

大家好! 我叫 Sasha,是 LoyaltyLab 的首席技术官兼联合创始人。 两年前,我和我的朋友们,像所有贫困学生一样,晚上去我们家附近最近的商店买啤酒。 我们非常沮丧的是,零售商知道我们会来喝啤酒,却没有提供薯条或饼干的折扣,尽管这是很合乎逻辑的! 我们不明白为什么会发生这种情况,并决定创办自己的公司。 好吧,作为奖励,每周五给自己购买同样筹码的折扣。

这一切都到了我在以下网址展示产品技术方面的材料的地步: 。 我们很高兴与社区分享我们的工作,因此我以文章的形式发布我的报告。
介绍
与旅程开始时的其他人一样,我们首先概述了推荐系统的制作方式。 最流行的架构是以下类型:

它由两部分组成:
- 使用简单而快速的模型(通常是协作模型)对候选者进行采样以进行推荐。
- 考虑到数据中所有可能的特征,使用更复杂和更慢的内容模型对候选者进行排名。
下面我将使用以下术语:
- 候选人/推荐候选人 - 可能包含在生产推荐中的用户-产品对。
- 候选提取/提取器/候选提取方法 ——从可用数据中提取“推荐候选人”的过程或方法。
第一步通常涉及使用协作过滤的不同变体。 最受欢迎 - 。 令人惊讶的是,大多数关于推荐系统的文章只揭示了第一阶段协作模型的各种改进,而没有人过多谈论其他采样方法。 对于我们来说,仅使用协作模型和对其进行各种优化的方法并不能达到我们预期的质量,因此我们专门针对这一部分进行了研究。 在文章的最后,我将展示我们能够在多大程度上改善 ALS,这是我们的基线。
在我继续描述我们的方法之前,需要注意的是,在实时推荐中,当我们需要考虑 30 分钟前发生的数据时,实际上没有多少方法可以在所需的时间内发挥作用。 但是,在我们的例子中,我们每天收集的建议不得超过一次,并且在大多数情况下是每周一次,这使我们有机会使用复杂的模型并成倍提高质量。
让我们以 ALS 在提取候选者任务中仅显示的指标作为基线。 我们监控的关键指标是:
- 精确度——从样本中正确选择候选人的比例。
- 召回率是指在目标区间内实际出现过的候选数中所占的比例。
- F1-score - 根据前两点计算的 F-measure。
我们还将在使用附加内容特征训练梯度提升后查看最终模型的指标。 这里还有 3 个主要指标:
- precision@5 - 每个买家的前 5 名产品的平均百分比。
- response-rate@5 - 客户从访问商店到购买至少一项个人优惠(一项优惠中包含 5 种产品)的转化。
- 每个用户的 avg roc-auc - 平均值 对于每个买家。
值得注意的是,所有这些指标都是根据 ,即前k周进行训练,第k+1周作为测试数据。 因此,季节性起伏对模型质量的解释影响很小。 此外,在所有图表上,横坐标轴将指示交叉验证中的周数,纵坐标轴将指示指定指标的值。 所有图表均基于一位客户的交易数据,因此彼此之间的比较是正确的。
在开始描述我们的方法之前,我们首先看一下基线,它是经过 ALS 训练的模型。
候选检索指标:
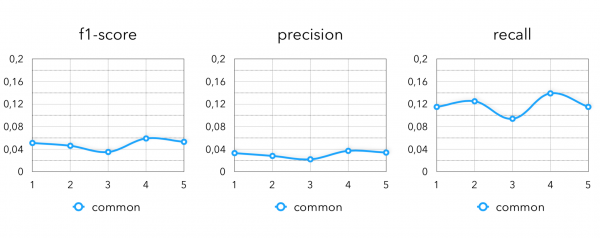
最终指标:
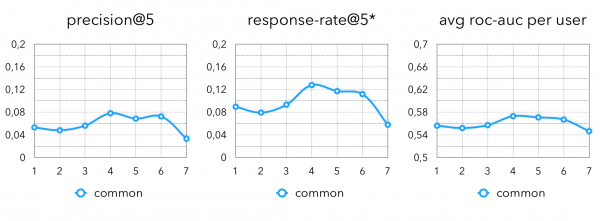
我将算法的所有实现视为某种业务假设。 因此,非常粗略地说,任何协作模型都可以被视为“人们倾向于购买与他们相似的人购买的东西”的假设。 正如我已经说过的,我们并没有将自己局限于这样的语义,以下是一些适用于线下零售数据的假设:
- 我之前已经买过。
- 和我之前买的差不多。
- 很久以前的购买时期。
- 按类别/品牌受欢迎。
- 每周交替购买不同的商品(马尔可夫链)。
- 向买家提供类似的产品,根据特性构建不同的模型(Word2Vec、DSSM等)。
你之前买了什么?
