


大家好!我叫 Oleg Anastasyev,在 Odnoklassniki 平台團隊工作。除了我之外,還有很多硬體人員在 Odnoklassniki 上工作。我們有四個資料中心,大約有 500 個機架,8 多台伺服器。在某個時候,我們意識到實施新的管理系統將使我們能夠更有效地裝載設備,促進存取管理,自動化(重新)分配運算資源,加快推出新服務,並加快對大規模事故的回應。
那麼結果如何呢?
除了我和一堆硬體之外,還有其他人使用這些硬體:直接位於資料中心的工程師;配置網路軟體的網路工程師;管理員或 SRE,確保基礎設施的容錯能力;和開發團隊,每個團隊負責入口網站的部分功能。他們創建的軟體的工作原理如下:
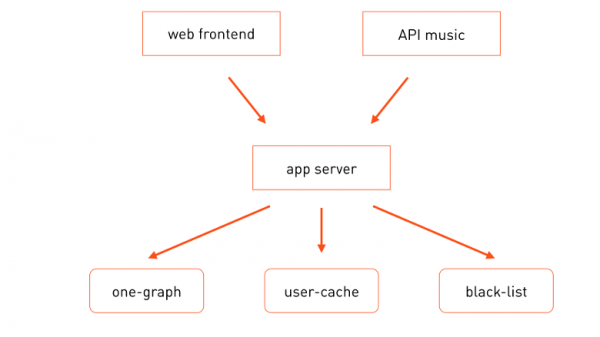
主入口網站的兩個前端均接收使用者請求 以及其他方面,例如音樂 API 方面。為了處理業務邏輯,他們調用應用程式伺服器,應用程式伺服器在處理請求時,調用必要的專門微服務 - one-graph(社交連接圖),user-cache(用戶設定檔快取)等。
這些服務中的每一個都部署在多台機器上,並且每個服務都有專門的開發人員負責模組的功能、運行和技術開發。所有這些服務都是在硬體伺服器上啟動的,直到最近我們才在每個伺服器上啟動一個任務,即它專門用於特定任務。
這是為什麼?這種方法有幾個優點:
- 變得更容易 群眾控制。假設該任務需要一些庫和一些設定。然後將伺服器指派給一個特定的群組,描述該群組的 cfengine 策略(或已經描述過),並將此配置集中自動推廣到該群組中的所有伺服器。
- 它被簡化了 診斷。假設您查看增加的 CPU 負載並意識到此負載只能由在該硬體處理器上執行的任務產生。對罪犯的搜捕很快就結束了。
- 它被簡化了 監控。如果伺服器出現問題,監視器會告訴您,您就會確切地知道誰應該受到指責。
由多個副本組成的服務會分配多個伺服器 - 每個伺服器一個。然後,服務的運算資源分配非常簡單:服務可以消耗與它擁有的伺服器數量相同的資源。這裡的「簡單」並不是指容易使用,而是指資源的分配是手動完成的。
這種方法也使我們能夠 專門的硬體配置 用於在此伺服器上執行的任務。如果任務儲存大量數據,我們使用具有4個磁碟機箱的38U伺服器。如果任務純粹是計算性的,那麼我們可以購買更便宜的 1U 伺服器。它的計算效率很高。除此之外,這種方法使我們能夠在與對我們友好的社交網路相當的負載下使用少四倍的機器。
如果我們從最昂貴的是伺服器這一前提出發,這種運算資源的使用效率也應該確保經濟效率。長期以來,最昂貴的是硬件,我們花了很多精力去降低硬體的價格,提出容錯演算法來降低對設備可靠性的要求。而今天我們已經到了伺服器價格不再是決定因素的階段。除非您正在考慮最新的特殊硬件,否則機架中伺服器的具體配置並不重要。現在我們面臨另一個問題——伺服器在資料中心所佔用的空間,也就是機架空間的價格。
意識到這是事實後,我們決定計算一下我們使用貨架的效率。
