


3. 使用全局变量时的结构选项
有序树之类的结构有多种特殊情况。让我们考虑一下在使用全局变量时具有实际意义的那些特殊情况。
3.1 特殊情况 1. 只有一个节点且没有分支
 全局变量不仅可以像数组一样使用,还可以像普通变量一样使用。例如,用作计数器:
全局变量不仅可以像数组一样使用,还可以像普通变量一样使用。例如,用作计数器:
Set ^counter = 0 ; установка счётчика
Set id=$Increment(^counter) ; атомарное инкрементирование此外,全局变量除了自身值之外,还可以有分支。两者并不互相排斥。
3.2 特殊情况 2:一个顶点和多个分支
总的来说,这是一个经典的键值数据库。如果我们把一个包含多个值的元组作为值存储,就会得到一个非常普通的、带有主键的表。
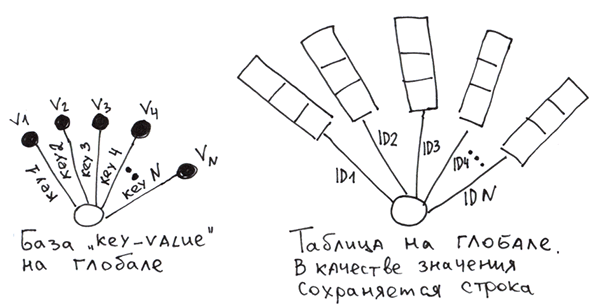
要使用全局变量实现表格,我们需要根据列值自行生成行,然后使用主键将它们保存到全局变量中。为了在读取时能够将行拆分回列,我们可以使用:
- 分隔符。
Set ^t(id1) = "col11/col21/col31" Set ^t(id2) = "col12/col22/col32" - 一种严格的模式,其中每个字段占用预定数量的字节。就像关系型数据库一样。
- 特殊函数 $LB(在 Cache 中可用),它可以根据值创建字符串。
Set ^t(id1) = $LB("col11", "col21", "col31") Set ^t(id2) = $LB("col12", "col22", "col32")
有趣的是,使用全局变量很容易实现类似于关系数据库中二级索引的功能。我们称这种结构为索引全局变量。索引全局变量是一个辅助树,用于快速搜索不属于主全局变量主键的字段。填充和使用它需要额外的代码。
让我们在第一列上创建一个全局索引。
Set ^i("col11", id1) = 1
Set ^i("col12", id2) = 1现在,为了快速查找第一列的信息,我们需要查看全局信息。 ^i 并找到与第一列所需值对应的主键(id)。
插入值时,我们可以立即为所需字段创建值和索引全局变量。为了保证可靠性,我们将所有操作都封装在一个事务中。
TSTART
Set ^t(id1) = $LB("col11", "col21", "col31")
Set ^i("col11", id1) = 1
TCOMMIT关于如何在 M 上执行此操作的详细信息 , .
