

如今,Bitrix24 服務沒有數百吉比特的流量,也沒有龐大的伺服器群組(當然,現有的伺服器數量相當多)。 但對許多客戶來說,它是公司工作的主要工具;它是真正的業務關鍵型應用程式。 所以,沒有辦法墮落。 如果崩潰確實發生了,但服務「恢復」得如此之快以至於沒有人注意到任何事情怎麼辦? 如何在不損失工作品質和客戶端數量的情況下實施故障轉移? Bitrix24 雲端服務總監 Alexander Demidov 在我們的部落格中談到了該產品存在 7 年以來預訂系統的演變。

「我們 24 年前推出了 Bitrix7 作為 SaaS。 主要困難可能在於:在作為 SaaS 公開推出之前,該產品只是以盒裝解決方案的形式存在。 客戶從我們這裡購買它,將其託管在他們的伺服器上,建立一個企業入口網站——一個用於員工溝通、文件儲存、任務管理、CRM 的通用解決方案,僅此而已。 到 2012 年,我們決定將其作為 SaaS 推出,自行管理,確保容錯性和可靠性。 我們一路走來累積了經驗,因為在那之前我們根本沒有經驗——我們只是軟體製造商,而不是服務提供者。
在推出服務時,我們明白最重要的是確保服務的容錯性、可靠性和持續可用性,因為如果你有一個簡單的普通網站,例如一個商店,它落在你身上並坐在那裡一個小時,只有你受苦,你失去了訂單,你失去了客戶,但是對於你的客戶本人來說,這對他來說並不是很關鍵。 當然,他很沮喪,但他去另一個網站買了它。 而如果這是一個將公司內部的所有工作、溝通、決策都捆綁在一起的應用程序,那麼最重要的就是獲得用戶的信任,也就是不讓他們失望,不讓他們跌倒。 因為如果內部的某些東西不起作用,所有的工作都會停止。
Bitrix.24 作為 SaaS
我們在公開發布前一年(即 2011 年)組裝了第一個原型。 我們花了大約一周的時間組裝它,查看它,旋轉它 - 它甚至可以工作。 也就是說,您可以進入表單,在其中輸入門戶的名稱,將開啟一個新門戶,並建立一個使用者群組。 我們看了它,原則上評估了這個產品,報廢了它,然後繼續完善它整整一年。 因為我們有一項艱鉅的任務:我們不想製作兩個不同的程式碼庫,我們不想支援單獨的打包產品、單獨的雲端解決方案 - 我們希望在一個程式碼中完成這一切。
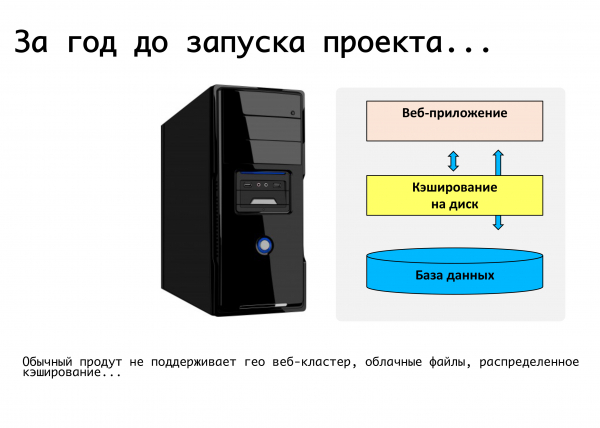
當時典型的 Web 應用程式是一台伺服器,運行一些 PHP 程式碼,一個 mysql 資料庫,上傳文件,將文件、圖片放在上傳資料夾中 - 好吧,這一切都有效。 可惜的是,使用它來啟動極為穩定的 Web 服務是不可能的。 在那裡,不支援分散式緩存,不支援資料庫複製。
我們制定了需求:這是能夠位於不同地點,支援複製,最好位於不同地理分佈的資料中心。 將產品邏輯與資料儲存分開。 能夠根據負載動態擴展,並完全容忍靜態。 事實上,從這些考慮出發,我們在這一年中對產品的要求進行了完善。 在此期間,在這個統一的平台上——對於盒裝解決方案,對於我們自己的服務——我們為我們需要的東西提供了支持。 在產品本身層面支援mysql複製:也就是說,編寫程式碼的開發人員不會考慮他的請求將如何分配,他使用我們的api,我們知道如何在master之間正確分配寫入和讀取請求和奴隸。
