

今年,主要的歐洲 Kubernetes 會議 - KubeCon + CloudNativeCon Europe 2020 - 是虛擬的。 不過,這樣的格式變化並沒有妨礙我們交付蓄謀已久的報告《走? 猛擊! 認識 Shell 操作員」致力於我們的開源項目 .
本文受演講啟發,提出了一種簡化為 Kubernetes 創建運算符的過程的方法,並展示瞭如何使用 shell 運算符以最少的努力創建自己的運算符。

介紹 (大約 23 分鐘的英文,明顯比文章豐富)以及文本形式的主要摘錄。 去!
在 Flant,我們不斷優化和自動化一切。 今天我們將討論另一個令人興奮的概念。 見面: 雲端原生 shell 腳本!
然而,讓我們從這一切發生的背景開始:Kubernetes。
Kubernetes API 和控制器
Kubernetes 中的 API 可以表示為一種檔案伺服器,其中包含每種類型物件的目錄。 此伺服器上的物件(資源)由 YAML 檔案表示。 此外,伺服器還有一個基本的 API,可讓您執行三件事:
- 收到 資源的種類和名稱;
- 改變 資源(在這種情況下,伺服器僅儲存「正確」的物件 - 所有格式不正確或用於其他目錄的物件都將被丟棄);
- 追踪 對於資源(在這種情況下,用戶立即收到其當前/更新版本)。
因此,Kubernetes 充當一種檔案伺服器(用於 YAML 清單),具有三種基本方法(是的,實際上還有其他方法,但我們現在將忽略它們)。

問題是伺服器只能儲存資訊。 為了讓它發揮作用,你需要 調節器 - Kubernetes 世界中第二重要和基本的概念。
有兩種主要類型的控制器。 第一個從 Kubernetes 獲取信息,根據嵌套邏輯對其進行處理,然後將其返回給 K8s。 第二種從 Kubernetes 獲取訊息,但與第一種不同的是,它會更改某些外部資源的狀態。
讓我們仔細看看 Kubernetes 中建立 Deployment 的過程:
- 部署控制器(包含在
kube-controller-manager)接收有關 Deployment 的資訊並建立 ReplicaSet。 - ReplicaSet 會根據此資訊建立兩個副本(兩個 Pod),但這些 Pod 尚未調度。
- 調度程式調度 Pod 並將節點資訊新增至其 YAML 中。
- Kubelet 對外部資源(例如 Docker)進行更改。
然後以相反的順序重複整個序列:kubelet 檢查容器,計算 pod 的狀態並將其發回。 ReplicaSet 控制器接收狀態並更新副本集的狀態。 部署控制器也會發生同樣的事情,使用者最終獲得更新的(目前)狀態。
Shell 運算符
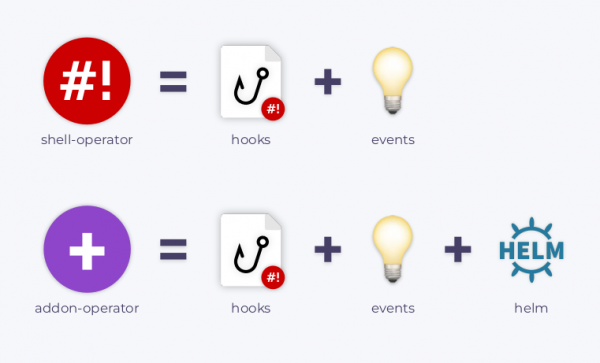
事實證明,Kubernetes 是基於各種控制器的共同工作(Kubernetes 操作員也是控制器)。 問題來了,如何以最少的努力創建自己的操作符? 我們開發的這款產品可以拯救您 。 它允許系統管理員使用熟悉的方法建立自己的報表。
簡單的例子:複製秘密
讓我們來看一個簡單的例子。
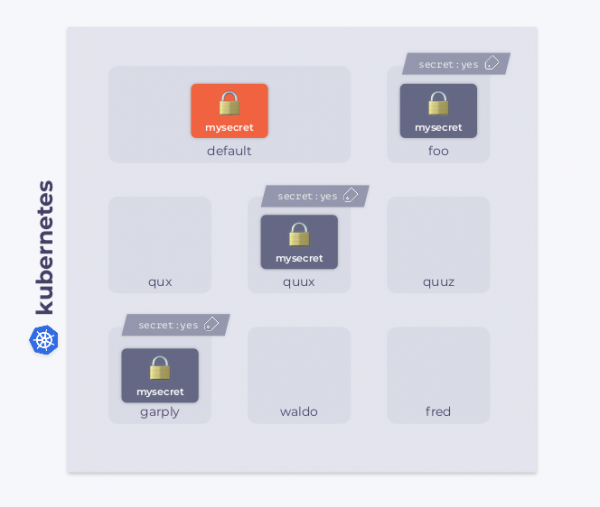
