

在前两篇文章中,我提出了自动化问题并勾勒出其框架,在第二篇文章中,我退回到网络虚拟化,作为自动化服务配置的第一种方法。
现在是时候绘制物理网络图了。
如果您不熟悉设置数据中心网络,那么我强烈建议您从 .
所有问题:
本系列中描述的实践应该适用于任何类型的网络、任何规模、任何种类的供应商(不是)。然而,不可能描述这些方法的应用的通用示例。因此,我将重点关注DC网络的现代架构: .
我们将在 MPLS L3VPN 上进行 DCI。
Overlay 网络在主机的物理网络之上运行(这可以是 OpenStack 的 VXLAN 或 Tungsten Fabric 或任何其他仅需要网络基本 IP 连接的网络)。
在这种情况下,我们得到了一个相对简单的自动化场景,因为我们有很多设备以相同的方式配置。
我们将选择真空中的球形 DC:
- 到处都是一种设计版本。
- 两个厂商组成两个网络平面。
- 一个 DC 就像另一个 DC 一样,就像豆荚里的两颗豌豆。
内容
- 物理拓扑
- 路由
- 知识产权计划
- 腊八
- 结论
- 有用的链接
例如,让我们的服务提供商 LAN_DC 托管有关在电梯卡住时生存的培训视频。
在大城市,这非常流行,因此您需要大量物理机器。
首先,我将按照我的意愿大致描述该网络。然后我将在实验室中简化它。
物理拓扑
地点
LAN_DC 将有 6 个 DC:
- 俄罗斯 (RU):
- 莫斯科(MSK)
- 喀山(克兹恩)
- 西班牙 (SP):
- 巴塞罗那(BCN)
- 马拉加(MLG)
- 中国 (CN):
- 上海 (沙)
- 西安(两)

DC 内部(DC 内)
所有 DC 都具有基于 Clos 拓扑的相同内部连接网络。
它们是什么类型的 Clos 网络以及为什么它们位于单独的网络中 .
每个 DC 有 10 个装有机器的机架,它们将编号为 A, B, C 等。
每个机架有30台机器。他们不会让我们感兴趣。
此外,在每个机架中都有一个所有机器都连接到的交换机 - 这是 架顶式交换机 - ToR 否则,就 Clos 工厂而言,我们将其称为 叶.

工厂总图。
我们会打电话给他们 XXX-叶Y哪里 XXX - 三字母缩写 DC,以及 Y - 序列号。例如, kzn-leaf11.
在我的文章中,我将允许自己相当随意地使用术语 Leaf 和 ToR 作为同义词。然而,我们必须记住,事实并非如此。
ToR 是安装在连接机器的机架中的交换机。
Leaf是物理网络中设备的角色,或者是Cloes拓扑中的第一级交换机。
也就是说,Leaf != ToR。
例如,Leaf 可以是 EndofRaw 交换机。
然而,在本文的框架内,我们仍然将它们视为同义词。
每个 ToR 交换机依次连接到四个更高级别的聚合交换机 - 脊柱。 DC 中的一个机架分配给 Spines。我们将类似地命名它: XXX-脊柱Y.
同一机架将包含用于板载 MPLS 的 DC-2 路由器之间连接的网络设备。但总的来说,这些职责范围是相同的。也就是说,从 Spine 交换机的角度来看,连接机器的通常 ToR 或用于 DCI 的路由器并不重要 - 一个转发的地狱。
这种特殊的 ToR 称为 边叶型。我们会打电话给他们 XXX-边缘Y.
