.
- Đừng học hỏi từ tất cả dữ liệu! Có rất nhiều dữ liệu (khoảng 17 triệu hàng) và hoàn toàn không cần thiết phải sử dụng tất cả chúng để kiểm tra các giả thuyết. Quá trình đào tạo và tiền xử lý diễn ra khá chậm và rõ ràng là tôi đã có thời gian để thử nghiệm những giả thuyết thú vị hơn.
- <Lời khuyên gây tranh cãi> Không cần phải tìm kiếm một mô hình sát thủ. Tôi đã dành một thời gian dài để tìm hiểu Elmo và Bert, hy vọng rằng họ sẽ ngay lập tức đưa tôi lên một vị trí cao và kết quả là tôi đã sử dụng các phần nhúng được đào tạo trước của FastText cho tiếng Nga. Tôi không thể đạt được tốc độ tốt hơn với Elmo và tôi vẫn không có thời gian để tìm hiểu điều đó với Bert.
- <Lời khuyên gây tranh cãi> Không cần phải tìm kiếm một tính năng sát thủ. Nhìn vào dữ liệu, tôi nhận thấy rằng khoảng 1 phần trăm văn bản không thực sự chứa văn bản! Nhưng có những liên kết đến một số tài nguyên và tôi đã viết một trình phân tích cú pháp đơn giản để mở trang web và lấy ra tiêu đề cũng như mô tả. Đó có vẻ là một ý tưởng hay, nhưng sau đó tôi bị cuốn theo và quyết định phân tích tất cả các liên kết cho tất cả các văn bản và một lần nữa lại mất rất nhiều thời gian. Tất cả điều này không mang lại sự cải thiện đáng kể trong kết quả cuối cùng (mặc dù tôi đã tìm ra cách xuất phát chẳng hạn).
- Các tính năng cổ điển hoạt động. Ví dụ: chúng tôi Google, “tính năng văn bản kaggle”, đọc và thêm mọi thứ. TF-IDF đã cung cấp một cải tiến cũng như các tính năng thống kê như độ dài văn bản, từ và số lượng dấu câu.
- Nếu có các cột DateTime, bạn nên phân tích chúng thành nhiều tính năng riêng biệt (giờ, ngày trong tuần, v.v.). Những tính năng nào cần được làm nổi bật sẽ được phân tích bằng biểu đồ/một số số liệu. Ở đây, trong một khoảnh khắc bất chợt, tôi đã làm mọi thứ một cách chính xác và nêu bật các tính năng cần thiết, nhưng một phân tích bình thường sẽ không có hại gì (ví dụ, như chúng tôi đã làm ở trận chung kết).
Kết quả của cuộc thi, tôi đã đào tạo một mô hình máy ảnh với tính năng tích chập từ và một mô hình khác dựa trên LSTM và GRU. Cả hai đều sử dụng các phần nhúng FastText được đào tạo trước cho tiếng Nga (tôi đã thử một số phần nhúng khác, nhưng đây là những phần nhúng hoạt động tốt nhất). Sau khi tính trung bình các dự đoán, tôi đứng ở vị trí thứ 7 chung cuộc trong tổng số 76 người tham gia.
Sau giai đoạn đầu tiên nó đã được xuất bản , người chiếm vị trí thứ hai (anh ấy tham gia không cạnh tranh) và giải pháp của anh ấy ở một giai đoạn nào đó lặp lại của tôi, nhưng anh ấy đã tiến xa hơn nhờ cơ chế chú ý truy vấn-khóa-giá trị.
Giai đoạn thứ hai OK & IDAO
Giai đoạn thứ hai của cuộc thi diễn ra gần như liên tiếp nên tôi quyết định xem chúng cùng nhau.