我們採用了經濟上合理的最強大伺服器的價格,計算出有多少台伺服器可以裝入機架,基於「一台伺服器=一項任務」的舊模型,我們可以在這些伺服器上運行多少項任務,以及這些任務對設備的利用率有多高。我們數著數著,流下了眼淚。事實證明,我們使用機架的效率約為11%。結論是顯而易見的:我們需要提高資料中心的使用效率。解決方案似乎很明顯:您需要在一台伺服器上同時執行多個任務。但困難也正是從這裡開始的。
大規模配置變得更加複雜 - 現在不可能將伺服器分配給單一群組。現在,可以在一台伺服器上啟動來自不同命令的多個任務。另外,不同應用程式之間的配置可能會發生衝突。診斷也變得更加複雜:如果您發現伺服器上的 CPU 或磁碟使用率增加,您就不知道哪個任務導致了問題。
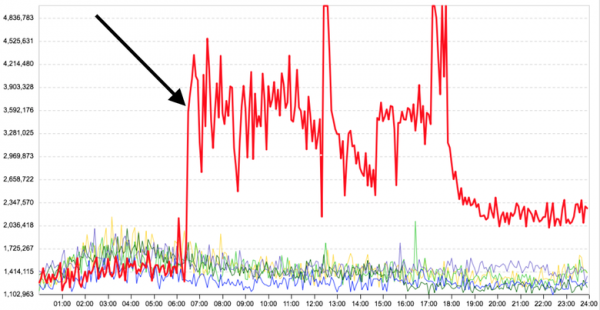
但最主要的是,同一台機器上執行的任務之間沒有隔離。例如,這是在同一台伺服器上啟動另一個計算應用程式(與第一個應用程式毫無關聯)之前和之後伺服器任務的平均回應時間的圖表 - 主任務的回應時間顯著增加。
顯然,我們需要在容器或虛擬機器中執行任務。因為我們幾乎所有的任務都在單一作業系統下運作(Linux或針對特定情況進行適配,我們無需支援多種作業系統。因此,虛擬化是不必要的;由於額外的開銷,其效率不如容器化。
作為直接在伺服器上運行任務的容器實現,Docker 是一個很好的候選者:檔案系統映像很好地解決了配置衝突的問題。由於映像可以由多層組成,因此我們可以透過將公共部分分離到單獨的基礎層來顯著減少將它們部署到基礎設施所需的資料量。然後,基礎層(和最大層)將在整個基礎設施中相當快速地緩存,並且只需要傳輸小層即可交付許多不同類型的應用程式和版本。
此外,Docker 中現成的註冊表和映像標記為我們提供了用於版本控制和將程式碼交付到生產的現成原語。
Docker 與任何其他類似技術一樣,為我們提供了一定程度的開箱即用的容器隔離。例如,記憶體隔離——每個容器都被賦予了機器記憶體使用的限制,超過這個限制就不會消耗。也可以透過 CPU 使用率來隔離容器。然而,對我們來說,標準的絕緣是不夠的。但下面會詳細介紹。
直接在伺服器上運行容器只是問題的一部分。另一部分與在伺服器上託管容器有關。您需要了解哪個容器可以安裝在哪個伺服器上。這並不是一件容易的事,因為容器需要盡可能密集地放置在伺服器上,同時又不能降低其效能。從容錯角度來看,這種部署也可能具有挑戰性。我們常常希望將同一服務的副本放置在資料中心的不同機架甚至不同房間中,這樣,如果一個機架或房間出現故障,我們不會立即丟失該服務的所有副本。
當您擁有 8 千台伺服器和 8-16 千個容器時,手動分發容器不是一個選擇。
此外,我們希望賦予開發人員更多資源分配自主權,以便他們可以自行將服務部署到生產環境中,而無需管理員的協助。同時,我們希望保持控制,以便某些次要服務不會消耗我們資料中心的所有資源。
顯然,需要有一個控制層來自動處理這個問題。
因此,我們得到了所有建築師都喜歡的簡單而清晰的畫面:三個正方形。
