

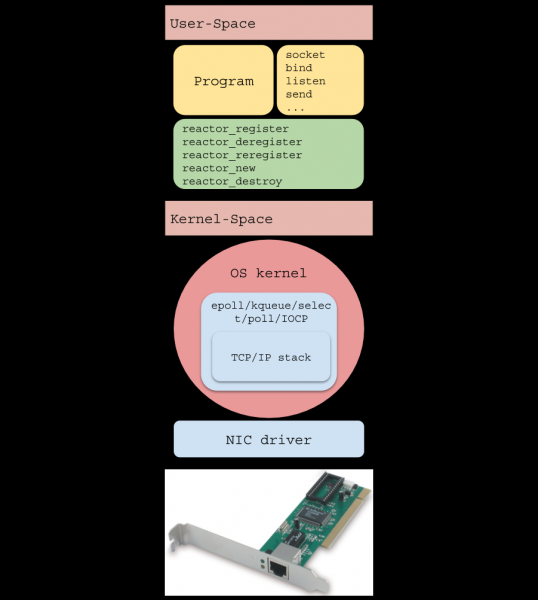
介绍
(单线程 ) 是一种编写高负载软件的模式,在许多流行的解决方案中使用:
- ...
在本文中,我们将了解 I/O 反应器的详细情况及其工作原理,用不到 200 行代码编写一个实现,并使一个简单的 HTTP 服务器每分钟处理超过 40 万个请求。
前言
- 撰写本文的目的是帮助了解 I/O 反应器的功能,从而了解使用它时的风险。
- 理解本文需要基础知识。 以及一些网络应用程序开发经验。
- 所有代码均严格按照(注意:PDF 较长) 为 Linux 并且可以在以下平台获取: .
为什么这样做?
随着互联网的日益普及,Web服务器开始需要同时处理大量连接,因此尝试了两种方法:大量操作系统线程上的阻塞I/O和与非阻塞I/O结合的非阻塞I/O。事件通知系统,也称为“系统选择器”(///ETC)。
第一种方法涉及为每个传入连接创建一个新的操作系统线程。 它的缺点是可扩展性差:操作系统必须实现许多 и 。 它们是昂贵的操作,并且可能导致缺乏可用 RAM 和大量连接。
修改后的版本亮点 (线程池),从而防止系统中止执行,但同时引入了一个新问题:如果一个线程池当前被长读操作阻塞,那么其他已经能够接收数据的套接字将无法接收数据。这样做。
第二种方法使用 (系统选择器)由操作系统提供。 本文讨论最常见的系统选择器类型,它基于有关 I/O 操作准备情况的警报(事件、通知),而不是基于 。 其使用的简化示例可以用以下框图表示:
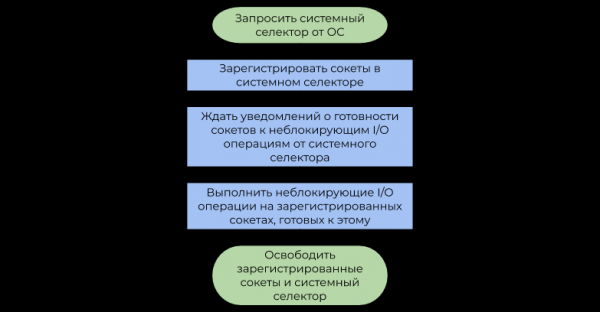
这些方法之间的区别如下:
- 阻塞 I/O 操作 暂停 用户流量 直到那时直到操作系统正常 传入 到字节流(,接收数据)或者内部写入缓冲区中没有足够的可用空间用于后续发送 (发送数据)。
- 系统选择器 随着时间的推移 通知程序操作系统 已经 经过碎片整理的 IP 数据包(TCP、数据接收)或内部写入缓冲区有足够的空间 已经 可用(发送数据)。
总而言之,为每个 I/O 保留一个操作系统线程是对计算能力的浪费,因为实际上,线程并没有做有用的工作(这就是该术语的来源) )。 系统选择器解决了这个问题,允许用户程序更经济地使用CPU资源。
I/O反应器模型
I/O 反应器充当系统选择器和用户代码之间的层。 其工作原理用下面的框图描述:
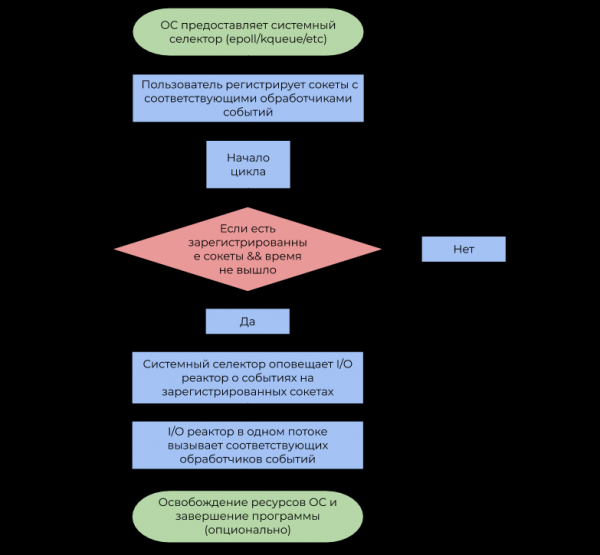
- 让我提醒您,事件是某个套接字能够执行非阻塞 I/O 操作的通知。
- 事件处理程序是 I/O 反应器在接收到事件时调用的函数,然后执行非阻塞 I/O 操作。
值得注意的是,I/O 反应器根据定义是单线程的,但没有什么可以阻止该概念以 1 线程:1 反应器的比例在多线程环境中使用,从而回收所有 CPU 核心。
履行
我们将把公共接口放在一个文件中 ,以及实施 - 在 . reactor.h 将包括以下公告:
在reactor.h中显示声明
typedef struct reactor Reactor;
/*
* Указатель на функцию, которая будет вызываться I/O реактором при поступлении
* события от системного селектора.
*/
typedef void (*Callback)(void *arg, int fd, uint32_t events);
/*
* Возвращает `NULL` в случае ошибки, не-`NULL` указатель на `Reactor` в
* противном случае.
*/
Reactor *reactor_new(void);
/*
* Освобождает системный селектор, все зарегистрированные сокеты в данный момент
* времени и сам I/O реактор.
*
* Следующие функции возвращают -1 в случае ошибки, 0 в случае успеха.
*/
