

系统越复杂,各种警报就越多。 并且需要对这些相同的警报做出反应,汇总它们并可视化它们。 我认为这种情况对很多人来说都很熟悉,甚至到了紧张的程度。
将要讨论的解决方案并不是最出乎意料的,但搜索并没有返回有关该主题的完整文章。
因此,我决定分享 FunCorp 的经验,并讨论值班流程的结构、谁打电话、为什么以及如何看待这一切。

什么是 PagerDuty?
因此,为了解决所有这些问题,我们开始寻找一种方便的工具。 经过一番搜索,我们选择了 PagerDuty。 在我们看来,PD 是一个相当完整和简洁的解决方案,具有大量的集成和设置。 她喜欢什么?
简而言之,PagerDuty是一个事件处理平台,可以通过各种集成处理传入的事件,设置值班指令,然后根据事件的级别向值班工程师发出警报(高级别-呼叫,低级别-来自应用程序/短信的推送)。
值班人员是谁?
这可能是开始设置 PD 的第一个地方。
与其他公司一样,FunCorp 也设有值班人员的荣誉职位。 它每天在工程师之间传送一次。 对来自 PagerDuty 的警报有所谓的第一行和第二行响应。 假设一个高优先级警报到达,如果从第一条线路呼叫值班人员 10 分钟后没有反应(即,没有转入确认或已解决状态),则呼叫转到第二条线路值班工程师。 这是通过升级策略在 PagerDuty 本身中配置的。
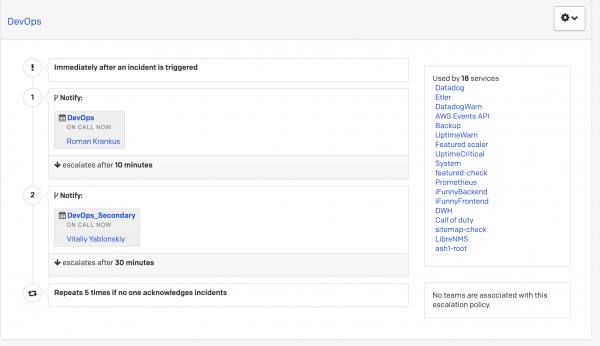
如果第二值班人员没有响应,通知将返回到 主要的 给值班人员。
因此,任何传入的高优先级警报都不能保持未处理状态。
现在让我们看看事件可能来自哪里。
我们使用什么集成?
PD 从不同的服务部门收到许多不同的事件。 我们目前拥有大约 25 个此类服务,为了处理它们,我们使用了一些现成的集成。
- 普罗米修斯
主要的指标收集系统是Prometheus。 Habré 上已经写了很多关于它的文章,我只想说我们有几个针对不同环境的指标:一个从虚拟机和 Docker 收集指标,另一个从 Amazon 服务收集指标,第三个从硬件机器收集指标。 Telegraf 主要用作指标导出器。
- 邮箱
我认为,从标题中也可以清楚地看出一切。 此集成用于从 cron 执行的某些脚本发送通知。 PD 会向您提供一个您可以寄信的特定地址。 创建具有此类集成的服务时,您可以设置优先级、处理传入事件的顺序、准确创建警报的方式(针对每个传入信件、针对传入信件 + 特定规则等)。

- Slack
在我看来,这是一个非常有趣的整合。 有时会发生一些事情,但没有被事件所涵盖。 因此,我们添加了 Slack 的集成来创建事件。 也就是说,你可以写信给企业Slack /callofduty 一切都很慢并且很快就会崩溃 PD 将进行处理并将事件发送给值班工程师。
我们这样做:

我们看到:

- API
HTTP 集成。 事实上,这里没有什么特别有趣的,只是一个带有 JSON 格式的 body 的 POST 请求。 例如,一些有趣的事情:我们使用它进行外部监控 。 该服务检查我们网站在世界不同地区的可访问性。 如果我们收到不可接受的响应代码(例如 502),则会创建一个事件,然后一切都遵循上述链。 StatusCake 本身能够监控内部 URL、SSL 证书或域过期。
- 自由网络管理系统
这是另一个监控系统,您可以在他们的网站上阅读更多相关信息 。 在它的帮助下,我们可以从服务器监控网络接口和 iDRAC。
还有 Datadog、CloudWatch 等集成。 您可以更多地了解他们发生的事情 .
可视化
主要的事件报告系统是 Slack。 所有进入 PD 的事件都会写入一个特殊的聊天室,如果其状态发生变化,也会显示在聊天室中。
当有机会在天花板上悬挂的显示器屏幕上显示有用的数据时,我们突然意识到我们(在 DevOps 部门)没有任何东西可以在它们上显示。 有一个很棒的 Grafana,但它并不能涵盖所有内容,员工对警报做出反应,而不是图表。
在 GitHub 上彻底但未成功搜索简洁且信息丰富的 PD“板”后,我们决定编写自己的 - 只包含我们需要的内容。 虽然一开始也有过把PD界面本身显示出来的想法,但看起来更加不方便。
要写入它,您所需要做的就是从具有只读权限的 PD 获取密钥。
这就是我们得到的:
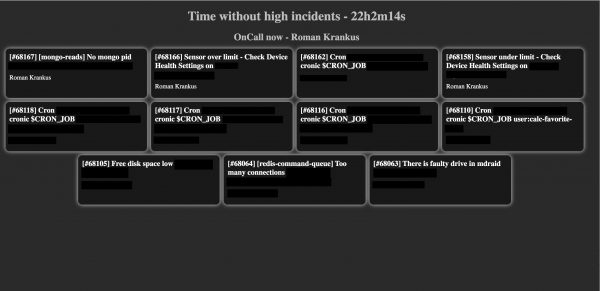
屏幕显示当前未处理的事件、所选计划中当前值班工程师的姓名以及没有高优先级事件的时间(具有高优先级事件的面板将以红色突出显示)。
.
因此,我们收到了一个方便的仪表板来查看所有事件。 如果你们中的一些人发现我们的经验有用,我将很高兴。
来源: habr.com
