

אָפט מענטשן וואָס אַרייַן די פעלד פון דאַטאַ וויסנשאַפֿט האָבן ווייניקער ווי רעאַליסטיש עקספּעקטיישאַנז פון וואָס אַווייץ זיי. פילע מענטשן טראַכטן אַז איצט זיי וועלן שרייַבן קיל נעוראַל נעטוואָרקס, שאַפֿן אַ קול אַסיסטאַנט פון Iron Man, אָדער שלאָגן אַלעמען אין די פינאַנציעל מארקפלעצער.
אָבער אַרבעט דאַטע ססיענטיסט איז דאַטן-געטריבן, און איינער פון די מערסט וויכטיק און צייט-קאַנסומינג אַספּעקץ איז פּראַסעסינג די דאַטן איידער פידינג עס אין אַ נעוראַל נעץ אָדער אַנאַלייזינג עס אין אַ זיכער וועג.
אין דעם אַרטיקל, אונדזער מאַנשאַפֿט וועט באַשרייַבן ווי איר קענען פּראָצעס דאַטן געשווינד און לייכט מיט שריט-דורך-שריט ינסטראַקשאַנז און קאָד. מיר געפרוווט צו מאַכן די קאָד גאַנץ פלעקסאַבאַל און קען זיין געוויינט פֿאַר פאַרשידענע דאַטאַסעץ.
פילע פּראָפעססיאָנאַלס קען נישט געפֿינען עפּעס ויסערגעוויינלעך אין דעם אַרטיקל, אָבער ביגינערז קענען לערנען עפּעס נייַ, און ווער עס יז וואָס האט לאַנג געחלומט צו מאַכן אַ באַזונדער העפט פֿאַר שנעל און סטראַקטשערד דאַטן פּראַסעסינג קענען נאָכמאַכן די קאָד און פֿאָרמאַט עס פֿאַר זיך, אָדער
מיר האָבן באקומען די דאַטן. וואָס צו טאָן ווייַטער?
אַזוי, דער נאָרמאַל: מיר דאַרפֿן צו פֿאַרשטיין וואָס מיר האַנדלען מיט, די קוילעלדיק בילד. צו טאָן דאָס, מיר נוצן פּאַנדאַס צו פשוט דעפינירן פאַרשידענע דאַטן טייפּס.
import pandas as pd #импортируем pandas
import numpy as np #импортируем numpy
df = pd.read_csv("AB_NYC_2019.csv") #читаем датасет и записываем в переменную df
df.head(3) #смотрим на первые 3 строчки, чтобы понять, как выглядят значения 
df.info() #Демонстрируем информацию о колонках 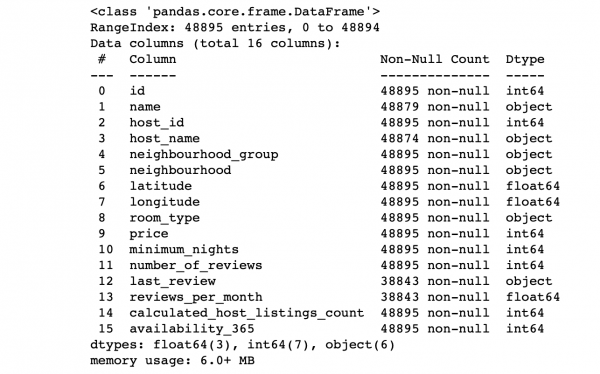
זאל ס קוק אין די זייַל וואַלועס:
- צי די נומער פון שורות אין יעדער זייַל שטימען צו די גאַנץ נומער פון שורות?
- וואָס איז די עסאַנס פון די דאַטן אין יעדער זייַל?
- וואָס זייַל טאָן מיר וועלן צו ציל צו מאַכן פֿאָרויסזאָגן פֿאַר אים?
די ענטפֿערס צו די פֿראגן וועט לאָזן איר צו פונאַנדערקלייַבן די דאַטאַסעט און בעערעך ציען אַ פּלאַן פֿאַר דיין ווייַטער אַקשאַנז.
