

大家好,我叫 Alexander,我在 CIAN 擔任工程師,負責基礎設施流程的系統管理和自動化。在之前一篇文章的評論中,我們被要求說明每天從哪裡獲得 4 TB 的日誌以及我們如何處理它們。是的,我們有很多日誌,並且創建了一個單獨的基礎設施叢集來處理它們,這使我們能夠快速解決問題。在本文中,我將討論我們如何在一年的時間內對其進行調整以處理不斷增長的資料流。
我們從哪裡開始?
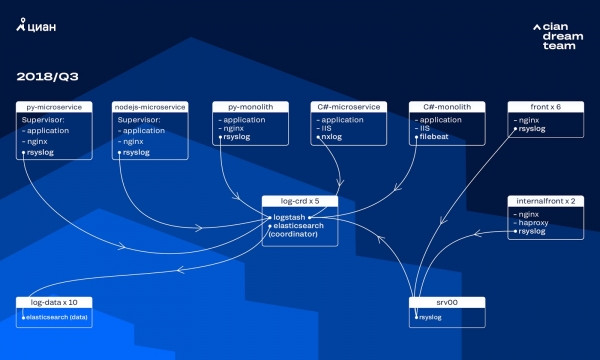
過去幾年,cian.ru的負載成長非常快,到2018年第三季度,資源流量達到每月11.2萬獨立用戶。當時關鍵時刻我們遺失了高達40%的日誌,這就是為什麼我們無法快速處理事件,並花費了大量的時間和精力去解決。我們也常常找不到問題的原因,一段時間後又會再出現。這是地獄,必須採取一些措施。
當時,我們使用ElasticSearch版本10、標準索引設定的5.5.2個資料節點的叢集來儲存日誌。它是一年多前推出的,作為一種流行且經濟實惠的解決方案:那時日誌流量還沒有那麼大,沒有必要提出非標準配置。
傳入日誌的處理由 Logstash 在五個 ElasticSearch 協調器的不同連接埠上提供。一個索引,無論大小,都由五個分片組成。每小時和每天輪換,集群中每小時會出現約 100 個新分片。雖然日誌不是很多,但叢集處理得很好,沒有人注意它的設定。
快速成長的挑戰
由於兩個進程相互重疊,產生的日誌量成長得非常快。一方面,該服務的用戶數量有所增長。另一方面,我們開始積極轉向微服務架構,用 C# 和 Python 打破舊的單體架構。數十個新的微服務取代了整體架構的一部分,為基礎設施叢集產生了更多的日誌。
正是擴展導致我們的叢集變得幾乎難以管理。當日誌開始以每秒 20 萬條訊息的速度到達時,頻繁的無用旋轉將分片數量增加到 6 個,每個節點有超過 600 個分片。
這導致了記憶體分配問題,當一個節點崩潰時,所有分片都會同時遷移,增加流量並加重剩餘節點的負載,使得向叢集寫入資料幾乎不可能。在此期間,我們甚至無法取得日誌。如果出現問題… 服務器 我們總共損失了十分之一的叢集資源。大量的小索引增加了複雜性。
沒有日誌,我們不了解事件的原因,遲早會再次踩到同一個耙子,而在我們團隊的意識形態中,這是不可接受的,因為我們所有的工作機制都旨在做相反的事情- 永不重複同樣的問題。為此,我們需要全部日誌及其幾乎即時的交付,因為值班工程師團隊不僅從指標中監控警報,還從日誌中監控警報。要了解問題的規模,當時的日誌總量約為每天 2 TB。
我們設定的目標是在不可抗力期間完全消除日誌遺失,並將其傳送到 ELK 叢集的時間減少到最多 15 分鐘(我們後來依賴這個數字作為內部 KPI)。
新的輪換機制與熱溫節點
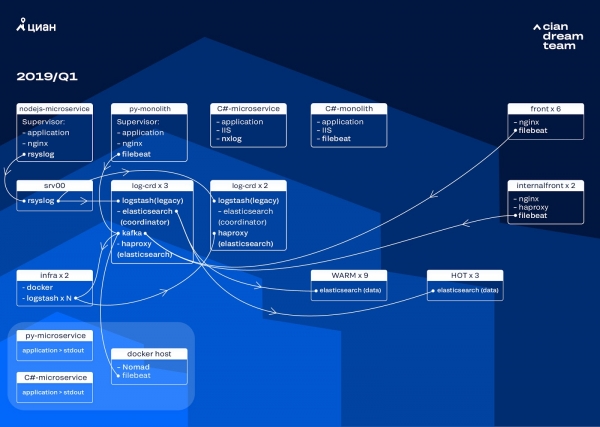
我們透過將 ElasticSearch 版本從 5.5.2 更新到 6.4.3 開始叢集轉換。我們的版本 5 叢集再次崩潰,我們決定關閉它並完全更新它 - 仍然沒有日誌。因此,我們在短短幾個小時內就完成了這項轉變。