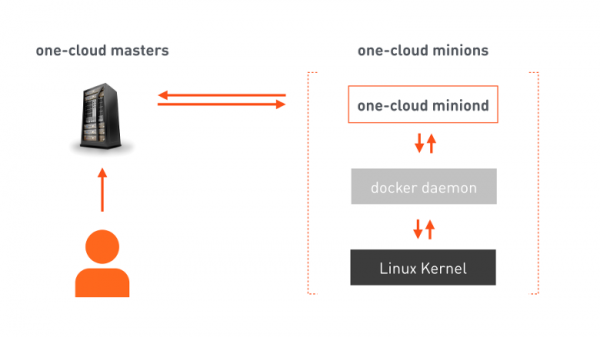
one-cloud masters 是一個負責雲端編排的容錯叢集。開發人員會向主機發送一份清單,其中包含託管服務所需的所有資訊。基於此,主機向選定的從機(設計用於啟動容器的機器)發出命令。在 minions 上有我們的代理,它接收命令,將其命令發送給 Docker,然後 Docker 配置 Linux 核心來啟動相應的容器。除了執行指令之外,代理程式還會不斷向主伺服器通報 minion 機器及其上執行的容器的狀態變更。
資源分配
現在讓我們來看看多個minions之間更複雜的資源分配問題。
一朵雲端中的運算資源是:
- 特定任務所消耗的處理器功率。
- 任務可用的內存量。
- 網路流量。每個 minion 都有一個特定的網路接口,頻寬有限,因此如果不考慮它們透過網路傳輸的資料量,就無法分配任務。
- 磁碟.顯然,除了為這些任務分配空間之外,我們還分配磁碟類型:HDD 或 SSD。磁碟每秒可以處理的請求數量是有限的 - IOPS。因此,對於產生的 IOPS 超過單一磁碟處理能力的任務,我們也會指派「主軸」 - 即必須專門為該任務保留的磁碟裝置。
然後對於某些服務,例如對於用戶緩存,我們可以這樣記錄所消耗的資源:400 個處理器核心、2,5 TB 內存、雙向 50 Gbit/s 流量、6 TB 硬碟空間,位於 100 個主軸上。或用更熟悉的形式:
alloc:
cpu: 400
mem: 2500
lan_in: 50g
lan_out: 50g
hdd:100x6T用戶快取服務資源僅消耗生產基礎設施中所有可用資源的一小部分。因此,我們希望確保使用者快取不會突然消耗超過分配的資源,無論是否因為操作員錯誤。也就是說,我們必須限制資源。但是我們可以將配額與什麼連結起來呢?
讓我們回到高度簡化的元件互動圖,並以更多細節重新繪製它 - 如下所示:
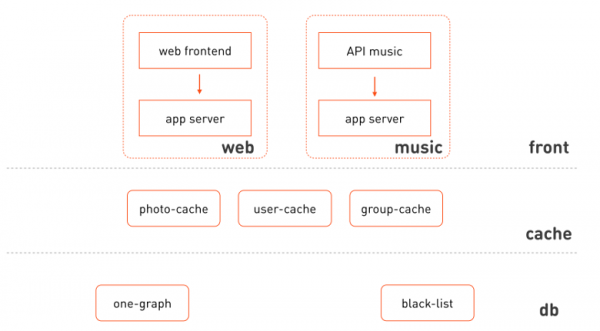
吸引你眼球的是:
- Web前端和音樂使用同一應用伺服器的隔離叢集。
- 我們可以區分這些叢集所屬的邏輯層:前端、快取、儲存層和資料管理。
- 前端不統一;它由不同的功能子系統組成。
- 快取還可以分散在快取資料的子系統中。
我們再重新畫一下圖:
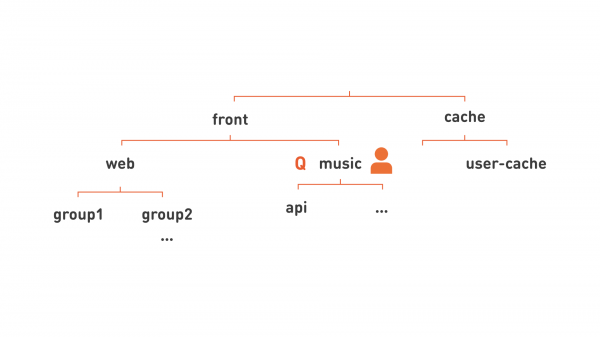
呸!是的,我們看到了層次結構!這意味著您可以將資源分配到更大的區塊中:將負責任的開發人員分配到此層次結構中與功能子系統(如圖中的「音樂」)相對應的節點,並將配額連結到層次結構的相同層級。這種層次結構也使我們能夠更靈活地組織服務,以方便管理。比如說所有的web,由於是一個非常大的伺服器群組,我們把它分成幾個小的群組,如圖中顯示為group1,group2。
透過刪除多餘的線條,我們可以以更平坦的形式寫出圖片的每個節點: group1.web.front, api.music.front, 使用者快取.cache.