如果插入/更新/删除行的函数是用 COS/M 编写并编译的,那么这类表的运行速度将与传统数据库一样快(甚至更快)。我通过对单个两列表进行批量 INSERT 和 SELECT 测试验证了这一说法,包括使用 TSTART 和 TCOMMIT 命令(事务)。
我还没有测试过并发访问和并行事务等更复杂的场景。
不使用事务时,一百万个值的插入速率为每秒 778,361 次插入。
3亿个值 - 每秒插入422,141次。
使用事务处理,在 5000 万次插入操作中,吞吐量为每秒 572,082 次插入。所有操作均由编译后的 M 代码执行。
硬盘是普通硬盘,不是固态硬盘。RAID 5 阵列,支持回写功能。处理器是 Phenom II 1100T。
要在 SQL 数据库上执行类似的测试,需要编写一个循环执行插入操作的存储过程。在测试 MySQL 5.5(InnoDB 存储)时,这种方法每秒最多只能执行 11K 次插入操作。
是的,使用全局变量实现表比在关系数据库中要复杂得多。因此,使用全局变量的工业数据库通常会提供 SQL 访问,以简化表格数据的操作。
 一般来说,如果数据模式不会经常改变,插入速度不是关键因素,并且整个数据库可以很容易地表示为规范化的表,那么使用 SQL 会更容易,因为它提供了更高层次的抽象。
一般来说,如果数据模式不会经常改变,插入速度不是关键因素,并且整个数据库可以很容易地表示为规范化的表,那么使用 SQL 会更容易,因为它提供了更高层次的抽象。
 在这个具体案例中,我想表明的是 全局变量可以作为构造函数来创建其他数据库。就像汇编语言一样,你也可以用它编写其他语言的代码。以下是一些使用全局变量创建类似功能的示例。
在这个具体案例中,我想表明的是 全局变量可以作为构造函数来创建其他数据库。就像汇编语言一样,你也可以用它编写其他语言的代码。以下是一些使用全局变量创建类似功能的示例。
如果您需要以最小的努力创建某种非标准数据库,那么值得考虑使用全局变量。
3.3 特殊情况 3:一棵两层树,第二层的每个节点都有固定数量的分支。
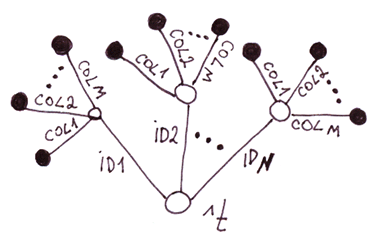 你可能已经猜到了:这是使用全局变量实现表格的另一种方法。让我们将这种实现方式与之前的实现方式进行比较。
你可能已经猜到了:这是使用全局变量实现表格的另一种方法。让我们将这种实现方式与之前的实现方式进行比较。
两层树上的表与一层树上的表。
缺点
优点
- 插入速度较慢,因为需要将节点数设置为等于列数。
- 磁盘空间占用更高。因为带有列名的全局索引(可以理解为数组索引)会占用磁盘空间,并且每一行都会重复创建。
- 直接访问单个列值速度更快,因为无需解析字符串。根据我的测试,两列数据时速度提升了 11,5%,列数越多,速度提升幅度越大。
- 更改数据模式更容易。
- 代码更直观易懂。
结论: 这是一种需要慢慢适应的方式。由于速度是全局变量的主要优势之一,因此使用这种实现方式意义不大,因为它可能不会比关系数据库中的表更快。
3.4 一般情况。树和有序树
任何可以用树状结构表示的数据结构都非常适合与全局变量一起使用。
3.4.1 具有子对象的对象
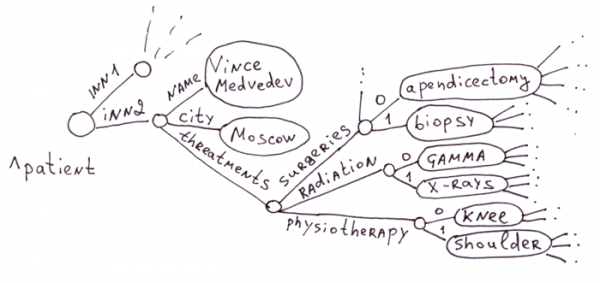
这是全局变量的传统应用领域。在医疗领域,疾病、药物、症状和治疗方法种类繁多。为每个患者创建一个包含一百万个字段的表是不切实际的,尤其考虑到其中 99% 的字段都是空的。
想象一下一个 SQL 数据库,其中包含以下表:“患者”表(约 10 万个字段)、“药物”表(10 万个字段)、“治疗”表(10 万个字段)、“并发症”表(10 万个字段),等等。或者,你也可以创建一个包含数千个表的数据库,每个表分别对应一种特定类型的患者(它们之间可以重叠!)、治疗方法、药物,以及数千个用于描述这些表之间关系的表。
全局变量非常适合医学领域,因为它们可以创建每个患者的病史、各种疗法和药物效果的精确树状描述,而不会像关系数据库那样在空列上浪费磁盘空间。
 全局变量便于创建包含人员数据的数据库。在需要尽可能多地收集和系统整理客户各种信息的情况下,这种方法就显得尤为重要。这在医疗、银行、市场营销、档案管理等领域都有着广泛的需求。
全局变量便于创建包含人员数据的数据库。在需要尽可能多地收集和系统整理客户各种信息的情况下,这种方法就显得尤为重要。这在医疗、银行、市场营销、档案管理等领域都有着广泛的需求。
.