這一階段最大規模的改造是在三個節點上實現 Apache Kafka,並以協調器作為中間緩衝區。訊息代理程式使我們避免在 ElasticSearch 出現問題時遺失日誌。同時,我們為叢集新增了2個節點,並切換到熱溫架構,其中三個「熱」節點位於資料中心的不同機架中。我們使用在任何情況下都不應丟失的掩碼(nginx)以及應用程式錯誤日誌將日誌重定向到它們。次要日誌被發送到其餘節點 - 調試、警告等,24 小時後,來自“熱”節點的“重要”日誌被傳輸。
為了不增加小索引的數量,我們從時間輪換切換到滾動機制。論壇上有很多資訊表明按索引大小進行輪換非常不可靠,因此我們決定使用按索引中文檔數量進行輪換。我們分析了每個索引並記錄了輪換後應該起作用的文件數量。因此,我們已經達到了最佳分片大小 - 不超過 50 GB。
叢集優化
然而,我們還沒有完全擺脫這些問題。不幸的是,小索引仍然出現:它們沒有達到指定的數量,沒有輪換,並且由於我們刪除了按日期輪換,因此通過對超過三天的索引進行全局清理來刪除它們。由於叢集中的索引完全消失,這導致了資料遺失,並且嘗試寫入不存在的索引破壞了我們用於管理的 curator 的邏輯。用於寫入的別名被轉換為索引並破壞了翻轉邏輯,導致某些索引不受控制地增長到600 GB。
例如,對於旋轉配置:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
如果沒有翻轉別名,則會發生錯誤:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
我們將這個問題的解決方案留到下一次迭代中,並解決了另一個問題:我們切換到 Logstash 的拉取邏輯,該邏輯處理傳入的日誌(刪除不必要的資訊並豐富)。我們將其放置在 docker 中,透過 docker-compose 啟動它,並且還放置了logstash-exporter,它將指標發送到 Prometheus 以對日誌流進行操作監控。這樣我們就有機會平滑地更改負責處理每種類型日誌的logstash實例的數量。
在我們改進叢集的同時,cian.ru 的流量增加到每月 12,8 萬獨立用戶。結果發現我們的改造有點落後於生產的變化,我們面臨著「熱」節點無法應對負載並減慢了整個日誌交付速度的事實。我們毫無故障地收到了「熱」數據,但我們必須幹預其餘數據的交付並進行手動滾動,以便均勻分配索引。
同時,由於它是本地 docker-compose,因此擴展和更改叢集中的 Logstash 實例的設定變得很複雜,並且所有操作都是手動執行的(要添加新端,需要手動遍歷所有操作)伺服器並在各處執行docker-compose up -d )。
日誌重新分配
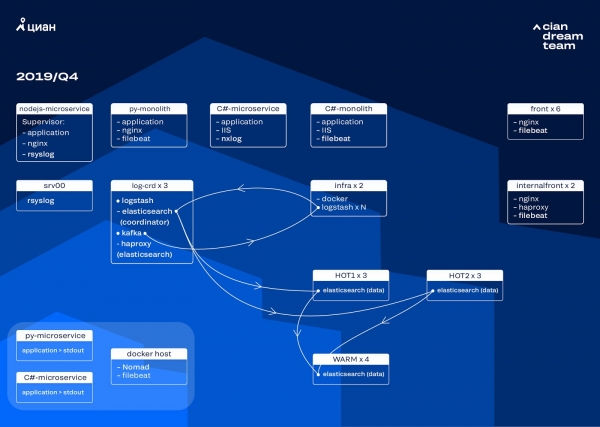
今年30月份,我們還在對單體進行切割,叢集的負載不斷增加,日誌流已經接近每秒XNUMX萬個訊息。
