


團隊 優惠 Clairvoyant 工程師 Rahul Bhatia 介紹了大數據中的文件格式、Hadoop 格式的最常見功能是什麼以及最好使用哪種格式。
為什麼需要不同的文件格式?
支援 HDFS 的應用程式(例如 MapReduce 和 Spark)的主要效能瓶頸是搜尋、讀取和寫入資料所需的時間。如果我們擁有不斷發展的而不是固定的模式,或者存在一些儲存限制,那麼管理大型資料集的困難就會加劇這些問題。
處理大數據會增加儲存子系統的負載——Hadoop 以冗餘方式儲存資料以實現容錯能力。除了磁碟之外,還要載入處理器、網路、輸入/輸出系統等。隨著資料量的成長,處理和儲存資料的成本也會增加。
不同的文件格式 正是為了解決這些問題而發明的。選擇正確的文件格式可以帶來一些顯著的好處:
- 閱讀時間更快。
- 錄音時間更快。
- 共享文件。
- 支持模式演變。
- 增強壓縮支援。
有些文件格式適合一般用途,有些則比較具體,有些文件格式在設計時考慮了特定的資料特性。所以選擇範圍確實很大。
Avro 檔案格式
為 數據序列化 Avro 被廣泛使用 - 這是 基於字串,即Hadoop中基於字串的資料儲存格式。它以 JSON 格式儲存模式,使任何程式都可以輕鬆讀取和解釋。資料本身是二進位格式,緊湊、有效率。
Avro 序列化系統與語言無關。檔案可以用不同的語言處理,目前包括 C、C++、C#、Java、Python 和 Ruby。
Avro 的一個關鍵特性是它對隨時間而變化(即演進)的資料模式的強大支援。 Avro 了解模式變更-刪除、新增或變更欄位。
Avro 支援多種資料結構。例如,您可以建立一個包含陣列、枚舉類型和子記錄的記錄。
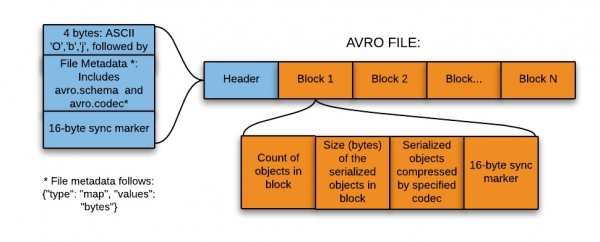
這種格式非常適合寫入資料湖的著陸區(過渡區)(或資料湖 - 除資料來源本身之外,用於儲存各種類型資料的實例集合)。
因此,對於寫入資料湖登陸區,這種格式最適合,原因如下:
- 該區域的資料通常會被完整讀取以供下游系統進一步處理 - 在這種情況下基於行的格式更有效。
- 下游系統可以輕鬆地從文件中提取模式表 - 無需在外部元存儲中單獨存儲模式。
- 對原始模式的任何更改都可以輕鬆處理(模式演變)。
Parquet 檔案格式
Parquet 是 Hadoop 的一種開源檔案格式,用於存儲 平面列格式的嵌套資料結構.
與傳統的基於行的方法相比,Parquet 在儲存和效能方面更有效率。
這對於從寬(多列)表中讀取特定列的查詢特別有用。該檔案格式確保只讀取必要的列,因此 I/O 保持在最低限度。
一點題外話解釋:為了更好地理解 Hadoop 中的 Parquet 檔案格式,讓我們看看基於列的格式(即列式格式)是什麼。在這種格式中,每列的相同值儲存在一起。
,該記錄包括欄位ID、姓名和部門。在這種情況下,ID 欄位的所有值將儲存在一起,Name 欄位的值也會儲存在一起,依此類推。該表看起來將類似於以下內容:
ID
名稱
參觀商店
1
emp1
d1
2
emp2
d2
3
emp3
d3
以字串格式,資料將保存如下:
1
emp1
d1
2
emp2
d2
3
emp3
d3
在列式檔案格式中,相同的資料將儲存如下:
1
2
3
emp1
emp2
emp3
d1
d2
d3
當您需要從表格中查詢多個列時,列式格式會更有效。它只會讀取所需的列,因為它們是相鄰的。因此,I/O 操作被減少到最低限度。
例如,您只需要 NAME 列。在 需要載入資料集中的每筆記錄,解析為字段,然後提取 NAME 資料。列式格式可讓您直接跳到名稱列,因為該列的所有值都儲存在一起。您不必掃描整個記錄。
因此,列式格式提高了查詢效能,因為它花費較少的查找時間來取得所需的列,並且由於只讀取所需的列而減少了 I/O 操作。
