

我會立即解釋文章的標題。最初的計劃是透過一個簡單但現實的範例來就如何加速反射的使用提供良好、可靠的建議,但在基準測試過程中發現反射並不像我想像的那麼慢,LINQ 比我的噩夢中還要慢。但最後發現我的測量也犯了一個錯誤…這個人生故事的細節在剪輯和評論中。由於這個例子非常常見,並且原則上按照企業中通常執行的方式實施,因此在我看來,它是一個非常有趣的生活演示:對文章主題速度的影響是由於外部邏輯不明顯:Moq、Autofac、 EF Core 和其他「條帶」。
我是在這篇文章的印像下開始工作的:
正如您所看到的,作者建議使用編譯委託而不是直接呼叫反射類型方法,這是大大加快應用程式速度的好方法。當然,存在 IL 排放,但我想避免它,因為這是執行任務的最勞動密集型方式,而且充滿了錯誤。
考慮到我一直對反思速度有類似的看法,所以我並沒有特別打算質疑作者的結論。
我經常遇到在企業中幼稚地使用反射的情況。類型已被採用。有關財產的資訊被獲取。 SetValue 方法被調用,每個人都歡欣鼓舞。價值已經到達目標領域,大家都很高興。非常聰明的人 - 前輩和團隊領導 - 基於這種簡單的實現從一種類型到另一種類型的“通用”映射器,編寫他們的對象擴展。本質通常是這樣的:我們獲取所有字段,獲取所有屬性,迭代它們:如果類型成員的名稱匹配,我們執行 SetValue。有時,我們會因錯誤而捕獲異常,即我們沒有在其中一種類型中找到某些屬性,但即使在這裡,也有一種提高效能的方法。試著抓。
我見過人們重新發明解析器和映射器,但沒有完全掌握有關他們之前的機器如何工作的資訊。我看過人們將他們幼稚的實作隱藏在策略、介面、注入後面,好像這可以為隨後的狂歡找藉口。我對這種認識嗤之以鼻。事實上,我沒有測量真正的性能洩漏,如果可能的話,我只是將實現更改為更“最佳”的實現(如果我能得到它)。因此,下面討論的第一個測量結果讓我感到非常困惑。
我想你們中的許多人在讀過 Richter 或其他思想家的著作後,都遇到過一個完全公平的說法,即程式碼中的反射是一種對應用程式的表現產生極其負面影響的現象。
呼叫反射會強制 CLR 遍歷程序集以找到所需的組件、提取其元資料、解析它們等。另外,遍歷序列時的反射會導致分配大量記憶體。我們正在耗盡內存,CLR 會發現 GC,並且開始出現條紋。相信我,它應該明顯很慢。現代生產伺服器或雲端電腦上的大量記憶體並不能防止高處理延遲。事實上,記憶體越多,您就越有可能注意到 GC 的工作原理。從理論上講,反思對他來說是一塊額外的紅布。
然而,我們都使用IoC容器和日期映射器,其運作原理也是基於反射,但通常不會對其性能產生任何疑問。不,並不是因為引入依賴關係和從外部有限上下文模型中抽像是非常必要的,以至於我們無論如何都必須犧牲效能。一切都變得更簡單——它確實不會對性能產生太大影響。
事實上,基於反射技術的最常見框架使用各種技巧來更優化地使用它。通常這是一個快取。通常,這些是從表達式樹編譯的表達式和委託。同一個自動映射器維護一個競爭字典,將類型與函數相匹配,這些函數可以將一種類型轉換為另一種類型,而無需調用反射。
這是如何實現的?本質上,這與平臺本身用來產生 JIT 程式碼的邏輯沒有什麼不同。當第一次呼叫一個方法時,它會被編譯(是的,這個過程並不快);在後續呼叫中,控制權將轉移到已經編譯的方法,並且不會有明顯的效能下降。
在我們的範例中,您也可以使用 JIT 編譯,然後使用與 AOT 對應項具有相同效能的編譯行為。在這種情況下,表達式會為我們提供幫助。
所討論的原則可以簡要表述如下:
您應該將反射的最終結果快取為包含已編譯函數的委託。將所有必要的物件與類型資訊快取在儲存在物件外部的類型(即工作人員)的欄位中也是有意義的。
這是有邏輯的。常識告訴我們,如果某些東西可以編譯和緩存,那麼就應該這樣做。
展望未來,應該說,即使您不使用建議的編譯表達式的方法,快取在使用反射時也有其優點。其實,我在這裡只是重複我上面提到的文章作者的論點。
現在關於代碼。讓我們來看一個例子,這個例子是基於我最近在一個嚴肅的信貸機構的嚴肅製作中不得不面對的痛苦。所有實體都是虛構的,因此沒有人會猜測。
有一些本質。要有聯絡方式。有些字母具有標準化的正文,解析器和水化器從中創建這些相同的聯絡人。一封信到達,我們閱讀它,將其解析為鍵值對,創建一個聯絡人,並將其保存在資料庫中。
