

2019年秋天,Mail.ru Cloud 的 iOS 團隊舉辦了一場期待已久的活動。對於行動世界來說,用於持久性儲存應用程式狀態的主資料庫已經變得相當奇特 (LMDB)。下面您將看到分為四個部分的詳細評論。首先,我們來談談做出如此重要且艱難的選擇的原因。然後我們將繼續考慮 LMDB 架構的三大支柱:記憶體映射檔案、B+ 樹、用於實現事務性和多版本控制的寫入時複製方法。最後,甜點——實踐部分。在其中,我們將考慮如何在低階鍵值 API 之上設計和實作包含索引在內的多個表的資料庫模式。
Содержание
3.1
3.2
3.3
4.1
4.2
4.3
1.實施動機
大約在 2015 年的某一天,我們開始擔心應用程式介面滯後頻率的指標。我們並不是就這樣去做的。我們收到越來越多的投訴,有時應用程式會停止響應用戶操作:按鈕無法點擊、列表無法滾動等。關於測量機制,我 在 AvitoTech 上,所以這裡我只給出數字的順序。
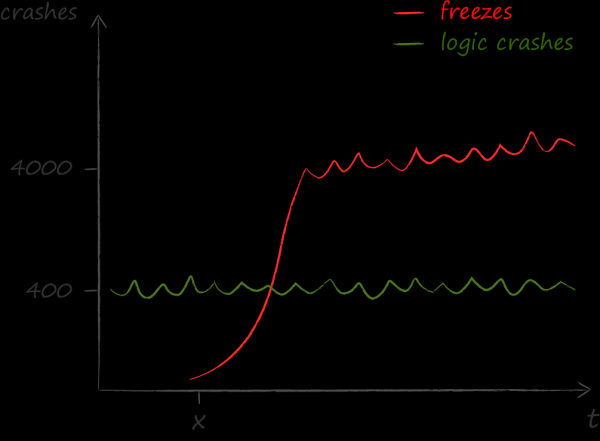
測量結果對我們來說無異於當頭一盆冷水。事實證明,凍結所導致的問題比其他任何問題都多。如果在意識到這一事實之前,品質的主要技術指標是無碰撞,那麼在關注之後 無凍結。
已建成 並且已經花費 и 分析原因後,主要的敵人就變得清晰起來——在應用程式的主線程中執行繁重的業務邏輯。對於這種恥辱的自然反應是強烈希望將其推入工作流程。為了有系統地解決這個問題,我們採用了基於輕量級參與者的多執行緒架構。我致力於讓它適應 iOS 世界。 在集體推特上 。在目前敘述的框架內,我想強調影響資料庫選擇的那些決策面向。
系統組織的參與者模型假設多執行緒成為其第二個本質。其中的模型物件喜歡跨越流邊界。而且他們不是偶爾、到處都這樣做,而是幾乎隨時隨地都這樣做。
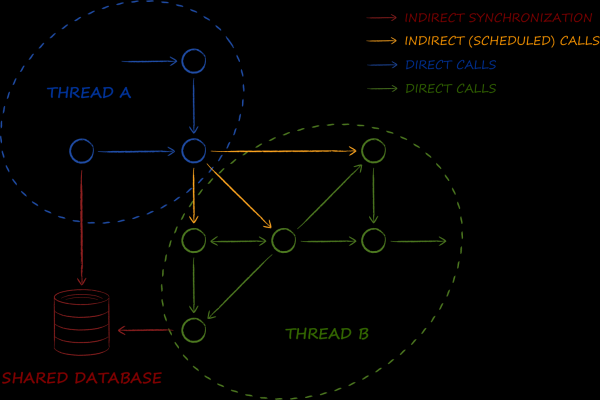
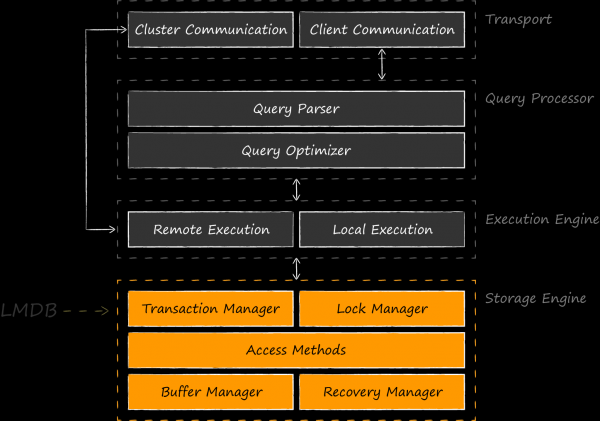
資料庫是圖中所示的基礎元件之一。其主要任務是實現宏觀模式。 。如果在企業世界中它用於組織服務之間的資料同步,那麼在參與者架構的情況下它用於組織執行緒之間的資料同步。因此,我們需要一個在多執行緒環境中使用時不會造成哪怕是最小困難的資料庫。具體來說,這意味著從中獲取的物件必須至少是線程安全的,並且理想情況下是完全不可變的。眾所周知,後者可以在多個線程中同時使用,而無需使用任何鎖,這對性能有益。
 影響資料庫選擇的第二個重要因素是我們的雲端 API。它的靈感來自於 git 所採用的同步方法。就像他一樣,我們的目標是 ,這看起來非常適合雲端客戶端。假設他們只會發布一次雲端的完整狀態,然後在絕大多數情況下透過推出變更來實現同步。不幸的是,這種可能性仍然只停留在理論層面,在實踐中,客戶還沒有學會如何使用補丁。造成這種情況的客觀原因有很多,為了不延誤介紹,我們將不予考慮。現在更令人感興趣的是,當 API 說「A」而其消費者沒有說「B」時會發生什麼,這是一個啟發性的教訓。
影響資料庫選擇的第二個重要因素是我們的雲端 API。它的靈感來自於 git 所採用的同步方法。就像他一樣,我們的目標是 ,這看起來非常適合雲端客戶端。假設他們只會發布一次雲端的完整狀態,然後在絕大多數情況下透過推出變更來實現同步。不幸的是,這種可能性仍然只停留在理論層面,在實踐中,客戶還沒有學會如何使用補丁。造成這種情況的客觀原因有很多,為了不延誤介紹,我們將不予考慮。現在更令人感興趣的是,當 API 說「A」而其消費者沒有說「B」時會發生什麼,這是一個啟發性的教訓。
因此,如果您想像一下 git,它在執行 pull 命令時不是將補丁應用到本地快照,而是將其完整狀態與完整伺服器狀態進行比較,那麼您將對雲端客戶端中同步的發生方式有一個相當準確的了解。很容易猜到,要實現它,需要在記憶體中分配兩棵 DOM 樹,其中包含有關所有伺服器和本地檔案的元資訊。事實證明,如果用戶在雲端中儲存了 500 萬個文件,那麼為了同步它,就需要重新創建和銷毀兩棵具有 1 萬個節點的樹。但每個節點都是一個包含子物件圖的聚合體。從這個角度來看,分析的結果是可以預期的。研究發現,即使不考慮合併演算法,創建和銷毀大量小物體的過程本身就花費了相當多的錢。大量使用者場景中包含基本同步操作,這使得情況更加惡化。因此,我們確定了選擇資料庫的第二個重要標準—無需動態分配物件即可實現 CRUD 操作的能力。
其他要求更為傳統,其完整清單如下。
- 線程安全。
- 多處理。希望使用相同的資料庫執行個體不僅在執行緒之間同步狀態,而且在主應用程式和 iOS 擴充功能之間同步狀態。
- 將儲存的實體表示為不可變物件的能力。
- CRUD 操作中沒有動態分配。
- 基本屬性的事務支持 :原子性、一致性、隔離性和可靠性。
- 最受歡迎案例的速度。
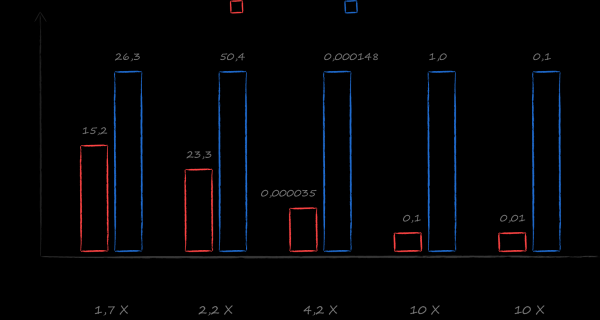
SQLite 過去是、現在仍然是滿足這組要求的好選擇。然而,在研究替代方案時,我偶然發現了一本書 。在她的領導下,編寫了一個基準,比較了在真實的雲端場景中使用不同資料庫的速度。結果超出了最瘋狂的預期。在最常見的情況下 - 取得所有檔案的排序清單和給定目錄的所有檔案的排序清單上的遊標 - LMDB 比 SQLite 快 10 倍。選擇變得顯而易見。
2. LMDB的定位
LMDB 是一個非常小的函式庫(只有 10K 行),實作了資料庫的最低基礎層 - 儲存。
上圖顯示,將 LMDB 與同樣實現更高層級的 SQLite 進行比較,通常不會比將 SQLite 與 Core Data 進行比較更正確。將相同的儲存引擎稱為同等競爭對手會更公平 - BerkeleyDB、LevelDB、Sophia、RocksDB 等。甚至還有 LMDB 充當 SQLite 的儲存引擎元件的開發。第一次這樣的實驗是在 2012 年 作者 LMDB . 事實證明,他的倡議非常有趣,得到了 OSS 愛好者的認可,並在 。 2020 年 XNUMX 月,本計畫作者 Den Shearer 他的 LinuxConfAu。
LMDB 的主要應用是作為應用程式資料庫的引擎。該圖書館的存在歸功於開發者 他們對使用 BerkeleyDB 作為其專案的基礎非常不滿意。從一間簡陋的圖書館開始 ,Howard Chu 能夠創造出我們這個時代最受歡迎的替代品之一。他為這個故事以及 LMDB 的內部結構貢獻了一份非常酷的報告。 。 Leonid Yuryev(又名 ) Positive Technologies 在 Highload 2015 大會上的報告中 。在其中,他在實現 ReOpenLDAP 的類似任務的背景下討論了 LMDB,而 LevelDB 則受到了比較批評。實施後,Positive Technologies 甚至有一個積極開發的分支 具有非常好的功能、優化和 .