它看起来像这样。
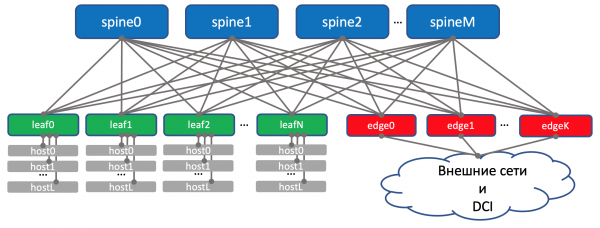
在上图中,我实际上将边缘和叶子放置在同一水平面上。 他们教导我们将上行链路(因此称为上行链路)视为上行链路。事实证明,DCI“上行链路”再次下降,这对某些人来说稍微打破了通常的逻辑。在大型网络的情况下,当数据中心被划分为更小的单元时 - POD的(交货点),突出显示个人 边缘POD用于 DCI 和访问外部网络。
为了将来便于感知,我仍然会将 Edge 绘制在 Spine 之上,同时我们要记住,Spine 上没有智能,并且在使用常规 Leaf 和 Edge-leaf 时没有差异(尽管这里可能存在细微差别) ,但一般来说这是正确的)。
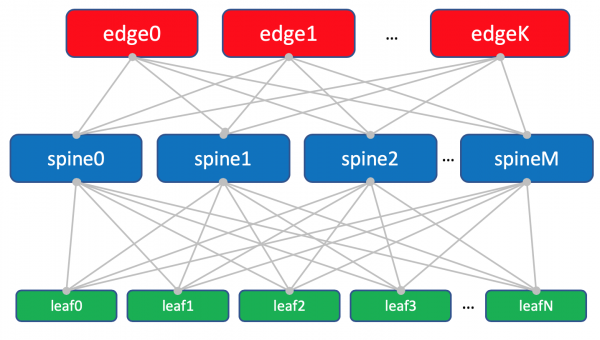
带边叶的工厂方案。
Leaf、Spine 和 Edge 三位一体形成了一个 Underlay 网络或工厂。
网络工厂的任务(阅读Underlay),正如我们已经在中定义的 ,非常非常简单 - 在同一 DC 内以及它们之间的机器之间提供 IP 连接。
这就是为什么网络被称为工厂,就像模块化网络盒内的交换工厂一样,您可以在中阅读更多信息 .
一般来说,这样的拓扑被称为工厂,因为fabric翻译过来就是fabric的意思。很难不同意:
工厂完全是L3。没有 VLAN,没有广播 - 我们在 LAN_DC 拥有如此优秀的程序员,他们知道如何编写生活在 L3 范式中的应用程序,并且虚拟机不需要保留 IP 地址的实时迁移。
再次:回答为什么工厂和 L3 是在一个单独的地方的问题 .
DCI - 数据中心互连(DC 间)
DCI 将使用 Edge-Leaf 进行组织,也就是说,它们是我们高速公路的出口点。
为简单起见,我们假设 DC 通过直接链路相互连接。
让我们排除外部连接的考虑。
我知道每次删除一个组件时,我都会显着简化网络。当我们将抽象网络自动化时,一切都会好起来的,但在真实的网络上就会有拐杖。
这是真实的。尽管如此,本系列的重点是思考和研究方法,而不是英勇地解决想象中的问题。
在 Edge-Leaf 上,底层被放置在 VPN 中并通过 MPLS 主干网(相同的直接链路)传输。
这是我们得到的顶层图。

路由
对于 DC 内的路由,我们将使用 BGP。
MPLS 中继上的OSPF+LDP。
对于 DCI,即在地下组织连接 - 基于 MPLS 的 BGP L3VPN。
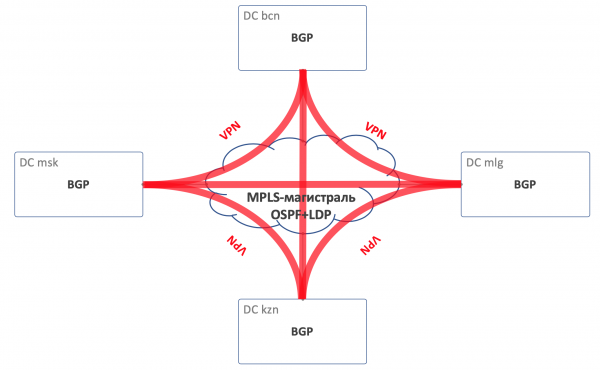
通用路由方案
工厂没有 OSPF 或 ISIS(俄罗斯联邦禁止的路由协议)。
这意味着不会自动发现或计算最短路径——只有手动(实际上是自动的——我们在这里讨论的是自动化)设置协议、邻域和策略。
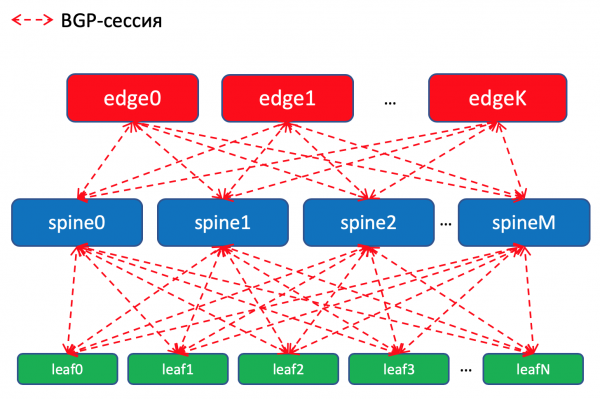
DC内BGP路由方案
为什么选择 BGP?