Đầu tiên, tôi và nhóm mới được mua lại đến văn phòng ấn tượng của công ty Mail.ru, nơi nhiệm vụ của chúng tôi là kết hợp mô hình của ba bản nhạc từ giai đoạn đầu tiên - văn bản, hình ảnh và cộng tác. Hơn 2 ngày được phân bổ cho việc này, hóa ra là rất ít. Trên thực tế, chúng tôi chỉ có thể lặp lại kết quả của giai đoạn đầu mà không nhận được bất kỳ lợi ích nào từ việc sáp nhập. Cuối cùng chúng tôi đứng thứ 5 nhưng không thể sử dụng mẫu văn bản. Sau khi xem xét giải pháp của những người tham gia khác, có vẻ như việc cố gắng phân cụm các văn bản và thêm chúng vào mô hình cộng tác là điều đáng giá. Một tác dụng phụ của giai đoạn này là những ấn tượng mới, gặp gỡ và giao tiếp với những người tham gia và người tổ chức thú vị, cũng như tình trạng thiếu ngủ nghiêm trọng, có thể ảnh hưởng đến kết quả của giai đoạn cuối cùng của IDAO.
Nhiệm vụ ở giai đoạn Chung kết IDAO 2019 là dự đoán thời gian chờ đặt hàng của các tài xế taxi Yandex tại sân bay. Ở giai đoạn 2, 3 nhiệm vụ = 3 sân bay đã được xác định. Đối với mỗi sân bay, dữ liệu từng phút về số lượng đơn đặt hàng taxi trong sáu tháng được cung cấp. Và dưới dạng dữ liệu thử nghiệm, dữ liệu tháng tiếp theo và dữ liệu từng phút về các đơn đặt hàng trong 2 tuần qua đã được cung cấp. Có rất ít thời gian (1,5 ngày), nhiệm vụ khá cụ thể, chỉ có một người trong đội đến tham gia cuộc thi - và kết quả là về cuối cuộc thi là một nơi đáng buồn. Những ý tưởng thú vị bao gồm nỗ lực sử dụng dữ liệu bên ngoài: thời tiết, ùn tắc giao thông và thống kê đơn đặt hàng taxi Yandex. Dù ban tổ chức không cho biết những sân bay này là gì nhưng nhiều người tham gia cho rằng đó là Sheremetyevo, Domodedovo và Vnukovo. Mặc dù giả định này đã bị bác bỏ sau cuộc thi, nhưng các tính năng, chẳng hạn như dữ liệu thời tiết ở Moscow, đã cải thiện kết quả cả về xác nhận và trên bảng xếp hạng.
Kết luận
- Các cuộc thi ML rất hay và thú vị! Ở đây bạn sẽ tìm thấy việc sử dụng các kỹ năng trong phân tích dữ liệu cũng như trong các mô hình và kỹ thuật tinh vi cũng như ý thức chung đơn giản đều được chào đón.
- ML đã là một khối kiến thức khổng lồ dường như đang tăng lên theo cấp số nhân. Tôi đặt cho mình mục tiêu làm quen với các lĩnh vực khác nhau (tín hiệu, hình ảnh, bảng biểu, văn bản) và đã nhận ra có bao nhiêu điều cần phải học. Ví dụ: sau những cuộc thi này, tôi quyết định nghiên cứu: thuật toán phân cụm, các kỹ thuật nâng cao để làm việc với các thư viện tăng cường độ dốc (đặc biệt là làm việc với CatBoost trên GPU), mạng viên nang, cơ chế chú ý truy vấn-khóa-giá trị.
- Không phải bởi kaggle một mình! Có nhiều cuộc thi khác mà việc nhận được ít nhất một chiếc áo phông sẽ dễ dàng hơn và có nhiều cơ hội nhận được các giải thưởng khác hơn.
- Giao tiếp! Hiện đã có một cộng đồng lớn trong lĩnh vực học máy và phân tích dữ liệu, có các nhóm chuyên đề về telegram, Slack và những người nghiêm túc từ Mail.ru, Yandex và các công ty khác trả lời các câu hỏi và giúp đỡ những người mới bắt đầu cũng như những người tiếp tục con đường của họ trong lĩnh vực này kiến thức.
- Tôi khuyên tất cả những người được truyền cảm hứng từ điểm trước đó nên ghé thăm – một hội nghị miễn phí lớn ở Moscow, sẽ diễn ra vào ngày 10-11 tháng XNUMX.
Nguồn: www.habr.com
