


尽管现在几乎到处都有大量数据,但分析数据库仍然很奇特。 它们鲜为人知,更糟糕的是无法有效地使用它们。 许多人继续用专为其他场景设计的 MySQL 或 PostgreSQL “吃仙人掌”,用 NoSQL 吃亏,或者为商业解决方案多付钱。 ClickHouse 改变了游戏规则,显着降低了进入分析型 DBMS 世界的门槛。
来自 BackEnd Conf 2018 的报告,经演讲者许可发布。


我是谁,我为什么要谈论 ClickHouse? 我是 LifeStreet 的开发总监,该公司使用 ClickHouse。 另外,我是 Altinity 的创始人。 是推广ClickHouse的Yandex合作伙伴,帮助Yandex让ClickHouse更加成功。 也准备分享有关 ClickHouse 的知识。

而且我不是 Petya Zaitsev 的兄弟。 我经常被问到这个问题。 不,我们不是兄弟。

“每个人都知道”ClickHouse:
- 非常快,
- 非常舒服
- 在 Yandex 中使用。
对哪些公司以及如何使用它知之甚少。

我会告诉你为什么、在哪里以及如何使用 ClickHouse,除了 Yandex。
我会告诉你在不同的公司如何借助 ClickHouse 解决具体的任务,你的任务可以使用哪些 ClickHouse 工具,以及它们在不同的公司是如何使用的。
我选择了三个从不同角度展示 ClickHouse 的示例。 我认为这会很有趣。

第一个问题是:“为什么我们需要 ClickHouse?”。 这似乎是一个相当明显的问题,但有不止一个答案。

- 第一个答案是性能。 ClickHouse 非常快。 ClickHouse 上的分析也非常快。 它通常可以用在其他东西非常慢或非常糟糕的地方。
- 第二个答案是成本。 首先,扩展成本。 例如,Vertica 是一个非常棒的数据库。 如果您没有大量的 TB 数据,它会很好地工作。 但是当涉及到数百 TB 或 PB 时,许可和支持的成本就相当可观了。 而且很贵。 ClickHouse 是免费的。
- 第三个答案是运营成本。 这是一种略有不同的方法。 RedShift 是一个很好的模拟。 在 RedShift 上,您可以非常快速地做出决定。 它会运作良好,但与此同时,每小时、每天和每月,您都会向亚马逊支付相当高的费用,因为这是一项非常昂贵的服务。 谷歌 BigQuery 也是。 如果有人使用它,那么他就会知道您可以在那里运行多个请求并突然收到数百美元的账单。
ClickHouse 不存在这些问题。

ClickHouse现在用在哪里? 除了 Yandex 之外,ClickHouse 还用于许多不同的企业和公司。
- 首先,这是 Web 应用程序分析,即这是来自 Yandex 的用例。
- 许多 AdTech 公司使用 ClickHouse。
- 许多公司需要分析来自不同来源的事务日志。
- 一些公司使用 ClickHouse 来监控安全日志。 他们将它们上传到 ClickHouse,制作报告,并获得他们需要的结果。
- 公司开始将其用于财务分析,即大企业也逐渐接近 ClickHouse。
- 云耀斑。 如果有人关注 ClickHouse,那么他们很可能听说过这家公司的名字。 这是来自社区的重要贡献者之一。 他们有一个非常认真的 ClickHouse 安装。 例如,他们为 ClickHouse 制作了 Kafka Engine。
- 电信公司开始使用。 一些公司使用 ClickHouse 作为概念验证或已经投入生产。
- 一家公司使用 ClickHouse 来监控生产流程。 他们测试微电路,注销一堆参数,大约有 2 个特征。 然后他们分析游戏是好是坏。
- 区块链分析。 有一家俄罗斯公司,如 Bloxy.info。 这是对以太坊网络的分析。 他们也在 ClickHouse 上这样做了。

规模大小并不重要。很多公司只用一台小型服务器就能解决他们的问题。而更多的公司则使用由多台服务器组成的大型集群。 服务器 或者几十台服务器。
如果你查看记录,那么:
- Yandex:500 多台服务器,他们每天在那里存储 25 亿条记录。
- LifeStreet:60 台服务器,每天大约 75 亿条记录。 与 Yandex 相比,服务器更少,记录更多。
- CloudFlare:36台服务器,他们每天保存200亿条记录。 他们拥有更少的服务器并存储更多的数据。
- 彭博社:102 伺服器每天约有万亿条记录。创纪录保持者。
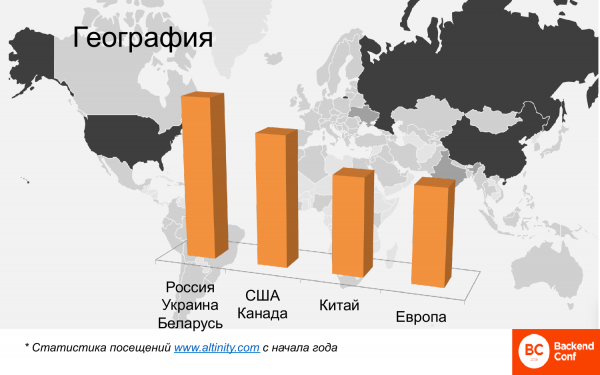
从地理上讲,这也很多。 此处的这张地图显示了世界上使用 ClickHouse 的地方的热图。 俄罗斯、中国、美国在这里非常突出。 欧洲国家很少。 并且有4个集群。
这是比较分析,不需要找绝对数字。 这是对在 Altinity 网站上阅读英文材料的访问者的分析,因为那里没有俄语材料。 而俄罗斯、乌克兰、白俄罗斯,即社区中讲俄语的部分,这些是最多的用户。 然后是美国和加拿大。 中国正在迎头赶上。 六个月前那里几乎没有中国,现在中国已经超过欧洲并继续增长。 老欧洲也不甘落后,奇怪的是,法国是 ClickHouse 使用的领导者。