最明显的启发式方法在杂货零售中非常有效。 这里我们取会员卡持卡人最近K天内(通常是1-3周),或者一年前K天内购买的所有商品。 仅应用此方法,我们获得以下指标:
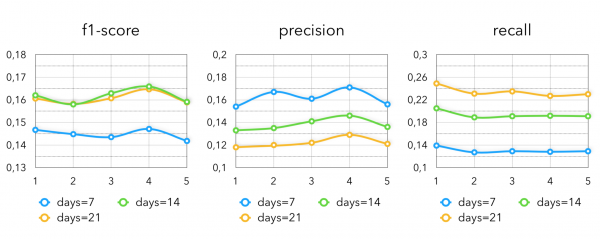
很明显,我们花费的时间越长,我们的召回率就越高,而精确率就越低,反之亦然。 平均而言,“过去两周”为客户带来了更好的结果。
和我之前买的差不多
对于杂货零售来说,“我以前买过的东西”效果很好,这并不奇怪,但仅从用户已经购买过的东西中提取候选者并不是很酷,因为它不太可能用一些新产品让买家感到惊讶。 因此,我们建议使用相同的协作模型稍微改进这种启发式。 根据我们在 ALS 训练期间收到的向量,我们可以获得与用户已购买的产品类似的产品。 这个想法与观看视频内容服务中的“相似视频”非常相似,但由于我们不知道用户在特定时刻正在吃/买什么,所以我们只能寻找与他已经购买过的东西相似的东西,尤其是因为我们已经知道它的效果如何。 将此方法应用于过去两周的用户交易,我们获得以下指标:
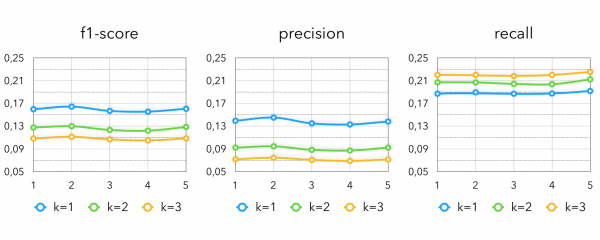
这是 k — 买家在过去 14 天内购买的每件产品检索到的类似产品的数量。
这种方法对我们的客户尤其有效,对他们来说,不要推荐用户购买历史记录中已有的任何内容至关重要。
后期购买期
正如我们已经发现的,由于购买商品的频率很高,第一种方法很适合我们的特定需求。 但是洗衣粉/洗发水等商品呢? 也就是说,这些产品不太可能每周或两周都需要,并且以前的方法无法提取。 这就引出了以下想法——建议对购买该产品次数较多的顾客平均计算该产品的购买时长 k 一次。 然后提取买家最有可能已经用完的东西。 可以亲眼检查计算出的货物期限是否充足:
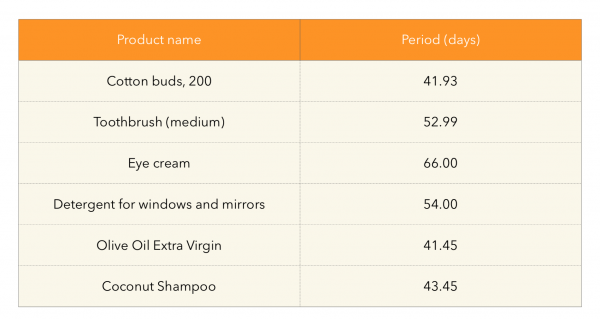
然后我们将查看产品周期的结束是否落在建议投入生产的时间间隔内,并对发生的情况进行采样。 该方法可以这样说明:
