

底
作為復古硬體的愛好者,我曾經從英國的賣家那裡購買過 ZX Spectrum+。 我收到了電腦中附帶的幾盤遊戲錄音帶(在原包裝中,附有說明),以及錄製在沒有特殊標記的錄音帶上的程式。 令人驚訝的是,40 年前的磁帶中的資料可讀性很好,我可以從中下載幾乎所有的遊戲和程式。

然而,我在一些磁帶上發現了明顯不是由 ZX Spectrum 電腦錄製的錄音。 它們聽起來完全不同,並且與上述電腦的錄音不同,它們並不是以簡短的 BASIC 引導程式啟動,而該引導程式通常出現在所有程式和遊戲的錄音中。
一段時間以來,這一直困擾著我——我真的很想找出它們裡面隱藏著什麼。 如果您可以將音訊訊號讀取為位元組序列,則可以在其中找到字元或任何指示訊號來源的內容。 一種復古考古學。
現在我已經走了一路,看看磁帶本身的標籤,我笑了,因為
答案一直就在我眼前
左側磁帶的標籤上是 TRS-80 計算機的名稱,在製造商名稱的正下方:“Manufactured by Radio Shack in USA”
(如果您想把陰謀留到最後,請勿劇透)
音訊訊號比較
首先,讓我們將錄音數位化。 你可以聽聽它的聲音:
和往常一樣,ZX Spectrum 計算機的錄音聽起來如下:
在這兩種情況下,在錄音開始時都會有一個所謂的 導頻音 - 相同頻率的聲音(在第一次錄音中,它非常短<1秒,但可以區分)。 導頻音向電腦發出訊號準備接收資料。 通常,每台電腦通過訊號的形狀及其頻率僅識別其「自己的」導頻音。
有必要談談訊號形狀本身。 例如,在 ZX Spectrum 上,其形狀是矩形:
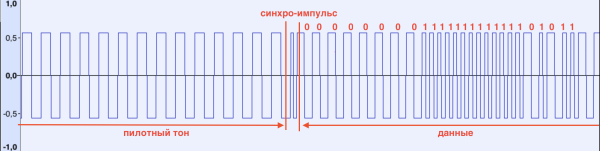
當偵測到導頻音時,ZX Spectrum 在螢幕邊框上交替顯示紅色和藍色條,表示訊號已被識別。 導頻音結束 同步脈衝,它指示計算機開始接收資料。 其特點是持續時間較短(與導頻音和後續數據相比)(見圖)
接收到同步脈衝後,電腦記錄訊號的每次上升/下降,測量其持續時間。 如果持續時間小於某個限制,則將位元 1 寫入內存,否則為 0。這些位元將收集到位元組中,並重複該過程,直到接收到 N 個位元組。 數字 N 通常取自下載檔案的標頭。 載入順序如下:
- 導頻音
- header(固定長度),包含下載資料的大小(N)、檔案名稱和類型
- 導頻音
- 數據本身
為了確保資料正確加載,ZX Spectrum 讀取所謂的 奇偶校驗位元組 (奇偶校驗位元組),在儲存檔案時透過對寫入資料的所有位元組進行異或來計算。 讀取檔案時,電腦會根據接收的資料計算奇偶校驗字節,如果結果與已儲存的結果不同,則顯示錯誤訊息「R 磁帶載入錯誤」。 嚴格來說,如果在讀取時計算機無法識別脈衝(丟失或其持續時間不符合某些限制),則計算機可以提前發出此訊息
那麼,現在讓我們來看看未知訊號是什麼樣的:
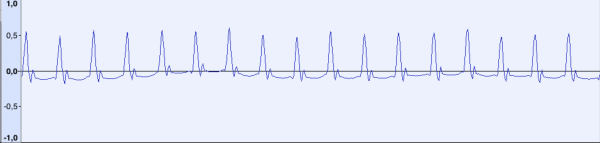
這是導頻音。 訊號的形狀明顯不同,但很明顯該訊號由特定頻率的重複短脈衝組成。 在取樣頻率為 44100 Hz 時,「峰值」之間的距離約為 48 個樣本(對應於約 918 Hz 的頻率)。讓我們記住這個數字。
現在讓我們來看看資料片段:
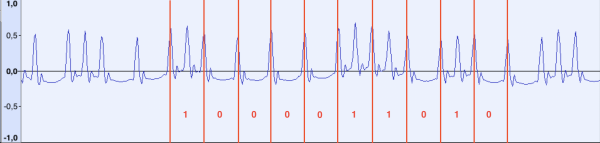
如果我們測量各個脈衝之間的距離,結果顯示「長」脈衝之間的距離仍然約為 48 個樣本,短脈衝之間的距離約為 24 個樣本。 展望未來,我會說,最終結果是,頻率為 918 Hz 的「參考」脈衝從文件的開頭到結尾連續不斷地跟隨。 可以假設,在傳輸資料時,如果在參考脈衝之間遇到額外的脈衝,我們將其視為位元1,否則視為0。
