

下午好我叫 Danil Lipovoy,我们 Sbertech 的团队开始使用 HBase 作为操作数据的存储。 在学习的过程中,积累了一些经验,我想将其系统化和描述(希望对很多人有用)。 以下所有实验均使用 HBase 版本 1.2.0-cdh5.14.2 和 2.0.0-cdh6.0.0-beta1 进行。
- 通用架构
- 将数据写入HBASE
- 从HBASE读取数据
- 数据缓存
- 批量数据处理MultiGet/MultiPut
- 将表拆分为区域的策略(拆分)
- 容错、压缩和数据局部性
- 设置和性能
- 压力测试
- 发现
1. 总体架构
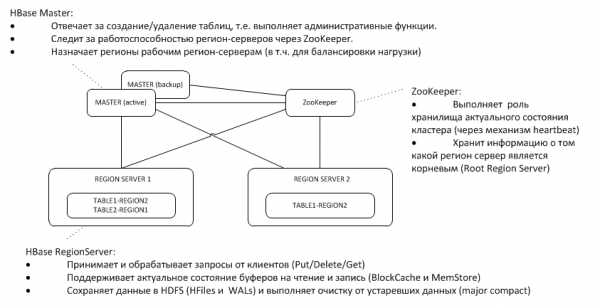
备份Master监听ZooKeeper节点上活动Master的心跳,并在主节点消失的情况下接管Master的功能。
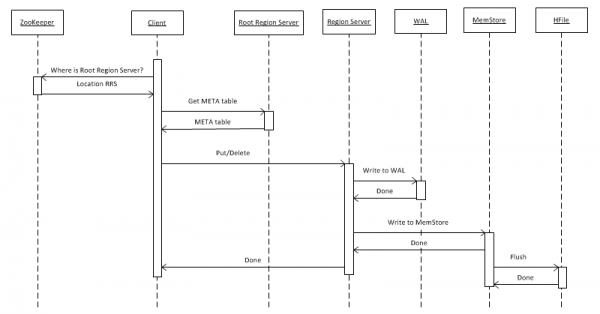
2.将数据写入HBASE
首先,让我们看一下最简单的情况 - 使用 put(rowkey) 将键值对象写入表。 客户端首先必须找出存储 hbase:meta 表的根区域服务器 (RRS) 所在的位置。 他从 ZooKeeper 接收此信息。 之后,它访问 RRS 并读取 hbase:meta 表,从中提取有关哪个 RegionServer (RS) 负责存储感兴趣表中给定行键的数据的信息。 为了将来使用,元表由客户端缓存,因此后续调用速度更快,直接到 RS。
接下来,RS 收到请求后,首先将其写入 WriteAheadLog (WAL),这是崩溃时恢复所必需的。 然后将数据保存到MemStore。 这是内存中的一个缓冲区,其中包含给定区域的一组排序键。 一个表可以分为多个区域(分区),每个区域都包含一组不相交的键。 这允许您将区域放置在不同的服务器上以获得更高的性能。 然而,尽管这个声明很明显,我们稍后会看到这并不适用于所有情况。
将条目放入 MemStore 后,将向客户端返回条目已成功保存的响应。 然而,实际上它只存储在缓冲区中,并且只有在经过一定时间或充满新数据后才会到达磁盘。
执行“删除”操作时,数据并未被物理删除。 它们被简单地标记为已删除,并且销毁本身发生在调用主要紧凑函数时,这在第 7 段中有更详细的描述。
HFile 格式的文件在 HDFS 中累积,并且不时启动较小的压缩进程,该进程只是将小文件合并为大文件,而不删除任何内容。 随着时间的推移,这变成了一个仅在读取数据时出现的问题(我们稍后会回到这个问题)。
除了上述加载过程之外,还有一个更有效的过程,这可能是该数据库最强大的一面 - BulkLoad。 它在于我们独立地形成 HFile 并将它们放在磁盘上,这使我们能够完美地扩展并获得非常不错的速度。 事实上,这里的限制不是HBase,而是硬件的能力。 下面是由 16 个 RegionServer 和 16 个 NodeManager YARN(CPU Xeon E5-2680 v4 @ 2.40GHz * 64 线程)、HBase 版本 1.2.0-cdh5.14.2 组成的集群上的启动结果。