LMDB 也經常被用作原樣儲存。例如,Mozilla Firefox 瀏覽器 它可以滿足各種需求,從版本 9 開始,Xcode 它的 SQLite 用於儲存索引。
該引擎也在行動開發領域佔有一席之地。其使用痕跡可以 在 Telegram 的 iOS 客戶端。 LinkedIn 甚至更進一步,選擇 LMDB 作為其自主研發的數據緩存框架 Rocket Data 的預設存儲,該框架 在他 2016 年的文章中。
在 BerkeleyDB 轉由 Oracle 控制後,LMDB 成功地在 BerkeleyDB 留下的市場中爭奪了一席之地。即使與同類圖書館相比,該圖書館也因其速度和可靠性而受到人們的喜愛。眾所周知,沒有免費的午餐,我想強調在 LMDB 和 SQLite 之間進行選擇時必須面對的權衡。上圖清楚地展示瞭如何實現速度的提升。首先,我們不需要為磁碟儲存之上的額外抽象層付費。當然,在一個好的架構中無論如何都離不開它們,它們不可避免地會出現在應用程式程式碼中,但它們會更加微妙。它們不會具有特定應用程式不需要的功能,例如對 SQL 查詢的支援。其次,可以最佳地實現應用程式操作到磁碟儲存請求的對應。如果 SQLite 是基於一般應用程式的平均需求,那麼身為應用程式開發人員您很清楚主要的負載場景。更有效率的解決方案將需要增加初始解決方案的開發及其後續支援的價格。
3. LMDB 的三大支柱
從鳥瞰視角看完 LMDB 之後,是時候進行更深入的了解了。接下來的三節將致力於分析儲存架構所基於的主要支柱:
- 記憶體映射檔案作為處理磁碟和同步內部資料結構的機制。
- B+樹作為儲存資料的結構的組織。
- 寫入時複製是確保事務和多版本 ACID 屬性的方法。
3.1.鯨魚#1。記憶體映射文件
記憶體映射檔案是一種非常重要的架構元素,它們甚至出現在儲存名稱中。快取和對儲存資訊的存取同步問題完全留給作業系統處理。 LMDB 本身不包含任何快取。這是作者的深思熟慮的決定,因為直接從映射文件讀取資料可以在引擎實作中使用許多快捷方式。以下是其中一些的遠非完整的列表。
- 當多個進程使用儲存資料時,維護儲存中資料的一致性成為作業系統的責任。下一節將透過圖片詳細分析此機制。
- 沒有快取就完全消除了與 LMDB 中的動態分配相關的開銷。實際上,讀取資料只是將指標設定到虛擬記憶體中的正確位址,僅此而已。這聽起來像是科幻小說,但在儲存庫來源中,所有 calloc 呼叫都集中在儲存庫配置函數中。
- 缺少快取也意味著缺少與其存取同步相關的鎖定。讀取器(可以同時存在任意數量的讀取器)在讀取資料的途中不會遇到單一互斥鎖。因此,讀取速度與 CPU 數量具有理想的線性可擴展性。在 LMDB 中,僅同步修改操作。任何給定時間只能有一名作者。
- 最少的快取和同步邏輯使程式碼擺脫了在多執行緒環境中工作時產生的極其複雜類型的錯誤。 Usenix OSDI 2014 會議上有兩個有趣的資料庫研究: и 。從中,我們可以了解到 LMDB 前所未有的可靠性以及幾乎完美地實現事務的 ACID 屬性,超越了相同的 SQLite。
- LMDB 的極簡主義允許其程式碼的機器表示完全位於處理器的 L1 快取中,從而具有速度特性。
不幸的是,在 iOS 中,記憶體映射檔案的情況並不像我們想像的那麼樂觀。為了更有意識地談論相關的缺點,有必要回顧一下在作業系統中實現這種機制的一般原則。
有關內存映射文件的一般信息
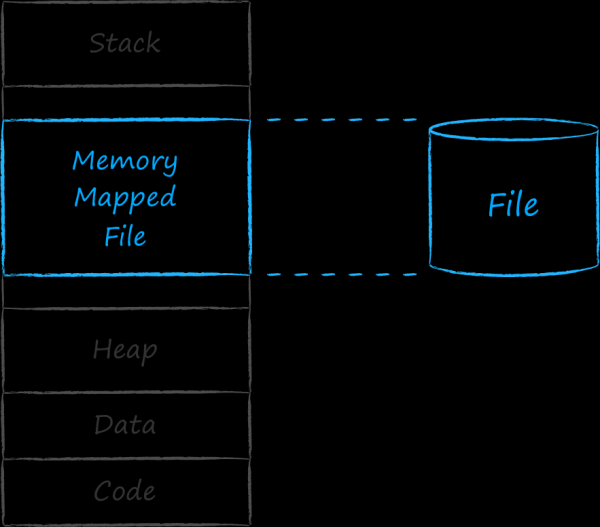 對於每個正在運行的應用程序,作業系統都會關聯一個稱為進程的實體。每個進程都被分配了一個連續的位址範圍,它將運行所需的一切放置在其中。最低地址包含代碼和硬編碼資料和資源的部分。接下來是向上增長的動態位址空間區塊,也就是我們所知的堆。它包含程式運行期間出現的實體的位址。最上面是應用程式堆疊使用的記憶體區域。它會增長和縮小,換句話說,它的尺寸也具有動態性。為了防止堆疊和堆疊互相推送和乾擾,它們位於位址空間的不同端。頂部和底部的兩個動態部分之間有一個孔。作業系統使用中間部分的位址將各種實體與進程關聯起來。具體來說,它可以將磁碟上的檔案與一組特定的連續位址關聯起來。這樣的檔案稱為記憶體映射檔。
對於每個正在運行的應用程序,作業系統都會關聯一個稱為進程的實體。每個進程都被分配了一個連續的位址範圍,它將運行所需的一切放置在其中。最低地址包含代碼和硬編碼資料和資源的部分。接下來是向上增長的動態位址空間區塊,也就是我們所知的堆。它包含程式運行期間出現的實體的位址。最上面是應用程式堆疊使用的記憶體區域。它會增長和縮小,換句話說,它的尺寸也具有動態性。為了防止堆疊和堆疊互相推送和乾擾,它們位於位址空間的不同端。頂部和底部的兩個動態部分之間有一個孔。作業系統使用中間部分的位址將各種實體與進程關聯起來。具體來說,它可以將磁碟上的檔案與一組特定的連續位址關聯起來。這樣的檔案稱為記憶體映射檔。
