

大家好!在他的 我寫了一篇關於為微服務架構組織模組化監控系統的文章。沒有什麼是一成不變的,我們的專案不斷發展,儲存的指標數量也在不斷增長。我們如何在高負載條件下組織從 Graphite+Whisper 到 Graphite+ClickHouse 的過渡、我們對它的期望以及遷移的結果,請閱讀下文。

在我告訴您我們如何組織從 Graphite+Whisper 到 Graphite+ClickHouse 存儲指標的轉變之前,我想提供有關做出此決定的原因以及我們長期以來所忍受的 Whisper 的缺點的信息。
Graphite+Whisper 問題
1. 磁碟子系統負載高
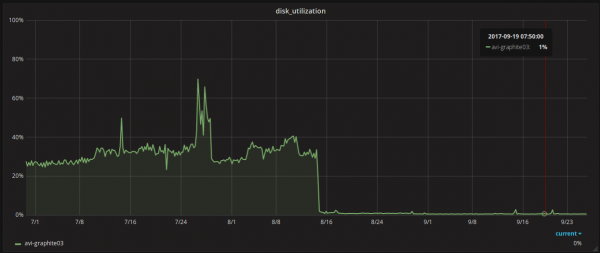
在過渡期間,我們每分鐘收到大約 1.5 萬個指標。在這樣的流程下,伺服器的磁碟利用率約為 30%。總體而言,這是完全可以接受的 - 一切都運行穩定,編寫速度很快,閱讀速度也很快......直到其中一個開發團隊推出了一項新功能,並開始每分鐘向我們發送 10 萬個指標。那時磁碟子系統開始更努力工作,我們看到了 100% 的利用率。問題很快就解決了,但是不愉快的感覺仍然存在。
2. 缺乏複製和一致性
最有可能的是,就像每個使用/曾經使用過 Graphite+Whisper 的人一樣,我們為了實現容錯功能,將相同的指標流同時倒入多個 Graphite 伺服器。而且這並沒有出現什麼特別的問題 - 直到其中一台伺服器因某種原因崩潰。有時我們能夠足夠快地恢復宕機的伺服器,並且 carbon-c-relay 能夠從其快取中上傳指標,但有時卻不能。然後指標中出現了一個漏洞,我們用 rsync 來填補。整個過程相當漫長。唯一讓我們感到慶幸的是,這種情況很少發生。我們也定期採取一組隨機指標,並將它們與群集鄰近節點上的其他類似指標進行比較。在大約 5% 的情況下,幾個值有所不同,這讓我們感到不太高興。
3.佔用大量空間
由於我們不僅在 Graphite 中寫入基礎設施指標,還寫入業務指標(現在還有來自 Kubernetes 的指標),所以我們經常會遇到這樣的情況:指標只包含幾個值,而 .wsp 檔案是在考慮整個保留期的情況下創建的,並佔用預先分配的空間,在我們的例子中約為 2 MB。隨著時間的推移,大量此類文件不斷出現,在產生報告時需要花費大量時間和資源來讀取空點,這使得問題變得更加嚴重。
我想立即指出,上述問題可以透過各種方法來解決,而且其有效性程度各不相同,但收到的數據越多,問題就會變得越嚴重。
以上所有情況(考慮到之前的 ),以及接收指標數量的不斷增長,希望將所有指標轉移到 30 秒的儲存間隔。 (如果需要最多 10 秒),我們決定嘗試 Graphite+ClickHouse 作為 Whisper 的有前途的替代品。
Graphite+ClickHouse。期望
我參加了 Yandex 的幾次聚會,讀過 ,在仔細閱讀了文件並找到了將 ClickHouse 綁定到 Graphite 的合理元件後,我們決定採取行動!
我想要得到以下資訊:
- 將磁碟子系統的利用率從 30% 降低到 5%;
- 將佔用的空間從1TB減少到100GB;
- 每分鐘能夠接收 100 億個指標到伺服器;
- 開箱即用的資料複製和容錯;
- 不要在這個專案上停留一年,並在合理的時間範圍內完成轉變;
- 無需停機即可切換。
相當雄心勃勃,對吧?
