

在這篇文章中,我們想分享一種處理分散式系統配置的有趣方法。
配置以型別安全的方式直接用 Scala 語言表示。 詳細描述了範例實作。 討論了該提案的各個方面,包括對整體開發過程的影響。
()
引言
建置健全的分散式系統需要在所有節點上使用正確且一致的配置。 典型的解決方案是使用文字部署描述(terraform、ansible 或類似的東西)和自動產生的設定檔(通常專用於每個節點/角色)。 我們也希望在每個通訊節點上使用相同版本的相同協定(否則我們會遇到不相容問題)。 在 JVM 世界中,這意味著至少訊息傳遞庫在所有通訊節點上應該具有相同的版本。
測試系統怎麼樣? 當然,在進行整合測試之前,我們應該對所有組件進行單元測試。 為了能夠在運行時推斷測試結果,我們應該確保所有庫的版本在運行時和測試環境中保持相同。
執行整合測試時,在所有節點上使用相同的類別路徑通常會更容易。 我們只需要確保在部署時使用相同的類路徑。 (可以在不同的節點上使用不同的類路徑,但表示此配置並正確部署它更加困難。)因此,為了保持簡單,我們將只考慮所有節點上相同的類路徑。
配置往往與軟體一起發展。 我們通常使用版本來標識各種
軟體演化的階段。 將配置覆蓋在版本管理下並用一些標籤來識別不同的配置似乎是合理的。 如果生產中只有一種配置,我們可以使用單一版本作為識別碼。 有時我們可能會有多個生產環境。 對於每個環境,我們可能需要一個單獨的配置分支。 因此,配置可能會標有分支和版本,以唯一標識不同的配置。 每個分支標籤和版本對應於每個節點上的分散式節點、連接埠、外部資源、類別路徑庫版本的單一組合。 在這裡,我們將僅介紹單一分支,並透過三分量十進位版本 (1.2.3) 來識別配置,與其他工件相同。
在現代環境中,不再手動修改設定檔。 通常我們生成
部署時的設定檔和 然後。 那麼有人會問為什麼我們仍然使用文字格式的設定檔呢? 一個可行的選擇是將配置放置在編譯單元內,並從編譯時配置驗證中受益。
在這篇文章中,我們將研究將配置保留在已編譯工件中的想法。
可編譯配置
在本節中,我們將討論靜態配置的範例。 正在設定和實作兩個簡單的服務-echo 服務和echo 服務的用戶端。 然後實例化具有這兩種服務的兩個不同的分散式系統。 一種用於單節點配置,另一種用於兩個節點配置。
典型的分散式系統由幾個節點組成。 可以使用某種類型來識別節點:
sealed trait NodeId
case object Backend extends NodeId
case object Frontend extends NodeId要不就
case class NodeId(hostName: String)甚至
object Singleton
type NodeId = Singleton.type這些節點執行各種角色,運行一些服務,並且應該能夠透過 TCP/HTTP 連線與其他節點進行通訊。
對於 TCP 連接,至少需要一個連接埠號碼。 我們還想確保客戶端和伺服器正在使用相同的協定。 為了對節點之間的連接進行建模,我們聲明以下類別:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])哪裡 Port 只是一個 Int 在允許的範圍內:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]精緻型
觀看 圖書館。 簡而言之,它允許向其他類型添加編譯時間約束。 在這種情況下 Int 只允許有可以表示連接埠號碼的16位元值。 這種配置方法不需要使用該函式庫。 看起來非常合適。
對於 HTTP(REST),我們可能還需要服務的路徑:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]]
case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)幻影型
為了在編譯期間識別協議,我們使用 Scala 聲明類型參數的功能 Protocol 課堂上沒有使用它。 這是一個所謂的 幻影型。 在運行時我們很少需要協議標識符的實例,這就是我們不儲存它的原因。 在編譯過程中,這種幻像類型提供了額外的類型安全性。 我們無法通過協定不正確的連接埠。
最廣泛使用的協定之一是具有 Json 序列化的 REST API:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]哪裡 RequestMessage 是客戶端可以發送到伺服器的訊息的基本類型 ResponseMessage 是來自伺服器的回應訊息。 當然,我們可以創建其他協定描述,以所需的精度指定通訊協定。