分配給進程的位址空間巨大。理論上,位址的數量僅受指標大小的限制,而指標的大小則由系統的位元深度決定。如果將其 1:1 映射到實體內存,則第一個進程將耗盡所有 RAM,並且不會有任何多任務處理。
然而,根據我們的經驗,我們知道現代作業系統可以同時執行任意數量的進程。這是可能的,因為它們只在紙面上為進程分配大量內存,但實際上它們只將當前需要的部分加載到主物理內存中。因此,與進程相關的記憶體被稱為虛擬的。
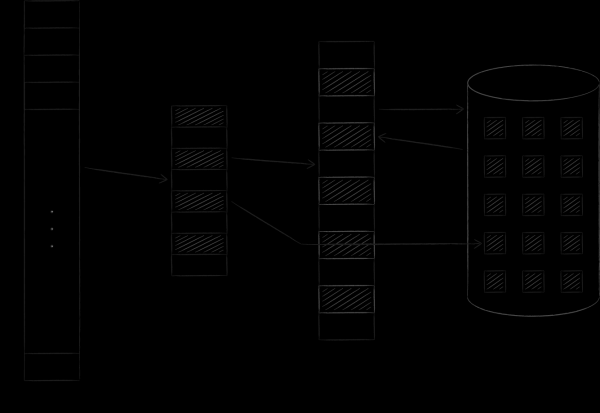
作業系統將虛擬記憶體和實體記憶體組織成一定大小的頁面。一旦需要虛擬記憶體頁面,作業系統就會將其載入到實體記憶體中並將其對應到特殊的表中。如果沒有空閒槽,則將先前載入的頁面之一複製到磁碟,並用所需頁面取代它。我們很快就會回到這個過程,它被稱為交換。下圖說明了所描述的過程。在其中,位址為 0 的頁面 A 被載入並放置在位址為 4 的主記憶體頁面上。這一事實反映在單元號 0 的對應表中。
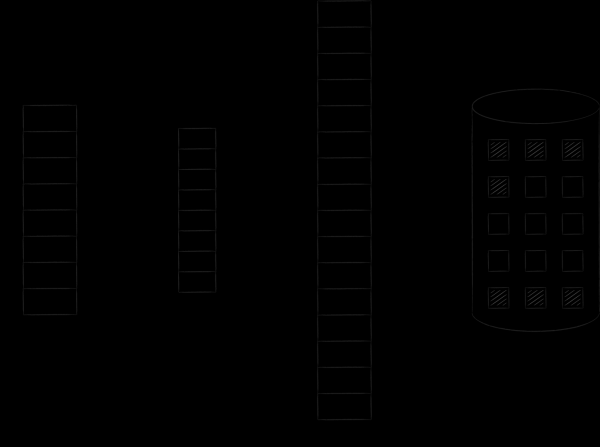
記憶體映射檔案的情況完全相同。從邏輯上講,它們應該連續且完整地位於虛擬位址空間中。但是,它們只是按需一頁一頁地進入實體記憶體。此類頁面的修改與磁碟上的檔案同步。這樣,您只需處理記憶體中的位元組即可執行檔案 I/O,並且所有變更都將由作業系統核心自動傳輸到原始檔案。
下圖示範了 LMDB 在從不同進程處理資料庫時如何同步其狀態。透過將不同進程的虛擬記憶體映射到同一個文件,我們實際上迫使作業系統以傳遞方式同步其位址空間的某些區塊,這就是 LMDB 所尋找的地方。
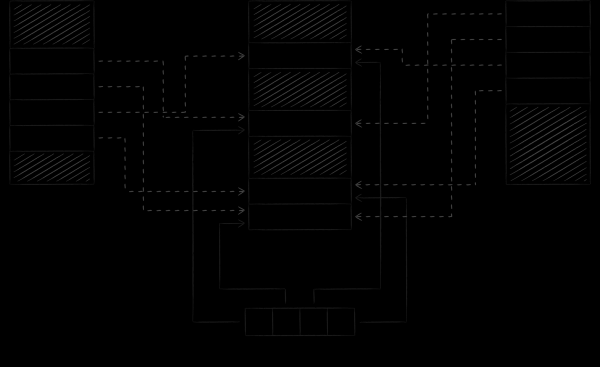
一個重要的細微差別是,LMDB 預設透過寫入系統呼叫機制修改資料文件,並以唯讀模式顯示文件本身。這種方法有兩個重要意義。
第一個後果對於所有作業系統來說都是共同的。其本質是增加對資料庫的保護,防止不正確的程式碼對資料庫造成意外的損壞。眾所周知,進程的可執行指令可以自由存取其位址空間中任何地方的資料。同時,正如我們剛剛記得的,以讀寫模式顯示檔案意味著任何指令也可以修改它。如果她錯誤地執行了此操作,例如,實際上試圖覆蓋不存在的索引處的數組元素,她可能會意外更改映射到該地址的文件,從而損壞資料庫。如果檔案以唯讀模式顯示,則嘗試變更相應的位址空間將導致程式異常終止並發出訊號 SIGSEGV,並且文件將保持不變。
第二個後果已經是特定於 iOS。作者或任何其他來源都沒有明確提及它,但如果沒有它,LMDB 將無法在該行動作業系統上使用。下一節將對此進行討論。
iOS 中記憶體映射檔案的具體內容
2018 年 WWDC 上有一個精彩的演講 。它解釋說,在 iOS 中,位於實體記憶體中的所有頁面都被分為以下三種類型之一:髒的、壓縮的和乾淨的。

乾淨記憶體是可以從實體記憶體中安全卸載的頁面的集合。其中包含的資料可以根據需要從其原始來源重新載入。只讀記憶體映射檔案屬於此類。 iOS 不怕隨時從記憶體卸載映射到檔案的頁面,因為它們保證與磁碟上的檔案同步。
所有修改過的頁面,無論它們最初位於何處,最終都會進入髒內存。具體來說,透過寫入與其關聯的虛擬記憶體而修改的記憶體映射檔案將以這種方式進行分類。使用 flag 開啟 LMDB MDB_WRITEMAP,對其進行更改後,您可以親自看到這一點。
一旦應用程式開始佔用過多的實體內存,iOS 就會對其進行髒頁壓縮。髒頁和壓縮頁所佔用的記憶體總量構成了應用程式所謂的記憶體佔用。當達到某個閾值時,OOM 殺手系統守護程序就會追蹤該進程並強制終止它。這就是 iOS 與桌面作業系統的不同之處。與它們不同,iOS 不提供透過將頁面從實體記憶體交換到磁碟來減少記憶體佔用的功能。人們只能猜測原因。也許密集地將頁面移動到磁碟並返回的過程對於行動裝置來說太耗能了,或者 iOS 節省了在 SSD 磁碟上重寫單元的資源,或者設計師對系統的整體效能不滿意,因為所有內容都在不斷交換。不管怎樣,事實就是事實。
好消息是,前面已經提到過,LMDB 預設不使用 mmap 機制來更新檔案。這意味著顯示的資料被 iOS 歸類為乾淨內存,不會增加記憶體佔用。您可以使用名為 VM Tracker 的 Xcode 工具來驗證這一點。下面的截圖顯示了iOS雲端應用程式運行時的虛擬記憶體狀態。一開始,其中初始化了2個LMDB實例。第一個允許在 1GiB 虛擬記憶體上顯示其文件,第二個允許在 512MiB 虛擬記憶體上顯示其檔案。儘管兩個儲存都佔用了一定量的駐留內存,但它們都不會增加髒的大小。
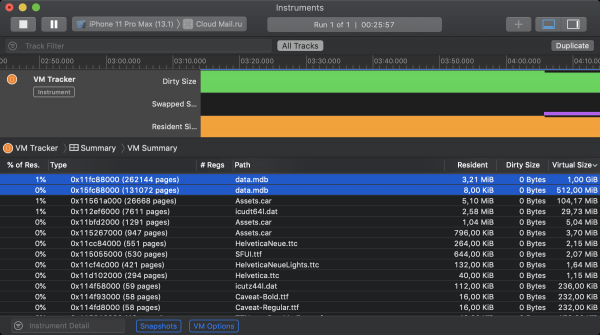