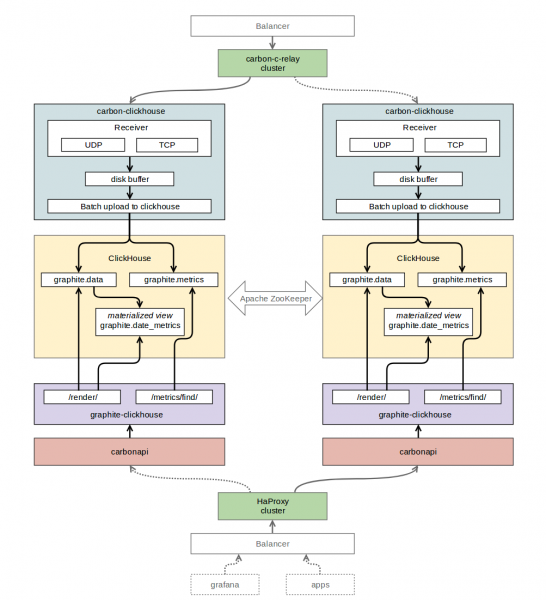
Graphite+ClickHouse。成分
為了透過 Graphite 協定取得數據,然後將其寫入 ClickHouse,我們選擇了 (戈朗)。
選擇最新的 ClickHouse 穩定版本 1.1.54253 作為儲存時間序列的資料庫。使用它時出現了一些問題:日誌中湧入了大量錯誤,而且並不完全清楚如何處理它們。與…討論 (作者 carbon-clickhouse、graphite-clickhouse 以及許多其他作者)選擇了較舊的 。錯誤消失了——一切都開始完美運作。
若要從 ClickHouse 讀取數據,請選擇以下內容: (戈朗)。作為 Graphite 的 API - (戈朗)。為了組織 ClickHouse 表之間的複製,我們使用 。對於指標路由,我們離開了我們心愛的 (和) .
Graphite+ClickHouse。表結構
「graphite」是我們為監控表所建立的資料庫。
「graphite.metrics」-附有 ReplicatedReplacingMergeTree 引擎的表(複製 )。此表儲存了指標的名稱及其路徑。
CREATE TABLE graphite.metrics ( Date Date, Level UInt32, Path String, Deleted UInt8, Version UInt32 ) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/replicator/graphite.metrics', ‘r1’, Date, (Level, Path), 8192, Version);“graphite.data” — 帶有 ReplicatedGraphiteMergeTree 引擎的表格(複製 )。此表儲存指標值。
CREATE TABLE graphite.data ( Path String, Value Float64, Time UInt32, Date Date, Timestamp UInt32 ) ENGINE = ReplicatedGraphiteMergeTree('/clickhouse/tables/replicator/graphite.data', 'r1', Date, (Path, Time), 8192, 'graphite_rollup')“graphite.date_metrics” 是一個使用 ReplicatedReplacingMergeTree 引擎的條件填色表。表格記錄了一天中遇到的所有指標的名稱。其創建的原因在本節中描述 在本文的最後。
CREATE MATERIALIZED VIEW graphite.date_metrics ( Path String, Level UInt32, Date Date) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/replicator/graphite.date_metrics', 'r1', Date, (Level, Path, Date), 8192) AS SELECT toUInt32(length(splitByChar('.', Path))) AS Level, Date, Path FROM graphite.data「graphite.data_stat」 是一個使用 ReplicatedAggregatingMergeTree 引擎(複製 )。表格記錄了傳入指標的數量,分為 4 個巢狀層級。
CREATE MATERIALIZED VIEW graphite.data_stat ( Date Date, Prefix String, Timestamp UInt32, Count AggregateFunction(count)) ENGINE = ReplicatedAggregatingMergeTree('/clickhouse/tables/replicator/graphite.data_stat', 'r1', Date, (Timestamp, Prefix), 8192) AS SELECT toStartOfMonth(now()) AS Date, replaceRegexpOne(Path, '^([^.]+.[^.]+.[^.]+).*$', '1') AS Prefix, toUInt32(toStartOfMinute(toDateTime(Timestamp))) AS Timestamp, countState() AS Count FROM graphite.data GROUP BY Timestamp, PrefixGraphite+ClickHouse。組件互動圖
