

嘿哈布尔! 我叫 Maxim Vasiliev,在 FINCH 担任分析师和项目经理。 今天我想告诉您,我们如何使用 ElasticSearch 在 15 分钟内处理 6 万个请求并优化我们一位客户网站上的每日负载。 不幸的是,我们将不得不没有名字,因为我们有保密协议,我们希望文章的内容不会受到影响。 我们走吧。
项目如何运作
在我们的后端,我们创建服务以确保我们客户的网站和移动应用程序的性能。 大致结构可以看图:
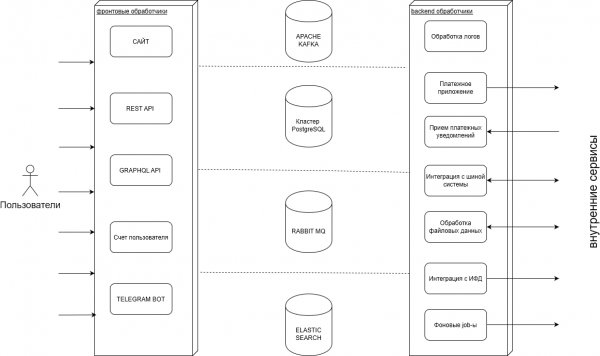
在工作过程中,我们处理大量交易:购买、支付、用户余额操作,我们为此存储大量日志,以及将这些数据导入和导出到外部系统。
当我们从客户端接收数据并将其传递给用户时,也有相反的过程。 此外,还有处理付款和奖金计划的流程。
简要背景
最初,我们使用 PostgreSQL 作为唯一的数据存储。 它对于 DBMS 的标准优势:事务的存在、开发的数据采样语言、广泛的集成工具; 结合良好的性能,满足了我们很长一段时间的需求。
我们将所有数据都存储在 Postgres 中:从交易到新闻。 但是用户数量增加了,请求数量也随之增加。
据了解,2017 年仅桌面网站的年会话数为 131 亿。2018 年为 125 亿。2019 年再次为 130 亿。再加上移动版网站和移动应用程序的 100-200 亿,你将收到大量请求。
随着项目的增长,Postgres 停止处理负载,我们没有时间 - 出现了大量不同的查询,我们无法为其创建足够数量的索引。
我们知道需要其他数据存储来满足我们的需求并减轻 PostgreSQL 的负担。 Elasticsearch 和 MongoDB 被认为是可能的选择。 后者在以下几点上失利:
- 随着索引中数据量的增长,索引速度变慢。 使用 Elastic,速度不取决于数据量。
- 没有全文搜索
所以我们为自己选择了 Elastic 并为过渡做好了准备。
过渡到 Elastic
1. 我们从销售点搜索服务开始转型。 我们的客户总共有大约 70 个销售点,这需要在网站和应用程序中进行多种类型的搜索:
- 按城市名称进行文本搜索
- 从某个点在给定半径内进行地理搜索。 例如,如果用户想查看哪些销售点离他家最近。
- 按给定的正方形搜索 - 用户在地图上绘制一个正方形,并向他显示该半径内的所有点。
- 按其他过滤器搜索。 销售点在分类上各不相同
如果我们谈论组织,那么在 Postgres 中我们有地图和新闻的数据源,而在 Elastic 中快照是从原始数据中获取的。 事实上,最初 Postgres 无法处理所有标准的搜索。 不仅有很多索引,它们还可能重叠,所以 Postgres 调度器迷路了,不知道该使用哪个索引。
2. 接下来是新闻版块。 网站上每天都会出现出版物,这样用户就不会迷失在信息流中,必须在发布前对数据进行分类。 这就是搜索的用途:您可以通过文本匹配来搜索网站,同时连接额外的过滤器,因为它们也是通过 Elastic 制作的。
3.然后我们把事务处理搬过来了。 用户可以在网站上购买某种产品并参加抽奖。 此类购买后,我们会处理大量数据,尤其是在周末和节假日。 相比之下,如果平时的购买量在1,5万到2万之间,那么节假日这个数字就可以达到53万。
同时,必须在尽可能短的时间内处理数据——用户不喜欢等待几天的结果。 无法通过 Postgres 实现这样的截止日期——我们经常收到锁,当我们处理所有请求时,用户无法检查他们是否收到奖品。 这对业务来说不是很愉快,所以我们将处理转移到 Elasticsearch。
周期性
现在更新是基于事件配置的,根据以下条件:
- 销售点。 一旦我们从外部来源接收到数据,我们就会立即开始更新。