אויך, פֿאַר אַ דיפּער קוק אין די וואַלועס אין יעדער זייַל, מיר קענען נוצן די פּאַנדאַס דיסקרייב () פונקציע. אָבער, די כיסאָרן פון דעם פֿונקציע איז אַז עס טוט נישט צושטעלן אינפֿאָרמאַציע וועגן שפאלטן מיט שטריקל וואַלועס. מי ר װעל ן זי ך שפעטע ר באהאנדלען .
df.describe() 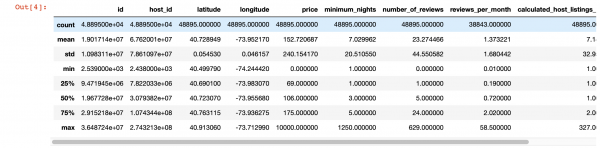
מאַגיק וויזשוואַלאַזיישאַן
זאל ס קוק אין ווו מיר האָבן קיין וואַלועס אין אַלע:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis') 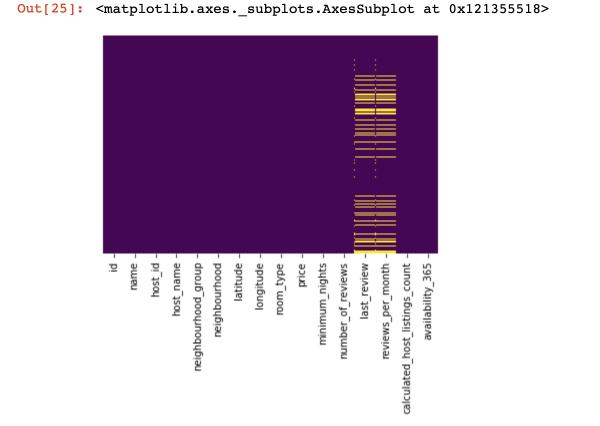
דאָס איז געווען אַ קורץ קוק פון אויבן, איצט מיר וועלן גיין אויף צו מער טשיקאַווע זאכן
לאָמיר פּרובירן צו געפֿינען און, אויב מעגלעך, אַראָפּנעמען שפאלטן וואָס האָבן בלויז איין ווערט אין אַלע ראָוז (זיי וועלן נישט ווירקן די רעזולטאַט אין קיין וועג):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] #Перезаписываем датасет, оставляя только те колонки, в которых больше одного уникального значенияאיצט מיר באַשיצן זיך און די הצלחה פון אונדזער פּרויעקט פון דופּליקאַט שורות (שורות וואָס אַנטהאַלטן די זעלבע אינפֿאָרמאַציע אין דער זעלביקער סדר ווי איינער פון די יגזיסטינג שורות):
df.drop_duplicates(inplace=True) #Делаем это, если считаем нужным.
#В некоторых проектах удалять такие данные с самого начала не стоит.מיר טיילן די דאַטאַסעט אין צוויי: איינער מיט קוואַליטאַטיווע וואַלועס, און די אנדערע מיט קוואַנטיטאַטיווע
דאָ מיר דאַרפֿן צו מאַכן אַ קליין קלעראַפאַקיישאַן: אויב די שורות מיט פעלנדיק דאַטן אין קוואַליטאַטיווע און קוואַנטיטאַטיווע דאַטן זענען נישט זייער קאָראַלייטאַד מיט יעדער אנדערע, דעמאָלט מיר דאַרפֿן צו באַשליסן וואָס מיר קרבן - אַלע די שורות מיט פעלנדיק דאַטן, בלויז טייל פון זיי, אָדער זיכער שפאלטן. אויב די שורות זענען קאָראַלייטאַד, מיר האָבן אַלע רעכט צו טיילן די דאַטאַסעט אין צוויי. אַנדערש, איר וועט ערשטער דאַרפֿן צו האַנדלען מיט די שורות וואָס טאָן ניט קאָראַלייט די פעלנדיק דאַטן אין קוואַליטאַטיווע און קוואַנטיטאַטיווע, און בלויז דעמאָלט טיילן די דאַטאַסעט אין צוויי.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])מיר טאָן דאָס צו מאַכן עס גרינגער פֿאַר אונדז צו פּראָצעס די צוויי פאַרשידענע טייפּס פון דאַטן - שפּעטער מיר וועלן פֿאַרשטיין ווי פיל גרינגער דאָס מאכט אונדזער לעבן.