Graphite+ClickHouse。資料遷移
我們記得,根據該專案的期望,向 ClickHouse 的過渡應該沒有停機時間,因此,我們必須以某種方式將我們的整個監控系統盡可能透明地切換到新的存儲,以便我們的用戶使用。
我們就是這樣做的。
在 carbon-c-relay 中,新增了一條規則,將額外的指標流傳送到參與 ClickHouse 表複製的伺服器之一的 carbon-clickhouse。
我們編寫了一個小型 Python 腳本,使用 whisper-dump 庫從我們的存儲中讀取所有 .wsp 文件,並將這些數據通過 24 個線程發送到上面描述的 carbon-clickhouse。 carbon-clickhouse 中接受的指標值數量達到了 125 億/分鐘,ClickHouse 甚至沒有費什麼力氣。
在 Grafana 中建立了一個單獨的資料來源,用於調試現有儀表板中使用的功能。我們找到了我們使用過但未在 carbonapi 中實現的功能清單。我們完成了這些函數的編寫,並向 carbonapi 的作者發送了 PR(特別感謝他們)。
- 為了在平衡器設定中切換讀取負載,我們將端點從 graphite-api(Graphite+Whisper 的 API 介面)更改為 carbonapi。
Graphite+ClickHouse。結果
將磁碟子系統的利用率從 30% 降低到 1%;

- 將佔用的空間量從 1 TB 減少到 300 GB;
- 我們有能力每分鐘接收 125 億個指標到伺服器(遷移時的峰值);
- 將所有指標轉移到三十秒的儲存間隔;
- 接收資料的複製和容錯;
- 無需停機即可切換;
- 總共花了大約7週的時間。
Graphite+ClickHouse。問題
就我們的情況而言,存在一些陷阱。這就是我們在轉型之後遇到的情況。
- ClickHouse 並不總是動態重新讀取配置,有時需要重新啟動。例如,在ClickHouse配置中關於zookeeper叢集的描述中,直到clickhouse-server重新啟動後才生效。
- 大型 ClickHouse 查詢未通過,因此在 graphite-clickhouse 中我們的 ClickHouse 連接字串如下所示:
url = "http://localhost:8123/?max_query_size=268435456&max_ast_elements=1000000" - ClickHouse 經常發布穩定版本的新版本,其中可能包含驚喜:請小心。
- kubernetes 中動態建立的容器會傳送大量具有短暫且隨機生命週期的指標。具有此類指標的點並不多,空間也沒有問題。但是在建立查詢時,ClickHouse 會從「指標」表中提出大量相同的指標。在 90% 的情況下,沒有關於它們該時間段(24 小時)的數據。但是在「資料」表中搜尋這些資料需要花費時間,最終會導致逾時。為了解決這個問題,我們開始維護一個單獨的視圖,其中包含白天遇到的指標的資訊。因此,在動態建立的容器上建立報告(圖表)時,我們只查詢在給定視窗內發生的指標,而不是整個時間段內的指標,這大大加快了報告的建置速度。對於上述解決方案, ,包括使用 date_metrics 表的實作。
Graphite+ClickHouse。標籤
自 1.1.0 版本以來,Graphite 已成為官方 。我們正在積極思考如何在 graphite+clickhouse 堆疊中支援這項計劃。
Graphite+ClickHouse。異常檢測器
基於上面描述的基礎設施,我們實現了異常檢測器的原型,並且它可以運行!但在下一篇文章中我們會更了解他。
訂閱,按向上箭頭並快樂!
來源: www.habr.com