int reactor_destroy(Reactor *reactor);
int reactor_register(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg);
int reactor_deregister(const Reactor *reactor, int fd);
int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg);
/*
* Запускает цикл событий с тайм-аутом `timeout`.
*
* Эта функция передаст управление вызывающему коду если отведённое время вышло
* или/и при отсутствии зарегистрированных сокетов.
*/
int reactor_run(const Reactor *reactor, time_t timeout);I/O反应器结构包括 选择器 и ,它将每个套接字映射到 CallbackData (事件处理程序的结构及其用户参数)。
显示 Reactor 和 CallbackData
struct reactor {
int epoll_fd;
GHashTable *table; // (int, CallbackData)
};
typedef struct {
Callback callback;
void *arg;
} CallbackData;请注意,我们已经启用了处理的能力 根据指数。 在 reactor.h 我们声明结构 reactor而在 reactor.c 我们定义它,从而防止用户显式更改其字段。 这是图案之一 ,它简洁地符合 C 语义。
功能 reactor_register, reactor_deregister и reactor_reregister 更新系统选择器和哈希表中感兴趣的套接字和相应事件处理程序的列表。
显示注册功能
#define REACTOR_CTL(reactor, op, fd, interest)
if (epoll_ctl(reactor->epoll_fd, op, fd,
&(struct epoll_event){.events = interest,
.data = {.fd = fd}}) == -1) {
perror("epoll_ctl");
return -1;
}
int reactor_register(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg) {
REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest)
g_hash_table_insert(reactor->table, int_in_heap(fd),
callback_data_new(callback, callback_arg));
return 0;
}
int reactor_deregister(const Reactor *reactor, int fd) {
REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0)
g_hash_table_remove(reactor->table, &fd);
return 0;
}
int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg) {
REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest)
g_hash_table_insert(reactor->table, int_in_heap(fd),
callback_data_new(callback, callback_arg));
return 0;
}I/O 反应器拦截带有描述符的事件后 fd,它调用相应的事件处理程序,并将其传递给该事件处理程序 fd, 生成的事件和用户指针 void.