מיר אַרבעטן מיט קוואַנטיטאַטיווע דאַטן
דער ערשטער זאַך מיר זאָל טאָן איז צו באַשליסן צי עס זענען "שפּיאָן שפאלטן" אין די קוואַנטיטאַטיווע דאַטן. מיר רופן די שפאלטן אַז ווייַל זיי פאָרשטעלן זיך ווי קוואַנטיטאַטיווע דאַטן, אָבער אַקט ווי קוואַליטאַטיווע דאַטן.
ווי טאָן מיר דעפינירן זיי? פון קורס, עס אַלע דעפּענדס אויף די נאַטור פון די דאַטן איר אַנאַלייז, אָבער אין אַלגעמיין, אַזאַ שפאלטן קען האָבן אַ ביסל יינציק דאַטן (אין דער געגנט פון 3-10 יינציק וואַלועס).
print(df_numerical.nunique())אַמאָל מיר האָבן יידענאַפייד די שפּיאָן שפאלטן, מיר וועלן מאַך זיי פון קוואַנטיטאַטיווע דאַטן צו קוואַליטאַטיווע דאַטן:
spy_columns = df_numerical[['колонка1', 'колока2', 'колонка3']]#выделяем колонки-шпионы и записываем в отдельную dataframe
df_numerical.drop(labels=['колонка1', 'колока2', 'колонка3'], axis=1, inplace = True)#вырезаем эти колонки из количественных данных
df_categorical.insert(1, 'колонка1', spy_columns['колонка1']) #добавляем первую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка2', spy_columns['колонка2']) #добавляем вторую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка3', spy_columns['колонка3']) #добавляем третью колонку-шпион в качественные данныеצום סוף, מיר האָבן גאָר אפגעשיידט קוואַנטיטאַטיווע דאַטן פון קוואַליטאַטיווע דאַטן און איצט מיר קענען אַרבעטן מיט עס רעכט. דער ערשטער זאַך איז צו פֿאַרשטיין ווו מיר האָבן ליידיק וואַלועס (נאַן, און אין עטלעכע קאַסעס 0 וועט זיין אנגענומען ווי ליידיק וואַלועס).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())אין דעם פונט, עס איז וויכטיק צו פֿאַרשטיין אין וואָס שפאלטן זעראָס קען אָנווייַזן פעלנדיק וואַלועס: איז דאָס רעכט צו ווי די דאַטן זענען געזאמלט? אָדער קען עס זיין שייַכות צו די דאַטן וואַלועס? די פראגעס מוזן זיין געענטפערט אויף אַ פאַל-ביי-פאַל יקער.
אַזוי, אויב מיר נאָך באַשליסן אַז מיר קען זיין פעלנדיק דאַטן ווו עס זענען זעראָס, מיר זאָל פאַרבייַטן די זעראָס מיט NaN צו מאַכן עס גרינגער צו אַרבעטן מיט די פאַרפאַלן דאַטן שפּעטער:
df_numerical[["колонка 1", "колонка 2"]] = df_numerical[["колонка 1", "колонка 2"]].replace(0, nan)איצט לאָמיר זען ווו מיר פעלן דאַטן:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # Можно также воспользоваться df_numerical.info() 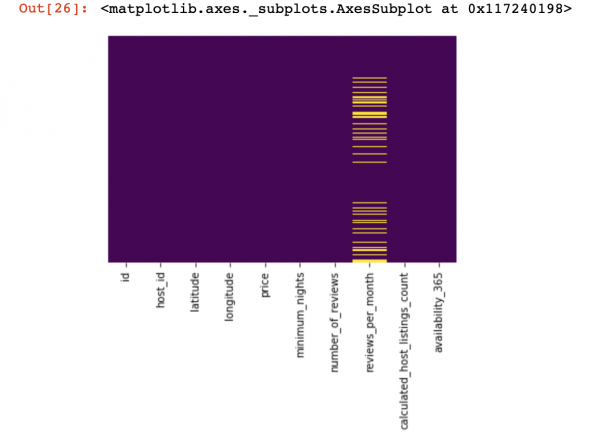
דאָ די וואַלועס ין די שפאלטן וואָס זענען פעלנדיק זאָל זיין אנגעצייכנט אין געל. און איצט די שפּאַס הייבט - ווי צו האַנדלען מיט די וואַלועס? זאָל איך ויסמעקן ראָוז מיט די וואַלועס אָדער שפאלטן? אָדער פּלאָמבירן די ליידיק וואַלועס מיט עטלעכע אנדערע?