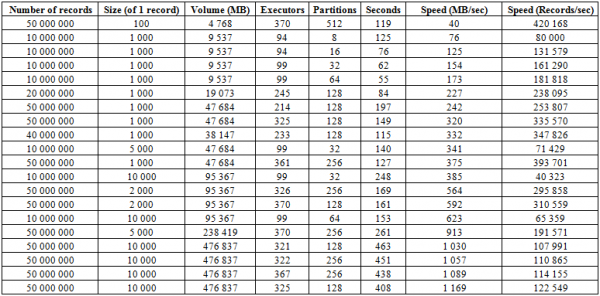
在这里您可以看到,通过增加表中分区(区域)的数量以及 Spark 执行器,我们获得了下载速度的提高。 此外,速度取决于录音音量。 在其他条件相同的情况下,大块会增加 MB/秒,小块会增加单位时间插入的记录数。
您还可以同时开始加载到两个表中并获得双倍的速度。 下面您可以看到,同时向两个表写入 10 KB 块的速度约为 600 MB/秒(总计 1275 MB/秒),这与写入一个表 623 MB/秒的速度一致(请参阅上面第 11 条)

但第二次运行50KB的记录时,下载速度略有增长,这表明它已经接近极限值。 同时,您需要记住,HBASE 本身几乎没有创建任何负载,所需要做的只是首先从 hbase:meta 提供数据,然后在排列 HFiles 后,重置 BlockCache 数据并保存MemStore 缓冲区到磁盘,如果不为空。
3.从HBASE读取数据
如果我们假设客户端已经拥有来自 hbase:meta 的所有信息(参见第 2 点),则请求将直接发送到存储所需密钥的 RS。 首先,在 MemCache 中执行搜索。 无论那里是否有数据,都会在 BlockCache 缓冲区中进行搜索,如果需要,还会在 HFile 中进行搜索。 如果在文件中找到数据,则会将其放置在 BlockCache 中,并在下一次请求时更快地返回。 由于使用了布隆过滤器,在 HFile 中搜索相对较快,即读取少量数据后,它会立即判断该文件是否包含所需的密钥,如果不包含,则转到下一个。
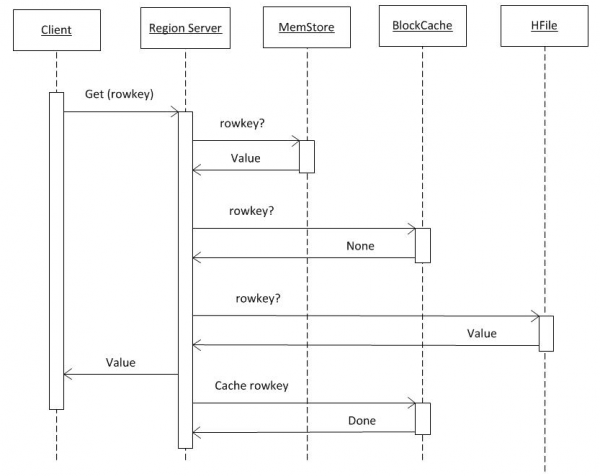
从这三个源接收到数据后,RS 生成响应。 特别是,如果客户端请求版本控制,它可以一次传输对象的多个找到的版本。
4.数据缓存
MemStore 和 BlockCache 缓冲区最多占用已分配堆上 RS 内存的 80%(其余部分保留给 RS 服务任务)。 如果典型的使用模式是进程写入并立即读取相同的数据,那么减少 BlockCache 并增加 MemStore 是有意义的,因为当写入数据没有进入缓存进行读取时,BlockCache 的使用频率会降低。 BlockCache 缓冲区由两部分组成:LruBlockCache(始终在堆上)和 BucketCache(通常在堆外或 SSD 上)。 当有大量读取请求且无法放入 LruBlockCache 时,应使用 BucketCache,这会导致垃圾收集器主动工作。 同时,您不应期望通过使用读取缓存来大幅提高性能,但我们将在第 8 段中返回这一点
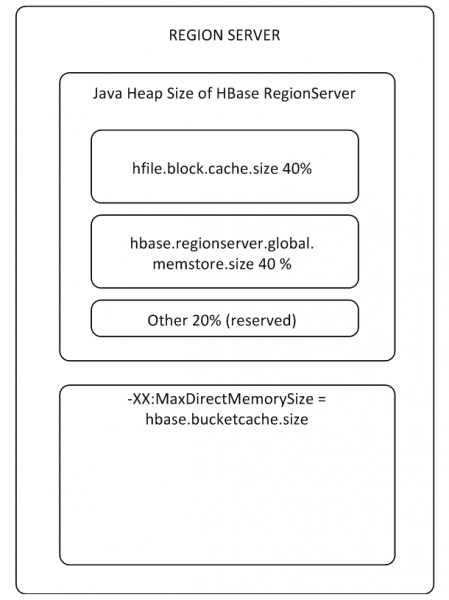
整个RS有一个BlockCache,每个表有一个MemStore(每个Column Family一个)。