出於本文的目的,我們將使用該協議的更簡單版本:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]在此協定中,請求訊息附加到 url 中,回應訊息以純字串形式傳回。
服務配置可以透過服務名稱、連接埠集合和一些依賴項來描述。 有幾種可能的方法可以在 Scala 中表示所有這些元素(例如, HList,代數資料型態)。 出於本文的目的,我們將使用蛋糕模式並將可組合的部分(模組)表示為特徵。 (蛋糕模式不是這種可編譯配置方法的要求。它只是該想法的一種可能的實現。)
可以使用蛋糕模式作為其他節點的端點來表示依賴關係:
type EchoProtocol[A] = SimpleHttpGetRest[A, A]
trait EchoConfig[A] extends ServiceConfig {
def portNumber: PortNumber = 8081
def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo")
def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort)
}Echo 服務只需要設定一個連接埠。 並且我們聲明該連接埠支援echo協定。 請注意,我們此時不需要指定特定端口,因為特徵允許抽象方法聲明。 如果我們使用抽象方法,編譯器將需要在配置實例中實作。 這裡我們提供了實作(8081),如果我們在具體配置中跳過它,它將被用作預設值。
我們可以在 echo 服務客戶端的配置中聲明依賴項:
trait EchoClientConfig[A] {
def testMessage: String = "test"
def pollInterval: FiniteDuration
def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]]
}依賴項具有相同的類型 echoService。 特別是,它需要相同的協議。 因此,我們可以確定,如果我們連接這兩個依賴項,它們將正常工作。
服務實施
服務需要一個函數來啟動和正常關閉。 (關閉服務的能力對於測試至關重要。)同樣,有一些選項可以為給定的配置指定此類函數(例如,我們可以使用類型類別)。 在這篇文章中,我們將再次使用蛋糕圖案。 我們可以使用以下方式表示服務 cats.Resource 它已經提供了包圍和資源釋放。 為了獲取資源,我們應該提供配置和一些運行時上下文。 所以服務啟動函數可能如下所示:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]]
trait ServiceImpl[F[_]] {
type Config
def resource(
implicit
resolver: AddressResolver[F],
timer: Timer[F],
contextShift: ContextShift[F],
ec: ExecutionContext,
applicative: Applicative[F]
): ResourceReader[F, Config, Unit]
}哪裡
Config— 此服務啟動器所需的設定類型AddressResolver— 一個運行時對象,能夠獲取其他節點的真實地址(繼續閱讀以獲取詳細資訊)。
其他類型來自 cats:
F[_]— 效果類型(在最簡單的情況下F[A]可能只是() => A。 在這篇文章中我們將使用cats.IO.)Reader[A,B]— 或多或少是函數的同義詞A => Bcats.Resource- 有獲取和釋放的方法Timer— 允許睡眠/測量時間ContextShift- 類似物ExecutionContextApplicative— 有效的函數包裝器(幾乎是一個 monad)(我們最終可能會用其他東西替換它)
使用這個介面我們可以實作一些服務。 例如,一個不執行任何操作的服務:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] {
type Config <: Any
def resource(...): ResourceReader[F, Config, Unit] =
Reader(_ => Resource.pure[F, Unit](()))
}(見 對於其他服務實現 - ,
以及 .)