現在該聽一些壞消息了。由於 64 位元桌面作業系統中的交換機制,每個進程可以佔用與硬碟上的可用空間允許的潛在交換量相同的虛擬位址空間。在 iOS 中用壓縮代替交換會從根本上降低理論最大值。現在,所有正在運行的進程都必須適合主(讀取 RAM)內存,所有不適合的進程都將強制終止。如上所述 所以 。因此,iOS 嚴格限制了可用於 mmap 分配的記憶體量。這裡 您可以使用此系統呼叫查看在不同裝置上分配的記憶體大小的經驗限制。在最現代的智慧型手機型號上,iOS 慷慨地提供了 2 GB,而在 iPad 的頂級版本上則提供了 4 GB。當然,在實踐中,您必須專注於最年輕支援的設備型號,其中一切都非常令人沮喪。更糟的是,查看 VM Tracker 中應用程式的記憶體狀態可以發現,LMDB 遠不是唯一一個聲明記憶體映射記憶體的應用程式。好的區塊被系統分配器、資源檔案、影像框架和其他較小的掠食者吃掉。
根據雲端實驗的結果,我們得到分配的 LMDB 記憶體的折衷值:384 位元裝置為 32 兆位元組,768 位元裝置為 64 兆位元組。一旦此磁碟區用完,任何修改操作都會以程式碼終止 MDB_MAP_FULL。我們在監控中觀察到了此類錯誤,但目前它們很少,可以忽略不計。
儲存記憶體消耗過多的一個不明顯的原因可能是長期事務。為了理解這兩種現象之間的關係,我們來考慮剩下的兩隻 LMDB 鯨魚。
3.2.鯨魚#2。 B+樹
為了模擬鍵值儲存之上的表,其 API 必須具有以下操作:
- 插入新元素。
- 尋找具有給定鍵的元素。
- 刪除一個元素。
- 按排序順序對鍵的間隔進行迭代。
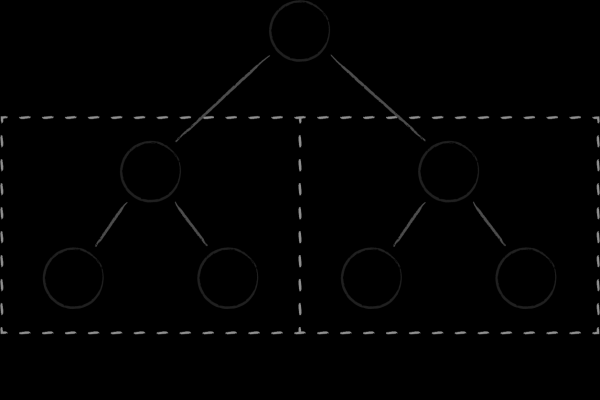 可以輕鬆實現所有四種操作的最簡單的資料結構是二元搜尋樹。它的每個節點代表一個鍵,將整個子鍵子集分成兩個子樹。左邊包含比父級小的元素,右邊包含比父級大的元素。透過經典的樹遍歷之一可以獲得有序的鍵集。
可以輕鬆實現所有四種操作的最簡單的資料結構是二元搜尋樹。它的每個節點代表一個鍵,將整個子鍵子集分成兩個子樹。左邊包含比父級小的元素,右邊包含比父級大的元素。透過經典的樹遍歷之一可以獲得有序的鍵集。
二元樹有兩個基本缺點,使得它們不能有效地作為磁碟資料結構。首先,它們的平衡程度是不可預測的。獲得不同分支的高度可能差異很大的樹的風險很大,與預期相比,這會大大增加搜尋的演算法複雜性。其次,節點之間大量的交叉引用使得二叉樹失去了記憶體中的局部性。緊密的節點(就它們之間的連結而言)可以位於虛擬記憶體中完全不同的頁面上。因此,即使簡單遍歷樹中的幾個相鄰節點也可能需要存取相當數量的頁面。即使我們談論二元樹作為記憶體資料結構的效率,這也是一個問題,因為在處理器快取中不斷旋轉頁面並不便宜。當頻繁從磁碟調出與節點相關的頁面時,情況會變得更糟。 。
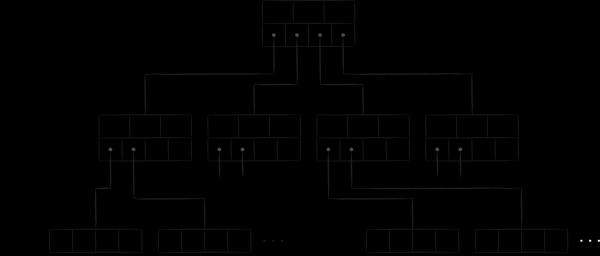
 B 樹是二元樹的演變,解決了上一段中概述的問題。首先,它們具有自我平衡能力。其次,它們的每個節點不是將子密鑰集合分成2個,而是分成M個有序子集,並且M的數量級可能相當大,達到幾百甚至幾千的數量級。
B 樹是二元樹的演變,解決了上一段中概述的問題。首先,它們具有自我平衡能力。其次,它們的每個節點不是將子密鑰集合分成2個,而是分成M個有序子集,並且M的數量級可能相當大,達到幾百甚至幾千的數量級。
由於這個原因:
- 每個節點包含大量已排序的鍵,且樹非常低。
- 樹獲得了在記憶體中放置局部性的屬性,因為相似值的鍵自然地位於相同或相鄰的節點上彼此附近。
- 在搜尋操作過程中下降樹時中轉節點的數量會減少。
- 範圍查詢中讀取的目標節點數量減少,因為每個目標節點已經包含大量有序鍵。
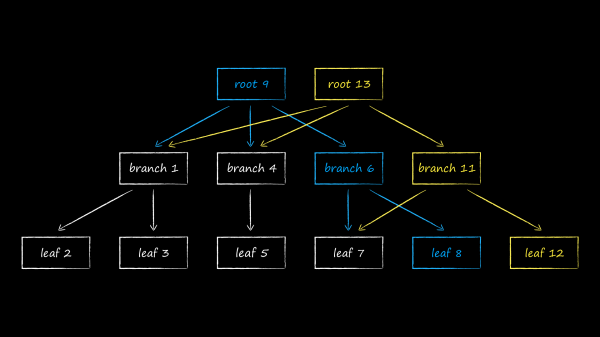
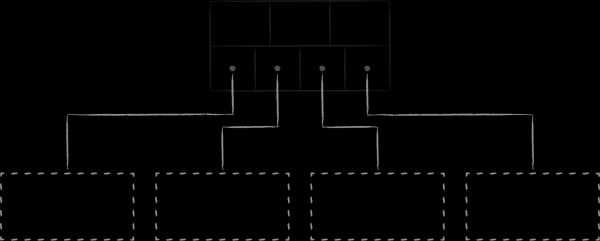
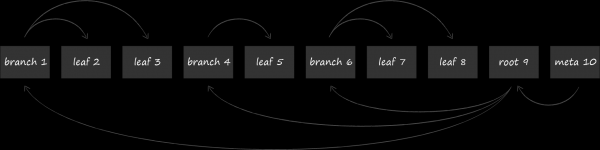
LMDB 使用 B 樹的變體(稱為 B+ 樹)來儲存資料。上圖顯示了它所包含的三種類型的節點:
- 根位於頂部。它只不過實現了儲存庫內的資料庫的概念。在單一 LMDB 實例中,您可以建立共用映射虛擬位址空間的多個資料庫。每一個都是從它自己的根源開始的。
- 最底層是樹葉。它們且只有它們包含儲存在資料庫中的鍵值對。順便說一下,這是 B+ 樹的特別之處。常規 B 樹將值部分儲存在各級節點中,而 B+ 變體僅將它們儲存在最底層。確定了這一事實後,我們將從此將 LMDB 中使用的樹的子類型簡稱為 B 樹。
- 在根和葉之間有 0 個或多個帶有導航(分支)節點的技術等級。他們的任務是將已排序的鍵集劃分到葉子節點之間。
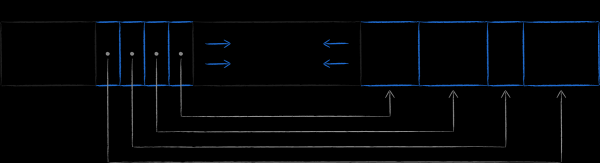
物理上,節點是預定長度的記憶體區塊。它們的大小是作業系統中記憶體頁面大小的倍數,我們上面討論過。節點的結構如下圖所示。標頭包含元訊息,其中最明顯的例如是校驗和。接下來是有關包含資料的儲存格所在位置的偏移量的資訊。如果我們談論的是導航節點,那麼資料可以是鍵;如果是葉子節點,那麼資料可以是整個鍵值對。您可以在作品中閱讀有關頁面結構的更多信息 .