显示reactor_run()函数
int reactor_run(const Reactor *reactor, time_t timeout) {
int result;
struct epoll_event *events;
if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL)
abort();
time_t start = time(NULL);
while (true) {
time_t passed = time(NULL) - start;
int nfds =
epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed);
switch (nfds) {
// Ошибка
case -1:
perror("epoll_wait");
result = -1;
goto cleanup;
// Время вышло
case 0:
result = 0;
goto cleanup;
// Успешная операция
default:
// Вызвать обработчиков событий
for (int i = 0; i < nfds; i++) {
int fd = events[i].data.fd;
CallbackData *callback =
g_hash_table_lookup(reactor->table, &fd);
callback->callback(callback->arg, fd, events[i].events);
}
}
}
cleanup:
free(events);
return result;
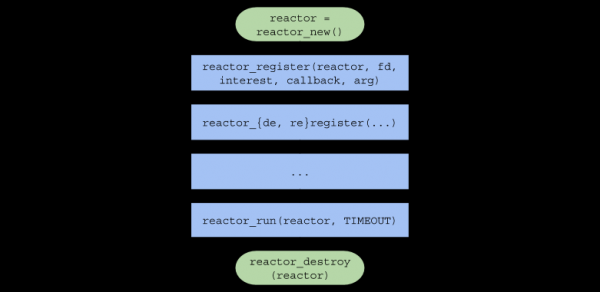
}总而言之,用户代码中的函数调用链将采用以下形式:
单线程服务器
为了测试高负载下的 I/O 反应器,我们将编写一个简单的 HTTP Web 服务器,用图像响应任何请求。
HTTP 协议快速参考
- 这是协议 ,主要用于服务器与浏览器交互。
HTTP 可以很容易地使用 协议 ,以指定的格式发送和接收消息 .
请求格式
<КОМАНДА> <URI> <ВЕРСИЯ HTTP>CRLF
<ЗАГОЛОВОК 1>CRLF
<ЗАГОЛОВОК 2>CRLF
<ЗАГОЛОВОК N>CRLF CRLF
<ДАННЫЕ>CRLF是两个字符的序列:rиn,分隔请求的第一行、标头和数据。<КОМАНДА>- 其中之一CONNECT,DELETE,GET,HEAD,OPTIONS,PATCH,POST,PUT,TRACE。 浏览器将向我们的服务器发送命令GET,意思是“将文件的内容发送给我。”<URI>- 。 例如,如果 URI =/index.html,然后客户端请求站点的主页。<ВЕРСИЯ HTTP>— HTTP 协议的版本,格式为HTTP/X.Y。 目前最常用的版本是HTTP/1.1.<ЗАГОЛОВОК N>是格式为的键值对<КЛЮЧ>: <ЗНАЧЕНИЕ>,发送到服务器进行进一步分析。<ДАННЫЕ>— 服务器执行操作所需的数据。 很多时候很简单 或任何其他格式。
响应格式
<ВЕРСИЯ HTTP> <КОД СТАТУСА> <ОПИСАНИЕ СТАТУСА>CRLF
<ЗАГОЛОВОК 1>CRLF
<ЗАГОЛОВОК 2>CRLF
<ЗАГОЛОВОК N>CRLF CRLF
<ДАННЫЕ><КОД СТАТУСА>是表示运算结果的数字。 我们的服务器将始终返回状态 200(操作成功)。<ОПИСАНИЕ СТАТУСА>— 状态代码的字符串表示形式。 对于状态代码 200,这是OK.<ЗАГОЛОВОК N>— 标头的格式与请求中的格式相同。 我们将归还标题Content-Length(文件大小)和Content-Type: text/html(返回数据类型)。<ДАННЫЕ>— 用户请求的数据。 在我们的例子中,这是图像的路径 .