同步脈衝呢? 我們來看看數據的開頭:
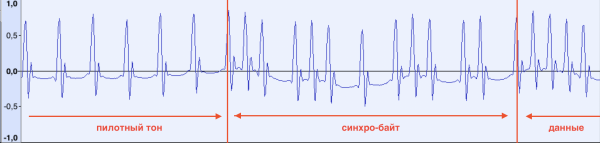
導頻音結束,資料立即開始。 稍後,在分析了幾個不同的錄音後,我們發現資料的第一個位元組總是相同的(10100101b,A5h)。 計算機收到資料後即可開始讀取資料。
您也可以注意同步位元組中最後一個參考脈衝緊接而來的第一個參考脈衝的移位。 後來在開發資料辨識程式的過程中才發現,無法穩定讀取文件開頭的資料。
現在讓我們嘗試描述一種處理音訊檔案和載入資料的演算法。
載入資料中
首先,讓我們來看一些保持演算法簡單的假設:
- 我們只會考慮 WAV 格式的檔案;
- 音訊檔案必須以導頻音開頭,且開頭不得包含靜音
- 來源檔案的取樣率必須為 44100 Hz。 在這種情況下,48個樣本的參考脈衝之間的距離已經確定,我們不需要透過程式設計來計算它;
- 樣本格式可以是任何格式(8/16 位元/浮點)-因為在讀取時我們可以將其轉換為所需的格式;
- 我們假設原始檔案按幅度進行歸一化,這應該可以穩定結果;
讀取演算法如下:
- 我們將檔案讀入內存,同時將樣本格式轉換為8位元;
- 確定音訊資料中第一個脈衝的位置。 為此,您需要計算具有最大幅度的樣本數。 為了簡單起見,我們將手動計算一次。 讓我們將其保存到 prev_pos 變數中;
- 最後一個脈衝的位置加 48 (pos := prev_pos + 48)
- 由於將位置增加 48 並不能保證我們將到達下一個參考脈衝的位置(磁帶缺陷、磁帶驅動機構運作不穩定等),因此我們需要調整 pos 脈衝的位置。 為此,請取得一小段資料 (pos-8;pos+8) 並找到其上的最大幅度值。 最大值對應的位置將儲存在pos中。 這裡8 = 48/6是一個透過實驗獲得的常數,它保證我們將確定正確的最大值並且不會影響附近可能的其他脈衝。 在非常糟糕的情況下,當脈衝之間的距離遠小於或大於48時,可以實現強制搜尋脈衝,但在本文的範圍內我不會在演算法中對此進行描述;
- 在上一步中,還需要檢查是否找到了參考脈衝。 也就是說,如果您只是尋找最大值,這並不能保證該段中存在脈衝。 在我最新的讀取程式實作中,我檢查了一段上的最大和最小幅度值之間的差異,如果它超過了一定的限制,我就會計算脈衝的存在。 問題還在於如果找不到參考脈衝該怎麼辦。 有 2 個選項:要么數據已結束並出現沉默,要么這應被視為讀取錯誤。 然而,我們將省略這一點以簡化演算法;
- 下一步,我們需要確定是否存在資料脈衝(位元 0 或 1),為此我們取段的中間 (prev_pos;pos) middle_pos 等於 middle_pos := (prev_pos+pos)/2 並且在線段上middle_pos 的某個鄰域(middle_pos-8;middle_pos +8) 讓我們計算最大和最小振幅。 如果它們之間的差值大於10,則將結果寫入位元1,否則為0。10是實驗得到的常數;
- 將目前位置儲存在 prev_pos 中 (prev_pos := pos)
- 從步驟3開始重複,直到讀取整個檔案;
- 產生的位數組必須儲存為一組位元組。 由於我們在讀取時沒有考慮同步字節,因此位數可能不是8的倍數,所需的位元偏移量也是未知的。 在演算法的第一次實作中,我不知道同步位元組的存在,因此簡單地保存了8個具有不同數量的偏移位的檔案。 其中一份包含正確的數據。 在最終的演算法中,我只需刪除 A5h 之前的所有位,這使我能夠立即獲得正確的輸出文件