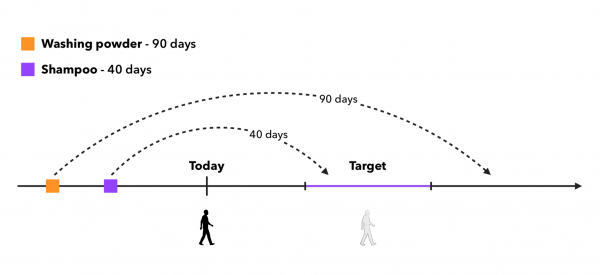
这里我们有两种可以考虑的主要情况:
- 是否有必要对购买该产品少于K次的客户进行抽样?
- 如果产品的周期结束时间早于目标间隔开始时间,是否有必要对产品进行采样?
下图显示了该方法在不同超参数下取得的结果:
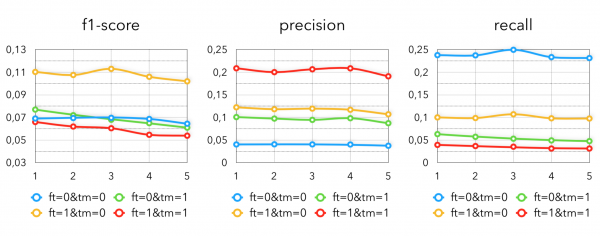
ft — 仅选取购买该产品至少 K 次(此处 K=5)次的客户
tm — 只选取属于目标区间内的候选人
他能够做到这一点并不奇怪 (0,0) 最大 记得 和最小的 精确,因为在这种情况下,检索到的候选者最多。 然而,当我们不为购买特定产品少于 k 时间并提取,包括其期间结束时间早于目标间隔的货物。
按类别热门
另一个相当明显的想法是对不同类别或品牌的流行产品进行采样。 这里我们为每个买家计算 前k个 “最喜欢的”类别/品牌并从此类别/品牌中提取“流行”。 在我们的例子中,我们将根据产品的购买次数来确定“最喜欢”和“受欢迎”。 这种方法的另一个优点是它在冷启动情况下的适用性。 也就是说,对于那些购买次数很少,或者很长时间没有去过商店,或者刚刚发行会员卡的顾客。 对他们来说,库存受顾客欢迎且有历史的商品更容易、更好。 得出的指标是:
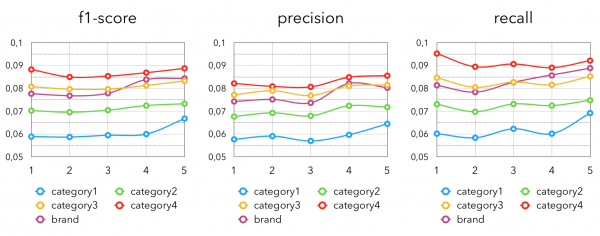
这里“类别”一词后面的数字表示类别的嵌套级别。
总体而言,更窄的类别取得更好的结果也就不足为奇了,因为它们为购物者提取了更准确的“最喜欢”的产品。
每周交替购买不同的商品
我在有关推荐系统的文章中没有看到的一个有趣的方法是一种相当简单且同时有效的马尔可夫链统计方法。 在这里,我们需要 2 周的时间,然后为每个客户构建成对的产品 [第 i 周购买]-[第 j 周购买],其中 j > i,从这里我们计算每个产品下周切换到另一个产品的概率。 也就是说,对于每对商品 产品-产品j 我们计算找到的对中它们的数量,然后除以对的数量,其中 产品 是在第一周。 为了提取候选人,我们获取买家的最后收据并提取 前k个 我们收到的转换矩阵中最有可能的下一个产品。 构造转移矩阵的过程如下:
从转移概率矩阵的真实例子中我们看到以下有趣的现象:
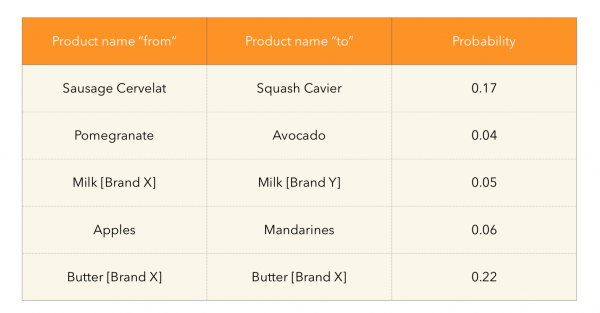
在这里,您可以注意到消费者行为中揭示的有趣依赖性:例如,柑橘类水果或牛奶品牌的爱好者可能会转向另一种品牌。 黄油等重复购买频率较高的产品也出现在这里也就不足为奇了。
马尔可夫链方法中的度量如下:
k — 从买家上次交易中为每个购买的产品检索到的产品数量。
我们可以看到,k=4 的配置显示了最好的结果。 第 4 周的峰值可以用假期前后的季节性行为来解释。
同类产品买家,根据不同车型特点打造
现在我们来到了最困难和最有趣的部分——根据客户向量和根据各种模型构建的产品来搜索最近邻居。 在我们的工作中,我们使用 3 个这样的模型:
- ALS
- Word2Vec(用于此类任务的 Item2Vec)
- DSSM
我们已经讨论过 ALS,您可以阅读有关它如何学习的内容 。 对于 Word2Vec,我们使用众所周知的模型实现 Gensim。 通过与文本类比,我们将报价定义为购买收据。 因此,在构建产品向量时,模型学习预测收据中的产品的“上下文”(收据中的其余产品)。 在电子商务数据中,最好使用买家会话而不是收据;来自 。 DSSM 解析起来更有趣。 最初,它是由微软的人编写的,作为搜索模型, 。 该模型的架构如下所示:
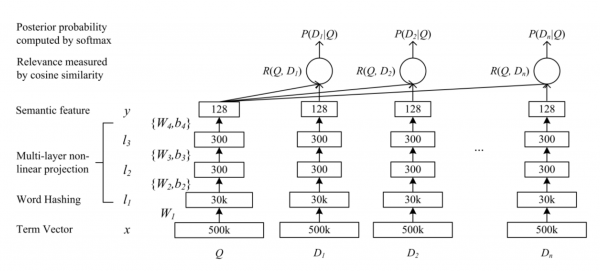
这是 Q — 查询,用户搜索查询, D[i] — 文档、互联网页面。 模型的输入分别是请求和页面的属性。 每个输入层之后都有许多完全连接的层(多层感知器)。 接下来,模型学习最小化模型最后几层获得的向量之间的余弦。
