

几个月前 - 民众 到 PostgreSQL。
从那时起,您已经使用它超过 6000 次,但其中一项可能未被注意到的便利功能是 结构线索,看起来像这样:
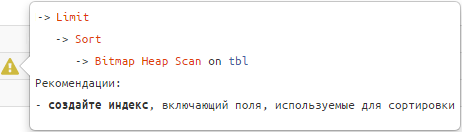
倾听他们的声音,您的要求将“变得如丝般顺滑”。 🙂
但严重的是,许多情况下请求在资源方面缓慢且“贪婪”, 具有典型性,可以通过计划的结构和数据识别.
在这种情况下,每个开发人员都不必自己寻找优化选项,完全依靠自己的经验——我们可以告诉他这里发生了什么,可能是什么原因,以及 如何提出解决方案. 这就是我们所做的。

让我们仔细看看这些案例——它们是如何定义的以及它们带来了哪些建议。
为了更好地沉浸在主题中,您可以先从中收听相应的块 ,然后才去详细分析每个例子:

#1:索引“undersorting”
什么时候出现
显示客户“LLC Kolokolchik”的最后一张发票。
如何鉴别
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
建议
使用的索引 扩展排序字段.
示例:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
fk_cli = 1 -- отбор по конкретной связи
ORDER BY
pk DESC -- хотим всего одну "последнюю" запись
LIMIT 1; 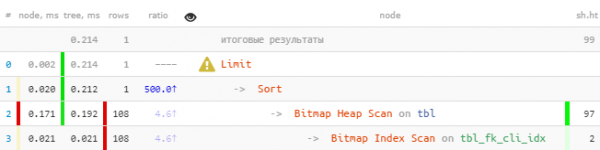
你可以立即注意到索引减去了 100 多条记录,然后将这些记录全部排序,然后只剩下一条。
我们修复:
DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC); -- добавили ключ сортировки

即使在这样一个原始样本上—— 读取速度提高 8.5 倍,读取次数减少 33 倍. 效果会更清晰,每个值的“事实”越多。 fk.
我注意到这样的索引将作为“前缀”索引使用,不会比其他查询的前一个索引差 fk, 排序依据 pk 过去不是现在也不是(你可以阅读更多关于这个 ). 特别是,它将提供正常的 显式外键支持 通过这个领域。
#2:索引交集(BitmapAnd)
什么时候出现
显示代表“NJSC Lyutik”为客户“LLC Kolokolchik”签订的所有合同。
如何鉴别
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan建议
创建 综合指数 按来自两个源的字段或从第二个扩展现有字段之一。
示例:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org); -- индекс для foreign key
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999); -- отбор по конкретной паре 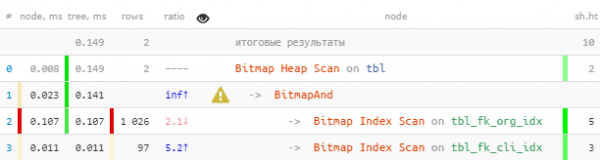
我们修复:
DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);

此处增益较小,因为位图堆扫描本身非常有效。 但不管怎么说 读取速度提高 7 倍,读取次数减少 2.5 倍.
#3:合并索引(BitmapOr)
什么时候出现
显示前 20 个最旧的“自己的”或未分配的处理请求,优先处理自己的请求。
如何鉴别
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan建议
使用 联合 [全部] 为每个条件 OR 块组合子查询。
示例:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL -- с вероятностью 1:16 запись "ничья"
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own;
CREATE INDEX ON tbl(fk_own, pk); -- индекс с "вроде как подходящей" сортировкой
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR -- свои
fk_own IS NULL -- ... или "ничьи"
ORDER BY
pk
, (fk_own = 1) DESC -- сначала "свои"
LIMIT 20;
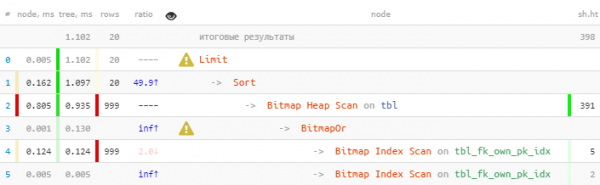
我们修复:
(
SELECT
*
FROM
tbl
WHERE
fk_own = 1 -- сначала "свои" 20
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL -- потом "ничьи" 20
ORDER BY
pk
LIMIT 20
)
LIMIT 20; -- но всего - 20, больше и не надо 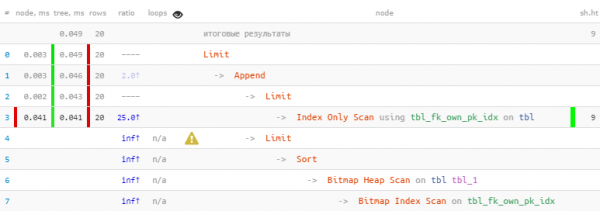
我们利用了第一个块中立即接收到所有 20 条必要记录的事实,所以第二个具有更“昂贵”的位图堆扫描的记录甚至没有被执行——结果 速度提高 22 倍,读取次数减少 44 倍!
关于这种优化方法的更详细的故事 具体例子 可以在文章中阅读 и .
通用版 通过几个键有序选择 (而不仅仅是一对 const / NULL)在文章中讨论 .
#4:我们读得太多了
什么时候出现
通常,当您想要“附加另一个过滤器”到现有请求时,它就会发生。
“而你没有相同的,但是 与珍珠母纽扣“? 电影《钻石之手》
例如,修改上面的任务,显示前 20 个最旧的“关键”处理请求,无论它们的目的如何。
如何鉴别
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- отфильтровано >80% прочитанного
&& loops × RRbF > 100 -- и при этом больше 100 записей суммарно
建议
创造 [更多] 专业 带 WHERE 子句的索引 或在索引中包含其他字段。
如果过滤条件对于您的任务是“静态的”——即 不包括扩展 未来的值列表 - 最好使用 WHERE 索引。 各种布尔/枚举状态很适合这一类。
如果过滤条件 可以取不同的值,最好用这些字段扩展索引——就像 Bitmap 和上面的情况一样。
示例:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own
, (random() < 1::real/50) critical; -- 1:50, что заявка "критичная"
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20; 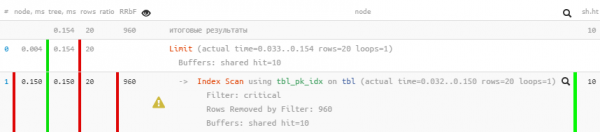
我们修复:
CREATE INDEX ON tbl(pk)
WHERE critical; -- добавили "статичное" условие фильтрации

