

这两个数据科学流行语让很多人感到困惑。 数据挖掘经常被误解为提取和检索数据,但实际情况要复杂得多。 在这篇文章中,让我们点挖掘并找出数据挖掘和数据提取之间的区别。
什么是数据挖掘?
数据挖掘,也称为 数据库知识发现(KDD),是一种经常用于使用统计和数学方法分析大型数据集的技术,以发现隐藏的模式或趋势并从中提取价值。
数据挖掘可以做什么?
通过自动化流程, 可以浏览数据库并有效地发现隐藏的模式。 对于企业来说,数据挖掘通常用于发现数据中的模式和关系,以帮助做出更好的业务决策。
应用实例
数据挖掘在1990世纪XNUMX年代普及后,零售、金融、医疗保健、运输、电信、电子商务等多个行业的公司开始使用数据挖掘方法来获取基于数据的信息。 数据挖掘可以帮助细分客户、识别欺诈、预测销售等等。
- 客户细分
通过分析客户数据并识别目标客户的特征,公司可以将他们分为一个单独的组,并提供满足他们需求的特殊优惠。 - 市场篮子分析
该技术基于这样的理论:如果您购买某组产品,您更有可能购买另一组产品。 一个著名的例子是:当父亲为婴儿购买尿布时,他们往往会在购买尿布的同时购买啤酒。 - 销售预测
它可能看起来与购物篮分析类似,但这次数据分析用于预测客户将来何时再次购买产品。 例如,教练购买了一罐可以使用 9 个月的蛋白质。 销售这种蛋白质的商店计划在 9 个月内推出新的蛋白质,以便教练再次购买。 - 欺诈识别
数据挖掘有助于构建欺诈检测模型。 通过收集欺诈和真实报告的样本,企业能够确定哪些交易是可疑的。 - 生产中的模式检测
在制造业中,数据挖掘用于通过识别产品架构、配置文件和客户需求之间的关系来帮助设计系统。 数据挖掘还可以预测产品开发时间和成本。
这些只是数据挖掘的几个用例。
数据挖掘的阶段
数据挖掘是收集、选择、清理、转换和提取数据的整体过程,以评估模式并最终提取价值。
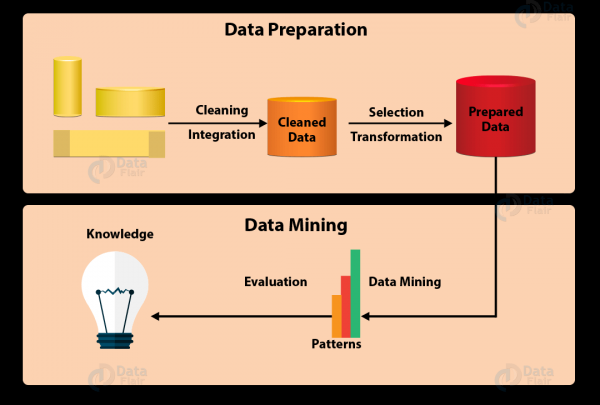
一般来说,整个数据挖掘过程可以概括为7个步骤:
- 数据清理
在现实世界中,数据并不总是经过清理和结构化的。 它们通常是嘈杂的、不完整的,并且可能包含错误。 为了确保数据挖掘结果准确,首先需要清理数据。 一些清理方法包括填写缺失值、自动和手动控制等。 - 数据集成
这是提取、组合和集成来自不同来源的数据的阶段。 来源可以是数据库、文本文件、电子表格、文档、多维数据集、互联网等。 - 数据采样
通常,数据挖掘中并不需要所有集成数据。 数据采样是从大型数据库中仅选择和提取有用数据的阶段。 - 数据转换
一旦选择了数据,它就会被转换为适合挖掘的形式。 这个过程包括归一化、聚合、泛化等。 - 数据挖掘
这是数据挖掘中最重要的部分 - 使用智能方法来查找其中的模式。 该过程包括回归、分类、预测、聚类、关联学习等。 - 模型评估
此步骤旨在识别潜在有用、易于理解的模式以及支持假设的模式。 - 知识表示
在最后阶段,使用知识表示和可视化方法以有吸引力的方式呈现获得的信息。
数据挖掘的缺点
- 大量的时间和劳动力投入
由于数据挖掘是一个漫长而复杂的过程,因此需要高效且熟练的人员进行大量工作。 数据科学家可以使用强大的数据挖掘工具,但他们需要专家来准备数据并理解结果。 因此,处理所有信息可能需要一些时间。 - 数据隐私和安全
由于数据挖掘通过市场方式收集客户信息,因此可能侵犯用户隐私。 此外,黑客还可以获取数据挖掘系统中存储的数据。 这对客户数据的安全构成威胁。 如果窃取的数据被滥用,很容易伤害他人。
以上是对数据挖掘的简单介绍。 正如我已经提到的,数据挖掘包含收集和整合数据的过程,其中包括提取数据(数据提取)的过程。 在这种情况下,可以肯定地说,数据提取可以是长期数据挖掘过程的一部分。
什么是数据提取?
也称为“网络数据挖掘”和“网络抓取”,这一过程是将数据从(通常是非结构化或结构不良)数据源提取到集中位置并集中在一个位置进行存储或进一步处理的行为。 具体来说,非结构化数据源包括网页、电子邮件、文档、PDF文件、扫描文本、大型机报告、卷轴文件、公告等。 集中存储可以是本地、云或混合。 重要的是要记住,数据提取不包括稍后可能发生的处理或其他分析。
数据提取可以做什么?