推荐任务使用完全相同的架构,只是用用户代替请求,用产品代替页面。 在我们的例子中,该架构被转换为以下内容:
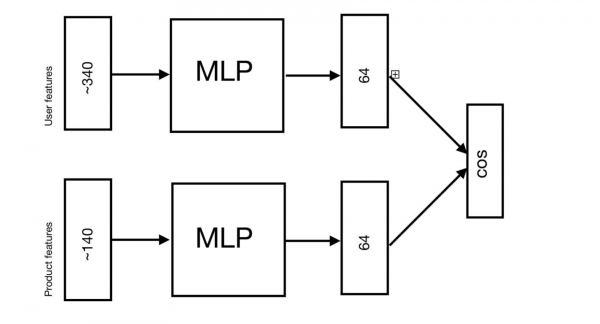
现在,为了检查结果,仍然需要涵盖最后一点 - 如果在 ALS 和 DSSM 的情况下我们明确定义了用户向量,那么在 Word2Vec 的情况下我们只有产品向量。 在这里,为了构建用户向量,我们定义了 3 种主要方法:
- 只需添加向量,然后对于余弦距离,结果表明我们只是对购买历史记录中的产品进行平均。
- 具有一定时间加权的向量求和。
- 用TF-IDF系数对货物进行称重。
在购买者向量线性加权的情况下,我们假设用户昨天购买的产品比他六个月前购买的产品对其行为的影响更大。 因此,我们以赔率 1 考虑买家前一周的情况,并以赔率 ½、⅓ 等考虑接下来发生的情况:
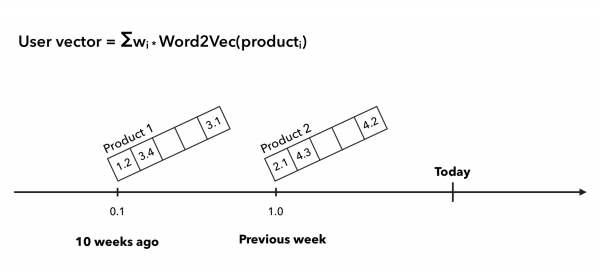
对于 TF-IDF 系数,我们与文本的 TF-IDF 完全相同,只是我们分别将买家视为文档,将支票视为报价,单词是产品。 这样,用户的向量将更多地转向稀有商品,而买家频繁和熟悉的商品不会改变太多。 该方法可以这样说明:
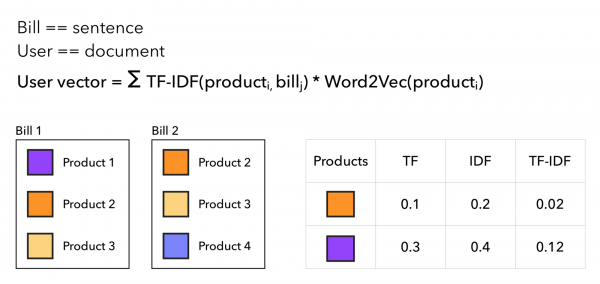
现在让我们看看指标。 ALS 结果如下所示:
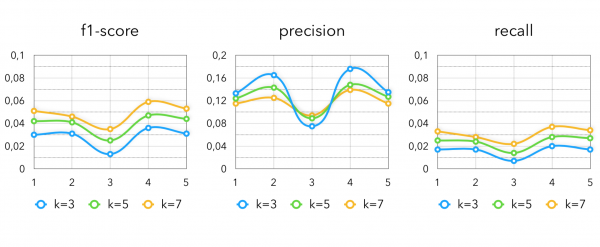
构建买家向量的不同变体的 Item2Vec 指标:
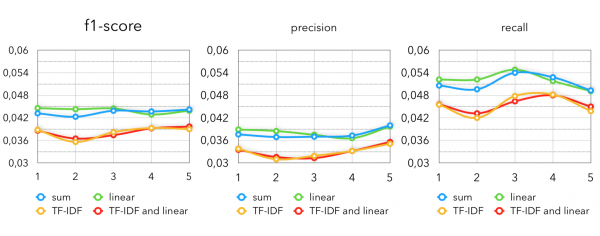
在这种情况下,使用与我们的基线完全相同的模型。 唯一的区别是我们将使用哪个 k。 为了仅使用协作模型,您必须为每个客户选取大约 50-70 个最接近的产品。
以及根据 DSSM 的指标:
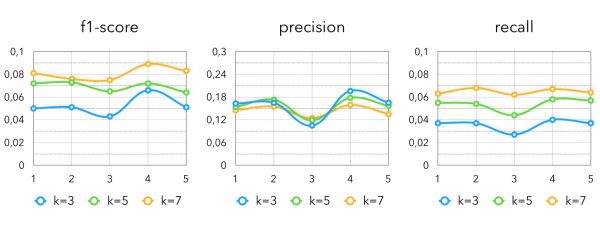
如何将所有方法结合起来?