如 理论上,写入时,数据不会进入缓存,实际上,表的 CACHE_DATA_ON_WRITE 参数和 RS 的“Cache DATA on Write”参数都设置为 false。 然而,在实践中,如果我们将数据写入MemStore,然后将其刷新到磁盘(从而清除它),然后删除生成的文件,那么通过执行get请求我们将成功接收数据。 此外,即使您完全禁用 BlockCache 并用新数据填充表,然后将 MemStore 重置到磁盘,删除它们并从另一个会话请求它们,它们仍然会从某个地方检索。 所以HBase存储的不仅仅是数据,还有神秘的奥秘。
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
“读取时缓存数据”参数设置为 false。 如果你有什么想法,欢迎在评论中讨论。
5.批量数据处理MultiGet/MultiPut
处理单个请求(Get/Put/Delete)是一项相当昂贵的操作,因此如果可能的话,您应该将它们组合成一个 List 或 List,这可以让您获得显着的性能提升。 对于写入操作尤其如此,但是在读取时存在以下陷阱。 下图显示了从 MemStore 读取 50 条记录的时间。 读取是在一个线程中执行的,横轴显示请求中的键数。 在这里您可以看到,当一个请求中增加到一千个键时,执行时间会下降,即速度增加。 但是,默认启用 MSLAB 模式,在此阈值之后,性能开始急剧下降,并且记录中的数据量越大,运行时间就越长。
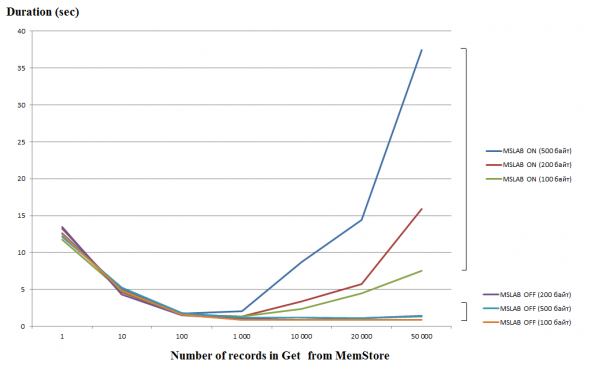
测试在虚拟机上进行,8核,版本HBase 2.0.0-cdh6.0.0-beta1。
MSLAB 模式旨在减少由于新旧代数据混合而产生的堆碎片。 作为一种解决方法,当启用 MSLAB 时,数据会被放入相对较小的单元(块)中并按块进行处理。 因此,当请求的数据包量超过分配的大小时,性能急剧下降。 另一方面,关闭此模式也是不可取的,因为它会导致在密集数据处理时由于 GC 而停止。 一个好的解决方案是在读取的同时通过 put 进行主动写入的情况下增加单元体积。 值得注意的是,如果在记录后运行flush命令(将MemStore重置到磁盘)或者使用BulkLoad加载,则不会出现该问题。 下表显示从 MemStore 查询较大(且相同数量)的数据会导致速度变慢。 然而,通过增加块大小,我们使处理时间恢复正常。
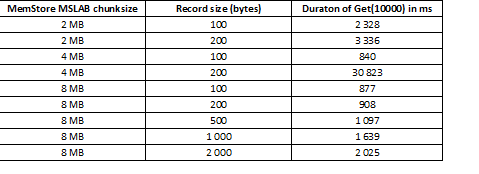
除了增加块大小之外,按区域分割数据也有帮助,即表分裂。 这会导致到达每个区域的请求减少,如果它们适合一个单元,则响应仍然良好。
6.表拆分为Region的策略(splitting)
由于HBase是键值存储,并且分区是按键进行的,因此将数据均匀地划分到所有区域是极其重要的。 例如,将这样的表分为三个部分将导致数据分为三个区域:
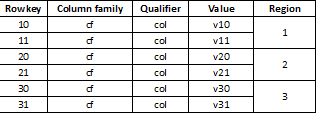