節點是運行一些服務的單一物件(透過蛋糕模式啟用啟動資源鏈):
object SingleNodeImpl extends ZeroServiceImpl[IO]
with EchoServiceService
with EchoClientService
with FiniteDurationLifecycleServiceImpl
{
type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig
}請注意,在節點中,我們指定了該節點所需的確切配置類型。 編譯器不會讓我們建構類型不足的物件(Cake),因為每個服務特徵都聲明了對 Config 類型。 此外,如果不提供完整的配置,我們將無法啟動節點。
節點位址解析
為了建立連接,我們需要每個節點的真實主機位址。 它可能比配置的其他部分更晚才知道。 因此,我們需要一種方法來提供節點 ID 與其實際位址之間的對應。 這個映射是一個函數:
case class NodeAddress[NodeId](host: Uri.Host)
trait AddressResolver[F[_]] {
def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]]
}有幾種可能的方法來實現這樣的功能。
- 如果我們在部署之前、節點主機實例化期間知道實際位址,那麼我們可以使用實際位址產生 Scala 程式碼,並在之後執行建置(執行編譯時檢查,然後執行整合測試套件)。 在這種情況下,我們的映射函數是靜態已知的,並且可以簡化為類似
Map[NodeId, NodeAddress]. - 有時我們只有在節點實際啟動後才能取得實際位址,或是我們沒有尚未啟動的節點的位址。 在這種情況下,我們可能有一個在所有其他節點之前啟動的發現服務,並且每個節點可能會在該服務中通告其位址並訂閱相依性。
- 如果我們可以修改
/etc/hosts,我們可以使用預先定義的主機名稱(例如my-project-main-node以及echo-backend)並在部署時將此名稱與 IP 位址相關聯。
在這篇文章中,我們不會更詳細地介紹這些案例。 事實上,在我們的玩具範例中,所有節點都將具有相同的 IP 位址 — 127.0.0.1.
在這篇文章中,我們將考慮兩種分散式系統佈局:
- 單節點佈局,所有服務都放在單一節點上。
- 雙節點佈局,服務和客戶端位於不同的節點上。
配置為 佈局如下:
單節點配置
object SingleNodeConfig extends EchoConfig[String]
with EchoClientConfig[String] with FiniteDurationLifecycleConfig
{
case object Singleton // identifier of the single node
// configuration of server
type NodeId = Singleton.type
def nodeId = Singleton
/** Type safe service port specification. */
override def portNumber: PortNumber = 8088
// configuration of client
/** We'll use the service provided by the same host. */
def echoServiceDependency = echoService
override def testMessage: UrlPathElement = "hello"
def pollInterval: FiniteDuration = 1.second
// lifecycle controller configuration
def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 requests, not 9.
}在這裡,我們建立一個擴展伺服器和客戶端配置的單一配置。 我們也配置了一個生命週期控制器,通常會在之後終止客戶端和伺服器 lifetime 間隔過去了。
同一組服務實作和配置可用於建立具有兩個獨立節點的系統佈局。 我們只需要創建 提供適當的服務:
兩個節點配置
object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig
{
type NodeId = NodeIdImpl
def nodeId = NodeServer
override def portNumber: PortNumber = 8080
}
object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig
{
// NB! dependency specification
def echoServiceDependency = NodeServerConfig.echoService
def pollInterval: FiniteDuration = 1.second
def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 request, not 9.
