


你好,我是 Sergey Elantsev,我開發 在 Yandex.Cloud 中。 此前,我領導了 Yandex 入口網站的 L7 平衡器的開發——同事開玩笑說,無論我做什麼,結果都是平衡器。 我將告訴 Habr 讀者如何管理雲端平台中的負載,我們認為實現這一目標的理想工具是什麼,以及我們如何建立這個工具。
首先,我們來介紹一些術語:
- VIP(虛擬IP)-平衡器IP位址
- 伺服器、後端、實例——運行應用程式的虛擬機
- RIP(真實IP)-伺服器IP位址
- Healthcheck - 檢查伺服器準備好
- 可用區,AZ - 資料中心內的隔離基礎設施
- 區域 - 不同可用區的聯合
負載平衡器解決三個主要任務:它們本身執行平衡,提高服務的容錯能力,並簡化其擴展。 透過自動流量管理確保容錯:平衡器監視應用程式的狀態,並將未通過活性檢查的實例排除在平衡之外。 透過在實例之間均勻分配負載以及動態更新實例清單來確保擴展。 如果平衡不夠均勻,某些實例將收到超出其容量限制的負載,並且服務將變得不太可靠。
負載平衡器通常根據其運行的 OSI 模型的協定層進行分類。 Cloud Balancer 在 TCP 層級運行,對應於第四層 L4。
讓我們繼續概述雲端平衡器架構。 我們將逐步提高細節水平。 我們將平衡器組件分為三類。 配置平面類別負責使用者互動並儲存系統的目標狀態。 控制平面儲存系統的當前狀態並管理資料平面類別的系統,資料平面類別直接負責將流量從客戶端傳遞到您的執行個體。
數據平面
流量最終到達稱為邊界路由器的昂貴設備。 為了提高容錯能力,多個此類設備在一個資料中心同時運作。 接下來,流量進入平衡器,平衡器透過 BGP 向客戶端宣布任播 IP 位址到所有可用區。
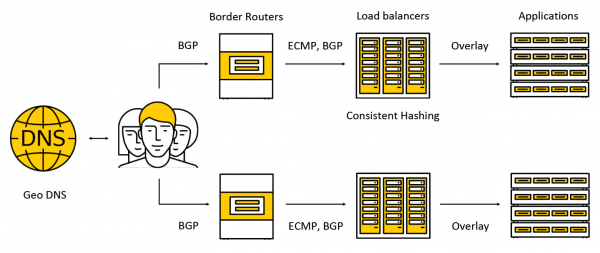
流量透過ECMP 傳輸- 這是一種路由策略,根據該策略,可以有多個同樣好的路由到達目標(在我們的例子中,目標將是目標IP 位址),並且封包可以沿著其中任何一個發送。 我們也根據以下方案支援多個可用區域的工作:我們在每個區域中公佈一個位址,流量流向最近的區域並且不會超出其限制。 在本文後面,我們將更詳細地了解流量發生的情況。
配置平面
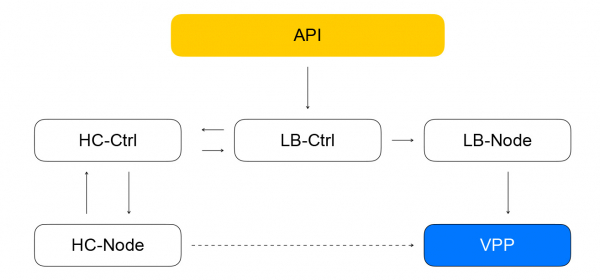
配置平面的關鍵元件是 API,透過它執行平衡器的基本操作:建立、刪除、更改實例的組成、取得健康檢查結果等。一方面,這是一個 REST API,另一方面另外,我們在雲端經常使用gRPC框架,所以我們將REST「翻譯」為gRPC,然後只使用gRPC。 任何請求都會導致創建一系列非同步冪等任務,這些任務在 Yandex.Cloud 工作執行緒的公共池上執行。 任務的編寫方式使得它們可以隨時暫停然後重新啟動。 這確保了操作的可擴展性、可重複性和日誌記錄。