如果稍后加载的数据看起来像长值,其中大多数以相同的数字开头,那么这会导致速度急剧下降,例如:
1000001
1000002
...
1100003
由于键存储为字节数组,因此它们都将以相同的方式开始,并且属于存储该范围键的同一区域#1。 分区策略有以下几种:
HexStringSplit – 将密钥转换为“00000000”=>“FFFFFFFF”范围内的十六进制编码字符串,并在左侧填充零。
UniformSplit – 将密钥转换为十六进制编码的字节数组,范围为“00”=>“FF”,并在右侧填充零。
此外,您可以指定任何范围或一组键进行拆分并配置自动拆分。 然而,最简单和最有效的方法之一是 UniformSplit 和哈希连接的使用,例如通过 CRC32(rowkey) 函数运行密钥的最重要的字节对和 rowkey 本身:
哈希+行键
然后所有数据将均匀分布在各个区域。 读取时,前两个字节被简单地丢弃,原始密钥保留下来。 RS 还控制该区域中的数据和密钥量,如果超出限制,则会自动将其分解为多个部分。
7. 容错和数据局部性
由于只有一个区域负责每组密钥,因此与 RS 崩溃或退役相关的问题的解决方案是将所有必要的数据存储在 HDFS 中。 当 RS 失效时,Master 通过 ZooKeeper 节点上没有心跳来检测到这一点。 然后它将服务区域分配给另一个RS,并且由于HFile存储在分布式文件系统中,新所有者读取它们并继续提供数据。 但是,由于部分数据可能在MemStore中,没有时间进入HFiles,所以使用同样存储在HDFS中的WAL来恢复操作的历史记录。 应用更改后,RS 能够响应请求,但此举导致一些数据和为它们提供服务的进程最终位于不同的节点上,即局部性正在减弱。
问题的解决方案是主要压缩 - 该过程将文件移动到负责它们的节点(它们的区域所在的位置),因此在此过程中网络和磁盘上的负载急剧增加。 然而,在未来,数据的访问速度将显着加快。 此外,major_compaction 将一个区域内的所有 HFile 合并到一个文件中,并根据表设置清理数据。 例如,您可以指定必须保留的对象的版本数或物理删除该对象的生命周期。
这个过程可以对HBase的运行产生非常积极的影响。 下图显示了活动数据记录导致的性能下降情况。 在这里您可以看到 40 个线程如何写入一张表以及 40 个线程如何同时读取数据。 写入线程会生成越来越多的 HFile,这些 HFile 会被其他线程读取。 结果,越来越多的数据需要从内存中移除,最终 GC 开始工作,这几乎瘫痪了所有工作。 大规模压实的启动清除了由此产生的碎片并恢复了生产力。
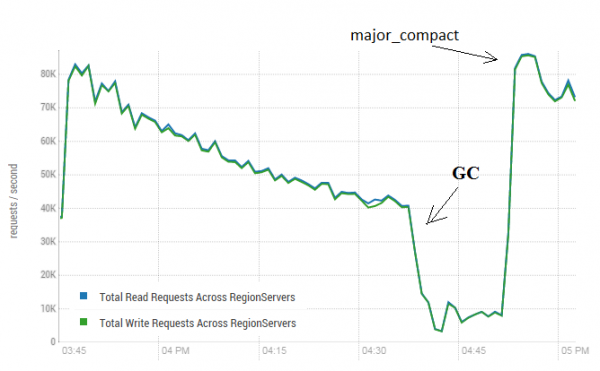
该测试在 3 个 DataNode 和 4 个 RS(CPU Xeon E5-2680 v4 @ 2.40GHz * 64 线程)上进行。 HBase版本1.2.0-cdh5.14.2