关于这个话题有 以 Facebook 和 Arista 命名,讲述如何构建 很大 使用 BGP 的数据中心网络。它读起来几乎就像小说一样,我强烈推荐它度过一个慵懒的夜晚。
我的文章中还有一整节专门讨论这一点。我该带你去哪里 .
但总而言之,没有IGP适合网络设备数量达到数千台的大型数据中心网络。
此外,到处使用 BGP 将使您不必浪费时间支持多种不同的协议以及它们之间的同步。
说实话,在我们工厂,大概率不会快速发展,OSPF 就足够了。这些实际上是大型企业和云巨头的问题。但让我们想象一下,只有几个版本需要它,我们将使用 BGP,正如 Pyotr Lapukhov 遗赠的那样。
路由策略
在 Leaf 交换机上,我们将前缀从 Underlay 网络接口导入到 BGP 中。
我们将在以下人员之间进行 BGP 会话: 每 叶-主干对,其中这些底层前缀将通过网络来回公布。
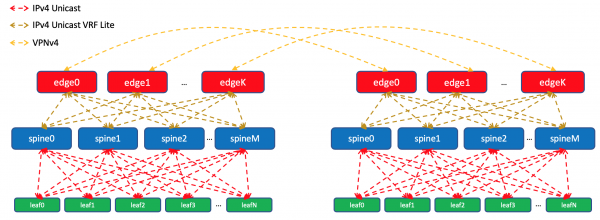
在一个数据中心内,我们将分发导入 ToRe 的规范。在 Edge-Leafs 上,我们将聚合它们并向远程 DC 宣布并将它们发送到 TOR。也就是说,每个 ToR 将确切地知道如何到达同一 DC 中的另一个 ToR,以及到达另一个 DC 中的 ToR 的入口点。
在DCI中,路由将作为VPNv4传输。为此,在 Edge-Leaf 上,通往工厂的接口将放置在 VRF 中,我们将其称为 UNDERLAY,Edge-Leaf 上的 Spine 邻域将在 VRF 内以及 VPNv4 中的 Edge-Leaf 之间上升 -家庭。
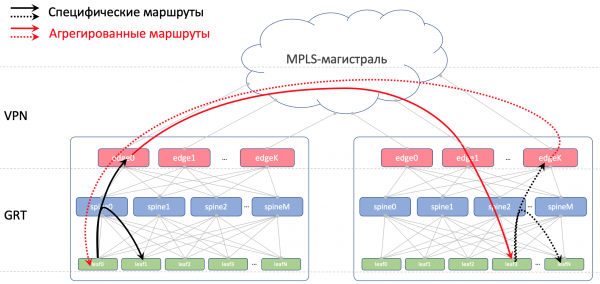
我们还将禁止重新宣布从脊椎收到的路由返回给它们。
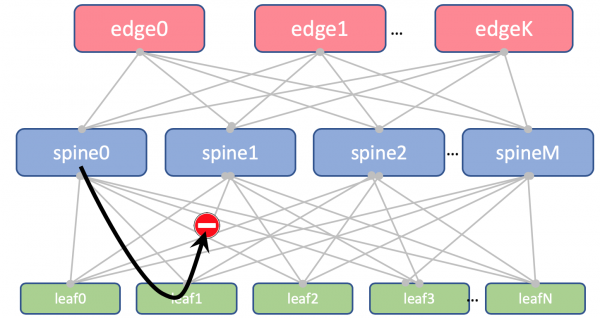
在 Leaf 和 Spine 上,我们不会导入 Loopback。我们只需要它们来确定路由器 ID。