def testMessage: String = "dolly"
}看看我們如何指定依賴關係。 我們將另一個節點提供的服務作為當前節點的依賴項。 檢查依賴類型,因為它包含描述協定的幻像類型。 在運行時我們將獲得正確的節點 ID。 這是所提出的配置方法的重要方面之一。 它使我們能夠僅設置一次連接埠並確保我們引用正確的連接埠。
兩個節點實現
對於此配置,我們使用完全相同的服務實作。 完全沒有變化。 但是,我們創建了兩個不同的節點實現,其中包含不同的服務集:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl {
type Config = EchoConfig[String] with SigTermLifecycleConfig
}
object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl {
type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig
}第一個節點實作伺服器,它只需要伺服器端配置。 第二個節點實作客戶端並需要配置的另一部分。 兩個節點都需要一些生命週期規格。 出於本次發布的目的,服務節點將具有無限的生命週期,可以使用以下方式終止: SIGTERM,而 echo 用戶端將在配置的有限持續時間後終止。 請參閱 洽詢詳情。
整體開發流程
讓我們看看這種方法如何改變我們使用配置的方式。
配置即程式碼將被編譯並產生一個工件。 將配置工件與其他程式碼工件分開似乎是合理的。 通常我們可以在同一個程式碼庫上有多種配置。 當然,我們可以擁有各種配置分支的多個版本。 在配置中,我們可以選擇特定版本的庫,並且每當我們部署此配置時,這將保持不變。
配置更改變成程式碼更改。 因此,它應該包含在相同的品質保證流程中:
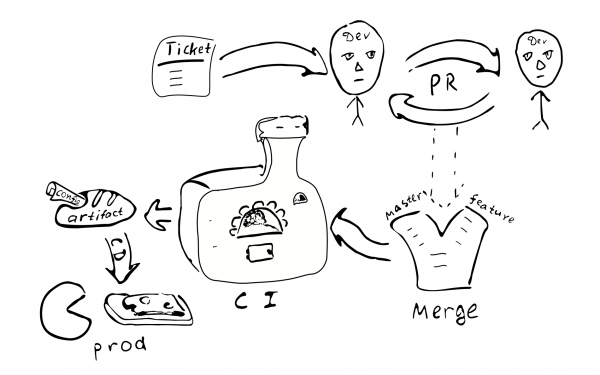
工單 -> PR -> 審核 -> 合併 -> 持續整合 -> 持續部署
此方法會產生以下後果:
- 此配置對於特定係統的實例是一致的。 看來沒有辦法讓節點之間出現錯誤的連結。
- 僅在一個節點中更改配置並不容易。 登入並更改一些文字檔案似乎不合理。 因此配置漂移的可能性變得較小。
- 小的配置更改並不容易。
- 大多數配置變更將遵循相同的開發流程,並且會通過一些審查。
我們是否需要一個單獨的儲存庫來進行生產配置? 生產配置可能包含我們希望讓許多人無法接觸到的敏感資訊。 因此,可能值得保留一個具有受限存取權限的單獨儲存庫,其中包含生產配置。 我們可以將配置分為兩部分 - 一部分包含最開放的生產參數,另一部分包含配置的秘密部分。 這將使大多數開發人員能夠存取絕大多數參數,同時限制對真正敏感內容的存取。 使用帶有預設參數值的中間特徵可以輕鬆實現這一點。
變化
讓我們看看所提出的方法與其他配置管理技術相比的優缺點。
首先,我們將列出處理配置的建議方法的不同方面的一些替代方案:
- 目標機器上的文字檔案。
- 集中式鍵值儲存(例如
etcd/zookeeper). - 可以在不重新啟動進程的情況下重新配置/重新啟動的子進程組件。
- 工件和版本控制之外的配置。
文字檔案在臨時修復方面提供了一定的靈活性。 系統管理員可以登入目標節點,進行變更並簡單地重新啟動服務。 對於更大的系統來說,這可能不太好。 變化沒有留下任何痕跡。 這項改變不會被另一雙眼睛所審視。 可能很難找出導致這種變化的原因。 它還沒有經過測試。 從分散式系統的角度來看,管理員可能只是忘記更新其他節點之一中的配置。
(順便說一句,如果最終需要開始使用文字配置文件,我們只需要添加可以產生相同結果的解析器+驗證器 Config 輸入,這足以開始使用文字配置。 這也表明編譯時配置的複雜度比基於文字的配置的複雜度要小一些,因為在基於文字的版本中我們需要一些額外的程式碼。)
