

通常,進入資料科學領域的人們對等待他們的事情抱持著不太現實的期望。 許多人認為現在他們將編寫很酷的神經網絡,創建鋼鐵人的語音助手,或擊敗金融市場上的所有人。
但工作 數據 科學家是數據驅動的,最重要和最耗時的方面之一是在將數據輸入神經網路或以某種方式分析之前對其進行處理。
在本文中,我們的團隊將介紹如何透過逐步說明和程式碼快速輕鬆地處理資料。 我們試圖使程式碼非常靈活並且可以用於不同的資料集。
許多專業人士可能不會在本文中發現任何特別之處,但初學者將能夠學到新東西,任何長期夢想製作一個單獨的筆記本以進行快速結構化資料處理的人都可以複製程式碼並自行格式化,或者
我們收到了數據集。 接下來做什麼?
所以,標準是:我們需要了解我們正在處理的是什麼,整體情況。 為此,我們使用 pandas 來簡單地定義不同的資料類型。
import pandas as pd #импортируем pandas
import numpy as np #импортируем numpy
df = pd.read_csv("AB_NYC_2019.csv") #читаем датасет и записываем в переменную df
df.head(3) #смотрим на первые 3 строчки, чтобы понять, как выглядят значения 
df.info() #Демонстрируем информацию о колонках 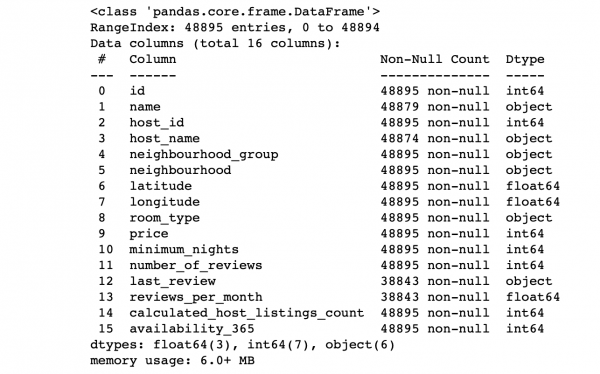
讓我們看看列值:
- 每列的行數是否與總行數相對應?
- 每列資料的本質是什麼?
- 我們想要針對哪一列來進行預測?
這些問題的答案將使您能夠分析資料集並粗略地制定下一步行動的計劃。
另外,為了更深入地查看每列中的值,我們可以使用 pandas describe() 函數。 但是,此函數的缺點是它不提供有關具有字串值的列的資訊。 我們稍後再處理他們。
df.describe() 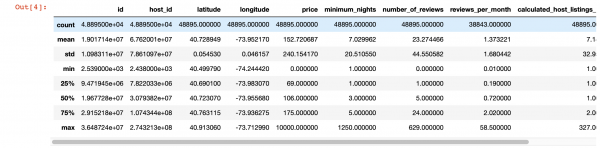
神奇的視覺化
我們來看看哪裡根本沒有值:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis') 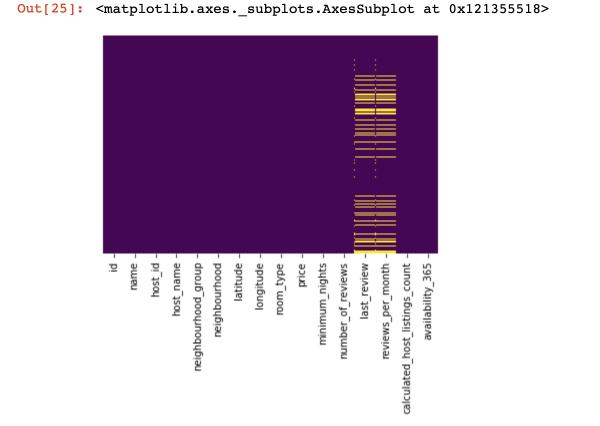
這是上面的簡短介紹,現在我們將繼續討論更有趣的事情
讓我們嘗試查找並在可能的情況下刪除所有行中只有一個值的列(它們不會以任何方式影響結果):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] #Перезаписываем датасет, оставляя только те колонки, в которых больше одного уникального значения現在,我們保護自己和專案的成功免受重複行的影響(包含與現有行之一的順序相同的資訊的行):
df.drop_duplicates(inplace=True) #Делаем это, если считаем нужным.