当然,在 SQL 中,您也可以仅使用几个表来模拟树状结构(, ,,,,,,,,,但这要复杂得多,而且速度也会慢很多。本质上,你需要编写一个操作表的全局变量,并将所有表操作隐藏在一个抽象层之下。用更高级的技术(SQL)来模拟更底层的技术(全局变量)是错误的,也不切实际。
众所周知,更改大型表的数据模式(ALTER TABLE)会耗费大量时间。例如,MySQL 执行 ALTER TABLE ADD|DROP COLUMN 时,会将旧表中的数据完整复制到新表中(我测试了 MyISAM 和 InnoDB 引擎)。这可能会导致拥有数十亿条记录的生产数据库冻结数天甚至数周。
 如果使用全局变量,改变数据结构不会给我们带来任何成本。 我们可以随时向层级结构中任何级别的任何对象添加所需的任何新属性。涉及分支重命名的更改可以在运行中的数据库后台执行。
如果使用全局变量,改变数据结构不会给我们带来任何成本。 我们可以随时向层级结构中任何级别的任何对象添加所需的任何新属性。涉及分支重命名的更改可以在运行中的数据库后台执行。
因此,当需要存储具有大量可选属性的对象时,全局变量是一个绝佳的选择。
此外,我还要提醒您,访问任何属性都是瞬间完成的,因为全局中的所有路径都是 B 树。
全局数据库通常是一种面向文档的数据库,能够存储层级信息。因此,面向文档的数据库可以在医疗记录存储领域与全局数据库展开竞争。 但它仍然不太一样。以 MongoDB 为例进行比较。 在这个区域 她输给全球选手的原因如下:
- 文件大小。 存储单元是 JSON 格式(更准确地说是 BSON)的文本,最大大小约为 16 MB。此限制旨在防止在 JSON 数据库中存储大型 JSON 文档并通过字段访问时,导致解析速度变慢。该文档应包含所有患者信息。我们都知道患者记录有多大。16 MB 的最大记录大小直接排除了包含 MRI 文件、X 光片和其他检查结果的患者记录。全球数据库的单个分支可能包含 GB 甚至 TB 级的信息。原则上,我们可以就此打住,但我将继续讲解。
- 意识状态/变化/移除患者卡片中新属性的时间。 这样的数据库必须将整个映射表读入内存(数据量非常大!),解析 BSON 数据,插入/修改/删除新节点,更新索引,将其打包成 BSON 数据,然后保存到磁盘。而全局变量则只需要访问和操作特定的属性。
- 快速访问各个房产信息。 如果文档包含许多属性且具有多级结构,访问单个属性会更快,因为全局变量中的每个路径都是一棵 B 树。然而,在 BSON 中,您必须线性解析文档才能找到所需的属性。
3.3.2 关联数组
关联数组(即使是嵌套数组)也能很好地与全局变量配合使用。例如,PHP 中这样的数组会在 3.3.1 节的第一张图中显示。
$a = array(
"name" => "Vince Medvedev",
"city" => "Moscow",
"threatments" => array(
"surgeries" => array("apedicectomy", "biopsy"),
"radiation" => array("gamma", "x-rays"),
"physiotherapy" => array("knee", "shoulder")
)
);3.3.3 层级文档:XML、JSON
它们也很容易存储在全局变量中。为了便于存储,可以采用多种方式进行排列。
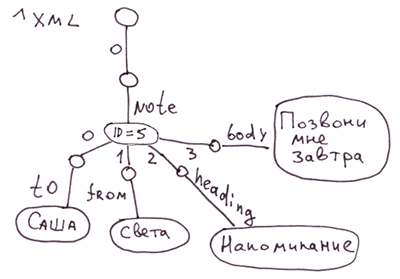