假設我們有一個 Kubernetes 叢集。 它有一個命名空間 default 帶著一些秘密 mysecret。 此外,集群中還有其他命名空間。 其中一些貼有特定的標籤。 我們的目標是將 Secret 複製到帶有標籤的命名空間中。
由於叢集中可能出現新的命名空間,並且其中一些命名空間可能具有此標籤,因此任務變得複雜。 另一方面,當標籤被刪除時,Secret也應該被刪除。 除此之外,Secret 本身也可以更改:在這種情況下,必須將新的 Secret 複製到所有帶有標籤的命名空間。 如果任何命名空間中的 Secret 被意外刪除,我們的操作員應該立即恢復它。
現在任務已經制定完畢,是時候開始使用 shell 運算子來實現它了。 但首先值得談談 shell 運算子本身。
shell 操作符如何運作
與 Kubernetes 中的其他工作負載一樣,shell-operator 在自己的 pod 中運作。 在這個pod目錄下 /hooks 儲存可執行檔。 這些可以是 Bash、Python、Ruby 等中的腳本。 我們稱這樣的可執行檔為鉤子(掛鉤).
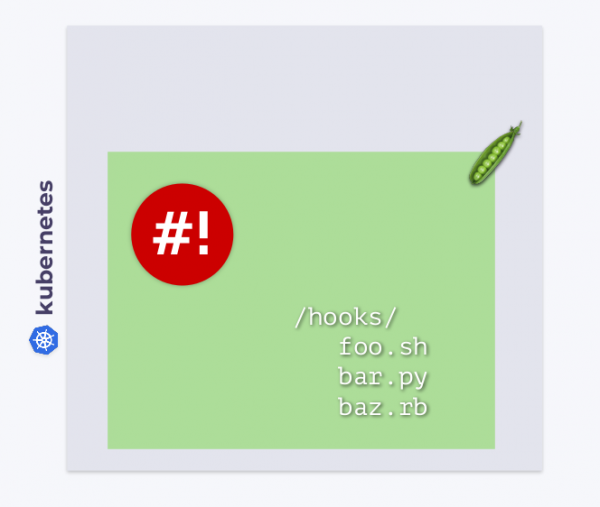
Shell-operator 訂閱 Kubernetes 事件並執行這些鉤子來回應我們需要的事件。
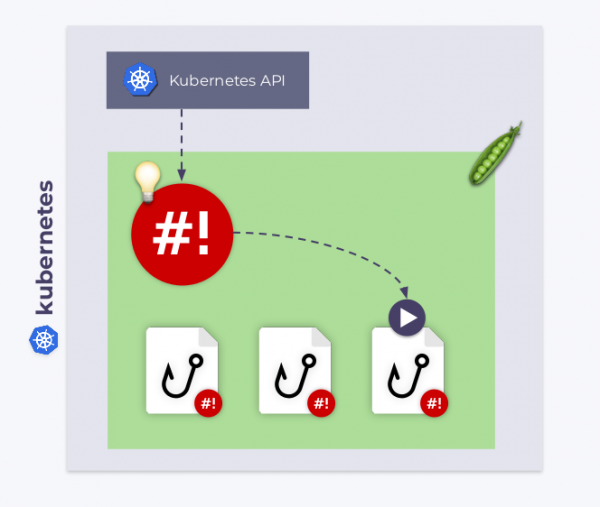
shell 操作員如何知道要執行哪個鉤子以及何時執行? 重點是每個鉤子都有兩個階段。 在啟動期間,shell 操作符運行帶有參數的所有鉤子 --config 這是配置階段。 之後,掛鉤以正常方式啟動 - 回應它們所附加的事件。 在後一種情況下,鉤子接收綁定上下文(綁定上下文) - JSON 格式的數據,我們將在下面更詳細地討論。
在 Bash 中建立一個運算符
現在我們已準備好實施。 為此,我們需要編寫兩個函數(順便說一下,我們建議 圖書館 ,這大大簡化了在 Bash 中編寫鉤子):
- 第一個是配置階段所需要的 - 它顯示綁定上下文;
- 第二個包含鉤子的主要邏輯。
#!/bin/bash
source /shell_lib.sh
function __config__() {
cat << EOF
configVersion: v1
# BINDING CONFIGURATION
EOF
}
function __main__() {
# THE LOGIC
}
hook::run "$@"
下一步是決定我們需要什麼物件。 在我們的例子中,我們需要追蹤:
- 更改的來源秘密;
- 叢集中的所有命名空間,以便您知道哪些命名空間附加了標籤;
- 目標機密以確保它們全部與來源機密同步。
訂閱秘密來源
它的綁定配置非常簡單。 我們表明我們對名稱為 Secret 感興趣 mysecret 在命名空間中 default:
function __config__() {
cat << EOF
configVersion: v1
kubernetes:
- name: src_secret
apiVersion: v1
kind: Secret
nameSelector:
matchNames:
- mysecret
namespace:
nameSelector:
matchNames: ["default"]
group: main
EOF