Ruby 演算法,對於有興趣的人
我選擇 Ruby 作為編寫程式的語言,因為... 我大部分時間都用它來編程。 該選項不是高效能,但使讀取速度盡可能快的任務是不值得的。
# Используем gem 'wavefile'
require 'wavefile'
reader = WaveFile::Reader.new('input.wav')
samples = []
format = WaveFile::Format.new(:mono, :pcm_8, 44100)
# Читаем WAV файл, конвертируем в формат Mono, 8 bit
# Массив samples будет состоять из байт со значениями 0-255
reader.each_buffer(10000) do |buffer|
samples += buffer.convert(format).samples
end
# Позиция первого импульса (вместо 0)
prev_pos = 0
# Расстояние между импульсами
distance = 48
# Значение расстояния для окрестности поиска локального максимума
delta = (distance / 6).floor
# Биты будем сохранять в виде строки из "0" и "1"
bits = ""
loop do
# Рассчитываем позицию следующего импульса
pos = prev_pos + distance
# Выходим из цикла если данные закончились
break if pos + delta >= samples.size
# Корректируем позицию pos обнаружением максимума на отрезке [pos - delta;pos + delta]
(pos - delta..pos + delta).each { |p| pos = p if samples[p] > samples[pos] }
# Находим середину отрезка [prev_pos;pos]
middle_pos = ((prev_pos + pos) / 2).floor
# Берем окрестность в середине
sample = samples[middle_pos - delta..middle_pos + delta]
# Определяем бит как "1" если разница между максимальным и минимальным значением на отрезке превышает 10
bit = sample.max - sample.min > 10
bits += bit ? "1" : "0"
end
# Определяем синхро-байт и заменяем все предшествующие биты на 256 бит нулей (согласно спецификации формата)
bits.gsub! /^[01]*?10100101/, ("0" * 256) + "10100101"