處理完頁面節點的內部內容後,我們將以以下方式進一步簡化呈現 LMDB B 樹。
帶有節點的頁面在磁碟上按順序排列。數字越大的頁面越靠近文件末尾。所謂的元頁麵包含有關可以找到所有樹的根的偏移量的信息。開啟文件時,LMDB 會從文件末尾到開頭逐頁掃描文件,以查找有效的元頁面並透過它找到現有的資料庫。
現在,我們對資料組織的邏輯和物理結構有了一定的了解,可以繼續考慮 LMDB 的第三支柱。在它的幫助下,對儲存的所有修改都以事務方式且彼此隔離的方式進行,從而使整個資料庫具有多版本屬性。
3.3.鯨魚#3。寫時複製
B 樹上的某些操作涉及對其節點進行一系列更改。一個例子是向已經達到其最大容量的節點添加新金鑰。在這種情況下,首先需要將節點一分為二,其次需要在新出芽的子節點的父節點中加入連結。這個過程可能非常危險。如果由於某種原因(崩潰、斷電等)僅發生了系列中的部分更改,則樹將保持不一致的狀態。
使資料庫容錯的傳統解決方案之一是在 B 樹旁邊添加額外的磁碟資料結構 - 交易日誌,也稱為預寫日誌 (WAL)。它是一個文件,在修改 B 樹本身之前,建議的操作嚴格寫入其末尾。因此,如果在自我診斷期間偵測到資料損壞,資料庫就會查閱日誌進行自我清理。
LMDB 選擇了一種不同的容錯方法,稱為寫入時複製。其本質是,它不會更新現有頁面上的數據,而是首先將其完全複製並對副本進行所有修改。
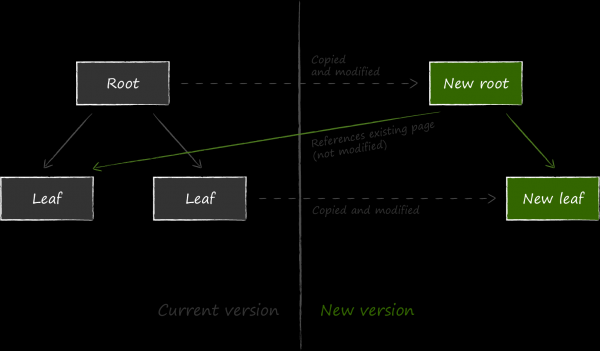
接下來,為了使更新的資料可用,您需要將連結變更為與其父節點相關的節點。由於這個也需要修改,所以也提前複製過來了。過程一直遞歸到根。最後要改變的是元頁面上的資料。
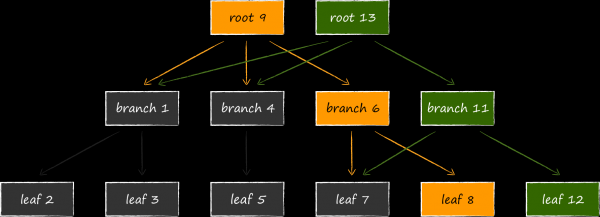
如果在更新過程中更新進程突然崩潰,則新的元頁面將不會被創建,或者不會完全寫入磁碟,並且其校驗和將不正確。無論哪種情況,新頁面都將無法訪問,而舊頁面不會受到影響。這使得 LMDB 不再需要維護預寫日誌來維持資料一致性。事實上,上面所描述的磁碟資料儲存結構也同時承擔了它的功能。沒有明確的交易日誌是LMDB的特性之一,保證了較高的資料讀取速度。
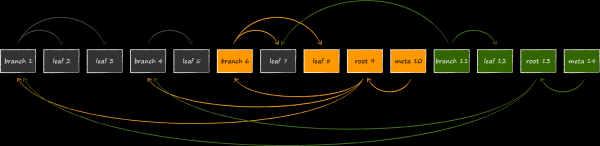
最終的構造稱為僅追加 B 樹,自然提供事務隔離和多版本控制。在 LMDB 中,每個開啟的事務都與樹的目前有效的根相關聯。在事務完成之前,與其關聯的樹的頁面永遠不會被修改或重新用於新版本的資料。因此,您可以根據需要,使用在交易開始時相關的資料集進行任意時間的工作,即使儲存當時仍在繼續主動更新。這就是多版本控制的本質,這使得 LMDB 成為我們摯愛的 UICollectionView。開啟交易後,無需急忙將當前數據放入某些記憶體結構中,以免不慎留下任何數據,從而增加應用程式的記憶體佔用。此功能將 LMDB 與無法實現如此完全隔離的 SQLite 區分開來。在後者中開啟兩個交易並刪除其中一個交易中的某筆記錄後,將無法再在剩下的第二個交易中獲得相同的記錄。
缺點是它可能會使用更多的虛擬記憶體。幻燈片展示了當資料庫結構同時被修改並且有 3 個開放讀取事務查看資料庫的不同版本時,資料庫結構將會是什麼樣子。由於 LMDB 無法重複使用與當前事務相關的根可存取的節點,因此儲存別無選擇,只能在記憶體中分配另一個第四個根並再次克隆其下的修改後的頁面。
這裡回顧一下記憶體映射檔案的部分會很有用。看起來虛擬記憶體的額外消耗不會給我們帶來太多困擾,因為它不會增加應用程式的記憶體佔用。然而,同時,我們也注意到 iOS 的分配非常吝嗇,我們不能像在伺服器或桌面上那樣,慷慨地為 LMDB 提供 1 TB 的區域,而完全不考慮這個功能。只要有可能,您就應該嘗試使事務的生命週期盡可能短。
4. 透過鍵值 API 設計資料模式
讓我們透過查看 LMDB 提供的基本抽象來開始我們的 API 審查:環境和資料庫、鍵和值、事務和遊標。
關於程式碼清單的說明
公共 LMDB API 中的所有函數都以錯誤代碼的形式傳回其工作結果,但在所有後續清單中,為了簡潔起見,都省略了其驗證。在實踐中,我們使用自己的方法與儲存進行交互 C++ 包裝器 ,其中錯誤表現為 C++ 異常。
將 LMDB 連接到 iOS 專案的最快方法 macOS 我提供我的 CocoaPod .
4.1.基本抽象
環境
結構 MDB_env 是 LMDB 內部狀態的儲存庫。帶有前綴的函數族 mdb_env 允許您配置它的一些屬性。在最簡單的情況下,引擎初始化看起來像這樣。
mdb_env_create(env);
mdb_env_set_map_size(*env, 1024 * 1024 * 512)
mdb_env_open(*env, path.UTF8String, MDB_NOTLS, 0664);在 Mail.ru Clouds 應用程式中,我們僅更改了兩個參數的預設值。
第一個是儲存檔案映射到的虛擬位址空間的大小。不幸的是,即使在同一裝置上,具體值在每次發佈時也會有很大差異。為了考慮到這個 iOS 特性,我們的最大儲存量是動態選擇的。從某個值開始,逐漸減半,直到函數 mdb_env_open 不會返回不同於 ENOMEM。理論上,也有相反的方法——首先為引擎分配最少的內存,然後,當發生錯誤時, MDB_MAP_FULL,增加它。然而,問題卻更加棘手。原因是使用函數的記憶體重新分配過程(重新映射) mdb_env_set_map_size 使先前從引擎接收到的所有實體(遊標、事務、鍵和值)無效。在程式碼中考慮到這一事件的變化將導致其變得非常複雜。然而,如果虛擬記憶體對你來說非常珍貴,那麼這可能是仔細研究已經走得很遠的分叉的一個原因 其中聲明的功能包括「自動動態調整資料庫大小」。
第二個參數的預設值不適合我們,它規定了確保執行緒安全的機制。不幸的是,至少在 iOS 10 中線程本地存儲支援存在問題。因此,在上面的例子中,儲存是用標誌打開的 MDB_NOTLS。除此之外,還必須 C++ 包裝器 剪切出具有此屬性的變數並將其放入其中。
數據庫
資料庫是我們上面討論的 B 樹的一個單獨實例。它的開啟發生在交易中,乍看之下可能有點奇怪。
MDB_txn *txn;
MDB_dbi dbi;
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
mdb_dbi_open(txn, NULL, MDB_CREATE, &dbi);
mdb_txn_abort(txn);事實上,LMDB 中的事務是儲存的實體,而不是特定資料庫的實體。這個概念允許對位於不同資料庫中的實體執行原子操作。理論上,這開啟了以不同資料庫的形式建模表的可能性,但我曾經走了另一條路,下面詳細描述。
鍵和值
結構 MDB_val 對鍵和值的概念進行建模。存儲庫不知道它們的語義是什麼。對她來說,其他任何東西都只是給定大小的位元組數組。最大密鑰大小為 512 位元組。
typedef struct MDB_val {
size_t mv_size;
void *mv_data;
} MDB_val;使用比較器,商店按升序對鍵進行排序。如果您不將其替換為自己的,則將使用預設值,該值會按字典按順序逐字節對它們進行排序。
交易
交易結構詳細描述如下 ,因此我在這裡簡單複述它們的主要屬性:
- 支援所有基本屬性 原子性、一致性、隔離性和可靠性。我不得不指出,就耐久性而言, macOS MDBX 修復了 iOS 系統中的一個漏洞。您可以在他們的文檔中了解更多。 .