因此,當來源秘密發生變化時,鉤子將被觸發(src_secret)並接收以下綁定上下文:
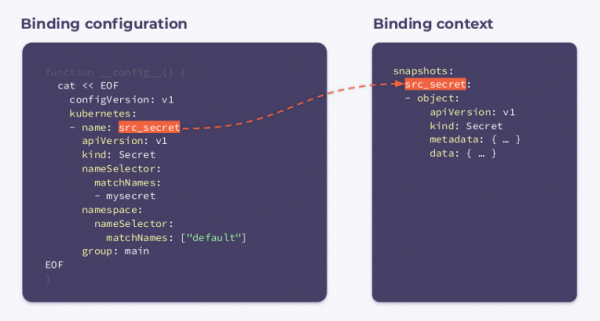
如您所見,它包含名稱和整個物件。
追蹤命名空間
現在您需要訂閱名稱空間。 為此,我們指定以下綁定配置:
- name: namespaces
group: main
apiVersion: v1
kind: Namespace
jqFilter: |
{
namespace: .metadata.name,
hasLabel: (
.metadata.labels // {} |
contains({"secret": "yes"})
)
}
group: main
keepFullObjectsInMemory: false
如您所見,配置中出現了一個新字段,其名稱為 jqFilter. 顧名思義, jqFilter 過濾掉所有不必要的信息,並使用我們感興趣的欄位建立一個新的 JSON 物件。 具有類似配置的鉤子將接收以下綁定上下文:
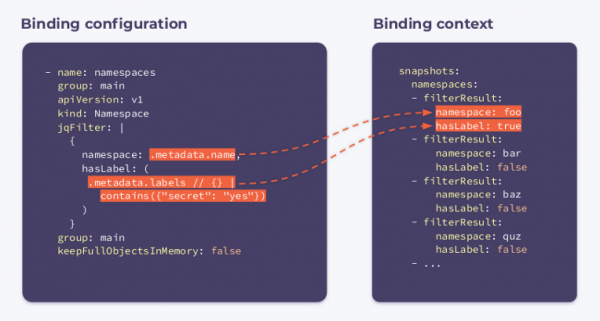
它包含一個數組 filterResults 對於叢集中的每個命名空間。 布林變數 hasLabel 指示標籤是否附加到給定的命名空間。 選擇器 keepFullObjectsInMemory: false 表示不需要在記憶體中保留完整的物件。
追蹤目標秘密
我們訂閱所有指定了註解的 Secret managed-secret: "yes" (這些都是我們的目標 dst_secrets):
- name: dst_secrets
apiVersion: v1
kind: Secret
labelSelector:
matchLabels:
managed-secret: "yes"
jqFilter: |
{
"namespace":
.metadata.namespace,
"resourceVersion":
.metadata.annotations.resourceVersion
}
group: main
keepFullObjectsInMemory: false
在這種情況下 jqFilter 過濾掉除命名空間和參數之外的所有訊息 resourceVersion。 最後一個參數在建立機密時傳遞給註解:它允許您比較機密的版本並使其保持最新。
以這種方式配置的鉤子在執行時將接收上述三個綁定上下文。 它們可以被認為是一種快照(快照) 簇。

基於所有這些信息,可以開發基本演算法。 它迭代所有名稱空間並且:
- 如果
hasLabel事項true對於目前命名空間:- 將全域秘密與本地秘密進行比較:
- 如果它們相同,則不執行任何操作;
- 如果它們不同 - 執行
kubectl replace或create;
- 將全域秘密與本地秘密進行比較:
- 如果
hasLabel事項false對於目前命名空間:- 確保 Secret 不在給定的命名空間中:
- 如果本地 Secret 存在,請使用刪除它
kubectl delete; - 如果未偵測到本機 Secret,則不執行任何操作。
- 如果本地 Secret 存在,請使用刪除它
- 確保 Secret 不在給定的命名空間中:

您可以在我們的下載 .