我为什么要说这一切? 表明ClickHouse正在成为大数据分析的标准方案,并且已经在很多地方得到应用。 如果你使用它,你就处于正确的趋势中。 如果您还没有使用它,那么您不必担心自己会孤单,没有人会帮助您,因为很多人已经在这样做了。

这些是几家公司实际使用 ClickHouse 的例子。
- 第一个例子是广告网络:从 Vertica 迁移到 ClickHouse。 我知道一些公司已经从 Vertica 转型或正在转型。
- 第二个例子是 ClickHouse 上的事务存储。 这是一个建立在反模式之上的例子。 根据开发人员的建议,不应在 ClickHouse 中完成的所有操作都在这里完成。 而且它做得如此有效以至于它起作用了。 而且它比典型的交易解决方案效果更好。
- 第三个例子是ClickHouse上的分布式计算。 有一个问题是如何将 ClickHouse 集成到 Hadoop 生态系统中。 我将展示一个公司如何在 ClickHouse 上做类似于 map reduce 容器的事情,跟踪数据本地化等,以计算一个非常重要的任务。

- LifeStreet 是一家广告技术公司,拥有广告网络附带的所有技术。
- 她从事广告优化、程序化竞价。
- 大量数据:每天约有 10 亿个事件。 同时,赛事又可以分为若干个子赛事。
- 这些数据有很多客户,这些客户不仅是人,还有更多 - 这些是参与程序化竞价的各种算法。

公司走过了一条漫长而充满荆棘的道路。 我在 HighLoad 上谈到了它。 首先,LifeStreet 从 MySQL(短暂停留在 Oracle)迁移到 Vertica。 你可以找到一个关于它的故事。
一切都很好,但很快就发现数据在增长,而 Vertica 很昂贵。 因此,寻求各种替代方案。 其中一些列在这里。 事实上,我们对从第 13 年到第 16 年市场上几乎所有可用的数据库进行了概念验证或有时性能测试,并且在功能方面大致合适。 我还在 HighLoad 上谈到了其中的一些。

任务首先是从 Vertica 迁移,因为数据在增长。 多年来,它们呈指数级增长。 然后他们上架了,但仍然如此。 并且预测这种增长,需要进行某种分析的数据量的业务需求,很明显很快就会讨论 PB 级。 为 PB 支付费用已经非常昂贵,因此我们正在寻找替代方案。
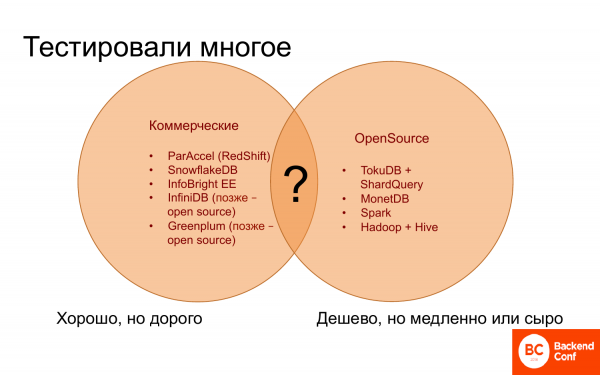
去哪儿? 很长一段时间都不清楚去哪里,因为一方面有商业数据库,它们似乎运作良好。 有些几乎和 Vertica 一样好,有些更差。 但它们都很贵,找不到更便宜更好的了。
另一方面,有开源解决方案,数量不是很多,即对于分析,它们可以在手指上计算。 它们免费或便宜,但速度慢。 而且它们通常缺乏必要和有用的功能。
并且没有什么可以将商业数据库中的优点与开源中的所有免费结合起来。