文件 (单线程服务器)包含文件 ,其中包含以下函数原型:
在 common.h 中显示函数原型
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов принять новое соединение.
*/
static void on_accept(void *arg, int fd, uint32_t events);
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов отправить HTTP ответ.
*/
static void on_send(void *arg, int fd, uint32_t events);
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов принять часть HTTP запроса.
*/
static void on_recv(void *arg, int fd, uint32_t events);
/*
* Переводит входящее соединение в неблокирующий режим.
*/
static void set_nonblocking(int fd);
/*
* Печатает переданные аргументы в stderr и выходит из процесса с
* кодом `EXIT_FAILURE`.
*/
static noreturn void fail(const char *format, ...);
/*
* Возвращает файловый дескриптор сокета, способного принимать новые
* TCP соединения.
*/
static int new_server(bool reuse_port);功能宏也有描述 SAFE_CALL() 并且函数被定义 fail()。 宏将表达式的值与错误进行比较,如果条件为真,则调用该函数 fail():
#define SAFE_CALL(call, error)
do {
if ((call) == error) {
fail("%s", #call);
}
} while (false)功能 fail() 将传递的参数打印到终端(例如 )并用代码终止程序 EXIT_FAILURE:
static noreturn void fail(const char *format, ...) {
va_list args;
va_start(args, format);
vfprintf(stderr, format, args);
va_end(args);
fprintf(stderr, ": %sn", strerror(errno));
exit(EXIT_FAILURE);
}功能 new_server() 返回由系统调用创建的“服务器”套接字的文件描述符 , и 并能够以非阻塞模式接受传入连接。
显示 new_server() 函数
static int new_server(bool reuse_port) {
int fd;
SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)),
-1);
if (reuse_port) {
SAFE_CALL(
setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)),
-1);
}
struct sockaddr_in addr = {.sin_family = AF_INET,
.sin_port = htons(SERVER_PORT),
.sin_addr = {.s_addr = inet_addr(SERVER_IPV4)},
.sin_zero = {0}};
SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1);
SAFE_CALL(listen(fd, SERVER_BACKLOG), -1);
return fd;
}- 请注意,套接字最初是使用标志以非阻塞模式创建的
SOCK_NONBLOCK这样在函数中on_accept()(了解更多)系统调用accept()并没有停止线程的执行。 - 如果
reuse_port是true,那么这个函数将使用选项配置套接字 通过 在多线程环境中使用相同的端口(请参阅“多线程服务器”部分)。
事件处理程序 on_accept() 操作系统生成事件后调用 EPOLLIN,在这种情况下意味着可以接受新连接。 on_accept() 接受新连接,将其切换到非阻塞模式并向事件处理程序注册 on_recv() 在 I/O 反应器中。
显示 on_accept() 函数
static void on_accept(void *arg, int fd, uint32_t events) {
int incoming_conn;
SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1);
set_nonblocking(incoming_conn);
SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv,
request_buffer_new()),
-1);
}事件处理程序 on_recv() 操作系统生成事件后调用 EPOLLIN,在这种情况下意味着连接已注册 on_accept(),准备接收数据。
on_recv() 从连接中读取数据,直到完全接收到 HTTP 请求,然后注册一个处理程序 on_send() 发送 HTTP 响应。 如果客户端中断连接,则套接字将被取消注册并关闭 .