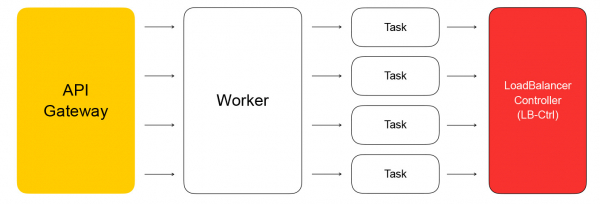
因此,來自 API 的任務將向平衡器服務控制器發出請求,該控制器是用 Go 編寫的。 它可以添加和刪除平衡器,更改後端和設定的組成。
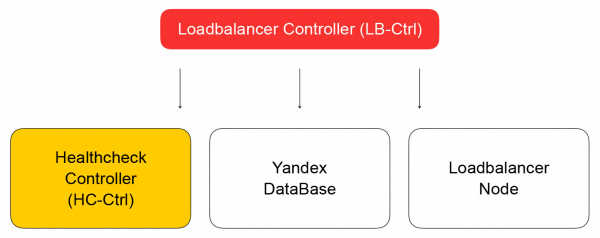
該服務將其狀態儲存在 Yandex 資料庫中,這是一個您很快就能使用的分散式託管資料庫。 在 Yandex.Cloud 中,正如我們已經 ,狗糧概念適用:如果我們自己使用我們的服務,那麼我們的客戶也會樂意使用它們。 Yandex 資料庫就是實現這一概念的一個範例。 我們將所有資料儲存在YDB中,我們不必考慮維護和擴展資料庫:這些問題都為我們解決了,我們將資料庫用作服務。
讓我們回到平衡器控制器。 它的任務是保存有關平衡器的信息,並向健康檢查控制器發送檢查虛擬機就緒情況的任務。
健康檢查控制器
它接收更改檢查規則的請求,將其保存在 YDB 中,在 healthcheck 節點之間分配任務並聚合結果,然後將結果儲存到資料庫並傳送到負載平衡器控制器。 反過來,它會向負載平衡器節點發送更改資料平面中叢集組成的請求,我將在下面討論。
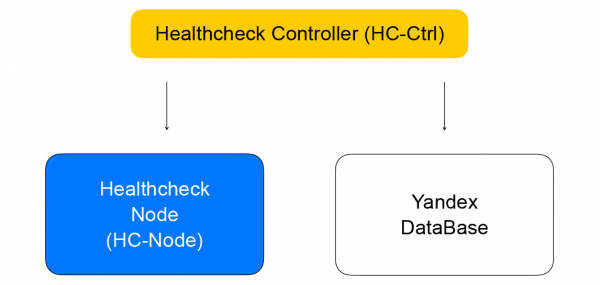
讓我們多討論健康檢查。 它們可以分為幾個類別。 審計有不同的成功標準。 TCP 檢查需要在固定時間內成功建立連線。 HTTP 檢查需要成功的連線和帶有 200 狀態碼的回應。
此外,檢查的作用類別也有所不同——它們是主動的和被動的。 被動檢查只是監視流量發生的情況,而不採取任何特殊操作。 這在 L4 上效果不太好,因為它取決於更高級別協議的邏輯:在 L4 上,沒有關於操作花費多長時間或連接完成是好還是壞的信息。 主動檢查需要平衡器向每個伺服器實例發送請求。
大多數負載平衡器都會自行執行活動檢查。 在 Cloud,我們決定將系統的這些部分分開以提高可擴展性。 這種方法將使我們能夠增加平衡器的數量,同時保持對服務的健康檢查請求的數量。 檢查由單獨的運行狀況檢查節點執行,檢查目標在這些節點上進行分片和複製。 您無法從一台主機執行檢查,因為它可能會失敗。 那我們就得不到他檢查的實例的狀態。 我們從至少三個運行狀況檢查節點對任何實例執行檢查。 我們使用一致的雜湊演算法來劃分節點之間檢查的目的。
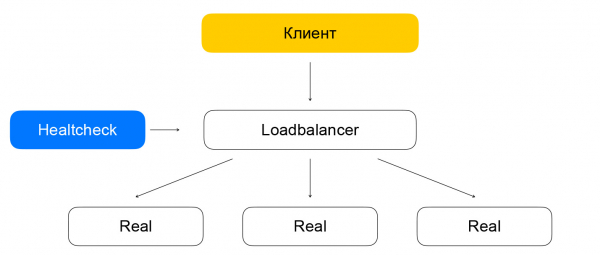
將平衡和健康檢查分開可能會導致問題。 如果健康檢查節點繞過平衡器(目前不為流量提供服務)向實例發出請求,則會出現奇怪的情況:資源似乎還活著,但流量不會到達它。 我們透過這種方式解決這個問題:我們保證透過平衡器啟動健康檢查流量。 換句話說,移動來自客戶端和健康檢查的流量的資料包的方案差異很小:在這兩種情況下,資料包都會到達平衡器,平衡器會將它們傳送到目標資源。