直到,Yandex 出乎意料地把 ClickHouse 拉了出来,就像戴帽子的魔术师,像兔子一样。 这是一个出乎意料的决定,他们仍然会问这个问题:“为什么?”,但是尽管如此。
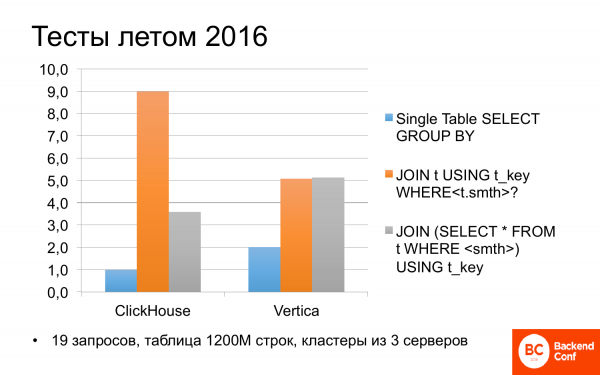
就在 2016 年夏天,我们开始研究什么是 ClickHouse。 事实证明,有时它可以比 Vertica 更快。 我们针对不同的查询测试了不同的场景。 而如果查询只使用一张表,即没有任何连接(join),那么 ClickHouse 的速度是 Vertica 的两倍。
我不太懒惰,前几天看了 Yandex 测试。 那里也一样:ClickHouse 的速度是 Vertica 的两倍,因此他们经常谈论它。
但是如果查询中有连接,那么一切都不是很明确。 而且 ClickHouse 的速度可能是 Vertica 的两倍。 如果您稍微更正请求并重写它,那么它们大致相等。 不错。 并且免费。

LifeStreet 收到测试结果并从不同角度进行了审视后,选择了 ClickHouse。

这是第 16 个年头,我提醒你。 这就像一个关于老鼠的笑话,它们哭泣并刺伤自己,但继续吃仙人掌。 并且对此进行了详细描述,有关于此的视频等。

所以,我就不详细讲了,只讲结果和当时没讲的几件有趣的事。
结果是:
- 成功迁移和一年多的系统已经在生产中运行。
- 生产率和灵活性有所提高。 在我们每天可以存储 10 亿条记录并存储很短时间的情况下,LifeStreet 现在每天存储 75 亿条记录,并且可以存储 3 个月或更长时间。 如果按峰值计算,那么这高达每秒 XNUMX 万个事件。 每天有超过一百万个 SQL 查询到达该系统,大部分来自不同的机器人。
- 尽管 ClickHouse 使用的服务器多于 Vertica,但它们也节省了硬件,因为 Vertica 使用了相当昂贵的 SAS 磁盘。 ClickHouse 使用 SATA。 为什么? 因为在 Vertica 中插入是同步的。 而同步要求磁盘不要减慢太多,网络也不要减慢太多,这是一个相当昂贵的操作。 而在 ClickHouse 中插入是异步的。 此外,您始终可以在本地编写所有内容,这不会产生额外费用,因此即使在较慢的驱动器上,也可以比 Vertika 更快地将数据插入 ClickHouse。 阅读也差不多。 在 SATA 上读取,如果它们在 RAID 中,那么这一切都足够快。
- 不受许可证限制,即 3 台服务器中的 60 PB 数据(20 台服务器是一个副本)和事实和聚合中的 6 万亿条记录。 Vertica 无法提供这样的服务。

在这个例子中,我现在转向实际的事情。
- 首先是高效的方案。 很大程度上取决于架构。
- 二是高效的SQL生成。
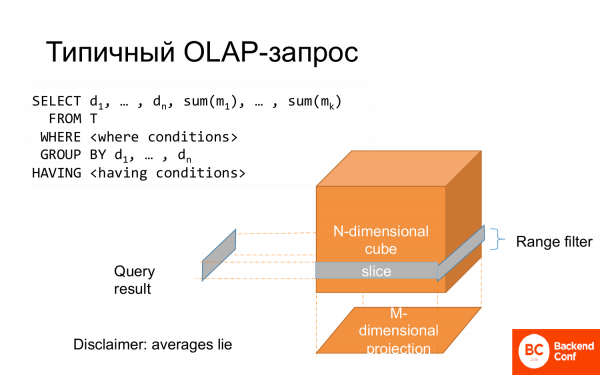
典型的 OLAP 查询是选择。 一些列用于分组,一些列用于聚合函数。 有一个地方,可以表示为立方体的一部分。 整个 group by 可以被认为是一个投影。 这就是为什么它被称为多元数据分析。

通常这是以星图的形式建模的,当沿着光线的两侧有一个中心事实和这个事实的特征时。

就物理设计而言,它如何适合桌面,他们通常会进行标准化表示。 您可以进行非规范化,但它在磁盘上的开销很大,而且查询效率不高。 因此,他们通常会做一个规范化的表示,即一个事实表和很多很多维表。
但它在 ClickHouse 中效果不佳。 原因有二:
- 第一个是因为 ClickHouse 没有很好的连接,即有连接,但它们很糟糕。 虽然不好。
- 第二个是表没有更新。 通常在星形电路周围的这些板中,需要进行一些更改。 例如,客户名称、公司名称等。 它不起作用。
在 ClickHouse 中有一个解决这个问题的方法。 甚至两个:
- 首先是字典的使用。 外部词典可以帮助 99% 解决星型模式、更新等问题。
- 二是数组的使用。 数组还有助于摆脱连接和规范化问题。

- 无需加入。
- 可升级。 自 2018 年 XNUMX 月以来,出现了一个未记录的机会(您不会在文档中找到它)来部分更新字典,即那些已更改的条目。 实际上,它就像一张桌子。
- 总是在内存中,所以与字典的连接比它是磁盘上的表更快,而且它还不是在缓存中的事实,很可能不是。