显示函数 on_recv()
static void on_recv(void *arg, int fd, uint32_t events) {
RequestBuffer *buffer = arg;
// Принимаем входные данные до тех пор, что recv возвратит 0 или ошибку
ssize_t nread;
while ((nread = recv(fd, buffer->data + buffer->size,
REQUEST_BUFFER_CAPACITY - buffer->size, 0)) > 0)
buffer->size += nread;
// Клиент оборвал соединение
if (nread == 0) {
SAFE_CALL(reactor_deregister(reactor, fd), -1);
SAFE_CALL(close(fd), -1);
request_buffer_destroy(buffer);
return;
}
// read вернул ошибку, отличную от ошибки, при которой вызов заблокирует
// поток
if (errno != EAGAIN && errno != EWOULDBLOCK) {
request_buffer_destroy(buffer);
fail("read");
}
// Получен полный HTTP запрос от клиента. Теперь регистрируем обработчика
// событий для отправки данных
if (request_buffer_is_complete(buffer)) {
request_buffer_clear(buffer);
SAFE_CALL(reactor_reregister(reactor, fd, EPOLLOUT, on_send, buffer),
-1);
}
}事件处理程序 on_send() 操作系统生成事件后调用 EPOLLOUT,表示连接已注册 on_recv(),准备发送数据。 此函数将包含带有图像的 HTML 的 HTTP 响应发送到客户端,然后将事件处理程序更改回 on_recv().
显示 on_send() 函数
static void on_send(void *arg, int fd, uint32_t events) {
const char *content = "<img "
"src="https://habrastorage.org/webt/oh/wl/23/"
"ohwl23va3b-dioerobq_mbx4xaw.jpeg">";
char response[1024];
sprintf(response,
"HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: "
"text/html" DOUBLE_CRLF "%s",
strlen(content), content);
SAFE_CALL(send(fd, response, strlen(response), 0), -1);
SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1);
}最后,在文件中 http_server.c,在函数中 main() 我们使用以下方法创建一个 I/O 反应器 reactor_new(),创建一个服务器套接字并注册它,使用启动反应堆 reactor_run() 正好一分钟,然后我们释放资源并退出程序。
显示http_server.c
#include "reactor.h"
static Reactor *reactor;
#include "common.h"
int main(void) {
SAFE_CALL((reactor = reactor_new()), NULL);
SAFE_CALL(
reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL),
-1);
SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1);
SAFE_CALL(reactor_destroy(reactor), -1);
}让我们检查一切是否按预期工作。 编译(chmod a+x compile.sh && ./compile.sh 在项目根目录下)并启动自己编写的服务器,打开 在浏览器中看看我们期望什么:
绩效衡量
显示我的汽车规格
$ screenfetch
MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa
MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic
MMd /++ -sNMd: Uptime: 2h 34m
MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217
ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20
NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080
NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10
NMm dMM -MMm `MMM dMM. dMM WM: Muffin
NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y)
NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3]
hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y
-NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9
-dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C]
`/dMNmy+/:-------------:/yMMM GPU: NV136
./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB
.MMMMMMMMMMMMMMMMMMM让我们测量一下单线程服务器的性能。 让我们打开两个终端:在一个终端中我们将运行 ./http_server,在不同的 - 。 一分钟后,第二个终端将显示以下统计信息:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 493.52us 76.70us 17.31ms 89.57%
Req/Sec 24.37k 1.81k 29.34k 68.13%
11657769 requests in 1.00m, 1.60GB read
Requests/sec: 193974.70
Transfer/sec: 27.19MB我们的单线程服务器每分钟能够处理来自 11 个连接的超过 100 万个请求。 结果还不错,但是可以改进吗?
多线程服务器
如上所述,I/O 反应器可以在单独的线程中创建,从而利用所有 CPU 核心。 让我们将这种方法付诸实践:
显示http_server_multithreaded.c
#include "reactor.h"
static Reactor *reactor;
#pragma omp threadprivate(reactor)
#include "common.h"
int main(void) {
#pragma omp parallel
{
SAFE_CALL((reactor = reactor_new()), NULL);
SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN,
on_accept, NULL),
-1);
SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1);
SAFE_CALL(reactor_destroy(reactor), -1);
}
}现在每个线程 反应堆:
static Reactor *reactor;
#pragma omp threadprivate(reactor)请注意函数参数 new_server() 行为 true。 这意味着我们将选项分配给服务器套接字 在多线程环境中使用它。 您可以阅读更多内容 .