如您所见,计划中的过滤完全没有了,请求变成了 快 5 倍.
#5:稀疏表
什么时候出现
各种尝试让自己的任务处理队列,当大量更新/删除表上的记录导致出现大量“死”记录的情况。
如何鉴别
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
建议
定期手动执行 真空[满] 或达到足够频繁的处理 通过微调其参数,包括 .
在大多数情况下,此类问题是由业务逻辑调用时查询布局不佳引起的,例如在 .
但是我们必须明白,即使是 VACUUM FULL 也不能总是提供帮助。 对于这种情况,您应该熟悉本文中的算法。 .
#6:从索引的“中间”读取
什么时候出现
看起来他们读了一点,所有的东西都被索引了,他们没有额外过滤任何人——但是,阅读的页面仍然比我们想要的多得多。
如何鉴别
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
建议
仔细查看所用索引的结构和查询中指定的关键字段 - 很可能, 未设置索引部分. 您很可能需要创建一个类似的索引,但没有前缀字段,或者 .
示例:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org, fk_cli); -- все почти как в #2
-- только вот отдельный индекс по fk_cli мы уже посчитали лишним и удалили
SELECT
*
FROM
tbl
WHERE
fk_cli = 999 -- а fk_org не задано, хотя стоит в индексе раньше
LIMIT 20; 
一切似乎都很好,即使就索引而言,但有些可疑 - 对于读取的 20 条记录中的每一条,必须减去 4 页数据,每条记录 32KB - 这不是大胆的吗? 是和索引名称 tbl_fk_org_fk_cli_idx 导致思想。
我们修复:
CREATE INDEX ON tbl(fk_cli); 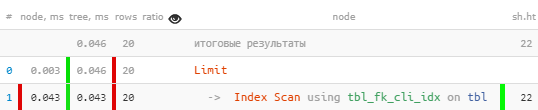
突然 - 阅读速度提高 10 倍,阅读时间减少 4 倍!
有关索引使用效率低下的更多示例,请参阅文章 .
#7:CTE×CTE
什么时候出现
应要求 得分“胖”CTE 来自不同的表,然后决定在它们之间做 JOIN.
该案例与低于 v12 的版本或带有 WITH MATERIALIZED.
如何鉴别
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- слишком большое декартово произведение CTE
建议
仔细分析请求 ? 如果是,那么 在 hstore/json 中应用“字典” 根据描述的模型 .
#8:交换到磁盘(临时写入)
什么时候出现
大量记录的一次性处理(排序或唯一化)不适合为此分配的内存。
如何鉴别
-> *
&& temp written > 0建议
如果操作使用的内存量没有大大超过参数的设置值 , 应该纠正。 你可以立即在每个人的配置中,或者你可以通过 SET [LOCAL] 对于特定的请求/交易。
示例:
SHOW work_mem;
-- "16MB"
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1; 
我们修复:
SET work_mem = '128MB'; -- перед выполнением запроса 
出于显而易见的原因,如果只使用内存而不使用磁盘,那么查询的执行速度会快得多。 同时,部分负载也从硬盘上卸下。
但是你需要明白,分配大量内存也总是行不通的——这对每个人来说都是不够的。
#9:不相关的统计数据
什么时候出现
一下子往基地里倒了很多,但他们没有时间把它赶走 ANALYZE.
如何鉴别
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10建议
花同样的钱 ANALYZE.
这种情况在中有更详细的描述 .
#10:“出了点问题”
什么时候出现
有锁在等待竞争请求,或者没有足够的 CPU/管理程序硬件资源。
如何鉴别
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- читали мало, но слишком долго
建议
使用外部 监视系统 服务器阻塞或异常资源消耗。 我们已经讨论过我们为数百台服务器组织此过程的版本。 и .
来源: habr.com
