

Meta/Facebook(在俄罗斯联邦被禁止)推出了一种新的音频编解码器 EnCodec,它使用机器学习方法来提高压缩比而不损失质量。 该编解码器既可用于实时流式传输音频,也可用于编码以便稍后保存在文件中。 EnCodec 参考实现是使用 PyTorch 框架用 Python 编写的,并根据 CC BY-NC 4.0(知识共享署名-非商业)许可证获得许可,仅供非商业用途。
提供两个现成的模型可供下载:
- 使用 24 kHz 采样率的因果模型,仅支持单声道音频,并在不同的音频数据上进行训练(适合语音编码)。 该模型可用于打包音频数据,以 1.5、3、6、12 和 24 kbps 的比特率进行传输。
- 使用 48 kHz 采样率的非因果模型,支持立体声音频并仅针对音乐进行训练。 该型号支持 3、6、12 和 24 kbps 的比特率。
对于每个模型,都准备了一个额外的语言模型,这使您可以在不损失质量的情况下实现压缩比的显着提高(高达 40%)。 与之前开发的使用机器学习方法进行音频压缩的项目不同,EnCodec不仅可以用于语音打包,还可以用于采样率为48kHz的音乐压缩,对应音频CD的水平。 据新编解码器的开发人员称,与 MP64 格式相比,当以 3 kbps 的比特率传输时,他们能够将音频压缩程度提高约十倍,同时保持相同的质量水平(例如,当使用MP3,需要64kbps的带宽,在EnCodec中传输相同质量的6kbps就足够了)。
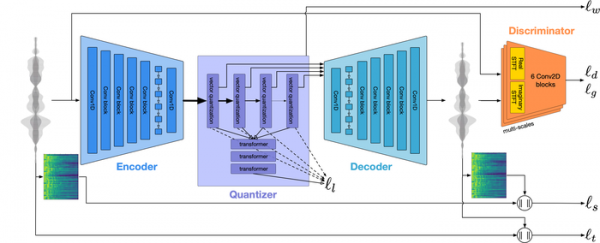
编解码器架构建立在具有“变压器”架构的神经网络之上,并基于四个链接:编码器、量化器、解码器和鉴别器。 编码器提取语音数据的参数并将其转换为较低帧速率的打包流。 量化器(RVQ,残差矢量量化器)将编码器输出的流转换为数据包集,并根据所选比特率压缩信息。 量化器的输出是数据的压缩表示,适合通过网络传输或保存到磁盘。
解码器对数据的压缩表示进行解码并重建原始声波。 考虑到人类听觉感知的模型,鉴别器提高了生成样本的质量。 无论质量和比特率水平如何,用于编码和解码的模型都具有相当适度的资源需求(实时操作所需的计算在单个 CPU 内核上执行)。
来源: opennet.ru