- 您也不需要加入。
- 这是一个紧凑的一对多表示。
- 在我看来,数组是为极客设计的。 这些是 lambda 函数等等。
这不是红色的字眼。 这是一个非常强大的功能,允许您以非常简单和优雅的方式做很多事情。

有助于求解数组的典型示例。 这些示例足够简单明了:
- 按标签搜索。 如果您在那里有主题标签并且想通过主题标签查找一些帖子。
- 按键值对搜索。 还有一些具有值的属性。
- 存储需要转换成其他内容的密钥列表。
所有这些任务都可以在没有数组的情况下解决。 标签可以放在某行中并使用正则表达式或在单独的表中选择,但是您必须进行连接。

而在 ClickHouse 中,你不需要做任何事情,为 hashtags 描述字符串数组或者为键值系统做一个嵌套结构就足够了。
嵌套结构可能不是最好的名字。 这两个数组在名称和一些相关特征上具有共同部分。
而且很容易按标签搜索。 有功能 has,它检查数组是否包含一个元素。 每个人,找到与我们会议相关的所有条目。
按 subid 搜索有点复杂。 我们需要先找到key的索引,然后取出有这个索引的元素,检查这个值是不是我们需要的。 但是,它非常简单紧凑。
如果将所有内容都放在一行中,您想要编写的正则表达式首先会很笨拙。 其次,它的工作时间比两个阵列长得多。

另一个例子。 您有一个存储 ID 的数组。 你可以把它们翻译成名字。 功能 arrayMap. 这是一个典型的 lambda 函数。 你在那里传递 lambda 表达式。 然后她从字典中提取每个 ID 的名称值。
可以用同样的方式进行搜索。 传递一个谓词函数来检查元素匹配的内容。

这些东西大大简化了电路,解决了一堆问题。
但我们面临的下一个问题是高效查询,我想提一下。
- ClickHouse 没有查询规划器。 绝对不。
- 尽管如此,仍然需要计划复杂的查询。 在哪些情况下?
- 如果查询中有多个连接,则将它们包装在子选择中。 它们的执行顺序很重要。
- 第二个 - 如果请求已分发。 因为在分布式查询中,只有最里面的 subselect 被分布式执行,其他所有内容都传递给您连接到的一台服务器并在那里执行。 因此,如果你有很多连接(join)的分布式查询,那么你需要选择顺序。
甚至在更简单的情况下,有时也需要做调度程序的工作并稍微重写查询。

这是一个例子。 左侧是显示前 5 个国家/地区的查询。 在我看来,这需要 2,5 秒。 在右侧,相同的查询,但略有重写。 我们不再按字符串分组,而是开始按键 (int) 分组。 而且速度更快。 然后我们将字典连接到结果。 该请求需要 2,5 秒,而不是 1,5 秒。 这很好。

重写过滤器的类似示例。 这是对俄罗斯的要求。 它运行 5 秒。 如果我们以这样一种方式重写它,即我们再次比较的不是字符串,而是与俄罗斯相关的一组键的数字,那么它会快得多。

有很多这样的技巧。 它们允许您显着加快您认为已经运行得很快,或者相反,运行缓慢的查询。 它们可以做得更快。

- 分布式模式下的最大工作量。
- 按最小类型排序,就像我按整数排序一样。
- 如果有任何连接(join),字典,那么最好将它们作为最后的手段,当你已经有至少部分分组的数据时,连接操作或字典调用将被调用更少的次数并且会更快.
- 更换过滤器。
还有其他技术,而不仅仅是我已经演示过的技术。 所有这些有时都可以显着加快查询的执行速度。

让我们继续下一个例子。 来自美国的X公司。 她在做什么?
有一个任务:
- 广告交易的离线链接。
- 对不同的绑定模型进行建模。

场景是什么?
例如,普通访问者每月通过不同的广告访问该网站 20 次,或者有时没有任何广告,因为他记得该网站。 查看一些产品,将它们放入篮子中,然后将它们从篮子中取出。 而且,最后,有些东西买了。
合理的问题:“如果有必要,谁应该支付广告费用?” 和“什么广告影响了他,如果有的话?”。 也就是说,他为什么要买,如何让像这个人这样的人也买?
为了解决这个问题,您需要以正确的方式将网站上发生的事件联系起来,即以某种方式在它们之间建立联系。 然后将它们发送到 DWH 进行分析。 并基于此分析,构建要展示谁和展示什么广告的模型。

广告交易是一组相关的用户事件,从显示广告开始,然后发生某些事情,然后可能是购买,然后可能是购买中的购买。 例如,如果这是一个移动应用程序或一个移动游戏,那么应用程序的安装通常是免费的,如果在那里做了一些事情,那么这可能需要钱。 一个人在应用程序中花费的越多,它就越有价值。 但是为此,您需要连接所有东西。