不同之處在於客戶端向 VIP 發出請求,而運行狀況檢查向每個單獨的 RIP 發出請求。 這裡出現了一個有趣的問題:我們為使用者提供了在灰色 IP 網路中建立資源的機會。 讓我們想像一下,有兩個不同的雲端擁有者將他們的服務隱藏在平衡器後面。 它們每個都在 10.0.0.1/24 子網路中擁有資源,並且具有相同的位址。 您需要能夠以某種方式區分它們,在這裡您需要深入了解 Yandex.Cloud 虛擬網路的結構。 最好在以下位置了解更多詳細信息 ,現在對我們來說很重要的是網路是多層的並且具有可以透過子網路id區分的隧道。
健康檢查節點使用所謂的準 IPv6 位址聯繫平衡器。 準位址是一個 IPv6 位址,其中嵌入了 IPv4 位址和使用者子網路 ID。 流量到達平衡器,平衡器從中提取 IPv4 資源位址,用 IPv6 取代 IPv4,並將封包傳送到用戶網路。
反向流量以同樣的方式進行:平衡器發現目的地是健康檢查器的灰色網絡,並將 IPv4 轉換為 IPv6。
VPP-資料平面的核心
平衡器是使用向量資料包處理 (VPP) 技術實現的,這是 Cisco 的一種用於批量處理網路流量的框架。 在我們的例子中,該框架在用戶空間網路設備管理庫-資料平面開發套件(DPDK)之上運作。 這確保了較高的資料包處理效能:核心中發生的中斷要少得多,並且在核心空間和使用者空間之間沒有上下文切換。
VPP 更進一步,透過將包裝組合成批次,從系統中榨取更多效能。 效能提升來自於現代處理器上快取的積極使用。 同時使用資料快取(資料包在「向量」中處理,資料彼此接近)和指令快取:在VPP中,資料包處理遵循圖表,其節點包含執行相同任務的函數。
例如,VPP中IP資料包的處理按照以下順序進行:首先,在解析節點中解析資料包頭,然後將它們傳送到該節點,該節點根據路由表進一步轉送資料包。
有點硬核。 VPP 的作者不容忍處理器快取使用方面的妥協,因此處理資料包向量的典型程式碼包含手動向量化:存在一個處理循環,其中處理「佇列中有四個資料包」的情況,然後兩個相同,然後-一個。 預取指令通常用於將資料載入到快取中,以加快後續迭代中對資料的存取速度。
n_left_from = frame->n_vectors;
while (n_left_from > 0)
{
vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
// ...
while (n_left_from >= 4 && n_left_to_next >= 2)
{
// processing multiple packets at once
u32 next0 = SAMPLE_NEXT_INTERFACE_OUTPUT;
u32 next1 = SAMPLE_NEXT_INTERFACE_OUTPUT;
// ...