דאָ איז אַן אַפּפּראָקסימאַטע דיאַגראַמע וואָס קענען העלפֿן איר באַשליסן וואָס קענען, אין פּרינציפּ, זיין געטאן מיט ליידיק וואַלועס:
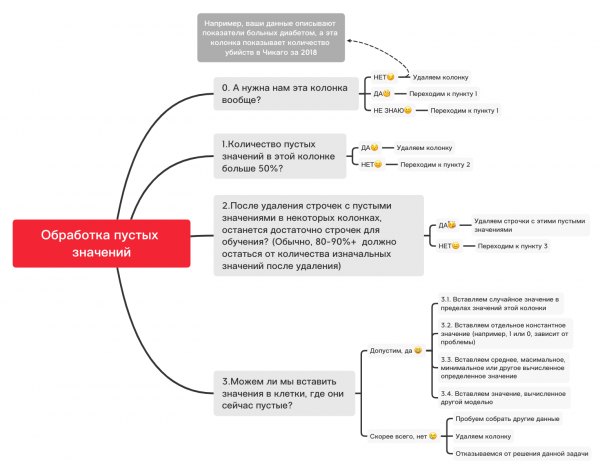
0. אַראָפּנעמען ומנייטיק שפאלטן
df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. איז די נומער פון ליידיק וואַלועס אין דעם זייַל מער ווי 50%?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)#Удаляем, если какая-то колонка имеет больше 50 пустых значений2. ויסמעקן שורות מיט ליידיק וואַלועס
df_numerical.dropna(inplace=True)#Удаляем строчки с пустыми значениями, если потом останется достаточно данных для обучения3.1. ינסערטינג אַ טראַפ - ווערט
import random #импортируем random
df_numerical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True) #вставляем рандомные значения в пустые клетки таблицы3.2. ינסערטינג אַ קעסיידערדיק ווערט
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>") #вставляем определенное значение с помощью SimpleImputer
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.3. אַרייַנלייגן די דורכשניטלעך אָדער רובֿ אָפט ווערט
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) #вместо mean можно также использовать most_frequent
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.4. אַרייַנלייגן די ווערט קאַלקיאַלייטיד דורך אן אנדער מאָדעל
מאל וואַלועס קענען זיין קאַלקיאַלייטיד מיט ראַגרעשאַן מאָדעלס ניצן מאָדעלס פון די סקלעאַרן ביבליאָטעק אָדער אנדערע ענלעך לייברעריז. אונדזער מאַנשאַפֿט וועט אָפּגעבן אַ באַזונדער אַרטיקל אויף ווי דאָס קענען זיין געטאן אין דעם לעבן צוקונפֿט.
דערווייַל, די דערציילונג וועגן קוואַנטיטאַטיווע דאַטן וועט זיין ינטעראַפּטיד, ווייַל עס זענען פילע אנדערע נואַנסיז וועגן ווי צו בעסער מאַכן דאַטן צוגרייטונג און פּרעפּראָסעססינג פֿאַר פאַרשידענע טאַסקס, און די יקערדיק טינגז פֿאַר קוואַנטיטאַטיווע דאַטן זענען גענומען אין חשבון אין דעם אַרטיקל, און איצט איז די צייט צו צוריקקומען צו קוואַליטאַטיווע דאַטן וואָס מיר אפגעשיידט עטלעכע טריט צוריק פון די קוואַנטיטאַטיווע. איר קענען טוישן דעם העפט ווי איר ווילט, צופּאַסן עס צו פאַרשידענע טאַסקס, אַזוי אַז די פּריפּראַסעסינג פון דאַטן איז זייער געשווינד!