- 多線程方法由“單寫入器/多讀取器”方案描述。作家們互相阻礙,但他們不會阻礙讀者。讀者不會阻礙作者,也不會阻礙其他讀者。
- 支持嵌套事務。
- 多版本支援。
LMDB 中的多版本控制非常好,所以我想實際演示它。從下面的程式碼中,您可以看到每個事務都與開啟時最新的資料庫的精確版本一起工作,與所有後續變更完全隔離。初始化儲存並向其中添加測試記錄並沒有什麼有趣的內容,因此這些儀式被留在了劇透之下。
新增測試條目
MDB_env *env;
MDB_dbi dbi;
MDB_txn *txn;
mdb_env_create(&env);
mdb_env_open(env, "./testdb", MDB_NOTLS, 0664);
mdb_txn_begin(env, NULL, 0, &txn);
mdb_dbi_open(txn, NULL, 0, &dbi);
mdb_txn_abort(txn);
char k = 'k';
MDB_val key;
key.mv_size = sizeof(k);
key.mv_data = (void *)&k;
int v = 997;
MDB_val value;
value.mv_size = sizeof(v);
value.mv_data = (void *)&v;
mdb_txn_begin(env, NULL, 0, &txn);
mdb_put(txn, dbi, &key, &value, MDB_NOOVERWRITE);
mdb_txn_commit(txn);MDB_txn *txn1, *txn2, *txn3;
MDB_val val;
// Открываем 2 транзакции, каждая из которых смотрит
// на версию базы данных с одной записью.
mdb_txn_begin(env, NULL, 0, &txn1); // read-write
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn2); // read-only
// В рамках первой транзакции удаляем из базы данных существующую в ней запись.
mdb_del(txn1, dbi, &key, NULL);
// Фиксируем удаление.
mdb_txn_commit(txn1);
// Открываем третью транзакцию, которая смотрит на
// актуальную версию базы данных, где записи уже нет.
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn3);
// Убеждаемся, что запись по искомому ключу уже не существует.
assert(mdb_get(txn3, dbi, &key, &val) == MDB_NOTFOUND);
// Завершаем транзакцию.
mdb_txn_abort(txn3);
// Убеждаемся, что в рамках второй транзакции, открытой на момент
// существования записи в базе данных, её всё ещё можно найти по ключу.
assert(mdb_get(txn2, dbi, &key, &val) == MDB_SUCCESS);
// Проверяем, что по ключу получен не абы какой мусор, а валидные данные.
assert(*(int *)val.mv_data == 997);
// Завершаем транзакцию, работающей хоть и с устаревшей, но консистентной базой данных.
mdb_txn_abort(txn2);我可以選擇建議使用 SQLite 嘗試相同的技巧,看看會發生什麼。
多版本為 iOS 開發人員的生活帶來了一些非常好的好處。此屬性可讓您根據使用者體驗考慮輕鬆自然地調整螢幕表單的資料來源更新率。舉個例子,讓我們以 Mail.ru Cloud 應用程式的一項功能為例,例如從系統媒體庫自動下載內容。在良好的連線下,客戶端每秒可以為伺服器添加多張照片。如果您在每次下載後更新 UICollectionView 由於媒體內容位於使用者的雲端,因此在此過程中您可以忘記 60 fps 和平滑滾動。為了防止螢幕頻繁更新,需要以某種方式限制基礎資料的變化率 UICollectionViewDataSource.
如果資料庫不支援多版本控制並且僅允許使用當前實際狀態,那麼要建立資料的時間穩定快照,就需要將其複製到某些記憶體資料結構或臨時表中。無論哪種方法,成本都非常高。對於記憶體儲存的情況,我們既需要儲存建構物件所導致的記憶體成本,也需要冗餘 ORM 轉換所導致的時間成本。至於臨時表,這是一個更昂貴的樂趣,只有在非平凡的情況下才有意義。
LMDB 多版本非常優雅地解決了維護穩定資料來源的問題。只需簡單地打開一個交易即可,瞧 - 直到我們完成它為止,數據集都保證被記錄下來。其更新速度的邏輯現在完全掌握在表示層手中,無需花費大量資源的開銷成本。
遊標
遊標提供了一種透過 B 樹遍歷以有序方式迭代鍵值對的機制。如果沒有它們,就不可能有效地對資料庫中的表格進行建模,這也是我們接下來要研究的內容。
4.2.表建模
鍵的排序屬性允許建立高階抽象,例如在基本抽象之上的表。讓我們以雲端客戶端的主表為例來考慮這個過程,它快取了有關所有使用者檔案和資料夾的資訊。
表格佈局
需要自訂具有資料夾樹的表結構的常見場景之一是選擇位於給定目錄內的所有元素。對於這種高效查詢來說,一個好的資料組織模型是 為了在鍵值儲存之上實現此功能,需要對檔案和資料夾鍵進行排序,以便根據其父目錄進行分組。此外,還需要以使用者友善的方式顯示目錄內容。 Windows 如果視圖是(先顯示資料夾,再顯示文件,兩者均按字母順序排序),則需要在鍵中包含對應的附加欄位。
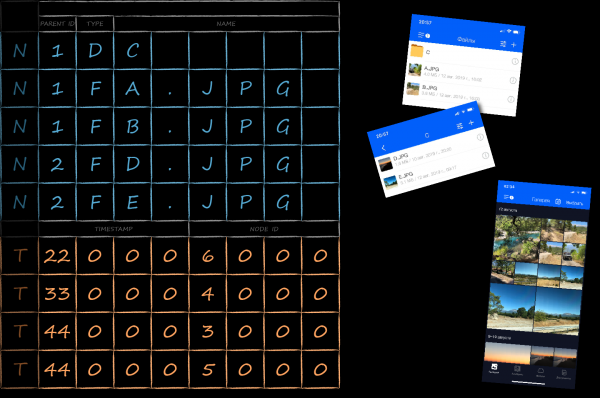
下圖顯示了根據當前任務,鍵作為位元組數組的表示形式。首先放置帶有父目錄標識符(紅色)的位元組,然後放置類型(綠色)並在尾部放置名稱(藍色)。它們按照預設的 LMDB 比較器按字典順序排序,並按所需的方式排序。按順序遍歷具有相同紅色前綴的鍵,我們可以按照它們在使用者介面(右側)中顯示的順序獲得它們的關聯值,而無需任何額外的後處理。

鍵和值的序列化
世界上已發明了許多物件序列化的方法。由於我們除了速度之外沒有其他要求,因此我們選擇了最快的方法 - 轉儲 C 語言結構實例所佔用的記憶體。因此,目錄元素的鍵可以透過以下結構建模 NodeKey.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;儲存 NodeKey 在儲存中,物件中是必需的 MDB_val 將資料指標定位到結構開頭的位址,並使用函數計算其大小 sizeof.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = sizeof(NodeKey),
.mv_data = (void *)key
};
}在關於資料庫選擇標準的第一章中,我提到最小化 CRUD 操作中的動態分配是一個重要的選擇因素。功能代碼 serialize 展示了在 LMDB 的情況下,如何在將新記錄插入資料庫時完全避免這些問題。從伺服器接收的位元組數組首先被轉換成堆疊結構,然後被簡單地轉儲到記憶體中。考慮到 LMDB 內部也沒有動態分配,您可以獲得符合 iOS 標準的絕佳情況 - 僅使用堆疊記憶體來處理從網路到磁碟的整個路徑上的資料!