我們在產品層面對各種雲端物件儲存提供了支援:google storage、amazon s3,以及對 open stack swift 的支援。 因此,這對於我們作為服務的我們和使用打包解決方案的開發人員來說都很方便:如果他們只是使用我們的API 進行工作,他們不會考慮文件最終將保存在何處,在本地文件系統上還是在其他地方。在目標檔案儲存中。
於是,我們立即決定在整個資料中心層級進行預留。 2012 年,我們完全在亞馬遜 AWS 上推出,因為我們已經擁有該平台的經驗 - 我們自己的網站就託管在那裡。 我們被亞馬遜在每個地區都有多個可用區域這一事實所吸引- 事實上,(用他們的術語來說)多個數據中心或多或少彼此獨立,並允許我們在整個數據中心的級別上進行預留:如果突然發生故障,資料庫將進行主-主複製,備份 Web 應用程式伺服器,並將靜態資料移至 s3 物件儲存。 負載平衡-當時是由 Amazon elb 實現的,但不久之後我們就使用了自己的負載平衡器,因為我們需要更複雜的邏輯。
他們想要的就是他們得到的......
我們想要確保的所有基本事項——伺服器本身、Web 應用程式、資料庫的容錯能力——一切都運作良好。 最簡單的場景:如果我們的一個 Web 應用程式出現故障,那麼一切都很簡單 - 它們會關閉平衡。
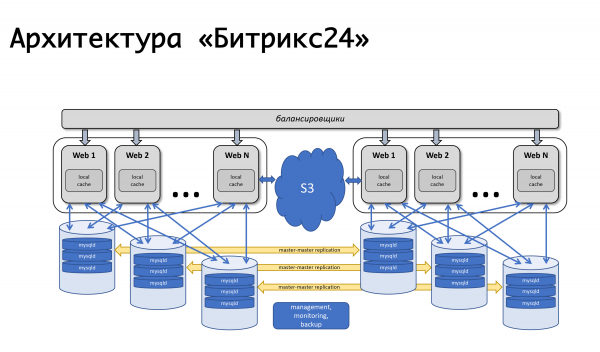
平衡器(當時是亞馬遜的 elb)將故障的機器標記為不健康,並關閉它們的負載分配。 亞馬遜自動擴展起作用了:當負載增長時,新機器被添加到自動擴展組中,負載被分配到新機器上 - 一切都很好。 對於我們的平衡器,邏輯大致相同:如果應用程式伺服器發生問題,我們會刪除其中的請求,丟掉這些機器,啟動新機器並繼續工作。 這些年來,該方案發生了一些變化,但仍然有效:它簡單、易於理解,而且沒有任何困難。
我們在世界各地工作,客戶負載峰值完全不同,並且,以友好的方式,我們應該能夠隨時對我們系統的任何組件進行某些服務工作 - 不被客戶注意到。 因此,我們有機會關閉資料庫的運行,將負載重新分配到第二個資料中心。
它是怎麼運作的? — 我們將流量切換到正在運行的資料中心- 如果資料中心發生事故,那麼完全如果這是我們計劃使用一個資料庫進行的工作,那麼我們將為這些客戶端提供服務的部分流量切換到第二個資料中心,暫停它複製。 如果由於第二個資料中心的負載增加而需要新機器用於 Web 應用程序,它們將自動啟動。 我們完成工作,恢復複製,然後返回整個負載。 如果我們需要在第二個 DC 中鏡像某些工作,例如安裝系統更新或更改第二個資料庫中的設置,那麼通常我們會重複相同的操作,只是在另一個方向上。 如果這是一個意外,那麼我們所做的一切都很簡單:我們使用監控系統中的事件處理程序機制。 如果觸發了多項檢查並且狀態變為嚴重,那麼我們將運行此處理程序,該處理程序可以執行此或那個邏輯。 對於每個資料庫,我們指定哪台伺服器是其故障轉移,以及如果不可用則需要切換流量。 從歷史上看,我們以一種或另一種形式使用 nagios 或其一些分叉。 原則上,幾乎所有監控系統中都存在類似的機制;我們還沒有使用任何更複雜的東西,但也許有一天我們會使用。 現在,監控是由不可用性觸發的,並且能夠切換某些內容。
我們已經預訂了一切嗎?