קוואַליטאַטיווע דאַטן
בייסיקלי, פֿאַר קוואַליטאַטיווע דאַטן, די איין-הייס-ענקאָדינג אופֿן איז געניצט אין סדר צו פֿאָרמאַט עס פון אַ שטריקל (אָדער כייפעץ) צו אַ נומער. איידער איר מאַך אויף צו דעם פונט, לאָזן אונדז נוצן די דיאַגראַמע און קאָד אויבן צו האַנדלען מיט ליידיק וואַלועס.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis') 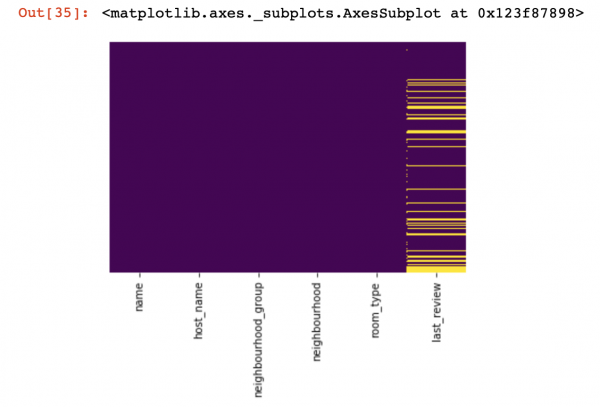
0. אַראָפּנעמען ומנייטיק שפאלטן
df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. איז די נומער פון ליידיק וואַלועס אין דעם זייַל מער ווי 50%?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True) #Удаляем, если какая-то колонка
#имеет больше 50% пустых значений2. ויסמעקן שורות מיט ליידיק וואַלועס
df_categorical.dropna(inplace=True)#Удаляем строчки с пустыми значениями,
#если потом останется достаточно данных для обучения3.1. ינסערטינג אַ טראַפ - ווערט
import random
df_categorical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True)3.2. ינסערטינג אַ קעסיידערדיק ווערט
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>")
df_categorical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_categorical[['колонка1', 'колонка2', 'колонка3']])
df_categorical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True)אַזוי, מיר האָבן לעסאָף באַקומען אַ שעפּן אויף נולז אין קוואַליטאַטיווע דאַטן. איצט עס איז צייט צו דורכפירן איין-הייס קאָדירונג אויף די וואַלועס וואָס זענען אין דיין דאַטאַבייס. דער אופֿן איז אָפט געניצט צו ענשור אַז דיין אַלגערידאַם קענען לערנען פון הויך-קוואַליטעט דאַטן.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["колонка1","колонка2","колонка3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))אַזוי, מיר האָבן לעסאָף פאַרטיק פּראַסעסינג באַזונדער קוואַליטאַטיווע און קוואַנטיטאַטיווע דאַטן - צייט צו פאַרבינדן זיי צוריק
new_df = pd.concat([df_numerical,df_categorical], axis=1)נאָך מיר האָבן קאַמביינד די דאַטאַסעץ צוזאַמען אין איין, מיר קענען לעסאָף נוצן דאַטן טראַנספאָרמאַציע ניצן MinMaxScaler פֿון די סקלעאַרן ביבליאָטעק. דאָס וועט מאַכן אונדזער וואַלועס צווישן 0 און 1, וואָס וועט העלפֿן ווען טריינינג די מאָדעל אין דער צוקונפֿט.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)די דאַטן זענען איצט גרייט פֿאַר אַלץ - נעוראַל נעטוואָרקס, נאָרמאַל ML אַלגערידאַמז, עטק!
אין דעם אַרטיקל, מיר טאָן ניט נעמען אין חשבון ארבעטן מיט צייט סעריע דאַטן, ווייַל פֿאַר אַזאַ דאַטן איר זאָל נוצן אַ ביסל אַנדערש פּראַסעסינג טעקניקס, דיפּענדינג אויף דיין אַרבעט. אין דער צוקונפֿט, אונדזער מאַנשאַפֿט וועט אָפּגעבן אַ באַזונדער אַרטיקל צו דעם טעמע, און מיר האָפֿן אַז עס וועט קענען צו ברענגען עפּעס טשיקאַווע, נייַ און נוציק אין דיין לעבן, פּונקט ווי דאָס.
מקור: www.habr.com