#В некоторых проектах удалять такие данные с самого начала не стоит.我們將資料集分為兩部分:一個具有定性值,另一個具有定量值
這裡我們需要做一個小小的澄清:如果定性和定量資料中缺失資料的行彼此相關性不是很強,那麼我們需要決定我們犧牲什麼 - 所有缺失資料的行,只有其中的一部分,或某些列。 如果這些線是相關的,那麼我們就完全有權將資料集一分為二。 否則,您首先需要處理與缺失資料在定性和定量方面不相關的線,然後才將資料集一分為二。
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])我們這樣做是為了讓我們更容易處理這兩種不同類型的數據——稍後我們就會明白這會讓我們的生活變得多麼容易。
我們使用定量數據
我們首先要做的是判斷量化資料中是否存在「間諜專欄」。 我們之所以這樣稱呼這些列,是因為它們將自己呈現為定量數據,但實際上卻充當定性數據。
我們如何識別它們? 當然,這完全取決於您正在分析的資料的性質,但一般來說,此類列可能幾乎沒有唯一資料(在 3-10 個唯一值的區域內)。
print(df_numerical.nunique())一旦我們確定了間諜專欄,我們將把它們從定量資料轉移到定性資料:
spy_columns = df_numerical[['колонка1', 'колока2', 'колонка3']]#выделяем колонки-шпионы и записываем в отдельную dataframe
df_numerical.drop(labels=['колонка1', 'колока2', 'колонка3'], axis=1, inplace = True)#вырезаем эти колонки из количественных данных
df_categorical.insert(1, 'колонка1', spy_columns['колонка1']) #добавляем первую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка2', spy_columns['колонка2']) #добавляем вторую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка3', spy_columns['колонка3']) #добавляем третью колонку-шпион в качественные данные最後,我們已經將定量數據與定性數據完全分離,現在我們可以正確使用它了。 首先要了解哪裡有空值(NaN,在某些情況下 0 將被接受為空值)。
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())此時,重要的是要了解哪些欄位中的零可能表示缺失值:這是由於資料的收集方式所致嗎? 或可能與數據值有關? 這些問題必須根據具體情況來回答。
因此,如果我們仍然認為可能會丟失有零的數據,我們應該用 NaN 替換零,以便以後更容易處理這些丟失的數據:
df_numerical[["колонка 1", "колонка 2"]] = df_numerical[["колонка 1", "колонка 2"]].replace(0, nan)現在讓我們看看哪裡缺少數據:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # Можно также воспользоваться df_numerical.info() 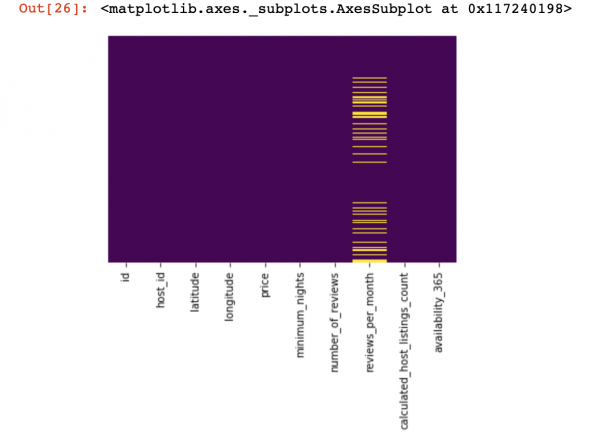
此處,列內缺少的那些值應標示為黃色。 現在有趣的事情開始了——如何處理這些數值? 我應該刪除具有這些值或列的行嗎? 或用其他一些值來填滿這些空值?