但在 Edge-Leafs 上,我们将其导入全局 BGP。在环回地址之间,Edge-Leaf 将在 IPv4 VPN 系列中相互建立 BGP 会话。
我们将在 EDGE 设备之间建立 OSPF+LDP 主干网。一切都在一个区域。配置极其简单。
这是带有路由的图片。
BGP ASN
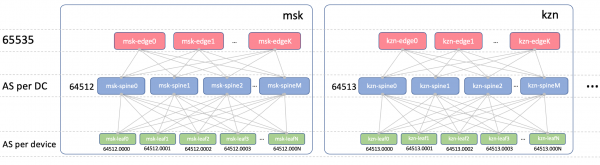
边叶 ASN
Edge-Leafs 将在所有 DC 中拥有一个 ASN。 Edge-Leaf 之间存在 iBGP 非常重要,我们不会陷入 eBGP 的细微差别中。设为 65535。实际上,这可能是公共 AS 的编号。
脊椎ASN
在 Spine 上,每个 DC 都有一个 ASN。让我们从私有 AS 范围中的第一个数字开始 - 64512、64513 等等。
为什么选择 DC 上的 ASN?
让我们把这个问题分成两个:
- 为什么一个 DC 的所有主干上的 ASN 都相同?
- 为什么它们在不同的 DC 中有所不同?
为什么一个 DC 的所有主干上都有相同的 ASN?
Edge-Leaf 上 Underlay 路由的 AS 路径如下所示:
[leafX_ASN, spine_ASN, edge_ASN]
当您尝试将其通告回 Spine 时,它将丢弃它,因为它的 AS (Spine_AS) 已在列表中。
然而,在 DC 内,我们完全满意的是,上升到 Edge 的 Underlay 路由将无法下降。 DC 内主机之间的所有通信都必须发生在主干级别内。
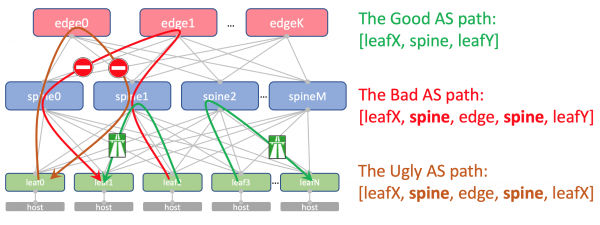
同时,其他 DC 的聚合路由在任何情况下都将轻松到达 ToR - 它们的 AS 路径将只有 ASN 65535 - AS Edge-Leaf 的数量,因为那是它们创建的地方。
为什么它们在不同的 DC 中有所不同?