你说很酷,但是如何使用如此大的候选提取工具集呢? 如何为您的数据选择最佳配置? 这里我们有几个问题:
- 有必要以某种方式限制每种方法中超参数的搜索空间。 当然,它到处都是离散的,但可能的点数量非常多。
- 使用具有特定超参数的特定方法的有限样本,如何为您的指标选择最佳配置?
我们还没有找到第一个问题的明确正确答案,因此我们从以下内容出发:对于每种方法,根据我们拥有的数据的一些统计数据编写超参数搜索空间限制器。 因此,知道了人们购买的平均间隔时间,我们就可以猜测在什么时间段内使用“已经购买过的东西”和“很久以前购买的时间段”方法。
在我们经历了一定数量的不同方法的变体之后,我们注意到以下几点:每个实现都会提取一定数量的候选者,并且对我们来说具有一定的关键指标值(回忆)。 我们希望根据我们允许的计算能力,获得一定数量的候选者,并具有尽可能高的指标。 在这里,问题完美地分解为背包问题。
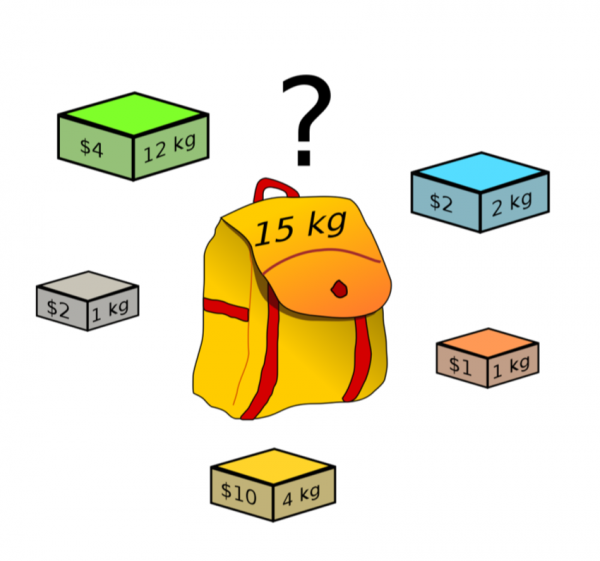
这里候选数就是元宝的重量,召回方法就是它的值。 然而,在实现该算法时还有两点需要考虑:
- 方法在检索到的候选者中可能有重叠。
- 在某些情况下,使用不同参数两次采用同一个方法是正确的,并且第一个方法的候选输出不会是第二个方法的子集。
例如,如果我们采用“我已经买过的东西”的方法以不同的间隔进行检索,那么它们的候选集将相互嵌套。 同时,出口处“周期性购买”中的不同参数并没有提供完全的交集。 因此,我们将具有不同参数的采样方法划分为多个块,以便从每个块中我们最多采取一种具有特定超参数的提取方法。 要做到这一点,你需要在背包问题的实现上稍微聪明一点,但渐进性和结果不会改变。
与简单的协作模型相比,这种智能组合使我们能够获得以下指标:
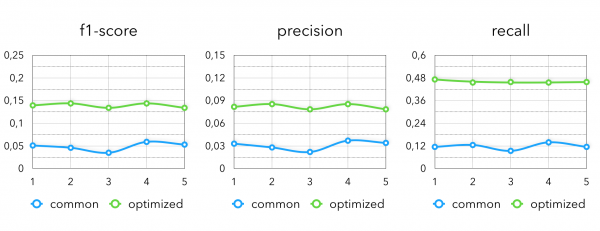
在最终的指标中我们看到下图:
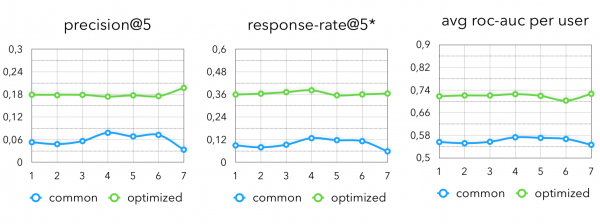