XML
将 XML 分解为全局变量的最简单方法是将标签属性存储在节点中。如果需要快速访问标签属性,我们可以将它们移到单独的分支中。
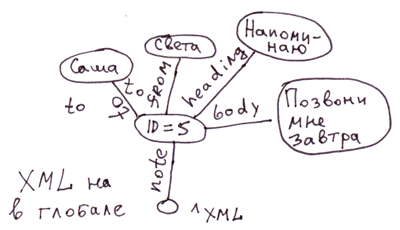
<note id=5>
<to>Вася</to>
<from>Света</from>
<heading>Напоминание</heading>
<body>Позвони мне завтра!</body>
</note>在 COS 系统中,这将对应于以下代码:
Set ^xml("note")="id=5"
Set ^xml("note","to")="Саша"
Set ^xml("note","from")="Света"
Set ^xml("note","heading")="Напоминание"
Set ^xml("note","body")="Позвони мне завтра!"备注: 对于 XML、JSON 和关联数组,您可以采用多种不同的方式显示全局变量。在本例中,我们没有反映注释标签中嵌套标签的顺序。在全局变量中 ^xml 嵌套标签将按字母顺序显示。要严格按照字母顺序显示,您可以使用例如以下显示方式:
JSON。
第 3.3.1 节中的第一张图片显示了该 JSON 文档的镜像:
var document = {
"name": "Vince Medvedev",
"city": "Moscow",
"threatments": {
"surgeries": ["apedicectomy", "biopsy"],
"radiation": ["gamma", "x-rays"],
"physiotherapy": ["knee", "shoulder"]
},
};3.3.4 通过层级关系连接的相同结构
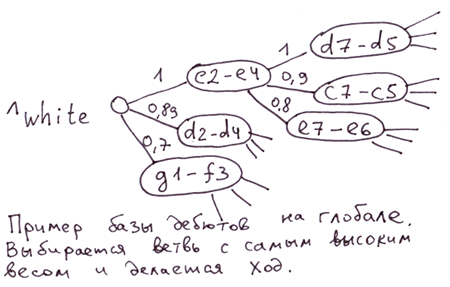
例如:销售办公室结构、多层次营销结构中的人员配置、国际象棋开局数据库。
首发基地。 您可以将移动的强度得分用作全局节点索引值。然后,要选择最强的移动,只需选择权重最高的节点分支即可。在全局范围内,每一层的所有节点分支都会按移动强度排序。
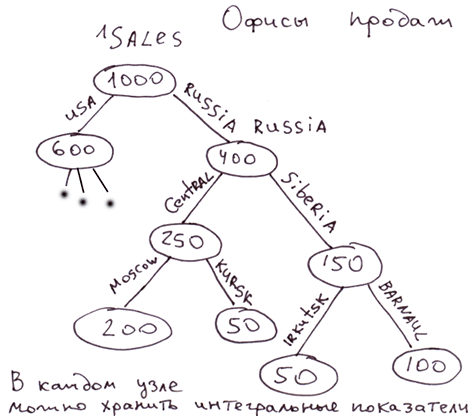
销售办事处的结构,多层次营销(MLM)中的人员结构。 节点可以存储反映整个子树特征的缓存值。例如,某个子树的销售额。我们可以随时检索反映任何分支业绩的数据。
4. 什么时候使用全局变量最有利?
第一列显示了使用全局变量可以显著提高速度的情况,第二列显示了使用全局变量可以简化开发或数据模型的情况。
速度
数据处理/呈现的便捷性
- 插入 [每级自动排序],[按主键索引]
- 删除子树
- 具有大量嵌套属性且需要单独访问的对象
- 具有层级结构的节点,可以绕过任何子分支,即使是不存在的子分支。
- 子树的深度优先遍历
- 具有大量可选[和/或嵌套]属性/实体的对象/实体
- 无模式数据。新属性可能频繁出现,而旧属性可能频繁消失。
- 需要创建自定义数据库。
- 路径基和决策树。当用树状结构表示路径比较方便时。
- 不使用递归移除层级结构
延期 .
免责声明: 本文以及我对其的评论仅代表我的观点,与 InterSystems Corporation 的官方立场无关。
来源: habr.com