- 消息。 一旦在网站上编辑了任何新闻,它就会自动发送到 Elastic。
这里再次值得一提的是 Elastic 的优势。 在 Postgres 中,发送请求时,必须等到它老老实实处理完所有记录。 您可以将 10 条记录发送到 Elastic 并立即开始工作,而无需等待记录分布到所有分片。 当然,有些 Shard 或者 Replica 可能不会马上看到数据,但是很快就会有一切。
整合方法
有两种方法可以与 Elastic 集成:
- 通过基于 TCP 的本机客户端。 本机驱动程序正在逐渐消失:不再支持它,它的语法非常不方便。 因此,我们实际上不使用它并试图完全放弃它。
- 通过可以同时使用 JSON 请求和 Lucene 语法的 HTTP 接口。 最后一个是使用 Elastic 的文本引擎。 在此版本中,我们能够通过 HTTP 对 JSON 请求进行批处理。 这是我们尝试使用的选项。
多亏了 HTTP 接口,我们可以使用提供 HTTP 客户端异步实现的库。 我们可以利用 Batch 和异步 API,从而获得高性能,这在大促销的日子里帮助很大(更多内容见下文)
一些数字进行比较:
- 在不分组的情况下在 20 个线程中保存 Postgres 赏金用户:460713 秒内 42 条记录
- 10 个线程的弹性 + 反应式客户端 + 1000 个元素的批处理:596749 秒内 11 条记录
- 10 个线程的弹性 + 反应式客户端 + 1000 个元素的批处理: 23801684 分钟内 4 个条目
现在我们已经编写了一个 HTTP 请求管理器,它将 JSON 构建为批处理/非批处理,并通过任何 HTTP 客户端发送它,而不管库是什么。 您还可以选择同步或异步发送请求。
在一些集成中,我们仍然使用官方传输客户端,但这只是下一次重构的事情。 本例采用基于Spring WebClient构建的自定义客户端进行处理。
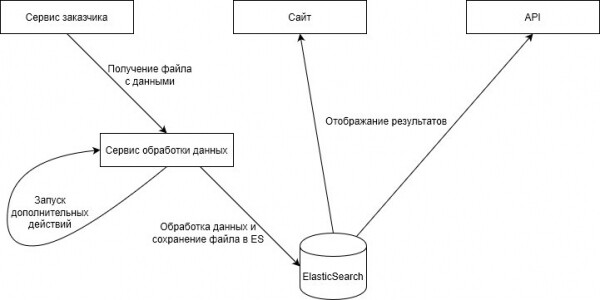
大促销
每年一次,该项目都会为用户举办一次大型促销活动——这也是同一个 Highload,因为此时我们同时与数千万用户合作。
通常,高峰负载发生在假期期间,但这次促销是完全不同的水平。 前年,促销当天,我们卖出了27件商品。 数据处理耗时超过半小时,给用户带来不便。 用户因参与而获得奖励,但很明显,这一过程需要加快。
2019 年初,我们决定需要 ElasticSearch。 整整一年,我们组织了在 Elastic 中处理接收到的数据,并在移动应用程序和网站的 API 中发布这些数据。 结果,在第二年的竞选期间,我们处理了 15 分钟内有 131 个条目。
由于我们有很多人想要购买商品并参与促销活动中的奖品,这是一个临时措施。 现在我们正在向 Elastic 发送最新信息,但未来我们计划将过去几个月的存档信息传输到 Postgres 作为永久存储。 为了不堵塞Elastic index,这也有其局限性。
结论/结论
目前,我们已经将我们想要的所有服务转移到 Elastic 并暂时暂停。 现在我们在 Postgres 的主要持久存储之上在 Elastic 中构建一个索引,它接管了用户负载。
将来,如果我们了解数据请求变得过于多样化并且搜索无限数量的列,我们计划转移服务。 这不再是 Postgres 的任务。
如果我们在功能上需要全文搜索,或者如果我们有很多不同的搜索条件,那么我们已经知道这需要转化为 Elastic。
⌘⌘⌘
谢谢阅读。 如果您的公司也使用 ElasticSearch 并且有自己的实施案例,请告诉我们。 知道别人怎么样会很有趣🙂
来源: habr.com