我們有很多來自美國的客戶,很多來自歐洲的客戶,還有很多靠近東方的客戶──日本、新加坡等。 當然,很大一部分客戶在俄羅斯。 也就是說,工作不在一個地區。 使用者想要快速回應,需要遵守各種當地法律,並且在每個區域內我們預留兩個資料中心,此外還有一些附加服務,這些服務同樣可以方便地放置在一個區域內 - 對於位於該地區正在發揮作用。 REST 處理程序、授權伺服器,它們對於整個客戶端的操作不太重要,您可以在可接受的較小延遲下切換它們,但您不想在如何監視它們以及做什麼方面重新發明輪子跟他們。 因此,我們試圖最大限度地利用現有的解決方案,而不是在其他產品中開發某種能力。 在某些地方,我們通常會在 DNS 層級使用切換,並透過相同的 DNS 來決定服務的活躍度。 Amazon 有 Route 53 服務,但它不僅僅是一個可以輸入條目的 DNS,僅此而已,它更加靈活和方便。 透過它,您可以使用地理位置建立地理分散式服務,當您使用它來確定客戶端來自哪裡並為其提供某些記錄時,您可以在它的幫助下建立故障轉移架構。 Route 53 本身也配置了相同的運作狀況檢查,您可以設定受監控的端點、設定指標、設定確定服務「活躍度」的協定 - tcp、http、https; 設定確定服務是否活動的檢查頻率。 在DNS 本身中,您可以指定什麼是主要的,什麼是次要的,如果在路由53 內觸發健康檢查,則在哪裡切換。所有這些都可以使用其他一些工具來完成,但為什麼它很方便-我們設定它啟動一次,然後完全不用考慮我們如何進行檢查、如何切換:一切都會自行運行。
第一個“但是”:如何以及用什麼來預訂 53 號公路本身? 誰知道,如果他出了什麼事呢? 幸運的是,我們從來沒有踩過這個耙子,但是,我會再講一個故事,解釋為什麼我們認為我們仍然需要預訂。 在這裡我們提前為自己鋪好了救命稻草。 我們每天多次徹底卸載 53 號公路上的所有區域。 亞馬遜的 API 允許您輕鬆地以 JSON 格式發送它們,我們有幾個備份伺服器,我們可以在其中轉換它,以配置的形式上傳它,並且粗略地說,有一個備份配置。 如果出現問題,我們可以快速手動部署,而不會遺失 DNS 設定資料。
第二個“但是”:這張圖裡的什麼東西還沒預訂? 平衡器本身! 我們按地區的客戶分佈變得非常簡單。 我們有網域 bitrix24.ru、bitrix24.com、.de - 現在有 13 個不同的域名,在不同的區域運作。 我們得出以下結論:每個地區都有自己的平衡器。 這使得跨區域分發更加方便,具體取決於網路上的尖峰負載所在的位置。 如果這是單一平衡器等級的故障,則只需將其停止服務並從 DNS 中刪除即可。 如果一組平衡器出現問題,則將它們備份到其他站點,並使用相同的路由在它們之間進行切換53,因為由於 TTL 較短,切換最多會在 2、3、5 分鐘內發生。
