

我继续讲如何交友Exchange和ELK(开头 )。 让我提醒您,这种组合能够毫不犹豫地处理大量日志。 这次我们将讨论如何让 Exchange 与 Logstash 和 Kibana 组件一起工作。
ELK堆栈中的Logstash用于智能处理日志并准备以文档的形式放置在Elastic中,在此基础上可以方便地在Kibana中构建各种可视化。
安装
由两个阶段组成:
- 安装和配置 OpenJDK 包。
- 安装和配置 Logstash 软件包。
安装和配置 OpenJDK 包
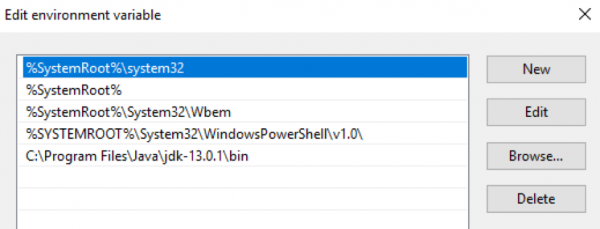
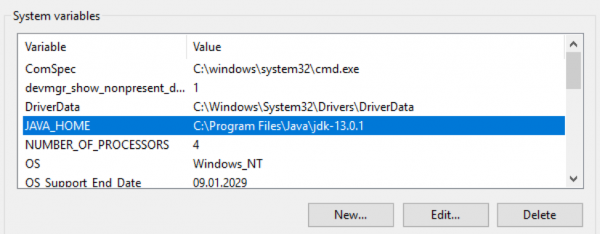
必须下载 OpenJDK 软件包并将其解压到指定目录。然后,必须将此目录的路径添加到操作系统的 $env:Path 和 $env:JAVA_HOME 环境变量中。 Windows:
我们来检查一下 Java 版本:
PS C:> java -version
openjdk version "13.0.1" 2019-10-15
OpenJDK Runtime Environment (build 13.0.1+9)
OpenJDK 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)
安装和配置 Logstash 包
使用 Logstash 发行版下载存档文件 。 存档必须解压到磁盘根目录。 解压到文件夹 C:Program Files 不值得,Logstash 将拒绝正常启动。 然后你需要输入到文件中 jvm.options 负责为 Java 进程分配 RAM 的修复。 我建议指定服务器 RAM 的一半。 如果板上有 16 GB RAM,则默认键为:
-Xms1g
-Xmx1g
必须替换为:
-Xms8g
-Xmx8g
另外,建议注释掉该行 -XX:+UseConcMarkSweepGC. 更多关于它 。 下一步是在logstash.conf 文件中创建默认配置:
input {
stdin{}
}
filter {
}
output {
stdout {
codec => "rubydebug"
}
}
通过此配置,Logstash 从控制台读取数据,将其通过空过滤器,然后将其输出回控制台。 使用此配置将测试 Logstash 的功能。 为此,让我们以交互模式运行它:
PS C:...bin> .logstash.bat -f .logstash.conf
...
[2019-12-19T11:15:27,769][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2019-12-19T11:15:27,847][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-12-19T11:15:28,113][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Logstash 在端口 9600 上成功启动。
安装的最后一步:将 Logstash 作为服务运行 Windows例如,可以使用以下软件包来实现这一点 :
PS C:...bin> .nssm.exe install logstash
Service "logstash" installed successfully!
容错
持久队列机制保证了源服务器传输日志的安全性。
它是如何工作
日志处理过程中队列的布局是:输入→队列→过滤器+输出。
输入插件从日志源接收数据,将其写入队列,并向源发送数据已收到的确认。
来自队列的消息由 Logstash 处理,并通过过滤器和输出插件。 当从输出中收到日志已发送的确认时,Logstash 将从队列中删除已处理的日志。 如果 Logstash 停止,所有未处理的消息和未收到确认的消息都会保留在队列中,Logstash 将在下次启动时继续处理它们。
调整
可通过文件中的键进行调整 C:Logstashconfiglogstash.yml:
queue.type:(可能的值-persistedиmemory (default)).path.queue: (队列文件所在文件夹的路径,默认存储在 C:Logstashqueue 中)。queue.page_capacity:(最大队列页面大小,默认值为 64mb)。queue.drain:(true/false - 启用/禁用在关闭Logstash之前停止队列处理。我不建议启用它,因为这会直接影响服务器关闭的速度)。queue.max_events:(队列中的最大事件数,默认为 0(无限制))。queue.max_bytes:(最大队列大小以字节为单位,默认 - 1024mb (1gb))。
如果配置了 queue.max_events и queue.max_bytes,那么当达到任何这些设置的值时,消息将停止被接受到队列中。 了解有关持久队列的更多信息 .