使用二進制比較器對鍵進行排序
鍵的順序關係由稱為比較器的特殊函數指定。由於引擎對它們包含的位元組的語義一無所知,因此預設比較器別無選擇,只能透過逐字節比較鍵來按字典順序對鍵進行排序。用它來組織結構就像用屠夫的斧頭刮鬍子。然而,在簡單的情況下我發現這種方法是可以接受的。下面描述了替代方案,在這裡我將指出其中存在的幾個陷阱。
首先要記住的是原始資料類型的記憶體表示。因此,在所有 Apple 裝置上,整數變數都以以下格式存儲 。這意味著最低有效位元組將位於左側,並且無法使用逐字節比較對整數進行排序。例如,嘗試使用一組從 0 到 511 的數字執行此操作將產生以下結果。
// value (hex dump)
000 (0000)
256 (0001)
001 (0100)
257 (0101)
...
254 (fe00)
510 (fe01)
255 (ff00)
511 (ff01)為了解決這個問題,必須將整數以適合位元組比較器的格式儲存在鍵中。家庭的功能將有助於實現必要的轉變 hton* (尤其 htons (範例中的雙位元組數字)。
眾所周知,在程式設計中表示字串的格式是一個整體 。如果字串的語義和用於在記憶體中表示它們的編碼表明每個字元可能有多個字節,那麼最好立即放棄使用預設比較器的想法。
要記住的第二件事是 結構字段編譯器。由於它們的存在,具有垃圾值的位元組會在欄位之間的記憶體中形成,這當然會破壞位元組排序。為了消除垃圾,您必須按照嚴格定義的順序聲明字段,牢記對齊規則,或使用結構聲明中的屬性 packed.
使用外部比較器訂購鑰匙
對於二進制比較器來說,比較鍵的邏輯可能過於複雜。其中一個原因是結構中存在技術領域。我將使用我們已經熟悉的目錄元素的鍵的範例來說明它們的出現。
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;儘管它很簡單,但在絕大多數情況下它會消耗太多記憶體。名稱的緩衝區佔用 256 個字節,儘管檔案和資料夾名稱平均很少超過 20-30 個字元。
優化記錄大小的標準技術之一是「修剪」它以適合實際大小。其本質是將所有變長字段的內容儲存在結構末尾的緩衝區中,並將其長度儲存在單獨的變數中。按照這種方法,關鍵 NodeKey 變換如下。
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;此外,在序列化過程中,資料大小指定為 sizeof 整個結構,以及所有固定長度欄位的大小加上緩衝區實際使用部分的大小。
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = offsetof(NodeKey, nameBuffer) + key->nameLength,
.mv_data = (void *)key
};
}重構的結果是,我們顯著節省了鍵所佔用的空間。然而,由於技術領域 nameLength,預設二進制比較器不再適合比較鍵。如果我們不將其替換為我們自己的,那麼在排序時,名稱的長度將比名稱本身俱有更高的優先順序。
LMDB 允許每個資料庫擁有自己的鍵比較功能。這是使用函數完成的 mdb_set_compare 嚴格至開封。由於顯而易見的原因,資料庫在其生存期內不能被改變。比較器接收兩個二進位格式的鍵作為輸入,並傳回比較結果作為輸出:小於(-1)、大於(1)或等於(0)。虛擬程式碼 NodeKey 看起來像這樣。
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey * const aKey = (NodeKey * const)a->mv_data;
NodeKey * const bKey = (NodeKey * const)b->mv_data;
return // ...
}只要資料庫中的所有鍵具有相同的類型,就可以無條件地將其位元組表示轉換為鍵的應用程式結構的類型。這裡有一個細微差別,但將在下面的“閱讀記錄”小節中討論。
值的序列化
LMDB 與儲存的記錄鍵密切相關。它們之間的比較發生在任何應用程式操作的框架內,整個解決方案的效能取決於比較器的速度。在理想情況下,預設的二進位比較器應該足以比較鍵,但如果您必須使用自己的比較器,那麼其中反序列化鍵的過程應該盡可能快。
資料庫對記錄的值部分不是特別感興趣。只有當應用程式程式碼需要它時(例如,將其顯示在螢幕上),才會將其從位元組表示轉換為物件。由於這種情況相對較少發生,因此對該過程的速度要求不是那麼嚴格,並且在實施過程中我們可以更加自由地關注便利性。例如,為了序列化尚未載入的檔案的元數據,我們使用 NSKeyedArchiver.
NSData *data = serialize(object);
MDB_val value = {
.mv_size = data.length,
.mv_data = (void *)data.bytes
};然而,有時性能確實很重要。例如,為了保存有關用戶雲的文件結構的元信息,我們使用相同的物件記憶體轉儲。形成其序列化表示的任務的亮點是目錄元素由類別層次結構建模。
為了在 C 語言中實現它,繼承者的特定字段被移動到單獨的結構中,並且它們與基類的連接通過聯合類型字段指定。關聯的實際內容透過技術屬性類型指定。
typedef struct NodeValue {
EntityId localId;
EntityType type;
union {
FileInfo file;
DirectoryInfo directory;
} info;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeValue;新增和更新記錄
序列化的鍵和值可以加入到儲存中。該函數就是用於此目的。 mdb_put.
// key и value имеют тип MDB_val
mdb_put(..., &key, &value, MDB_NOOVERWRITE);在配置階段,可以允許或禁止儲存庫儲存具有相同金鑰的多筆記錄。如果禁止重複鍵,那麼在插入記錄時,可以確定是否允許更新現有記錄。如果覆蓋僅因代碼錯誤而發生,那麼您可以透過指定標誌來確保自己不會發生這種情況 NOOVERWRITE。
閱讀條目
此函數用於讀取LMDB中的記錄 mdb_get。如果鍵值對由先前轉儲的結構表示,則該過程如下所示。
NodeValue * const readNode(..., NodeKey * const key) {
MDB_val rawKey = serialize(key);
MDB_val rawValue;
mdb_get(..., &rawKey, &rawValue);
return (NodeValue * const)rawValue.mv_data;
}所呈現的清單顯示如何透過結構轉儲進行序列化,不僅允許您在寫入時擺脫動態分配,而且允許您在讀取資料時擺脫動態分配。源自函數 mdb_get 指標準確指向資料庫儲存物件位元組表示的虛擬記憶體位址。事實上,我們幾乎免費地獲得了一種提供非常高的資料讀取速度的 ORM。儘管這種方法很美妙,但有必要記住與之相關的幾個特點。
- 對於唯讀事務,指向值結構的指標保證僅在事務關閉之前保持有效。如前所述,由於寫時複製原則,只要物件所在的 B 樹頁面被至少一個交易引用,它們就會保持不變。同時,一旦與它們相關的最後一個事務完成,這些頁面就可以重新用於新資料。如果物件需要在創建它們的事務中存活,那麼它們仍然需要被複製。
- 對於讀寫事務,指向接收值結構的指標僅在第一次修改過程(寫入或刪除資料)之前有效。
- 儘管該結構
NodeValue雖然不是完全成熟的,但經過了修剪(請參閱“使用外部比較器對鍵進行排序”小節),透過指標您可以輕鬆存取其欄位。最重要的是不要取消引用它! - 在任何情況下都不應透過接收的指標來修改結構。所有更改只能透過方法進行
mdb_put。然而,即使你真的想這樣做,你也無法做到這一點,因為該結構所在的記憶體區域是以唯讀模式映射的。 - 將檔案重新對應到進程位址空間,例如,使用函數增加最大儲存大小
mdb_env_set_map_size完全使所有交易和相關實體以及特別是讀取物件的指標無效。
最後,還有一個特徵非常陰險,僅憑這一點不足以揭示其本質。在有關 B 樹的章節中,我提供了其記憶體中頁面的結構圖。由此可見,序列化資料的緩衝區的起始位址可以是任意的。因此,結構中接收到的指向它們的指針 MDB_val 並轉換為指向結構的指針,它通常是不對齊的。同時,某些晶片的架構(對 iOS 來說,這是 armv7)要求任何資料的位址都是機器字大小的倍數,或者換句話說,是系統的位元深度(對於 armv7,這是 32 位元)。換句話說,操作就像 *(int *foo)0x800002 對他們來說,這相當於逃跑,並導致判決執行 EXC_ARM_DA_ALIGN。有兩種方法可以避免這種悲慘的命運。
第一個是將資料預先複製到預先對齊的結構中。例如,在自訂比較器上,這將反映如下。
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey aKey, bKey;
memcpy(&aKey, a->mv_data, a->mv_size);
memcpy(&bKey, b->mv_data, b->mv_size);
return // ...