理论上,我们可能需要在DC之间拖拽Loopback和一些业务虚拟机。
例如,在主机上我们将运行 Route Reflector 或 (虚拟网络网关),它将通过 BGP 与 TopR 锁定并宣布其环回,该环回应该可以从所有 DC 访问。
所以它的 AS 路径如下所示:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN]
并且任何地方都不应该有重复的 ASN。
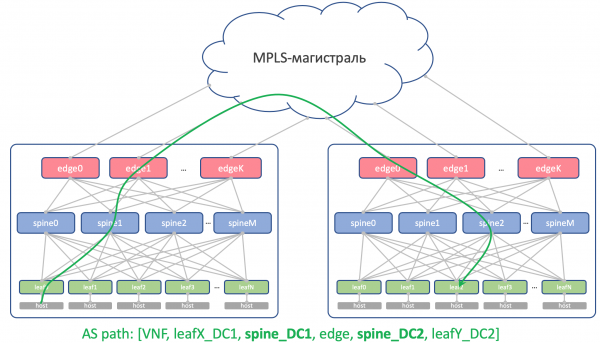
也就是说,Spine_DC1 和 Spine_DC2 必须不同,就像 leafX_DC1 和 leafY_DC2 一样,这正是我们正在接近的。
您可能知道,尽管有环路预防机制(Cisco 上的allowas-in),有些黑客仍允许您接受具有重复 ASN 的路由。它甚至还有合法用途。但这是网络稳定性的潜在差距。我个人也曾陷入过几次。
如果我们有机会不使用危险的东西,我们就会利用它。
叶ASN
我们将在整个网络中的每个叶子交换机上都有一个单独的 ASN。
我们这样做的原因如下:AS 路径没有环路,BGP 配置没有书签。
为了使Leaf之间的路由顺利通过,AS-Path应该如下所示:
[leafX_ASN, spine_ASN, leafY_ASN]
其中 leafX_ASN 和 leafY_ASN 最好是不同的。
对于 DC 之间宣布 VNF 环回的情况也需要这样做:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN]
我们将使用 4 字节的 ASN,并根据 Spine 的 ASN 和 Leaf 交换机编号生成它,即如下所示: Spine_ASN.0000X.
这是带有 ASN.1 的图片。
知识产权计划
基本上,我们需要为以下连接分配地址:
- ToR 和计算机之间的底层网络地址。它们在整个网络中必须是唯一的,以便任何机器都可以与任何其他机器通信。非常合身 10/8。每个机架有 /26 个备用。我们将为每个 DC 分配 /19,为每个区域分配 /17。
- Leaf/Tor 和 Spine 之间的链接地址。
我想通过算法来分配它们,即根据需要连接的设备的名称来计算它们。
就这样吧...169.254.0.0/16。
即, 169.254.00X.Y/31哪里 X - 脊柱数量, Y ——P2P网络/31.
这将允许您在 DC 中启动最多 128 个机架和最多 10 个 Spine。链接地址可以(并且将会)在 DC 之间重复。 - 我们在子网上组织 Spine-Edge-Leaf 连接 169.254.10X.Y/31,其中完全相同 X - 脊柱数量, Y ——P2P网络/31.
- 从 Edge-Leaf 到 MPLS 主干网的链路地址。这里的情况有些不同 - 所有部分都连接成一个饼,因此重复使用相同的地址将不起作用 - 您需要选择下一个空闲子网。因此,我们以 192.168.0.0/16 我们将从其中剔除免费的。
- 环回地址。我们将为他们提供整个系列 172.16.0.0/12.
- Leaf - /25 每个 DC - 相同的 128 个机架。我们将为每个区域分配/23。
- Spine - /28 每个 DC - 最多 16 个 Spine。让我们为每个区域分配 /26。
- Edge-Leaf - 每个 DC /29 - 最多 8 盒。让我们为每个区域分配/27。
如果我们在 DC 中没有足够的分配范围(并且不会有任何范围 - 我们声称是超大规模器),我们只需选择下一个块。
这是带有 IP 寻址的图片。
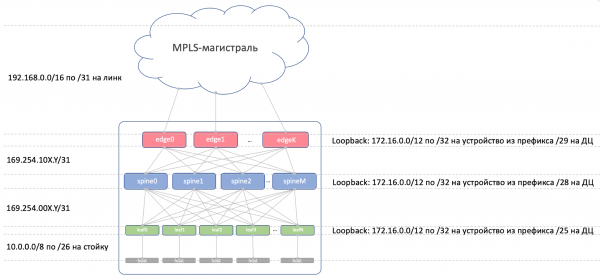
环回:
字首
设备角色
地区
直流
172.16.0.0/23