這是初級的。假設聯絡人具有「全名」、「年齡」和「聯絡電話」屬性。該數據透過信函傳輸。該企業還希望能夠快速添加新鍵,以將實體屬性映射到信件正文中的對中。如果有人在模板中犯了錯字,或者在發布之前需要緊急啟動新合作夥伴的映射,以適應新的格式。然後我們可以添加一個新的映射相關性作為廉價的資料修復。也就是生活中的例子。
我們實作、創建測試。作品。
我不會提供程式碼:有很多來源,可以透過文章末尾的連結在 GitHub 上取得它們。您可以加載它們,將它們折磨得面目全非並測量它們,因為這會影響您的情況。我只會給出兩個模板方法的程式碼,以區分水合器(應該是快的)和水合器(應該是慢的)。
邏輯如下:模板方法接收基本解析器邏輯產生的對。 LINQ 層是解析器和 Hydrator 的基本邏輯,它向資料庫上下文發出請求,並將鍵與解析器中的對進行比較(對於這些函數,有不帶 LINQ 的程式碼進行比較)。接下來,這些對被傳遞到主水合方法,並將這些對的值設定為實體的相應屬性。
「快速」(基準測試中的前綴「快速」):
protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
正如我們所看到的,使用了具有 setter 屬性的靜態集合 - 調用 setter 實體的已編譯 lambda。由以下程式碼建立:
static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
總的來說是很清楚的。我們遍歷屬性,為它們建立呼叫 setter 的委託,然後儲存它們。然後我們會在必要時打電話。
「慢」(基準測試中的前綴「慢」):
protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
這裡我們立即繞過屬性,直接呼叫SetValue。
為了清楚起見並作為參考,我實作了一種簡單的方法,將其相關對的值直接寫入實體欄位。前綴 – 手動。
現在讓我們使用 BenchmarkDotNet 來檢查效能。突然...(劇透 - 這不是正確的結果,詳細資訊如下)
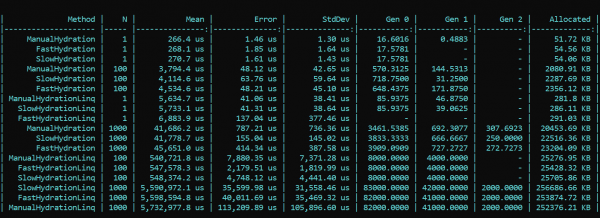
我們在這裡看到什麼?事實證明,帶有 Fast 前綴的方法幾乎在所有傳遞中都比帶有 Slow 前綴的方法慢。對於工作分配和速度都是如此。另一方面,盡可能使用 LINQ 方法進行漂亮而優雅的映射實現,相反,會大大降低生產力。差別在於順序。趨勢不會隨著通過次數的不同而改變。唯一的差別在於規模。使用 LINQ 時速度要慢 4 - 200 倍,並且在大致相同的規模上會出現更多的垃圾。
已更新
我不相信自己的眼睛,更重要的是,我們的同事既不相信我的眼睛,也不相信我的程式碼—— 。在仔細檢查了我的解決方案後,他出色地發現並指出了一個錯誤,該錯誤是由於從最初到最終的實施過程中的許多變更而導致我錯過的。修正了最小起訂量設定中發現的錯誤後,所有結果都已到位。根據重新測試的結果,主要趨勢沒有改變——LINQ仍然比反射更影響效能。然而,令人高興的是,表達式編譯的工作並沒有白費,而且結果在分配和執行時間上都是可見的。第一次啟動時,當初始化靜態欄位時,對於「快速」方法來說自然會較慢,但隨後情況發生了變化。
這是重新測試的結果:
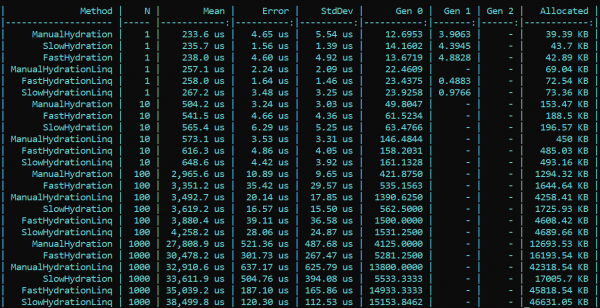
結論:在企業中使用反射時,沒有特別需要訴諸技巧-LINQ會消耗更多的生產力。然而,在需要最佳化的高負載方法中,您可以以初始化器和委託編譯器的形式保存反射,然後這將提供「快速」邏輯。這樣您就可以同時保持反射的靈活性和應用程式的速度。
基準代碼可在此處取得。任何人都可以仔細檢查我的話:
PS:測試中的程式碼使用 IoC,而在基準測試中它使用明確構造。事實是,在最終的實現中,我切斷了所有可能影響性能並使結果變得嘈雜的因素。
PPS:感謝用戶 發現我在設定起訂量時的錯誤,這影響了第一次測量。如果讀者有足夠的緣分,請按讚。那人停了下來,那人讀了一遍,那人仔細檢查並指出了錯誤。我想這是值得尊重和同情的。
PPPS:感謝細心的讀者,他們深入了解了風格和設計。我是為了統一和方便。演講的外交技巧還有很多不足之處,但我考慮了這些批評。我要彈丸。
來源: www.habr.com