第三個“但是”: 什麼還沒保留? S3,正確。 當我們把為用戶儲存的檔案放在s3中時,我們真誠地相信它是穿甲彈的,不需要在那裡保留任何東西。 但歷史表明,事情的發生方式有所不同。 一般來說,Amazon 將S3 描述為基礎服務,因為Amazon 本身使用S3 來儲存機器鏡像、配置、AMI 鏡像、快照…而如果s3 崩潰了,就像這7 年來發生過一次,只要我們一直在使用bitrix24,它像粉絲一樣跟著它,出現了一大堆事情——無法啟動虛擬機器、api 故障等等。
S3 也可能崩潰──這種事曾經發生過一次。 因此,我們得出了以下方案:幾年前,俄羅斯還沒有真正的公共物件儲存設施,我們考慮了做一些我們自己的事情的選擇......幸運的是,我們沒有開始這樣做,因為我們會挖掘了我們沒有的專業知識,並且可能會搞砸。 現在 Mail.ru 擁有 s3 相容存儲,Yandex 擁有,許多其他提供者也擁有。 我們最終得出這樣的想法:首先,我們希望擁有備份,其次,能夠使用本地副本。 特別是對於俄羅斯地區,我們使用 Mail.ru Hotbox 服務,該服務的 API 與 s3 相容。 我們不需要對應用程式內部的程式碼進行任何重大修改,我們做了以下機制:在 s3 中有觸發器可以觸發物件的建立/刪除,Amazon 有一個名為 Lambda 的服務 - 這是程式碼的無伺服器啟動僅當觸發某些觸發器時才會執行。
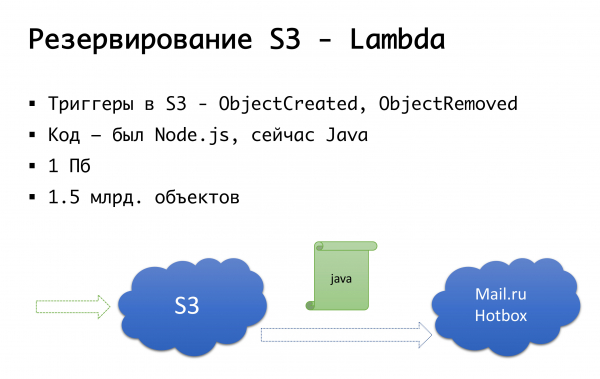
我們做得非常簡單:如果觸發器觸發,我們執行程式碼將物件複製到 Mail.ru 儲存。 為了全面啟動本地資料副本的工作,我們還需要反向同步,以便俄羅斯部分的客戶可以使用離他們更近的儲存。 郵件即將在其儲存中完成觸發器 - 將可以在基礎設施層級執行反向同步,但目前我們正在我們自己的程式碼層級執行此操作。 如果我們看到客戶端已發布文件,那麼在程式碼級別,我們將事件放入佇列中,對其進行處理並進行反向複製。 為什麼它不好:如果我們在產品之外對我們的物件進行某種工作,也就是說,透過某種外部手段,我們不會考慮它。 因此,我們等到最後,當觸發器出現在儲存層級時,這樣無論我們從哪裡執行程式碼,到達我們的物件都會被複製到另一個方向。
在代碼級別,我們為每個客戶端註冊兩個儲存:一個被視為主存儲,另一個被視為備份儲存。 如果一切順利,我們會使用離我們更近的儲存:也就是說,我們在亞馬遜的客戶,他們使用 S3,而那些在俄羅斯工作的客戶,他們使用 Hotbox。 如果該標誌被觸發,則應連接故障轉移,並且我們將用戶端切換到另一個儲存。 我們可以按區域單獨選取此框,並可以來回切換它們。 我們還沒有在實踐中使用它,但我們已經提供了這種機制,我們認為有一天我們會需要這個開關並派上用場。 這種情況已經發生過一次了。