值得注意的是,主要压缩是在“实时”表上启动的,数据是主动写入和读取的。 网上有说法称这可能会导致读取数据时出现错误响应。 为了进行检查,启动了一个进程来生成新数据并将其写入表中。 然后我立即阅读并检查结果值是否与记录的值一致。 当这个过程运行时,主要压缩运行了大约 200 次,没有记录到一次失败。 也许这个问题很少出现,并且只在高负载期间出现,因此按计划停止写入和读取进程并执行清理以防止此类 GC 下降会更安全。
此外,主要压缩不会影响MemStore的状态;要将其刷新到磁盘并压缩它,您需要使用flush (connection.getAdmin().flush(TableName.valueOf(tblName)))。
8. 设置与性能
正如已经提到的,HBase 在执行 BulkLoad 时不需要执行任何操作,从而显示出其最大的成功。 然而,这适用于大多数系统和人。 然而,该工具更适合以大块的方式批量存储数据,而如果该过程需要多个竞争的读写请求,则使用上述的 Get 和 Put 命令。 为了确定最佳参数,使用表参数和设置的各种组合进行了启动:
- 10 个线程连续同时启动 3 次(我们称之为线程块)。
- 对一个块内所有线程的运行时间进行平均,即为该块运行的最终结果。
- 所有线程都使用同一个表。
- 在线程块的每次启动之前,都会执行一次主要压缩。
- 每个块仅执行以下操作之一:
-放
-得到
—获取+放置
- 每个块执行 50 次迭代操作。
- 记录的块大小为 100 字节、1000 字节或 10000 字节(随机)。
- 使用不同数量的请求密钥(10 个密钥或 XNUMX 个密钥)启动块。
- 这些块在不同的表设置下运行。 参数更改:
— BlockCache = 打开或关闭
— 块大小 = 65 KB 或 16 KB
— 分区 = 1、5 或 30
— MSLAB = 启用或禁用
所以该块看起来像这样:
A。 MSLAB 模式已打开/关闭。
b. 创建了一个表,并为其设置了以下参数:BlockCache = true/none、BlockSize = 65/16 Kb、Partition = 1/5/30。
C。 压缩设置为 GZ。
d. 同时启动 10 个线程,对该记录为 1/10/100 字节的表执行 1000/10000 put/get/get+put 操作,连续执行 50 个查询(随机键)。
e. d点重复XNUMX次。
F。 对所有线程的运行时间进行平均。
测试了所有可能的组合。 可以预见的是,速度会随着记录大小的增加而下降,或者禁用缓存会导致速度变慢。 然而,我们的目标是了解每个参数影响的程度和显着性,因此收集的数据被输入到线性回归函数的输入中,这使得可以使用 t 统计量评估显着性。 以下是块执行 Put 操作的结果。 全套组合 2*2*3*2*3 = 144 个选项 + 72 个 tk。 有些做了两次。 因此,总共有 216 次运行:
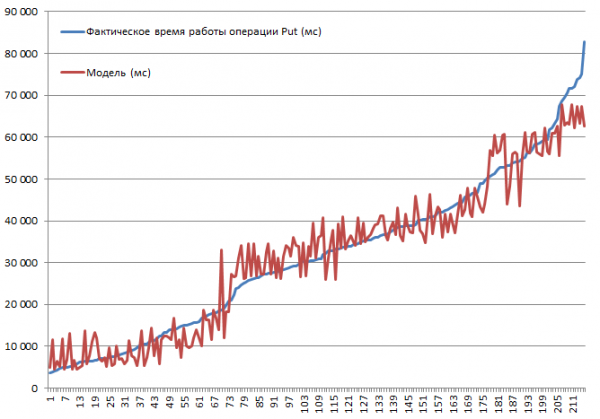