獨特的功能之一 在這種格式下它可以 使用嵌套結構儲存數據。這意味著在 Parquet 檔案中,即使是巢狀欄位也可以單獨讀取,而不必讀取嵌套結構中的所有欄位。為了儲存嵌套結構,Parquet 使用了分解和組裝演算法。
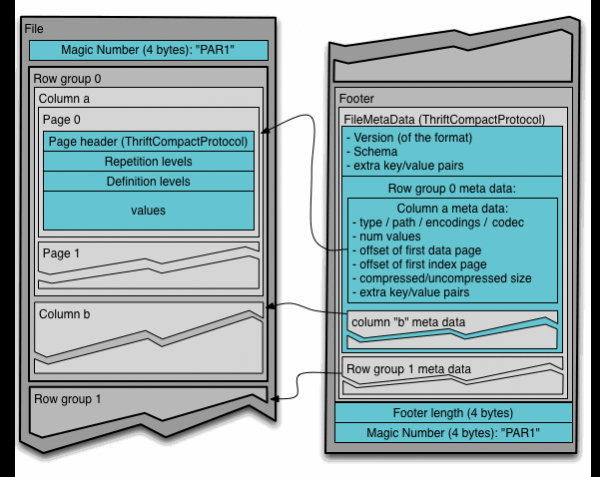
要了解 Hadoop 中的 Parquet 檔案格式,您需要了解以下術語:
- 線組 (行組):將資料依邏輯水平劃分為行。行組由資料集中每列的一部分組成。
- 列片段 (列塊):特定列的片段。這些列碎片位於特定的行組中,並保證在文件中連續。
- 頁 (頁):列片段被分成一個接一個寫入的頁面。這些頁面有一個共同的標題,因此您在閱讀時可以跳過不需要的頁面。
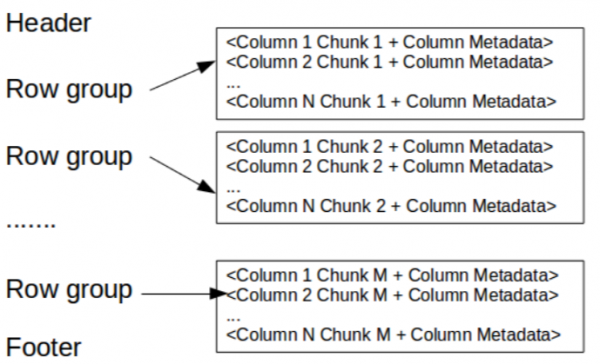
這裡的標題只是包含神奇的數字 PAR1 (4 個位元組)用於標識該檔案為 Parquet 格式的檔案。
頁尾內容如下:
- 包含每列元資料的起始座標的檔案元資料。讀取時,必須先讀取檔案的元數據,找到所有感興趣的列片段。然後應依序讀取列片段。元資料還包括格式版本、架構和任何其他鍵值對。
- 元資料長度(4位元組)。
- 神奇數字 PAR1 (4個位元組)。
ORC 文件格式
優化的行列文件格式 (優化行列式, ) 提供了一種非常有效的資料儲存方式,旨在克服其他格式的限制。以完美緊湊的形式儲存數據,使您能夠跳過不必要的細節 - 而無需建立大型、複雜或手動維護的索引。
ORC格式的優點:
- 每個任務輸出一個文件,從而減少 NameNode 上的負載。
- 支援 Hive 資料類型,包括 DateTime、十進位和複雜資料類型(struct、list、map 和 union)。
- 不同的 RecordReader 進程同時讀取同一個檔案。
- 無需掃描標記即可分割檔案。
- 根據檔案頁腳中資訊的估計讀取/寫入進程可能的最大堆記憶體分配。
- 元資料以稱為協定緩衝區的二進位序列化格式存儲,允許新增和刪除欄位。
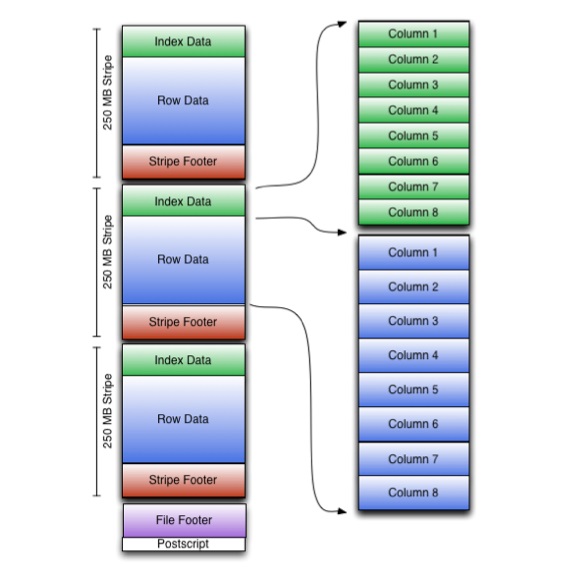
ORC 將行集合儲存在單一檔案中,並且在集合內,行資料以列式格式儲存。
ORC 檔案在檔案頁腳中儲存稱為條紋的行組和輔助資訊。文件末端的附言包含壓縮參數和壓縮頁腳的大小。
預設條帶大小為 250 MB。由於條帶尺寸如此之大,從 HDFS 讀取資料可以更有效率地進行:以大的連續區塊形式。
文件頁腳包含文件中的條帶清單、每個條帶的行數以及每列的資料類型。每列的計數、最小值、最大值和總和的結果值也寫在那裡。
條帶的頁腳包含流位置的目錄。
掃描表時使用行資料。
索引資料包括每列的最小值和最大值以及每列內行的位置。 ORC 索引僅用於選擇條帶和行組,而不是用於回答查詢。
不同文件格式的比較
Avro 與 Parquet
- Avro 是一種面向行的儲存格式,而 Parquet 以列的形式儲存資料。
- Parquet 更適合分析查詢,這意味著讀取和查詢資料比寫入效率高得多。
- Avro 的寫入效率比 Parquet 更高。
- Avro 在處理模式演變方面更加成熟。 Parquet 僅支援模式添加,而 Avro 具有多功能演進,即添加或更改列。
- Parquet 非常適合查詢多個清單中的列子集。 Avro 適用於查詢所有欄位的 ETL 操作。
ORC 與 Parquet
- Parquet 可以更好地儲存巢狀資料。
- ORC 比較適合謂詞下推。
- ORC 支援 ACID 屬性。
- ORC 具有更好的資料壓縮。
關於該主題還可以閱讀什麼:
- .
- .
- .
來源: www.habr.com