集中式鍵值儲存是分發應用程式元參數的良好機制。 這裡我們需要思考什麼是我們認為的配置值,什麼只是數據。 給定一個函數 C => A => B 我們通常稱之為很少改變的值 C “配置”,而經常更改的數據 A - 只需輸入資料。 配置應該早於資料提供給函數 A。 考慮到這個想法,我們可以說,預期的變化頻率可用於區分配置資料和普通資料。 此外,資料通常來自一個來源(使用者),而配置來自不同的來源(管理員)。 處理初始化過程後可以更改的參數會導致應用程式複雜度增加。 對於這些參數,我們必須處理它們的傳遞機制、解析和驗證,以及處理不正確的值。 因此,為了降低程式複雜性,我們最好減少運行時可以更改的參數數量(甚至完全消除它們)。
從這篇文章的角度來看,我們應該要區分靜態參數和動態參數。 如果服務邏輯需要在運行時很少更改某些參數,那麼我們可以將它們稱為動態參數。 否則它們是靜態的,可以使用建議的方法進行配置。 對於動態重新配置,可能需要其他方法。 例如,系統的某些部分可能會使用新的設定參數重新啟動,方式與重新啟動分散式系統的單獨程序類似。
(我的拙見是避免運行時重新配置,因為它增加了系統的複雜性。
僅依靠作業系統對重新啟動進程的支援可能會更直接。 不過,這可能並不總是可行。)
使用靜態配置有時會讓人考慮動態配置(沒有其他原因)的一個重要方面是配置更新期間的服務停機。 確實,如果我們必須對靜態配置進行更改,我們就必須重新啟動系統以使新值生效。 不同系統對停機時間的要求有所不同,因此可能不那麼重要。 如果很重要,那麼我們必須提前規劃任何系統重新啟動。 例如,我們可以實現 。 在這種情況下,每當我們需要重新啟動系統時,我們都會並行啟動系統的新實例,然後將 ELB 切換到它,同時讓舊系統完成現有連線的服務。
將配置保留在版本化工件內部還是外部怎麼樣? 將配置保留在工件內意味著在大多數情況下該配置已通過與其他工件相同的品質保證流程。 因此,人們可以確信配置品質良好且值得信賴。 相反,單獨文件中的配置意味著沒有任何痕跡表明誰以及為什麼對該文件進行了更改。 這重要嗎? 我們相信,對於大多數生產系統來說,擁有穩定且高品質的配置會更好。
工件的版本可找出它的建立時間、包含哪些值、啟用/停用哪些功能、誰負責在組態中進行每個變更。 可能需要付出一些努力才能將配置保留在工件內,這是一個設計選擇。
優點缺點
在這裡,我們想強調一些優點並討論所提出方法的一些缺點。
優點
完整的分散式系統的可編譯配置的特點:
- 配置的靜態檢查。 這給出了高度的置信度,在給定類型約束的情況下配置是正確的。
- 豐富的配置語言。 通常,其他配置方法最多僅限於變數替換。
使用 Scala 可以利用多種語言特性來更好地進行配置。 例如我們可以使用traits提供預設值,使用objects來設定不同的作用域,我們可以參考vals 在外部作用域中僅定義一次 (DRY)。 可以使用文字序列或某些類別的實例(Seq,Map等)。 - DSL。 Scala 對 DSL 編寫器提供了良好的支援。 人們可以利用這些特性建立一種更方便、對最終用戶友好的配置語言,使得最終的配置至少對網域用戶是可讀的。
- 節點間的完整性和一致性。 在一個地方對整個分散式系統進行配置的好處之一是所有值都嚴格定義一次,然後在我們需要它們的所有地方重複使用。 此外,類型安全連接埠聲明可確保在所有可能的正確配置中,系統節點將使用相同的語言。 節點之間存在明確的依賴關係,這使得很難忘記提供某些服務。
- 高品質的變革。 透過正常 PR 流程傳遞配置變更的整體方法也在配置中建立了高品質標準。
- 同時更改配置。 每當我們對配置進行任何更改時,自動部署都會確保所有節點都已更新。