测试是在由 3 个 DataNode 和 4 个 RS(CPU Xeon E5-2680 v4 @ 2.40GHz * 64 线程)组成的迷你集群上进行的。 HBase 版本 1.2.0-cdh5.14.2。
关闭MSLAB模式,在一个分区的表上,启用BlockCache,BlockSize = 3.7,记录16字节,每包100条,最高插入速度为10秒。
最低插入速度为 82.8 秒,启用 MSLAB 模式,在一个分区的表上,启用 BlockCache,BlockSize = 16,记录 10000 字节,每条 1 条。
现在让我们看看模型。 我们看到基于 R2 的模型具有良好的质量,但绝对清楚的是,此处禁止外推。 参数变化时系统的实际行为不会是线性的;该模型不是用于预测,而是用于理解给定参数内发生的情况。 例如,这里我们从 Student 的标准中看到,BlockSize 和 BlockCache 参数对于 Put 操作并不重要(这通常是可以预测的):

但增加分区数量导致性能下降的事实有些出乎意料(我们已经看到了使用 BulkLoad 增加分区数量的积极影响),尽管可以理解。 首先,为了进行处理,您必须向 30 个区域(而不是 XNUMX 个)生成请求,并且数据量不足以产生收益。 其次,总运行时间由最慢的RS决定,并且由于DataNode的数量小于RS的数量,因此某些区域的局部性为零。 好吧,让我们看看前五名:

现在让我们评估执行 Get 块的结果:

分区的数量已经失去了意义,这可能是因为数据缓存良好并且读缓存是最重要的(统计上)参数。 当然,增加请求中的消息数量对于性能也非常有用。 最高分:

好吧,最后我们看一下先执行get然后put的block的模型:

所有参数在这里都很重要。 以及领导者的结果:

9.负载测试
好吧,最后我们将推出或多或少不错的负载,但当你有东西可以比较时,它总是更有趣。 Cassandra的主要开发商DataStax的网站上有 NT 的许多 NoSQL 存储,包括 HBase 版本 0.98.6-1。 加载采用40个线程,数据大小100字节,SSD磁盘。 测试读取-修改-写入操作的结果显示以下结果。
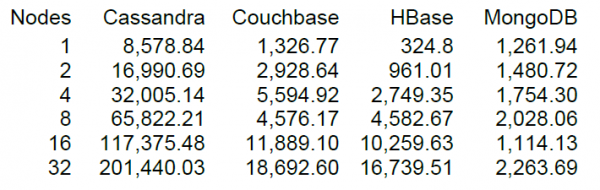
据我了解,读取是以100条记录为单位进行的,对于16个HBase节点,DataStax测试显示每秒10万次操作的性能。
幸运的是,我们的集群也有 16 个节点,但不太“幸运”的是每个节点有 64 个核心(线程),而在 DataStax 测试中只有 4 个。另一方面,他们有 SSD 驱动器,而我们有 HDD或更多新版本的 HBase 和负载期间的 CPU 利用率实际上并没有显着增加(视觉上增加了 5-10%)。 不过,让我们尝试开始使用此配置。 默认表设置,读取是在 0 到 50 万的键范围内随机执行的(即每次本质上都是新的)。 该表包含 50 万条记录,分为 64 个分区。 密钥使用 crc32 进行哈希处理。 表设置为默认设置,MSLAB 已启用。 启动 40 个线程,每个线程读取一组 100 个随机密钥,并立即将生成的 100 个字节写回这些密钥。