基本上,数据提取的目的分为三类。
- 归档
数据提取可以将数据从物理格式(例如书籍、报纸、发票)转换为数字格式(例如数据库)以进行存储或备份。 - 更改数据格式
当您想要将数据从当前站点迁移到正在开发的新站点时,您可以通过提取数据的方式从您自己的站点收集数据。 - 数据分析
通常需要进一步分析提取的数据以深入了解它。 这听起来可能与数据挖掘类似,但请记住,数据挖掘是数据挖掘的目标,而不是数据挖掘的一部分。 此外,对数据的分析也不同。 一个例子是,在线商店所有者从亚马逊等电子商务网站提取产品信息,以实时监控竞争对手的策略。 与数据挖掘一样,数据提取是一个自动化过程,具有许多优点。 过去,人们手动将数据从一个地方复制粘贴到另一个地方,这非常耗时。 数据提取加快了收集速度,大大提高了提取数据的准确性。
使用数据提取的一些示例
与数据挖掘类似,数据挖掘广泛应用于各个行业。 除了电子商务价格监控之外,数据挖掘还可以帮助您进行自己的研究、新闻聚合、营销、房地产、旅行和旅游、咨询、金融等。
- 领先一代
公司可以从目录中提取数据:Yelp、Crunchbase、Yellowpages,并为业务开发生成潜在客户。 您可以观看下面的视频,了解如何使用以下命令从黄页中提取数据 . - 内容和新闻的聚合
内容聚合网站可以从多个来源定期接收数据源并保持其网站最新。 - 情绪分析
从 Instagram 和 Twitter 等社交网络提取评论、评论和推荐后,专业人士可以分析潜在的态度并深入了解品牌、产品或现象的感知方式。
数据提取步骤
数据抽取是ETL(Extract、Transform、Load:提取、转换、加载)和ELT(Extract、Load、Transform)的第一阶段。 ETL 和 ELT 本身就是完整数据集成策略的一部分。 换句话说,提取数据可以是其提取的一部分。
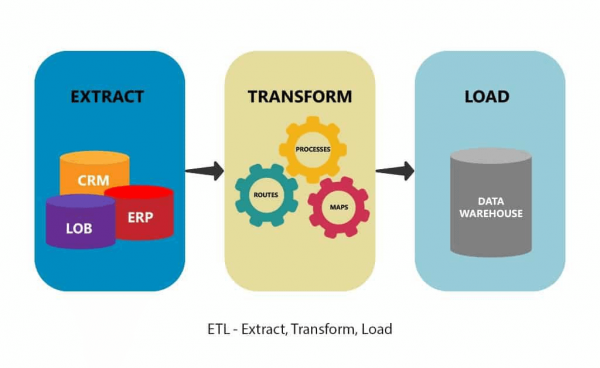
提取、转换、加载
虽然数据挖掘就是从大量数据中提取信息,但数据提取是一个更短、更简单的过程。 它可以简化为三个阶段:
- 选择数据源
选择您要从中提取数据的源,例如网站。 - 数据收集
向站点发送“GET”请求,并使用Python、PHP、R、Ruby等编程语言解析生成的HTML文档。 - 数据存储
将数据保存到本地数据库或云存储以供将来使用。 如果您是一位经验丰富的程序员,想要提取数据,那么上述步骤对您来说可能看起来很简单。 但是,如果您不是程序员,有一个捷径 - 使用数据挖掘工具,例如 。 数据提取工具与数据挖掘工具一样,旨在节省能源并使每个人都可以轻松进行数据处理。 这些工具不仅经济,而且适合初学者。 它们允许用户在几分钟内收集数据,将其存储在云中,并将其导出为多种格式:Excel、CSV、HTML、JSON,或通过 API 导出到网站上的数据库。
数据提取的缺点
- 服务器崩溃
当大规模提取数据时,目标站点的Web服务器可能会过载,从而导致服务器崩溃。 这会损害网站所有者的利益。 - 按IP禁止
当一个人过于频繁地收集数据时,网站可能会阻止他们的 IP 地址。 资源可以通过使数据不完整来完全禁止 IP 地址或限制访问。 为了检索数据并避免阻塞,您需要以适中的速度进行操作并应用一些防阻塞技术。 - 法律问题
当涉及到合法性时,从网络中提取数据就陷入了灰色地带。 Linkedin 和 Facebook 等主要网站在其使用条款中明确规定禁止任何自动提取数据的行为。 由于机器人活动,公司之间已经发生了许多诉讼。
数据挖掘和数据提取之间的主要区别
- 数据挖掘也称为数据库中的知识发现、知识提取、数据/模式分析、信息收集。 数据提取与网页数据提取、网页扫描、数据收集等可以互换使用。
- 数据挖掘研究主要基于结构化数据,而数据挖掘通常来自非结构化或结构不良的数据源。
- 数据挖掘的目标是使数据对分析更有用。 数据提取是将数据收集到可以存储或处理的地方。
- 数据挖掘分析基于识别模式或趋势的数学方法。 数据提取是基于编程语言或数据提取工具来绕过来源。
- 数据挖掘的目的是发现以前不知道或忽略的事实,而数据提取则处理现有信息。
- 数据挖掘更加复杂,需要大量投资来培训人员。 使用正确的工具提取数据可以非常简单且具有成本效益。
我们帮助初学者不要对数据感到困惑。 特别是对于 habravchans,我们制作了促销代码 哈勃, 在横幅上显示的折扣基础上额外提供 10% 的折扣。
更多课程
推荐文章
来源: habr.com