/* Prefetch next iteration. */
{
vlib_buffer_t *p2, *p3;
p2 = vlib_get_buffer (vm, from[2]);
p3 = vlib_get_buffer (vm, from[3]);
vlib_prefetch_buffer_header (p2, LOAD);
vlib_prefetch_buffer_header (p3, LOAD);
CLIB_PREFETCH (p2->data, CLIB_CACHE_LINE_BYTES, STORE);
CLIB_PREFETCH (p3->data, CLIB_CACHE_LINE_BYTES, STORE);
}
// actually process data
/* verify speculative enqueues, maybe switch current next frame */
vlib_validate_buffer_enqueue_x2 (vm, node, next_index,
to_next, n_left_to_next,
bi0, bi1, next0, next1);
}
while (n_left_from > 0 && n_left_to_next > 0)
{
// processing packets by one
}
// processed batch
vlib_put_next_frame (vm, node, next_index, n_left_to_next);
}因此,健康檢查透過 IPv6 與 VPP 進行通信,VPP 將其轉換為 IPv4。 這是由圖中的節點完成的,我們稱之為演算法 NAT。 對於反向流量(以及從 IPv6 到 IPv4 的轉換),存在相同的演算法 NAT 節點。
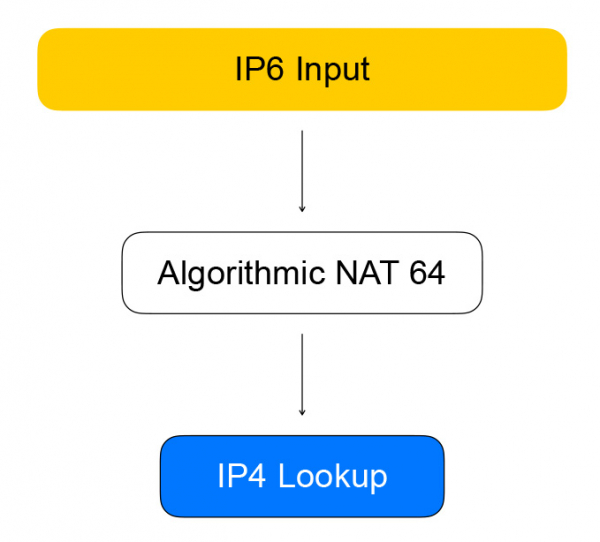
來自平衡器客戶端的直接流量通過圖節點,這些節點本身執行平衡。
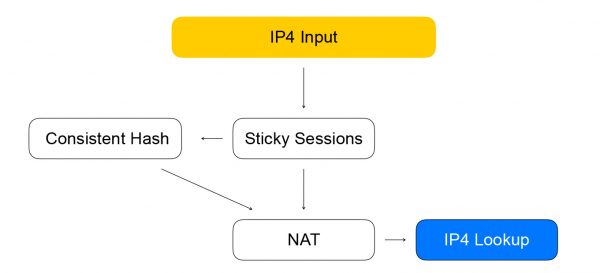
第一個節點是黏性會話。 它儲存的哈希值 對於已建立的會話。 五元組包括傳輸訊息的客戶端的位址和連接埠、可用於接收流量的資源的位址和連接埠以及網路協定。
五元組雜湊幫助我們在後續一致性雜湊節點中執行更少的計算,以及更好地處理平衡器後面的資源清單變化。 當沒有會話的封包到達平衡器時,它會被傳送到一致性哈希節點。 這是使用一致性雜湊進行平衡的地方:我們從可用的「即時」資源清單中選擇一個資源。 接下來,封包被傳送到 NAT 節點,該節點實際上會取代目標位址並重新計算校驗和。 正如你所看到的,我們遵循 VPP 的規則 - like to like,將相似的計算分組以提高處理器快取的效率。
一致的散列
我們為什麼選擇它?它到底是什麼? 首先,讓我們考慮前面的任務 - 從清單中選擇資源。
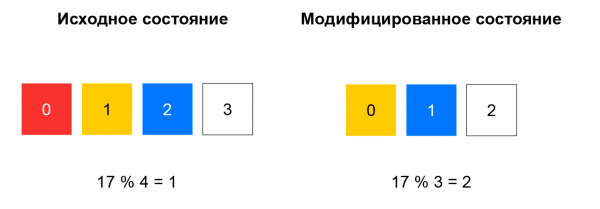
透過不一致散列,計算傳入資料包的雜湊,並透過該雜湊除以資源數量的餘數從清單中選擇資源。 只要列表保持不變,這個方案就可以正常工作:我們總是將具有相同 5 元組的資料包傳送到同一個實例。 例如,如果某些資源停止回應運行狀況檢查,那麼對於雜湊的很大一部分,選擇將會發生變化。 客戶端的 TCP 連線將中斷:先前到達執行個體 A 的資料包可能會開始到達執行個體 B,而實例 B 不熟悉該資料包的會話。