這就是我們如何使用 35 行 YAML 配置和大約相同數量的 Bash 程式碼來建立簡單的 Kubernetes 控制器! shell 操作符的工作是將它們連接在一起。
然而,複製機密並不是該實用程式的唯一應用領域。 這裡還有幾個例子來展示他的能力。
範例 1:對 ConfigMap 進行更改
讓我們來看看由三個 Pod 組成的 Deployment。 Pod 使用 ConfigMap 來儲存一些設定。 當 Pod 啟動時,ConfigMap 處於某種狀態(我們稱之為 v.1)。 因此,所有 Pod 都使用此特定版本的 ConfigMap。
現在我們假設 ConfigMap 已更改 (v.2)。 但是,Pod 將使用先前版本的 ConfigMap (v.1):
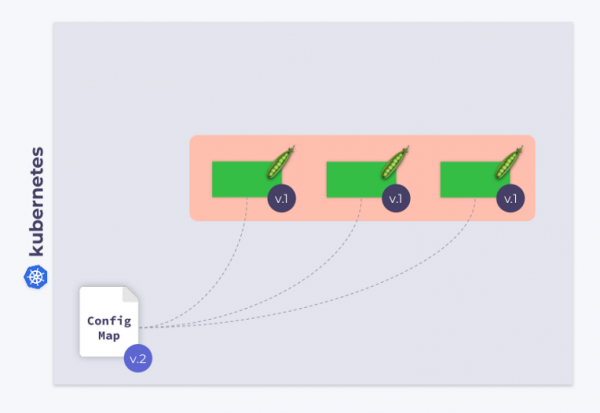
我怎麼能讓他們切換到新的 ConfigMap (v.2)? 答案很簡單:使用模板。 讓我們在該部分中添加一個校驗和註釋 template 部署配置:

結果,這個校驗和將被註冊到所有的 pod 中,並且它將與 Deployment 的校驗和相同。 現在您只需要在 ConfigMap 更改時更新註解即可。 在這種情況下,shell 運算子就派上用場了。 您所需要做的就是編程 一個將訂閱 ConfigMap 並更新校驗和的鉤子.
如果使用者對 ConfigMap 進行更改,shell 操作員將注意到它們並重新計算校驗和。 之後 Kubernetes 的魔力將發揮作用:編排器將殺死 pod,創建一個新的 pod,等待它成為 Ready,然後繼續下一個。 這樣一來,Deployment就會同步並切換到新版本的ConfigMap。
範例 2:使用自訂資源定義
如您所知,Kubernetes 允許您建立自訂類型的物件。 例如,您可以建立種類 MysqlDatabase。 假設該類型有兩個元資料參數: name и namespace.
apiVersion: example.com/v1alpha1
kind: MysqlDatabase
metadata:
name: foo
namespace: bar
我們有一個具有不同命名空間的 Kubernetes 集群,可以在其中建立 MySQL 資料庫。 在這種情況下,可以使用 shell-operator 來追蹤資源 MysqlDatabase,將它們連接到 MySQL 伺服器並同步叢集的所需狀態和觀察到的狀態。
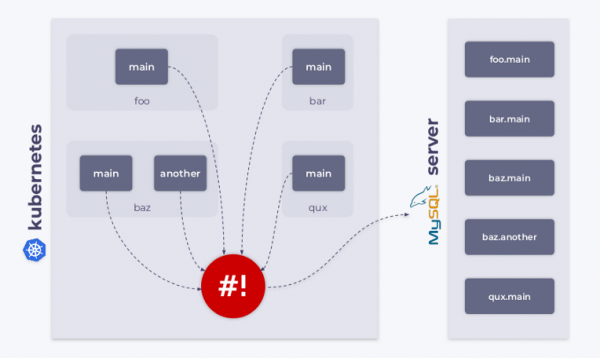
範例3:叢集網路監控
如您所知,使用 ping 是監控網路最簡單的方法。 在這個範例中,我們將展示如何使用 shell-operator 來實現這樣的監控。
首先,您需要訂閱節點。 shell 操作員需要每個節點的名稱和 IP 位址。 在他們的幫助下,他將 ping 這些節點。
configVersion: v1
kubernetes:
- name: nodes
apiVersion: v1
kind: Node
jqFilter: |
{
name: .metadata.name,
ip: (
.status.addresses[] |
select(.type == "InternalIP") |
.address
)
}
group: main
keepFullObjectsInMemory: false
executeHookOnEvent: []
schedule:
- name: every_minute
group: main
crontab: "* * * * *"
參數 executeHookOnEvent: [] 防止鉤子運行以回應任何事件(即回應變更、新增、刪除節點)。 然而,他 會跑 (並更新節點清單) 預定 - 每分鐘,依現場規定 schedule.