哦,亞馬遜逃跑了…
今年四月是俄羅斯開始封鎖 Telegram 的周年紀念日。 受影響最嚴重的提供者是亞馬遜。 不幸的是,為全世界服務的俄羅斯公司遭受的損失更大。
如果公司是全球性的,而俄羅斯只是它的一小部分,3-5%——好吧,不管怎樣,你可以犧牲他們。
如果這是一家純粹的俄羅斯公司——我確信它需要在當地設立——那麼,這對用戶本身來說會很方便、舒適,而且風險也會更少。
如果這是一家在全球範圍內運營並且來自俄羅斯和世界各地的客戶數量大致相同的公司怎麼辦? 各個部分的連結很重要,它們必須以某種方式相互協作。
2018年3月下旬,俄羅斯聯邦通訊、資訊科技和大眾媒體監管局(Roskomnadzor)致函各大網路營運商,告知他們計畫封鎖數百萬個亞馬遜IP位址,以封鎖…Zello即時通訊軟體。多虧了這些運營商,他們成功地將這封信洩露給了所有人,亞馬遜的網路連線可能中斷的消息也隨之傳開。那天是星期五,我們驚慌失措地聯繫了servers.ru的同事,說:「朋友們,我們需要幾台不在俄羅斯,不在亞馬遜的伺服器上的伺服器,比如說在阿姆斯特丹的某個地方。」這樣我們至少可以想辦法在那裡搭建自己的伺服器。 VPN 對於某些我們無法控制的端點,例如 S3 端點,我們需要使用代理程式——我們不能嘗試設定新服務並取得不同的 IP 位址;我們仍然需要能夠存取它們。幾天之內,我們就配置了這些伺服器,讓它們運作起來,並且基本上做好了應對封鎖的準備。有趣的是,Roskomnadzor 在看到騷動和恐慌之後說:「不,我們現在沒有封鎖任何東西。」(但這話直到他們開始封鎖 Telegram 的那一刻才應驗。)在設置了繞過方案並意識到封鎖尚未實施之後,我們仍然決定不去深入調查。以防萬一。

而到了2019年,我們仍然活在封鎖的狀況下。 我昨晚看了一下:大約有20萬個IP繼續被封鎖。 確實,亞馬遜幾乎完全暢通無阻,在巔峰時期達到了 2 萬個地址……總的來說,現實是可能沒有連貫性,良好的連貫性。 突然。 由於技術原因,它可能不存在——火災、挖掘機等等。 或者,正如我們所見,這並不完全是技術性的。 因此,擁有自己的 AS 的大公司可能可以透過其他方式來管理它 - 直接連接和其他東西已經處於 l3 級別。 但在像我們這樣或更小的簡單版本中,為了以防萬一,您可以在其他地方提出的伺服器級別上有冗餘,提前配置VPN、代理,並能夠在這些段中快速將配置切換到它們這對於您的連接至關重要。 當亞馬遜開始封鎖時,這對我們來說不止一次派上用場;在最壞的情況下,我們只允許 SXNUMX 流量通過它們,但逐漸這一切都得到了解決。
如何預訂...整個提供者?