這就是我們得出「分層隊列」概念的方式。它的名字類似於“group1.web.front”。它被分配了資源配額和使用者權限。我們將賦予 DevOps 人員將服務發送到佇列的權限,並且該人員可以在佇列中運行事物,我們將賦予 OpsDev 人員管理員權限,現在他們可以管理佇列、將人員分配到佇列、賦予這些人權限等。在該佇列中執行的服務將在佇列的配額內執行。如果佇列的計算配額不足以同時執行所有服務,則它們將按順序執行,從而形成佇列本身。
讓我們仔細看看這些服務。服務具有完全限定名稱,其中始終包含佇列名稱。那麼 Web 前端服務將具有下列名稱 ok-web.group1.web.front。並且它所訪問的應用程式伺服器服務將被調用 ok-app.group1.web.front。每個服務都有一個清單,其中指定了將其部署到特定機器所需的所有資訊:此任務消耗多少資源、需要什麼配置、應該有多少個副本以及處理此服務故障的屬性。當服務直接放置在機器上後,其實例就會出現。它們也被明確地命名為實例編號和服務名稱: 1.ok-web.group1.web.front,2.ok-web.group1.web.front,…
這非常方便:只需查看正在運行的容器的名稱,我們就可以立即發現很多資訊。
現在讓我們仔細看看這些標本實際上做了什麼:任務。
任務隔離類
OK 中的所有任務(可能所有地方的任務)都可以分成幾組:
- 短延任務 - 產品。對於這樣的任務和服務,回應延遲(等待時間)非常重要,即係統處理每個請求的速度有多快。任務範例:Web 前端、快取、應用程式伺服器、OLTP 儲存等。
- 計算任務——批量。這裡處理每個特定請求的速度並不重要。對他們來說重要的是這個任務在一定(較大的)時間段內將執行多少次計算(吞吐量)。這些將是任何 MapReduce、Hadoop、機器學習、統計任務。
- 後台任務 - 空閒。對於這樣的任務,延遲和吞吐量都不是很重要。這包括各種測試、遷移、重新計算以及從一種格式到另一種格式的資料轉換。一方面,它們與計算出來的類似,另一方面,我們並不真正關心它們完成的速度有多快。
讓我們看看這樣的任務是如何消耗資源的,例如中央處理器。
短延遲任務。 對於這樣的任務,CPU消耗模式將如下所示:
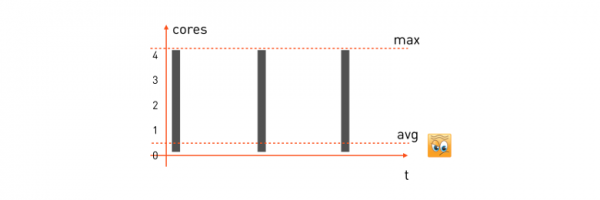
收到用戶的處理請求後,任務開始使用所有可用的 CPU 內核,進行處理,回傳回應,等待下一個請求並處於空閒狀態。下一個請求來了——我們再次選擇了所有我們擁有的東西,進行了計算,然後等待下一個請求。
為了確保此類任務的最小延遲,我們必須充分利用其消耗的資源,並在 minion(將執行該任務的機器)上保留所需數量的核心。那麼我們問題的預留公式如下:
alloc: cpu = 4 (max)如果我們有一台具有 16 個核心的 minion 機器,那麼正好可以在上面放置四個這樣的任務。特別值得注意的是,此類任務的平均 CPU 消耗通常非常低 - 這是顯而易見的,因為該任務花費了相當一部分時間等待請求而不執行任何操作。
計算問題。 它們的模式會略有不同:
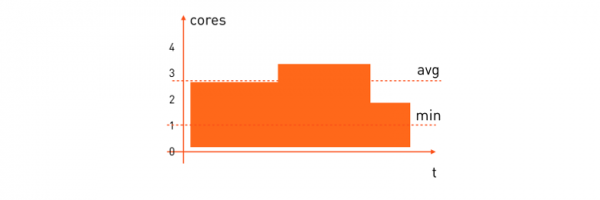
此類任務的平均 CPU 消耗相當高。很多時候我們希望一個計算任務能夠在一定的時間內完成,因此需要預留它所需的最少數量的處理器,以便整個計算能夠在可接受的時間內完成。其預留公式如下:
alloc: cpu = [1,*)“請將它放置在至少有一個空閒核心的僕從上,然後它會吞噬盡可能多的核心。”
這裡,使用效率已經比短延遲的任務好很多了。但是,如果您將兩種類型的任務結合在一台 minion 機器上並動態分配其資源,則收益將會更大。當一個延遲較短的任務需要處理器時,它會立即獲得處理器,而當不再需要資源時,它們會被轉移到計算任務,即如下所示:
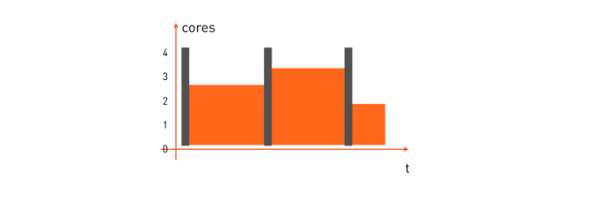
但是怎麼做呢?