# Сохраняем выходной файл, упаковывая биты в байты
File.write "output.cas", [bits].pack("B*")
導致
在嘗試了演算法和常數的幾種變體之後,我很幸運地得到了一些非常有趣的東西:
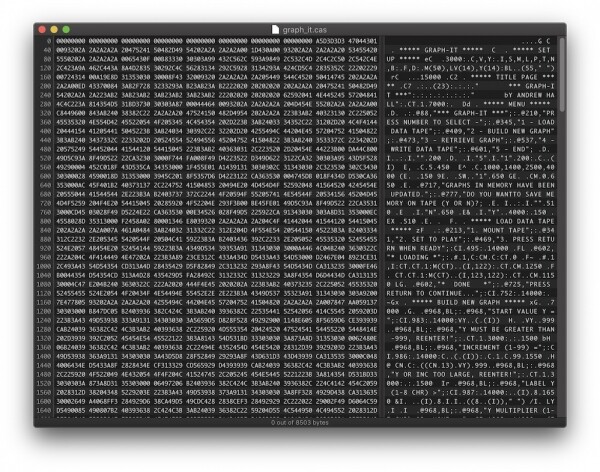
因此,根據字串判斷,我們有一個繪製圖表的程式。 然而,程式文字中沒有關鍵字。 所有關鍵字均編碼為位元組(每個值 > 80h)。 現在我們需要找出哪台 80 年代的電腦可以以這種格式儲存程式。
事實上,它與 BASIC 程式非常相似。 ZX Spectrum 計算機以大致相同的格式將程式儲存在記憶體中並將程式儲存到磁帶上。 以防萬一,我檢查了關鍵字 。 然而,結果顯然是否定的。
我還檢查了當時流行的 Atari、Commodore 64 和其他幾台電腦的 BASIC 關鍵字,我能夠找到這些電腦的文檔,但沒有成功 - 我對復古電腦類型的了解並不是那麼廣泛。
然後我決定去 ,然後我的目光落在了製造商Radio Shack的名字和TRS-80電腦上。 這些是我桌上的錄音帶標籤上寫的名字! 我以前不知道這些名字,也不熟悉TRS-80電腦,所以在我看來Radio Shack是巴斯夫、索尼或TDK等錄音帶製造商,TRS-80是播放時間。 為什麼不?
電腦 Tandy/無線電棚 TRS-80
我在文章開頭舉的例子中所討論的錄音很可能是在這樣的電腦上錄製的:

事實證明,這款計算機及其變種(Model I/Model III/Model IV等)一度非常流行(當然不是在俄羅斯)。 值得注意的是,他們使用的處理器也是Z80。 對於這台計算機,您可以在互聯網上找到 。 80年代,電腦資訊廣泛傳播 。 目前有幾個 不同平台的計算機。
我下載了模擬器 我第一次能夠看到這台計算機是如何運作的。 當然,電腦不支援彩色輸出;螢幕解析度只有128x48像素,但是有許多擴展和修改可以提高螢幕解析度。 該電腦的作業系統還有許多選項以及用於實現 BASIC 語言的選項(與 ZX Spectrum 不同,在某些型號中,該語言甚至沒有「閃存」到 ROM 中,任何選項都可以從軟碟加載,就像作業系統本身)
我還發現 將音訊錄音轉換為模擬器支援的 CAS 格式,但由於某種原因,無法使用它們從我的磁帶中讀取錄音。
弄清楚 CAS 檔案格式(結果只是我手邊已有的磁帶中資料的逐位複製,除了存在同步位元組的標頭之外),我製作了一個對我的程式進行了一些更改,並且能夠輸出在模擬器(TRS-80 Model III)中工作的工作CAS 檔案:
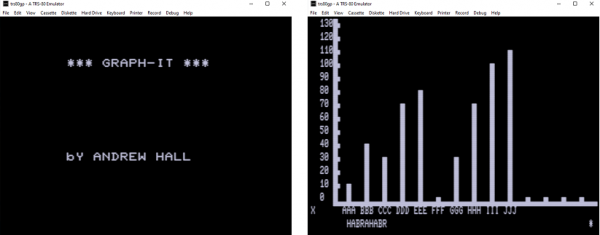
我設計了最新版本的轉換實用程序,自動確定第一個脈衝和參考脈衝之間的距離作為 GEM 包,原始碼可在 .
結論
我們走過的路原來是一次令人著迷的回溯之旅,我很高興最終找到了答案。 除其他事項外,我:
- 我弄清楚了 ZX Spectrum 中保存資料的格式,並研究了用於保存/讀取錄音帶資料的內建 ROM 例程
- 我熟悉了TRS-80計算機及其品種,研究了操作系統,查看了示例程序,甚至有機會用機器代碼進行調試(畢竟Z80的助記符我都很熟悉)
- 編寫了一個成熟的實用程序,用於將錄音轉換為 CAS 格式,它可以讀取“官方”實用程式無法識別的數據
來源: www.habr.com