有许多绑定模型。
最受欢迎的是:
- 最后一次互动,其中互动是点击或展示。
- 第一次互动,即把人带到网站的第一件事。
- 线性组合 - 都相等。
- 衰减。
- 等等。
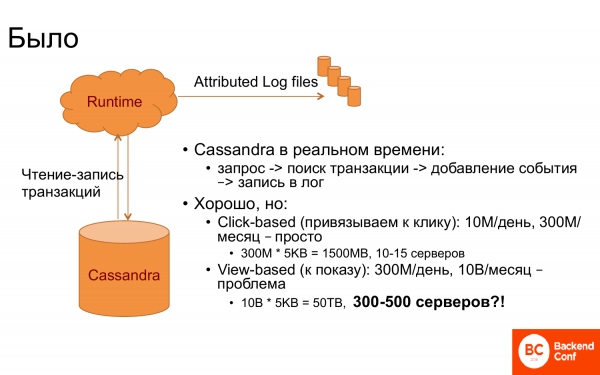
这一切最初是如何运作的? 有 Runtime 和 Cassandra。 Cassandra 被用作交易存储,即所有相关交易都存储在其中。 当运行时发生某些事件时,例如,显示某个页面或其他内容,然后向 Cassandra 发出请求 - 是否有这样的人。 然后获得了与之相关的交易。 并建立了联系。
如果幸运的是请求有一个事务 id,那就很容易了。 但通常没有运气。 因此,需要找到最后一笔交易或最后一次点击的交易等。
只要绑定到最后一次点击,这一切都非常有效。 因为如果我们设置一个窗口为一个月,那么每天有 10 万次点击,每月有 300 亿次点击。 而且由于在 Cassandra 中它必须全部在内存中才能快速运行,因为 Runtime 需要快速响应,因此大约需要 10-15 个服务器。
当他们想将交易链接到显示时,结果立即变得不那么有趣。 为什么? 可以看出需要存储30倍以上的事件。 因此,您需要多出 30 倍的服务器。 事实证明,这是某种天文数字。 为了进行链接而保留多达 500 台服务器,尽管运行时中的服务器要少得多,但这是某种错误的数字。 他们开始考虑该怎么做。

我们去了 ClickHouse。 以及如何在 ClickHouse 上进行? 乍一看,这似乎是一组反模式。
- 事务增长,我们将越来越多的事件连接到它,即它是可变的,而 ClickHouse 不能很好地处理可变对象。
- 当访客来找我们时,我们需要通过他的访问 ID 通过密钥提取他的交易。 这也是一个点查询,他们不会在 ClickHouse 中这样做。 通常 ClickHouse 有大...扫描,但这里我们需要获取一些记录。 也是一种反模式。
- 另外,交易是json的,但是他们不想重写,所以想把json非结构化的存储起来,如果有必要,再从里面拉出一些东西来。 这也是一种反模式。
即,一组反模式。
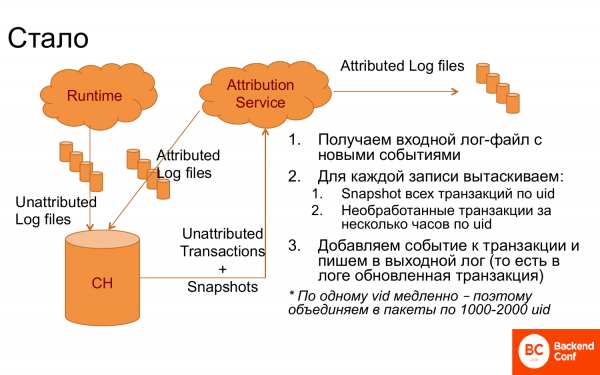
但尽管如此,事实证明它是一个运行良好的系统。
做了什么? ClickHouse 出现了,日志被扔进里面,分成记录。 出现了一个属性服务,它从 ClickHouse 接收日志。 之后,对于每个条目,通过访问 ID,我收到可能尚未处理的交易以及快照,即已经连接的交易,即先前工作的结果。 我已经从中得出逻辑,选择了正确的交易,连接了新事件。 再次登录。 日志返回到 ClickHouse,即它是一个不断循环的系统。 此外,我去了 DWH 在那里进行分析。
正是在这种形式下,它并没有很好地发挥作用。 为了让 ClickHouse 更容易,当有访问 ID 请求时,他们将这些请求分组为 1-000 个访问 ID 的块,并提取 2-000 人的所有交易。 然后一切都奏效了。
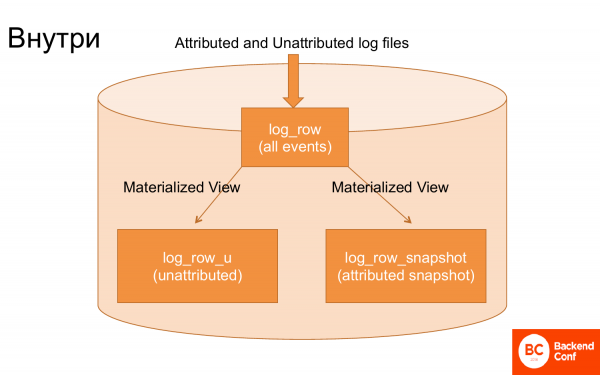
如果您查看 ClickHouse 内部,那么只有 3 个主表提供所有这些服务。
第一个上传日志的表,日志几乎不做任何处理就上传了。
第二张桌子。 通过物化视图,从这些日志中,尚未归因的事件,即不相关的事件,被咬掉了。 并通过物化视图,从这些日志中提取事务以构建快照。 也就是说,一个特殊的物化视图构建了一个快照,即事务的最后累积状态。
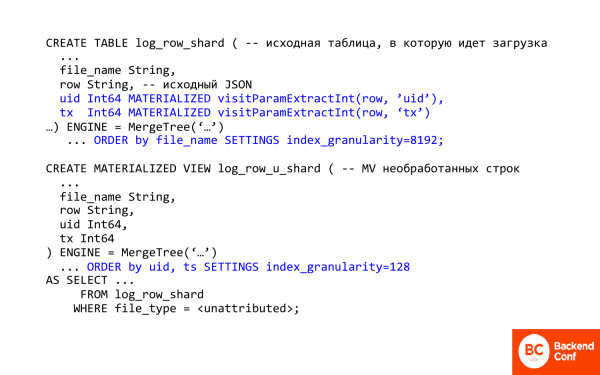
这是用 SQL 编写的文本。 我想评论其中的一些重要内容。
第一个重要的是能够从 ClickHouse 中的 json 中提取列和字段。 也就是说,ClickHouse 有一些处理 json 的方法。 他们非常非常原始。
visitParamExtractInt 允许您从 json 中提取属性,即第一个命中有效。 通过这种方式,您可以提取交易 ID 或访问 ID。 这次。
其次,这里使用了一个棘手的物化场。 这是什么意思? 这意味着你不能将它插入到表中,即它没有被插入,它是在插入时计算和存储的。 粘贴时,ClickHouse 会为您完成工作。 而你后面需要的已经从json中拉出来了。
在这种情况下,实体化视图用于原始行。 并且刚刚使用了第一个包含实际原始日志的表。 他是做什么的? 首先,它改变了排序,即现在按访问 id 排序,因为我们需要快速提取特定人的交易。
第二个重要的事情是 index_granularity。 如果你看过 MergeTree,默认情况下它通常是 8 index_granularity。 这是什么? 这是索引稀疏参数。 在 ClickHouse 中,索引是稀疏的,它从不索引每个条目。 它每 192 次执行一次。当需要计算大量数据时,这样做很好,但如果需要计算的数据很少,则不好,因为开销很大。 如果我们降低索引粒度,那么我们就减少了开销。 它不能减少到一个,因为可能内存不够。 索引始终存储在内存中。