目前我們還沒有考慮到整個亞馬遜癱瘓的情況。 俄羅斯也有類似的情況。 在俄羅斯,我們由一家提供者託管,我們選擇從該提供者擁有多個站點。 一年前,我們面臨一個問題:即使這是兩個資料中心,供應商的網路配置層面可能已經存在問題,仍然會影響兩個資料中心。 我們最終可能在這兩個網站上都無法使用。 當然,這就是發生的事情。 我們最終重新考慮了內部的架構。 它沒有太大變化,但對於俄羅斯,我們現在有兩個站點,它們不是來自同一提供者,而是來自兩個不同的提供者。 如果其中一個失敗了,我們可以切換到另一個。
假設,對於亞馬遜,我們正在考慮在另一個提供者層級進行預訂的可能性; 也許是谷歌,也許是其他人……但到目前為止,我們在實踐中觀察到,雖然亞馬遜在一個可用區級別發生事故,但整個區域級別的事故卻相當罕見。 因此,我們理論上有可能會做出「亞馬遜不是亞馬遜」的預訂,但實際上並非如此。
關於自動化的幾句話
自動化總是必要的嗎? 這裡有必要回顧一下鄧寧-克魯格效應。 「x」軸是我們所獲得的知識和經驗,「y」軸是對我們行動的信心。 起初我們一無所知,也完全不確定。 然後我們知道一點,變得超級自信——這就是所謂的“愚蠢的頂峰”,“癡呆和勇氣”這幅畫很好地說明了這一點。 然後我們就學到了一些知識並準備好投入戰鬥。 然後我們犯了一些極其嚴重的錯誤,發現自己陷入了絕望的深淵,我們似乎知道一些事情,但實際上我們知道的並不多。 然後,當我們累積經驗時,我們會變得更有自信。
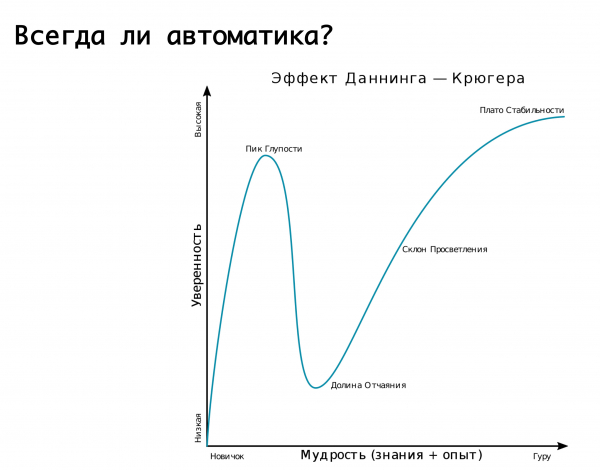
該圖很好地描述了我們對某些事故的各種自動切換的邏輯。 我們開始時——我們不知道如何做任何事情,幾乎所有的工作都是手工完成的。 然後我們意識到我們可以將自動化附加到一切事物上,就像安穩地睡覺一樣。 突然間,我們踩到了一個巨大的耙子:誤報被觸發,我們在我們不應該這樣做的時候來回切換流量。 結果,複製失敗或其他什麼——這就是絕望之谷。 然後我們認識到我們必須明智地對待一切。 也就是說,依賴自動化是有意義的,但有誤報的可能性。 但! 如果後果可能是毀滅性的,那麼最好將其留給值班人員,值班工程師,他們將確保並監控確實發生了事故,並將手動執行必要的操作...
結論
在七年的時間裡,我們從「當東西掉落時會出現恐慌」這一事實,轉變為認識到問題並不存在,只有任務,它們必須而且可以被解決。 當你建立一個服務時,從上面看它,評估所有可能發生的風險。 如果您立即看到它們,那麼請提前提供冗餘以及構建容錯基礎設施的可能性,因為任何可能發生故障並導致服務無法運行的點都肯定會發生這種情況。 即使您認為基礎設施的某些元素肯定不會失敗 - 就像同一個 s7,但仍然請記住它們可能會失敗。 至少在理論上,要知道如果確實發生了什麼事,你會如何處理它們。 制定風險管理計劃。 當您考慮自動或手動完成所有操作時,請評估風險:如果自動化開始切換所有操作會發生什麼 - 與事故相比,這不會導致更糟糕的情況嗎? 也許在某些地方,有必要在自動化的使用和值班工程師的反應之間進行合理的折衷,值班工程師將評估真實情況並了解是否需要當場切換某些內容或「是的,但不是現在」。
完美主義與真正的努力、時間、金錢之間的合理妥協,你可以花在你最終將擁有的計劃上。
本文是Alexander Demidov在會議上的報告的更新和擴展版本 .
來源: www.habr.com