- 應用程式簡化。 應用程式不需要解析和驗證配置以及處理不正確的配置值。 這簡化了整體應用程式。 (配置本身會增加一些複雜性,但這是對安全性的有意識的權衡。)返回到普通配置非常簡單 - 只需添加缺少的部分即可。 開始使用已編譯的配置並將其他部分的實作推遲到以後會更容易。
- 版本化配置。 由於配置變更遵循相同的開發流程,因此我們得到了具有唯一版本的工件。 它允許我們在需要時切換回配置。 我們甚至可以部署一年前使用的配置,它的工作方式完全相同。 穩定的配置提高了分散式系統的可預測性和可靠性。 配置在編譯時是固定的,並且在生產系統上不容易被篡改。
- 模組化。 所提出的框架是模組化的,模組可以以各種方式組合
支援不同的配置(設定/佈局)。 特別是,可以進行小規模的單節點佈局和大規模的多節點設定。 多種生產佈局是合理的。 - 測試。 出於測試目的,人們可以實現模擬服務並以類型安全的方式將其用作依賴項。 可以同時維護一些不同的測試佈局,其中各個部分被模擬替換。
- 集成測試。 有時在分散式系統中很難執行整合測試。 使用所描述的方法對完整的分散式系統進行類型安全性配置,我們可以以可控的方式在單一伺服器上運行所有分散式部分。 很容易模擬狀況
當其中一項服務不可用時。
缺點
編譯的配置方法與「正常」配置不同,它可能無法滿足所有需求。 以下是編譯配置的一些缺點:
- 靜態配置。 它可能不適合所有應用程式。 在某些情況下,需要繞過所有安全措施以快速修復生產中的配置。 這種方法使事情變得更加困難。 對配置進行任何更改後都需要編譯和重新部署。 這既是特徵,也是負擔。
- 配置生成。 當某些自動化工具產生配置時,此方法需要後續編譯(這可能會失敗)。 可能需要額外的努力才能將這個額外的步驟整合到建置系統中。
- 儀器。 目前使用的許多工具都依賴於基於文字的配置。 他們中有一些
編譯配置時將不適用。 - 需要轉變思維方式。 開發人員和 DevOps 熟悉文字設定檔。 編譯配置的想法對他們來說可能會顯得很奇怪。
- 在引入可編譯配置之前,需要高品質的軟體開發過程。
實施的範例有一些限制:
- 如果我們提供節點實作不需要的額外配置,編譯器將無法幫助我們偵測缺少的實作。 這可以透過使用來解決
HList或 ADT(案例類)用於節點配置,而不是特徵和蛋糕模式。 - 我們必須在設定檔中提供一些樣板:(
package,import,object聲明;
override def用於具有預設值的參數)。 使用 DSL 可以部分解決這個問題。 - 在這篇文章中,我們不討論相似節點叢集的動態重新配置。
結語
在這篇文章中,我們討論了以類型安全的方式直接在原始程式碼中表示配置的想法。 該方法可在許多應用程式中用作 xml 和其他基於文字的配置的替代。 儘管我們的範例是用 Scala 實現的,但它也可以翻譯為其他可編譯語言(如 Kotlin、C#、Swift 等)。 人們可以在新專案中嘗試這種方法,如果它不適合,則切換到老式方法。
當然,可編譯的配置需要高品質的開發過程。 作為回報,它承諾提供同樣高品質的穩健配置。
這種方法可以透過多種方式擴展:
- 人們可以使用巨集來執行組態驗證,並在編譯時失敗,以防出現任何業務邏輯約束失敗。
- 可以實作 DSL 來以網域使用者友善的方式表示配置。
- 具有自動配置調整的動態資源管理。 例如,當我們調整叢集節點的數量時,我們可能希望(1)節點獲得稍微修改的配置; (2)叢集管理器接收新節點資訊。
謝謝
我要感謝安德烈·薩克索諾夫(Andrey Saksonov)、帕維爾·波波夫(Pavel Popov)、安東·內哈耶夫(Anton Nehaev) 對本文草稿提供的鼓舞人心的反饋,幫助我把它弄得更清楚。
來源: www.habr.com