Snapshot 还使用了一些其他有趣的 ClickHouse 功能。
首先,它是 AggregatingMergeTree。 而 AggregatingMergeTree 存储 argMax,即这是与最后一个时间戳对应的交易状态。 对于给定的访问者,交易一直在生成。 在这个交易的最后一个状态中,我们添加了一个事件,我们有了一个新状态。 它再次击中了 ClickHouse。 而通过这个物化视图中的argMax,我们总能得到当前状态。

- 绑定与运行时“解耦”。
- 每月存储和处理多达 3 亿笔交易。 这比在 Cassandra 中,即在典型的事务系统中,多了一个数量级。
- 2x5 ClickHouse 服务器集群。 5台服务器,每台服务器有一个副本。 这甚至比在 Cassandra 中进行基于点击的归因还要少,而这里我们使用的是基于印象的归因。 也就是说,他们没有将服务器数量增加 30 倍,而是设法减少了服务器数量。

最后一个例子是金融公司 Y,它分析了股票价格变化的相关性。
任务是:
- 大约有5股。
- 每 100 毫秒的报价是众所周知的。
- 这些数据已经积累了 10 多年。 显然,对一些公司来说更多,对一些公司来说更少。
- 总共大约有 100 亿行。
并且有必要计算变化的相关性。
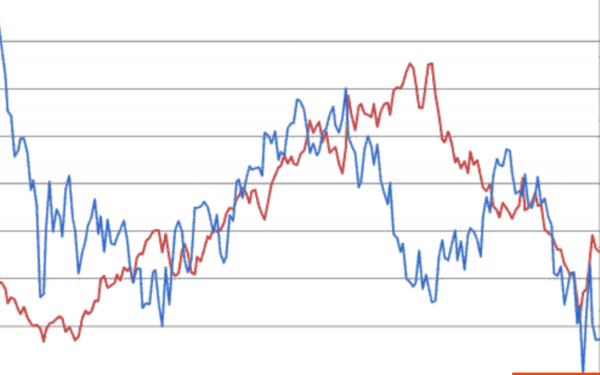
这是两只股票及其报价。 如果一个上升另一个上升,那么这是一个正相关关系,即一个上升另一个上升。 如果一个上升,如图所示,另一个下降,则这是负相关,即当一个上升时,另一个下降。
分析这些相互的变化,就可以对金融市场做出预测。

但任务艰巨。 正在为此做什么? 我们有 100 亿条记录:时间、股票和价格。 我们需要先计算出 100 亿次与价格算法的运行差值。 RunningDifference 是 ClickHouse 中的一个函数,可以顺序计算两个字符串之间的差异。
之后,您需要计算相关性,并且必须为每一对计算相关性。 对于 5 股,对是 000 万对。 这是很多,即需要计算这样一个相关函数的 12,5 倍。
如果有人忘记了,则͞x 和͞y 将死。 抽样期望。 也就是说,不仅需要计算根和和,还需要在这些和中再计算一个和。 一堆计算需要做12,5万次,还要按小时分组。 我们也有很多时间。 而且你必须在 60 秒内完成。 这是个笑话。