然而,在这里您可以注意到,对于对业务有用的推荐,有一个未被发现的点。 现在我们刚刚学会了如何很好地预测用户将购买什么,例如下周。 但仅仅对他已经购买的东西给予折扣并不是很酷。 但最大化期望是很酷的,例如,以下指标:
- 保证金/营业额基于个人建议。
- 平均客户检查。
- 访问频率。
因此,我们将获得的概率乘以不同的系数,并对它们重新排序,以便影响上述指标的乘积位于顶部。 对于哪种方法最好使用,没有现成的解决方案。 我们甚至直接在生产中试验这些系数。 但这里有一些有趣的技术,通常可以给我们带来最好的结果:
- 乘以产品的价格/利润。
- 乘以产品出现的平均收据。 因此货物会出现,他们通常会拿走其他东西。
- 乘以该产品买家的平均访问频率,基于该产品会促使人们更频繁地返回该产品的假设。
在对系数进行实验后,我们在生产中获得了以下指标:
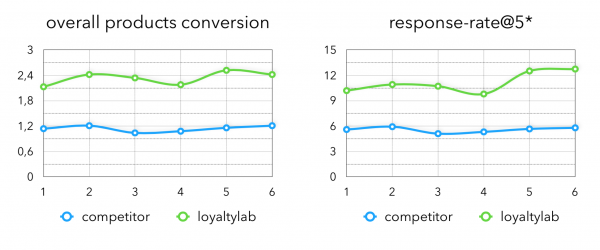
这是 整体产品转化 — 购买的产品占我们生成的推荐中所有产品的比例。
细心的读者会注意到离线和在线指标之间的显着差异。 这种行为的解释是,在训练模型时,并非可以考虑所有可推荐产品的动态过滤器。 对于我们来说,检索到的候选者中有一半可以被过滤掉是很正常的情况;这种特殊性在我们的行业中是典型的。
在收入方面,得到以下故事,很明显,在推出推荐后,测试组的收入增长强劲,现在我们的推荐收入平均增长为3-4%:
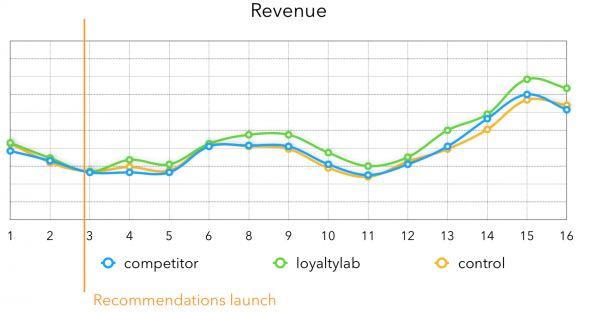
总之,我想说,如果您需要非实时推荐,那么在提取推荐候选者的实验中可以发现质量的大幅提高。 他们这一代人的大量时间使得可以结合许多好的方法,这总共将为企业带来巨大的成果。
我很乐意在评论中与任何觉得这些材料有趣的人聊天。 您可以亲自向我提问 。 我还在我的文章中分享了我对人工智能/初创公司的看法 - 欢迎 :)
来源: habr.com