}另一種方法是提前通知編譯器,鍵值結構可能無法使用屬性對齊 aligned(1)。在 ARM 上可以達到同樣的效果 並使用 packed 屬性。考慮到它也有助於優化結構佔用的空間,這種方法對我來說似乎更可取,儘管 導致資料存取操作的成本增加。
typedef struct __attribute__((packed)) NodeKey {
uint8_t parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;範圍查詢
LMDB 提供了一個遊標抽象,用於迭代一組記錄。讓我們使用我們已經熟悉的用戶雲端元資料表的範例來看看如何使用它。
作為顯示目錄中檔案清單的一部分,需要找到與其子檔案和資料夾關聯的所有鍵。在前面的小節中,我們對鍵進行了排序 NodeKey 因此它們主要按父目錄 ID 排序。因此,從技術上講,獲取資料夾內容的任務歸結為將遊標放在具有給定前綴的一組鍵的上邊界上,然後迭代到下邊界。

透過順序搜尋可以「正面」找到上限。為此,將遊標放在資料庫中整個鍵列表的開頭,然後遞增,直到具有父目錄標識符的鍵位於其下方。這種方法有兩個明顯的缺點:
- 線性搜尋複雜度,儘管眾所周知,在樹中,特別是在 B 樹中,它可以在對數時間內實現。
- 徒勞的是,所有位於被查找頁面之前的頁面都會從文件中移到主記憶體中,這是非常昂貴的。
幸運的是,LMDB API 提供了一種有效的方法來初始定位遊標。為此,您需要建立一個鍵,其值明顯小於或等於位於間隔上邊界的鍵。例如,相對於上圖中的列表,我們可以建立一個鍵,其中字段 parentId 將等於 2,其餘部分將用零填充。此類部分填充的金鑰被輸入到函數的輸入端 mdb_cursor_get 帶操作指示 MDB_SET_RANGE。
NodeKey upperBoundSearchKey = {
.parentId = 2,
.type = 0,
.nameLength = 0
};
MDB_val value, key = serialize(upperBoundSearchKey);
MDB_cursor *cursor;
mdb_cursor_open(..., &cursor);
mdb_cursor_get(cursor, &key, &value, MDB_SET_RANGE);如果找到了密鑰組的上限,那麼我們就對其進行迭代,直到達到上限或密鑰不同為止 parentId,否則鑰匙就永遠用不完。
do {
rc = mdb_cursor_get(cursor, &key, &value, MDB_NEXT);
// processing...
} while (MDB_NOTFOUND != rc && // check end of table
IsTargetKey(key)); // check end of keys group有趣的是,當使用 mdb_cursor_get 進行迭代時,我們不僅可以獲得鍵,還可以獲得值。如果為了滿足選擇條件,需要檢查記錄的值部分的字段,那麼無需任何額外的努力就可以存取它們。
4.3.表之間的關係建模
到目前為止,我們已經考慮了設計和使用單表資料庫的所有方面。我們可以說表是一組由相同的鍵值對組成的排序記錄。如果將鍵顯示為矩形並將其關聯值顯示為平行六面體,您將獲得資料庫的視覺化圖表。
![]()
然而,在現實生活中,很少會出現如此少量流血事件而不受懲罰的情況。通常,資料庫首先需要有多個表,其次需要按照與主鍵不同的順序在其中執行選擇。最後一部分專門討論它們的創作及其相互聯繫的問題。
索引表
雲端應用程式有一個“圖庫”部分。它顯示來自整個雲端的媒體內容,按日期排序。為了最佳地實現這種選擇,您需要在主表旁邊建立另一個具有新類型鍵的表。它們將包含一個帶有文件創建日期的字段,該字段將作為主要排序標準。由於新鍵引用與主表中的鍵相同的數據,因此它們被稱為索引鍵。在下圖中,它們以橙色突出顯示。
為了在一個資料庫中將不同表的鍵彼此分開,所有表都添加了一個額外的技術欄位 tableId。透過使其成為排序的最高優先級,我們將首先按表實現鍵的分組,然後根據我們自己的規則在表內實現鍵的分組。
索引鍵引用與主鍵相同的資料。透過將主鍵的值部分的副本與其關聯來直接實現此屬性從以下幾個角度來看並不是最佳的:
- 就佔用的空間而言,考慮到元資料可能相當豐富。
- 從效能角度來看,由於在更新節點元資料時,您必須重寫兩個金鑰。
- 從程式碼支援的角度來看,如果我們忘記更新其中一個鍵的數據,我們將在儲存中遇到難以捕獲的數據不一致錯誤。
接下來我們來考慮如何消除這些缺點。
組織表之間的關係
此模式非常適合將索引表連結到主表。 “鍵作為值”。顧名思義,索引記錄的值部分是主鍵值的副本。這種方法消除了與儲存主記錄的值部分的副本相關的所有上述缺點。唯一的代價是,要透過索引鍵取得值,您需要對資料庫進行兩次查詢,而不是一次。產生的資料庫模式如下所示。
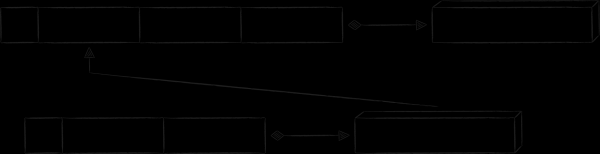
組織表之間關係的另一種模式是 “冗餘金鑰”。其本質是向鍵添加額外的屬性,這些屬性不是用於排序,而是用於重新建立關聯的鍵。 Mail.ru Cloud 應用程式有其使用的真實範例,但為了避免深入研究特定 iOS 框架的背景,我將給出一個虛構的但更容易理解的範例。
雲端行動用戶端有一個頁面,顯示使用者與其他人共享的所有檔案和資料夾。由於此類文件相對較少,並且與它們相關的宣傳具體信息很多(誰被授予訪問權限、具有什麼權限等),因此用它來壓低主表中記錄的價值部分是不合理的。但是,如果您想離線顯示此類文件,您仍然需要將其儲存在某個地方。一個自然的解決方案是為其建立一個單獨的表。在下圖中,它的鍵有前綴“P”,佔位符“propname”可以替換為更具體的值“public info”。
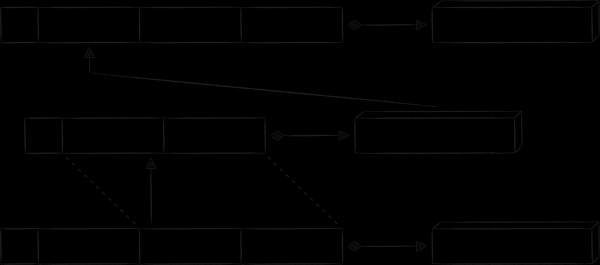
為儲存建立新資料表的所有唯一元資料都會移至記錄的值部分。同時,我不想重複主表中已經儲存的檔案和資料夾的資料。相反,冗餘資料以“節點 ID”和“時間戳”欄位的形式添加到“P”鍵中。透過它們,可以建立索引鍵,透過索引鍵獲取主鍵,最終獲取節點元資料。
結論
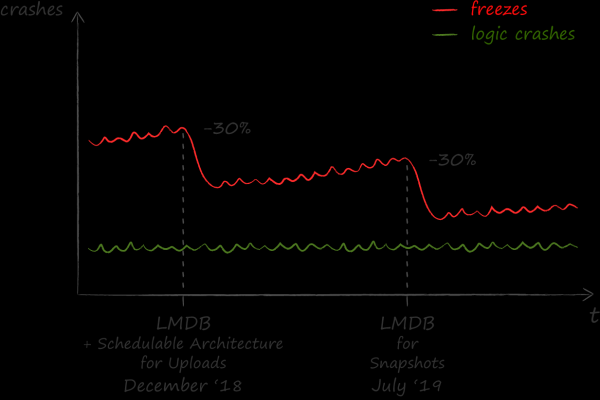
我們對 LMDB 實作的結果評價為正面的。此後,申請凍結的數量減少了30%。
這項工作的成果在 iOS 團隊之外也引起了共鳴。目前,「文件」應用的一個主要部分是基於這項工作的。 Android 我還改用了 LMDB,其他部分也在開發中。鍵值儲存是用 C 語言實現的,這為最初圍繞它用 C++ 建立跨平台應用程式框架提供了一個很好的起點。我們使用程式碼產生器將產生的 C++ 函式庫與原生 Objective-C 和 Kotlin 程式碼無縫連接。 來自 Dropbox,但那是另一個故事了。
來源: www.habr.com