一致性哈希解決了所描述的問題。 解釋這個概念的最簡單方法是:假設您有一個環,您可以透過雜湊(例如,透過 IP:連接埠)向其分配資源。 選擇資源就是轉動輪子一個角度,該角度由資料包的雜湊值決定。
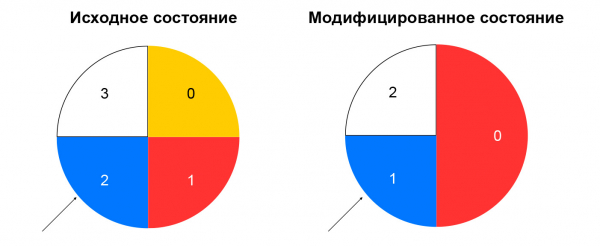
當資源組成發生變化時,這可以最大限度地減少流量重新分配。 刪除資源只會影響該資源所在的一致性雜湊環部分。 新增資源也會改變分佈,但是我們有一個黏性會話節點,它允許我們不將已經建立的會話切換到新資源。
我們研究了平衡器和資源之間引導流量時會發生什麼情況。 現在讓我們看看返回流量。 它遵循與檢查流量相同的模式 - 透過演算法 NAT,即透過反向 NAT 44 處理客戶端流量,透過 NAT 46 處理運行狀況檢查流量。 我們堅持自己的方案:我們統一健康檢查流量和真實用戶流量。
負載平衡器節點和組裝組件
VPP 中均衡器和資源的組成由本地服務 - loadbalancer-node 報告。 它訂閱來自負載平衡器控制器的事件流,並能夠繪製當前 VPP 狀態與從控制器接收的目標狀態之間的差異。 我們得到了一個封閉的系統:來自 API 的事件到達平衡器控制器,平衡器控制器將任務分配給健康檢查控制器以檢查資源的「活躍度」。 反過來,將任務分配給運行狀況檢查節點並聚合結果,然後將它們發送回平衡器控制器。 Loadbalancer-node 訂閱來自控制器的事件並更改 VPP 的狀態。 在這樣的系統中,每個服務只知道鄰近服務所需的內容。 連接數量有限,我們有能力獨立運作和擴展不同的細分市場。
避免了哪些問題?
我們控制平面中的所有服務都是用 Go 編寫的,具有良好的可擴展性和可靠性特徵。 Go 有許多用於建立分散式系統的開源程式庫。 我們積極使用 GRPC,所有元件都包含服務發現的開源實作 - 我們的服務監視彼此的效能,可以動態更改其組成,並且我們將其與 GRPC 平衡聯繫起來。 對於指標,我們也使用開源解決方案。 在數據層面,我們獲得了良好的性能和大量的資源儲備:事實證明,組裝一個可以依靠VPP而不是鐵網卡性能的支架是非常困難的。
問題與解決方案
是什麼效果不太好? Go有自動記憶體管理,但記憶體洩漏仍然會發生。 處理它們的最簡單方法是運行 goroutine 並記住終止它們。 重點:注意 Go 程式的記憶體消耗。 通常一個好的指標是 goroutine 的數量。 這個故事有一個優點:在 Go 中,很容易獲取運行時資料 - 記憶體消耗、運行的 goroutine 數量以及許多其他參數。
此外,Go 可能不是功能測試的最佳選擇。 它們相當冗長,「批量運行 CI 中的所有內容」的標準方法不太適合它們。 事實上,功能測試對資源的要求更高,並且會導致真正的逾時。 因此,測試可能會失敗,因為 CPU 正忙於單元測試。 結論:如果可能,將「繁重」測試與單元測試分開進行。
微服務事件架構比單體架構更複雜:收集數十台不同機器上的日誌並不是很方便。 結論:如果你製作微服務,請立即考慮追蹤。
我們的計劃
我們將推出內部平衡器、IPv6 平衡器,添加對Kubernetes 腳本的支持,繼續對我們的服務進行分片(目前僅對healthcheck-node 和healthcheck-ctrl 進行分片),添加新的健康檢查,並實現檢查的智慧聚合。 我們正在考慮使我們的服務更加獨立的可能性 - 以便它們不直接相互通信,而是使用訊息隊列。 雲端最近出現了與 SQS 相容的服務 .
最近,Yandex 負載平衡器公開發布。 探索 到服務中,以方便您的方式管理平衡器並提高專案的容錯能力!
來源: www.habr.com