以下是一個近似圖,可以幫助您決定原則上可以使用空值做什麼:
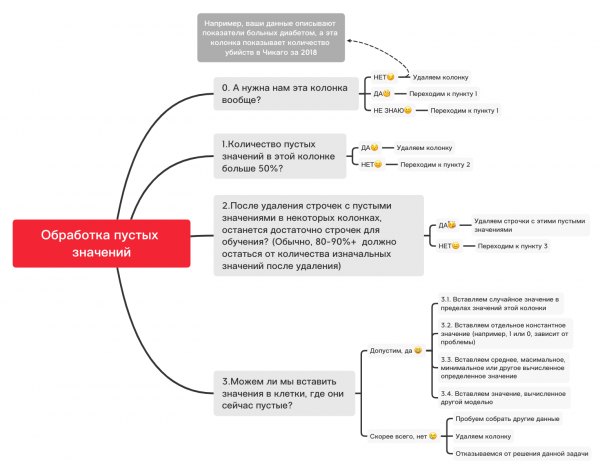
0.刪除不必要的列
df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1.該列中空值的數量是否大於50%?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)#Удаляем, если какая-то колонка имеет больше 50 пустых значений2.刪除空白值行
df_numerical.dropna(inplace=True)#Удаляем строчки с пустыми значениями, если потом останется достаточно данных для обучения3.1. 插入隨機值
import random #импортируем random
df_numerical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True) #вставляем рандомные значения в пустые клетки таблицы3.2. 插入常數值
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>") #вставляем определенное значение с помощью SimpleImputer
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.3. 插入平均值或最頻繁的值
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) #вместо mean можно также использовать most_frequent
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.4. 插入另一個模型計算的值
有時可以使用 sklearn 函式庫或其他類似函式庫中的模型使用迴歸模型來計算值。 我們的團隊將在不久的將來專門撰寫一篇文章來介紹如何做到這一點。
所以,現在,關於定量數據的敘述將被打斷,因為關於如何更好地為不同的任務做好數據準備和預處理還有許多其他細微差別,並且本文已經考慮了定量數據的基本內容,並且現在是回到定性資料的時候了,我們將定性資料與定量資料分開了幾步。 您可以隨意更改此筆記本,使其適應不同的任務,以便資料預處理進行得非常快!
定性數據
基本上,對於定性數據,使用 One-hot 編碼方法將其從字串(或物件)格式化為數字。 在繼續討論這一點之前,讓我們使用上面的圖表和程式碼來處理空值。
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis') 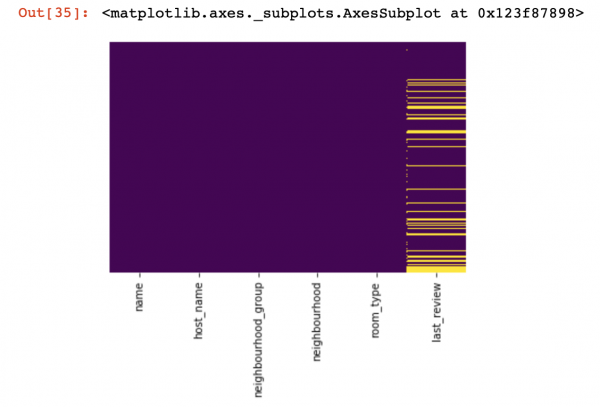
0.刪除不必要的列
df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1.該列中空值的數量是否大於50%?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True) #Удаляем, если какая-то колонка
#имеет больше 50% пустых значений2.刪除空白值行
df_categorical.dropna(inplace=True)#Удаляем строчки с пустыми значениями,
#если потом останется достаточно данных для обучения3.1. 插入隨機值
import random
df_categorical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True)3.2. 插入常數值
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>")
df_categorical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_categorical[['колонка1', 'колонка2', 'колонка3']])
df_categorical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True)因此,我們終於掌握了定性資料中的空值。 現在是時候對資料庫中的值執行 one-hot 編碼了。 這種方法經常用於確保您的演算法可以從高品質數據中學習。
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["колонка1","колонка2","колонка3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))所以,我們終於完成了單獨的定性和定量數據的處理 - 是時候將它們組合回來了
new_df = pd.concat([df_numerical,df_categorical], axis=1)將資料集組合在一起後,我們最終可以使用 sklearn 庫中的 MinMaxScaler 進行資料轉換。 這將使我們的值在0和1之間,這對於以後訓練模型時會有幫助。
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)這些數據現在可以用於任何用途 - 神經網路、標準 ML 演算法等!
在本文中,我們沒有考慮處理時間序列數據,因為對於此類數據,您應該根據您的任務使用略有不同的處理技術。 未來,我們的團隊將專門寫一篇文章來討論這個主題,我們希望它能為您的生活帶來一些有趣、新鮮和有用的東西,就像這篇文章一樣。
來源: www.habr.com