机架:16 个 DataNode 和 16 个 RS(CPU Xeon E5-2680 v4 @ 2.40GHz * 64 线程)。 HBase 版本 1.2.0-cdh5.14.2。
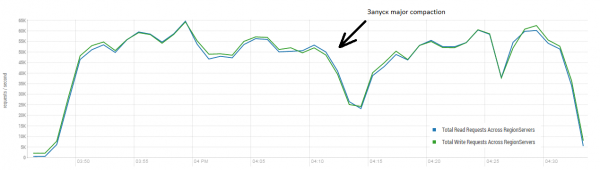
平均结果接近每秒 40 万次操作,明显优于 DataStax 测试。 但是,出于实验目的,您可以稍微更改条件。 所有工作不太可能只在一张表上执行,并且也仅在唯一键上执行。 我们假设有一组特定的“热”键生成主要负载。 因此,让我们尝试在 10 个不同的表中创建具有较大记录 (100 KB) 的负载,同样以 4 条为批次,并将请求的键的范围限制为 50。下图显示了启动 40 个线程,每个线程读取一组 100 个密钥,并立即在这些密钥上写入随机 10 KB。
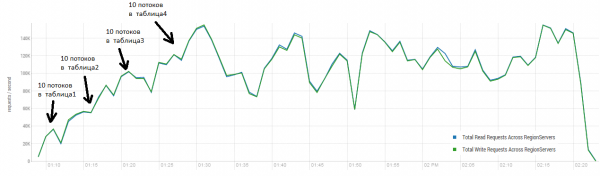
机架:16 个 DataNode 和 16 个 RS(CPU Xeon E5-2680 v4 @ 2.40GHz * 64 线程)。 HBase 版本 1.2.0-cdh5.14.2。
在加载过程中,会多次启动Major Compaction,如上图,如果没有这个过程,性能会逐渐下降,但执行过程中也会产生额外的负载。 亏损是由多种原因造成的。 有时线程完成工作并在重新启动时暂停,有时第三方应用程序在集群上创建了负载。
读和立即写是HBase最困难的工作场景之一。 如果只发出小的 put 请求,例如 100 个字节,将它们组合成 10-50 万块的包,每秒可以获得数十万次操作,情况与只读请求类似。 值得注意的是,结果比 DataStax 获得的结果要好得多,这主要是由于 50 万个块的请求。
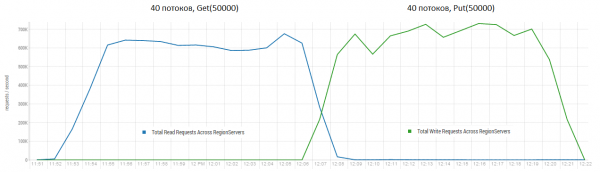
机架:16 个 DataNode 和 16 个 RS(CPU Xeon E5-2680 v4 @ 2.40GHz * 64 线程)。 HBase 版本 1.2.0-cdh5.14.2。
10。 发现
该系统配置相当灵活,但大量参数的影响仍然未知。 其中一些经过了测试,但未包含在最终的测试集中。 例如,初步实验表明 DATA_BLOCK_ENCODING 这样的参数意义不大,它使用相邻单元格的值对信息进行编码,这对于随机生成的数据来说是可以理解的。 如果您使用大量重复对象,增益可能会很大。 总的来说,我们可以说HBase给人的印象是一个相当严肃和经过深思熟虑的数据库,在对大数据块执行操作时可以非常高效。 特别是如果可以及时分离读取和写入过程。
如果您认为有什么披露得不够的地方,我愿意更详细地告诉您。 如果您不同意某些内容,我们邀请您分享您的经验或进行讨论。
来源: habr.com