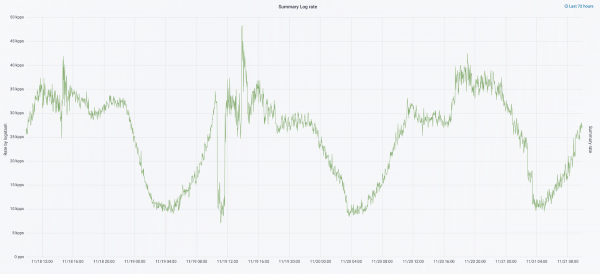
我們透過硬體更新開始了下一次迭代。我們從五個協調員改為三個,更換了資料節點,並在金錢和儲存空間方面取得了勝利。對於節點,我們使用兩種配置:
- 對於「熱」節點:E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2(3 個用於 Hot1,3 個用於 Hot2)。
- 對於「熱」節點:E3-1230 v6 / 4Tb SSD / 32 Gb x 4。
在本次迭代中,我們將微服務存取日誌的索引(與第一線 nginx 日誌佔用的空間相同)移至第二組三個「熱」節點。我們現在將資料儲存在「熱」節點上 20 小時,然後將它們傳輸到「熱」節點以記錄其餘日誌。
我們透過重新配置小索引的輪換來解決小索引消失的問題。現在,無論如何,索引每 23 小時輪換一次,即使那裡的數據很少。這稍微增加了分片數量(大約800個),但從集群性能的角度來看,這是可以忍受的。
結果,集群中有六個「熱」節點和四個「熱」節點。這會導致較長時間間隔內的請求略有延遲,但將來增加節點數量將解決此問題。
這次迭代也修復了缺乏半自動縮放的問題。為此,我們部署了一個基礎設施 Nomad 叢集 - 類似於我們已經在生產中部署的叢集。目前,Logstash 的數量不會根據負載自動變化,但我們會討論這一點。
Планынабудущее
實施的配置可以完美擴展,現在我們儲存了 13,3 TB 的資料 - 所有日誌為期 4 天,這對於警報的緊急分析是必要的。我們將一些日誌轉換為指標,並將其加入 Graphite 中。為了讓工程師的工作更輕鬆,我們提供了基礎設施叢集的指標和半自動修復常見問題的腳本。在規劃明年增加資料節點數量後,我們會將資料儲存從4天切換到7天。這對於營運工作來說已經足夠了,因為我們總是試圖盡快調查事件,而對於長期調查來說,有遙測數據。
2019 年 15,3 月,cian.ru 的流量已增加至每月 XNUMX 萬獨立用戶。這成為對日誌交付架構解決方案的嚴峻考驗。
現在我們正準備將ElasticSearch 更新到版本7。但是,為此我們必須更新ElasticSearch 中許多索引的映射,因為它們從版本5.5 移出並在版本6 中被宣告為已棄用(它們根本不存在於版本中) 7).這意味著在更新過程中肯定會出現某種不可抗力,導致我們在問題解決期間沒有日誌。在版本 7 中,我們最期待 Kibana 具有改進的介面和新的過濾器。
我們實現了我們的主要目標:我們不再遺失日誌,並將基礎設施群集的停機時間從每週 2-3 次崩潰減少到每月幾個小時的維護工作。所有這些生產工作幾乎是看不見的。然而,現在我們可以準確地確定我們的服務發生了什麼,我們可以在安靜模式下快速完成,而不用擔心日誌會遺失。總的來說,我們感到滿意、高興,並為新的探索做好準備,我們稍後會談到。
來源: www.habr.com