Logstash.yml 中负责设置队列的部分的示例:
queue.type: persisted
queue.max_bytes: 10gb
调整
Logstash 配置通常由三部分组成,负责处理传入日志的不同阶段:接收(输入部分)、解析(过滤部分)和发送到 Elastic(输出部分)。 下面我们将仔细研究它们。
输入
我们从 filebeat 代理接收带有原始日志的传入流。 我们在输入部分指出的就是这个插件:
input {
beats {
port => 5044
}
}
完成此配置后,Logstash开始监听5044端口,当接收到日志时,根据filter部分的设置进行处理。 如有必要,您可以将用于从 filebit 接收日志的通道包装在 SSL 中。 阅读有关 Beats 插件设置的更多信息 .
筛选
Exchange 生成的需要处理的所有文本日志均采用 csv 格式,其字段在日志文件本身中进行了描述。 为了解析 csv 记录,Logstash 为我们提供了三个插件: 、csv 和 grok。 第一个是最 ,但只处理解析最简单的日志。
例如,它会将以下记录拆分为两条(由于字段中存在逗号),这就是日志将被错误解析的原因:
…,"MDB:GUID1, Mailbox:GUID2, Event:526545791, MessageClass:IPM.Note, CreationTime:2020-05-15T12:01:56.457Z, ClientType:MOMT, SubmissionAssistant:MailboxTransportSubmissionEmailAssistant",…
解析日志时可以使用,例如IIS。 在这种情况下,过滤器部分可能如下所示:
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
}
}
}
Logstash 配置允许您使用 ,所以我们只能将带有 filebeat 标签的日志发送到 dissect 插件 IIS。 在插件内部我们将字段值与其名称相匹配,删除原始字段 message,其中包含日志中的条目,我们可以添加一个自定义字段,例如,其中包含我们从中收集日志的应用程序的名称。
在跟踪日志的情况下,最好使用csv插件;它可以正确处理复杂的字段:
filter {
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
}
在插件内部我们将字段值与其名称相匹配,删除原始字段 message (还有字段 tenant-id и schema-version),其中包含日志中的条目,我们可以添加一个自定义字段,例如,其中包含我们从中收集日志的应用程序的名称。
在过滤阶段的出口,我们将收到第一近似值的文档,准备在 Kibana 中可视化。 我们将缺少以下内容:
- 数字字段将被识别为文本,这会阻止对其进行操作。 即,字段
time-takenIIS日志以及字段recipient-countиtotal-bites日志跟踪。 - 标准文档时间戳将包含处理日志的时间,而不是在服务器端写入日志的时间。
- 领域
recipient-address看起来就像一个建筑工地,无法进行分析以计算信件收件人的数量。
是时候为日志处理过程添加一点魔法了。
转换数字字段
解剖插件有一个选项 convert_datatype,可用于将文本字段转换为数字格式。 例如,像这样:
dissect {
…
convert_datatype => { "time-taken" => "int" }
…
}
值得记住的是,此方法仅适用于字段肯定包含字符串的情况。 该选项不处理字段中的 Null 值并引发异常。
对于跟踪日志,最好不要使用类似的转换方法,因为字段 recipient-count и total-bites 可能为空。 要转换这些字段,最好使用插件 :
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
}
将recipient_address拆分为单独的收件人
这个问题也可以使用 mutate 插件来解决:
mutate {
split => ["recipient_address", ";"]
}
更改时间戳
在跟踪日志的情况下,这个问题很容易通过插件解决 ,这将帮助您在现场写作 timestamp 现场所需格式的日期和时间 date-time:
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
对于 IIS 日志,我们需要合并现场数据 date и time 使用 mutate 插件,注册我们需要的时区并将此时间戳记在 timestamp 使用日期插件:
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
输出
输出部分用于将处理后的日志发送到日志接收器。 如果直接发送到 Elastic,则使用插件 ,指定发送生成文档的服务器地址和索引名称模板:
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
最终配置
最终配置将如下所示:
input {
beats {
port => 5044
}
}
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
convert_datatype => { "time-taken" => "int" }
}
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
}
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
split => ["recipient_address", ";"]
}
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
相关链接:
来源: habr.com