現在問題來了,我們到底如何知道丟包等問題呢? 我們來看一下程式碼:
function __main__() {
for i in $(seq 0 "$(context::jq -r '(.snapshots.nodes | length) - 1')"); do
node_name="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.name')"
node_ip="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.ip')"
packets_lost=0
if ! ping -c 1 "$node_ip" -t 1 ; then
packets_lost=1
fi
cat >> "$METRICS_PATH" <<END
{
"name": "node_packets_lost",
"add": $packets_lost,
"labels": {
"node": "$node_name"
}
}
END
done
}
我們遍歷節點列表,取得它們的名稱和 IP 位址,對它們進行 ping 操作並將結果傳送到 Prometheus。 Shell-operator 可以將指標匯出到 Prometheus,將它們保存到根據環境變數中指定的路徑定位的檔案中 $METRICS_PATH.
您可以在叢集中建立一個操作員來進行簡單的網路監控。
排隊機制
如果不描述 shell 操作符中內建的另一個重要機制,本文將是不完整的。 想像一下,它執行某種鉤子來回應叢集中的事件。
- 如果集群中同時發生某些情況,會發生什麼情況? 多一個 事件?
- shell-operator 會運行鉤子的另一個實例嗎?
- 比如說,如果叢集中同時發生五個事件怎麼辦?
- shell 運算子會並行處理它們嗎?
- 消耗的資源(例如記憶體和CPU)怎麼樣?
幸運的是,shell-operator 有一個內建的排隊機制。 所有事件都按順序排隊和處理。
讓我們用例子來說明這一點。 假設我們有兩個鉤子。 第一個事件進入第一個鉤子。 一旦處理完成,佇列就會向前移動。 接下來的三個事件被重定向到第二個鉤子 - 它們被從佇列中刪除並以「捆綁」的形式進入佇列。 那是 鉤子接收事件數組 ——或者更準確地說,是一組綁定上下文。
還有這些 事件可以合併為一個大事件。 此參數負責此操作 group 在綁定配置中。

您可以建立任意數量的隊列/掛鉤及其各種組合。 例如,一個佇列可以使用兩個鉤子,反之亦然。
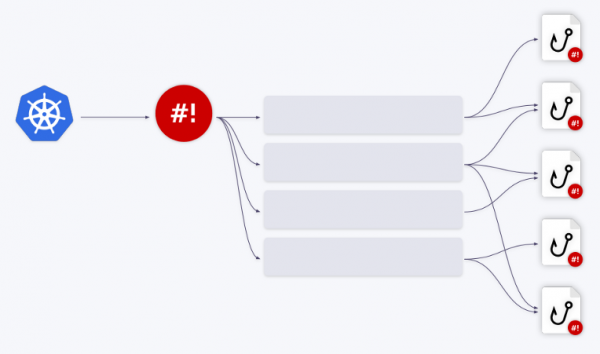
您需要做的就是相應地配置該字段 queue 在綁定配置中。 如果未指定佇列名稱,則掛鉤在預設佇列(default)。 這種排隊機制可以讓你徹底解決使用鉤子時的所有資源管理問題。
結論
我們解釋了什麼是 shell-operator,展示瞭如何使用它來快速、輕鬆地建立 Kubernetes 運算符,並給出了幾個使用範例。
有關 shell 操作符的詳細資訊以及如何使用它的快速教程可在相應的 。 如有疑問,請隨時與我們聯繫:您可以在特殊的方式中討論這些問題 (俄文)或 (用英語講)。
如果您喜歡它,我們總是很高興在 GitHub 上看到新問題/PR/stars,順便說一句,您可以在其中找到其他內容 。 其中值得強調的是 ,它是 shell-operator 的老大哥。 該實用程式使用 Helm 圖表來安裝附加元件,可以提供更新並監視各種圖表參數/值,控制圖表的安裝過程,還可以修改它們以回應叢集中的事件。
影片和幻燈片
表演影片(約 23 分鐘):

報告介紹:
聚苯乙烯
另請閱讀我們的博客:
- «“;
- «“;
- «“;
- «.
來源: www.habr.com