第二次运行
现在让我们测量多线程服务器的性能:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.14ms 2.53ms 40.73ms 89.98%
Req/Sec 79.98k 18.07k 154.64k 78.65%
38208400 requests in 1.00m, 5.23GB read
Requests/sec: 635876.41
Transfer/sec: 89.14MB1分钟处理的请求数增加了~3.28倍! 但我们只差 XNUMX 万左右,所以让我们尝试解决这个问题。
首先我们看一下生成的统计数据 :
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded
Performance counter stats for './http_server_multithreaded':
242446,314933 task-clock (msec) # 4,000 CPUs utilized
1 813 074 context-switches # 0,007 M/sec
4 689 cpu-migrations # 0,019 K/sec
254 page-faults # 0,001 K/sec
895 324 830 170 cycles # 3,693 GHz
621 378 066 808 instructions # 0,69 insn per cycle
119 926 709 370 branches # 494,653 M/sec
3 227 095 669 branch-misses # 2,69% of all branches
808 664 cache-misses
60,604330670 seconds time elapsed, 编译与 -march=native, ,点击次数增加 , 增加 MAX_EVENTS 并使用 EPOLLET 并没有给性能带来显着的提升。 但是如果增加同时连接的数量会发生什么?
352个同时连接的统计:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 352 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.12ms 3.79ms 68.23ms 87.49%
Req/Sec 83.78k 12.69k 169.81k 83.59%
40006142 requests in 1.00m, 5.48GB read
Requests/sec: 665789.26
Transfer/sec: 93.34MB获得了所需的结果,并显示了一个有趣的图表,显示 1 分钟内处理的请求数量与连接数量的依赖关系:
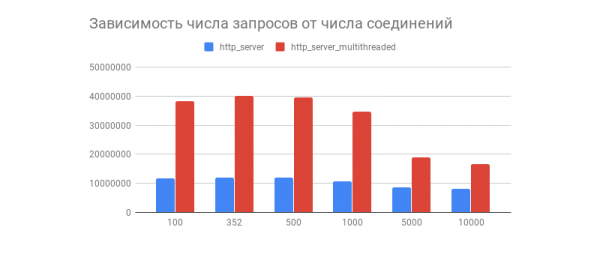
我们发现,在建立几百个连接后,两个服务器处理的请求数量都急剧下降(在多线程版本中更为明显)。这是否与实现方式有关? TCP/IP 堆 Linux欢迎在评论区分享您对该图表行为以及多线程和单线程版本优化方面的想法。
如 在评论中,这个性能测试并没有显示真实负载下 I/O 反应器的行为,因为几乎总是服务器与数据库交互,输出日志,使用加密技术 等等,其结果是负载变得不均匀(动态)。 有关 I/O 前摄器的文章将与第三方组件一起进行测试。
I/O反应器的缺点
您需要了解 I/O 反应器并非没有缺点,即:
- 在多线程环境中使用 I/O 反应器有些困难,因为您必须手动管理流量。
- 实践表明,大多数情况下负载不均匀,这可能会导致一个线程在记录日志,而另一个线程忙于工作。
- 如果一个事件处理程序阻塞了一个线程,那么系统选择器本身也会阻塞,这可能会导致难以发现的错误。
解决这些问题 ,它通常有一个调度程序,可以将负载均匀分配到线程池,并且还具有更方便的 API。 我们稍后会在我的另一篇文章中讨论它。
结论
我们从理论直接进入分析仪排气的旅程到此结束。
您不应该纠缠于此,因为还有许多其他同样有趣的方法来编写具有不同程度的便利性和速度的网络软件。 在我看来,有趣的是,下面给出了链接。
直到我们再次见面!
有趣的项目
- 他们自己
还有什么可读的?
来源: habr.com