有必要至少以某种方式有时间,因为在 ClickHouse 出现之前,所有这些工作都非常非常缓慢。

他们试图在 Hadoop、Spark、Greenplum 上计算它。 而这一切都非常缓慢或昂贵。 也就是说,有可能以某种方式计算,但它很昂贵。
然后 ClickHouse 出现了,事情变得好多了。
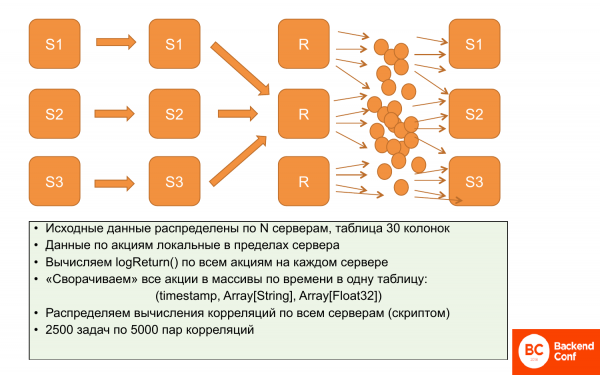
我提醒您,我们在数据本地化方面存在问题,因为相关性无法本地化。 我们不能把一些数据放在一台服务器上,一些放在另一台服务器上计算,我们必须让所有数据无处不在。
他们做了什么? 最初,数据是本地化的。 每个服务器都存储一组特定股票的定价数据。 而且它们不重叠。 因此,可以并行和独立地计算 logReturn,所有这些到目前为止都是并行和分布式发生的。
然后我们决定减少这些数据,同时不失去表现力。 减少使用数组,即对于每个时间段,制作一个股票数组和一个价格数组。 因此,它占用的数据空间要少得多。 而且它们更容易使用。 这些几乎是并行操作,即我们部分并行读取然后写入服务器。
之后,它可以被复制。 字母“r”表示我们复制了这些数据。 也就是说,我们在所有三台服务器上都有相同的数据——这些是数组。
然后使用需要计算的这组 12,5 万个相关性的特殊脚本,您可以制作包。 也就是说,具有 2 对相关性的 500 个任务。 而这个任务是要在特定的ClickHouse服务器上计算的。 他有所有的数据,因为数据是一样的,他可以依次计算。
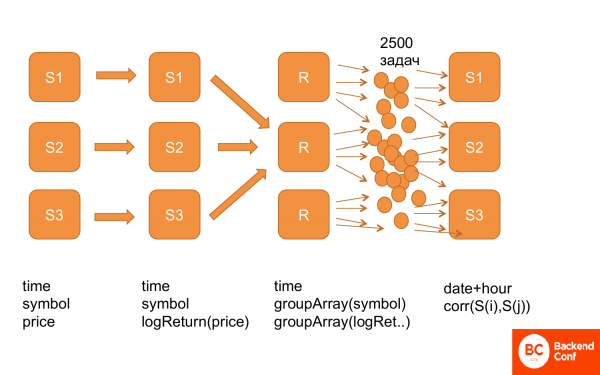
再一次,这就是它的样子。 首先,我们拥有此结构中的所有数据:时间、股票、价格。 然后我们计算 logReturn,即相同结构的数据,但我们已经有 logReturn 而不是价格。 然后他们被重做,即我们得到了时间和 groupArray 的股票和价格。 复制。 之后,我们生成了一堆任务并将它们提供给 ClickHouse,以便它对它们进行计数。 它有效。

在概念验证中,该任务是一个子任务,即使用的数据较少。 而且只有三台服务器。
前两个阶段:计算 Log_return 和包装在数组中大约需要一个小时。
而相关性的计算大约需要50个小时。 但 50 小时是不够的,因为他们过去常常工作数周。 这是一个巨大的成功。 如果你数一数,那么每秒 70 次所有东西都被计算在这个集群上。
但最重要的是这个系统几乎没有瓶颈,即它几乎是线性扩展的。 他们检查过了。 成功扩大规模。

- 正确的方案是成功的一半。 正确的方案是使用所有必要的 ClickHouse 技术。
- Summing/AggregatingMergeTrees 是允许您聚合或将状态快照视为特例的技术。 它极大地简化了很多事情。
- 物化视图允许您绕过一个索引限制。 可能我没说的很清楚,但是我们加载日志的时候,原始日志在一个索引的表中,属性日志在表中,即相同的数据,只是过滤,但是索引是完整的其他的。 好像是一样的数据,只是排序不同。 如果需要,实体化视图允许您绕过此类 ClickHouse 限制。
- 降低点查询的索引粒度。
- 并巧妙地分发数据,尽量将数据本地化在服务器内部。 并尽量确保请求也尽可能使用本地化。
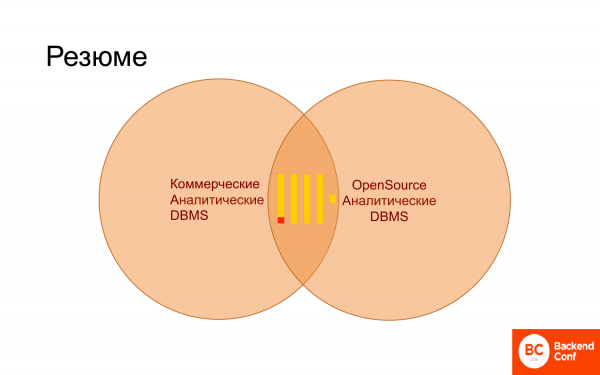
总结一下这个简短的演讲,我们可以说ClickHouse现在已经牢牢占据了商业数据库和开源数据库的领地,即专门用于分析。 他非常适合这片风景。 而且,它慢慢地开始排挤其他人,因为当您拥有 ClickHouse 时,您就不需要 InfiniDB。 如果 Vertika 提供正常的 SQL 支持,可能很快就不需要它们了。 享受!