边缘
172.16.0.0/27
ru
172.16.0.0/29
MSK
172.16.0.8/29
克兹恩
172.16.0.32/27
sp
172.16.0.32/29
BCN
172.16.0.40/29
MLG
172.16.0.64/27
cn
172.16.0.64/29
沙
172.16.0.72/29
两
172.16.2.0/23
脊柱
172.16.2.0/26
ru
172.16.2.0/28
MSK
172.16.2.16/28
克兹恩
172.16.2.64/26
sp
172.16.2.64/28
BCN
172.16.2.80/28
MLG
172.16.2.128/26
cn
172.16.2.128/28
沙
172.16.2.144/28
两
172.16.8.0/21
叶
172.16.8.0/23
ru
172.16.8.0/25
MSK
172.16.8.128/25
克兹恩
172.16.10.0/23
sp
172.16.10.0/25
BCN
172.16.10.128/25
MLG
172.16.12.0/23
cn
172.16.12.0/25
沙
172.16.12.128/25
两
衬垫:
字首
地区
直流
10.0.0.0/17
ru
10.0.0.0/19
MSK
10.0.32.0/19
克兹恩
10.0.128.0/17
sp
10.0.128.0/19
BCN
10.0.160.0/19
MLG
10.1.0.0/17
cn
10.1.0.0/19
沙
10.1.32.0/19
两
腊八
两个供应商。一网。 ADSM。
杜松 + 阿里斯塔。 Ubuntu好样的,伊娃。
Mirana 虚拟服务器上的资源量仍然有限,因此在实践中我们将使用简化到极限的网络。
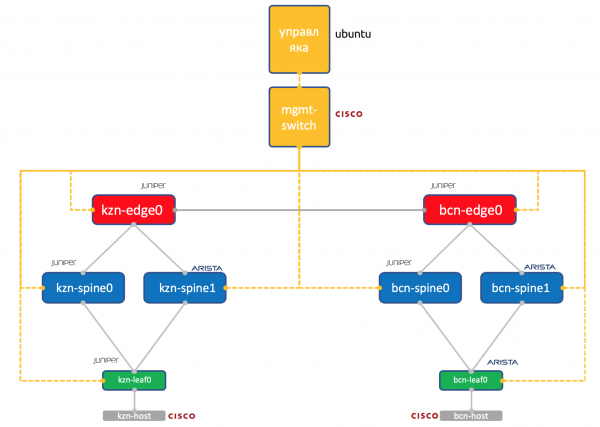
两个数据中心:喀山和巴塞罗那。
- 各有两个脊椎:Juniper 和 Arista。
- Juniper 和 Arista 中各有一个环面(叶),连接一台主机(为此我们采用轻量级 Cisco IOL)。
- 每个 Edge-Leaf 节点(目前仅限 Juniper)。
- 一台思科交换机即可统治所有这些。
- 除了网络设备外,还启动了一个虚拟机管理器。在控制下 Ubuntu.
它可以访问所有设备,它将运行 IPAM/DCIM 系统、一堆 Python 脚本、Ansible 以及我们可能需要的任何其他内容。
所有网络设备,我们将尝试使用自动化来重现。
结论
这也被接受了吗?我应该在每篇文章下写一个简短的结论吗?
所以我们选择了 DC 内的 Kloz 网络,因为我们预计会有大量东西向流量并需要 ECMP。
网络分为物理网络(underlay)和虚拟网络(overlay)。同时,覆盖层从主机开始——从而简化了对底层的要求。
我们选择 BGP 作为网络网络的路由协议,是因为它具有可扩展性和策略灵活性。
我们将有单独的节点来组织 DCI - Edge-leaf。
骨干网将采用OSPF+LDP。
DCI将基于MPLS L3VPN来实现。
对于P2P链接,我们将根据设备名称通过算法计算IP地址。
我们将根据设备的角色及其位置顺序分配环回。
底层前缀 - 仅在叶交换机上根据其位置顺序排列。
假设现在我们还没有安装设备。
因此,我们接下来的步骤是将它们添加到系统(IPAM、库存)、组织访问、生成配置并部署它。
在下一篇文章中,我们将讨论 Netbox——DC 中 IP 空间的库存和管理系统。
谢谢
- Andrey Glazkov 又名 @glazgoo 进行校对和更正
- Alexander Klimenko 又名 @v00lk 进行校对和编辑
- KDPV 的 Artyom Chernobay
来源: habr.com