- 感谢您的报告! 很有意思! 与 Apache Phoenix 有什么比较吗?
不,我还没有听到有人比较过。 我们和 Yandex 试图跟踪所有 ClickHouse 与不同数据库的比较。 因为如果突然发现某个东西比 ClickHouse 还快,那么 Lesha Milovidov 晚上会睡不着觉并开始快速加速。 我没有听说过这样的比较。
(Aleksey Milovidov) Apache Phoenix 是一个基于 Hbase 的 SQL 引擎。 Hbase主要针对key-value工作场景。 在每一行中,可以有任意数量的具有任意名称的列。 对于 Hbase、Cassandra 等系统,可以这样说。 正是繁重的分析查询对他们来说无法正常工作。 或者,如果您没有任何使用 ClickHouse 的经验,您可能会认为它们工作正常。
谢谢
下午好我已经对这个话题很感兴趣了,因为我有一个分析子系统。 但是看了ClickHouse,感觉ClickHouse很适合做事件分析,mutable。 而如果我需要用一堆大表来分析大量的业务数据,那么ClickHouse,据我了解是不是很适合我? 特别是如果他们改变了。 这是正确的还是有可以反驳这一点的例子?
这是对的。 大多数专业分析数据库都是如此。 它们是为一个或多个可变的大表以及许多变化缓慢的小表而量身定制的。 也就是说,ClickHouse 不像 Oracle,您可以在其中放置所有内容并构建一些非常复杂的查询。 为了有效地使用 ClickHouse,您需要以在 ClickHouse 中运行良好的方式构建方案。 即避免过度归一化,使用词典,尽量少做长链接。 并且如果以这种方式构建模式,那么类似的业务任务可以在 ClickHouse 上比在传统的关系数据库上更有效地解决。
感谢您的报告! 我有一个关于最新财务案例的问题。 他们有分析。 有必要比较一下它们是如何上升和下降的。 我知道你专门为这个分析构建了系统? 例如,如果明天他们需要关于此数据的一些其他报告,他们是否需要重新构建模式并上传数据? 也就是说,做某种预处理来获取请求?
当然,这是将 ClickHouse 用于一个非常具体的任务。 它可以更传统地在 Hadoop 中解决。 对于 Hadoop,这是一项理想的任务。 但是在 Hadoop 上它非常慢。 我的目标是证明 ClickHouse 可以解决通常通过完全不同的方式解决的任务,但同时更有效地完成它。 这是为特定任务量身定制的。 很明显,如果类似的东西有问题,那么可以用类似的方法解决。
天气晴朗。 你说处理了 50 个小时。 是从一开始,你什么时候加载数据或者得到结果?
是的,是的。
好的,非常感谢。
这是在一个 3 服务器集群上。
问候! 感谢您的报告! 一切都很有趣。 我不会问一点功能,而是在稳定性方面使用ClickHouse。 也就是说,你有没有,你必须恢复吗? 在这种情况下,ClickHouse 的行为如何? 碰巧你也有一个复制品吗? 例如,我们遇到了 ClickHouse 仍然超出其限制并下降的问题。
当然,没有理想的系统。 而ClickHouse也有自己的问题。 但是您是否听说过 Yandex.Metrica 长时间无法使用? 可能不会。 自 2012-2013 年以来,它一直在 ClickHouse 上可靠地工作。 我可以对我的经历说同样的话。 我们从未有过彻底的失败。 一些部分的事情可能会发生,但它们永远不会严重到严重影响业务的程度。 它从未发生过。 ClickHouse 非常可靠,不会随机崩溃。 你不必担心。 这不是一个原始的东西。 这已被许多公司证明。
你好! 您说您需要立即考虑数据模式。 如果它发生了怎么办? 我的数据不断涌入。 六个月过去了,我明白这样生活是不可能的,我需要重新上传数据并对它们做点什么。
这当然取决于您的系统。 有几种方法可以几乎不间断地做到这一点。 例如,您可以创建一个实体化视图,如果可以唯一映射,您可以在其中制作不同的数据结构。 也就是说,如果它允许使用 ClickHouse 进行映射,即提取一些东西,更改主键,更改分区,那么您可以制作物化视图。 在那里覆盖旧数据,新数据将自动写入。 然后切换到使用物化视图,然后切换记录并杀死旧表。 这通常是一种不间断的方法。
谢谢。
来源: habr.com