首先,讓我們處理prod及其alloc:cpu = 4。我們需要預留四個核心。在 Docker 運行中,可以透過兩種方式完成此操作:
- 使用選項
--cpuset=1-4,即為該任務分配機器上的四個特定核心。 - 使用
--cpuquota=400_000 --cpuperiod=100_000,為處理器時間分配一個配額,即規定每100毫秒的實際時間任務消耗的處理器時間不超過400毫秒。獲得相同的四個核心。
但這些方法中哪一種會有效呢?
cpuset 看起來相當有吸引力。該任務有四個專用核心,這意味著處理器快取將盡可能有效地工作。這有一個缺點:我們必須承擔在機器的空閒核心而不是作業系統上分配計算的任務,這是一項相當不簡單的任務,特別是如果我們嘗試在這樣的機器上託管批次任務。測試表明,配額選項在這裡更適合:這讓作業系統在選擇當前時刻運行任務的核心時有更大的自由,並且處理器時間分配得更有效率。
讓我們弄清楚如何在 Docker 中預留最少數量的核心。批次任務的配額不再適用,因為不需要限制最大值,只要保證最小值就可以了。這個選項很適合這裡 docker run --cpushares.
我們同意,如果一批產品需要至少一個核心保證,那麼我們就指定 --cpushares=1024,如果至少有兩個核心,那麼我們指定 --cpushares=2048。只要有足夠的處理器時間,CPU 共享就不會幹擾處理器時間的分配。因此,如果 prod 目前沒有使用其全部四個核心,則批次任務不受任何限制,並且它們可以使用額外的 CPU 時間。但在處理器短缺的情況下,如果 prod 已經消耗了其所有四個核心並達到了配額,則剩餘的處理器時間將按比例分配給 cpushares,即在三個空閒核心的情況下,一個將由具有 1024 cpushares 的任務接收,其餘兩個將由具有 2048 cpushares 的任務接收。
但僅僅使用配額和份額是不夠的。我們需要確保在分配 CPU 時間時,低延遲任務的優先權高於批次任務。如果沒有這種優先權設置,當生產環境需要 CPU 時間時,批次任務就會佔用所有 CPU 時間。 Docker Run 本身沒有任何容器優先權選項,但 CPU 調度策略可以解決這個問題。 Linux您可以閱讀更多關於他們的資訊。 ,在本文的框架內,我們將簡要介紹它們:
- SCHED_OTHER
預設情況下,所有普通用戶進程都會接收 Linux-車。 - SCHED_BATCH
專為資源密集型流程而設計。當一個任務被放置在處理器上時,就會引入所謂的激活懲罰:如果該任務目前正在被具有 SCHED_OTHER 的任務使用,則該任務不太可能獲得處理器資源 - SCHED_IDLE
優先權非常低的後台進程,甚至低於 nice -19。我們使用我們的開源庫 ,以便在啟動容器時透過呼叫來設定所需的策略
one.nio.os.Proc.sched_setscheduler( pid, Proc.SCHED_IDLE )但即使您不使用 Java 編程,您也可以使用 chrt 命令執行相同的操作:
chrt -i 0 $pid為了清楚起見,我們將所有絕緣等級總結在一個表格中:
絕緣級別
分配範例
Docker 運行選項
sched_setscheduler chrt*
刺
CPU = 4
--cpuquota=400000 --cpuperiod=100000
SCHED_OTHER
批量
CPU = [1,*)
--cpushares=1024
SCHED_BATCH
空閒
CPU=[2,*)
--cpushares=2048
SCHED_IDLE
*如果您在容器內部執行 chrt,則可能需要 sys_nice 功能,因為預設情況下,Docker 在啟動容器時會取消此功能。
但任務不僅消耗處理器,還消耗流量,這比處理器資源的錯誤分配更能影響網路任務的延遲。因此,我們自然希望獲得完全相同的交通狀況。也就是說,當生產任務向網路發送一些資料包時,我們引用最大速度(公式 分配:lan=[*,500mbps) ),prod 可以用它來實現這一點。對於批量,我們只保證最小吞吐量,但不限制最大吞吐量(公式 分配:lan=[10Mbps,*) ) 在這種情況下,生產流量應該優先於批次任務。
這裡 Docker 沒有任何我們可以使用的原語。但他幫助了我們 。我們能夠透過紀律取得預期的結果。 。在它的幫助下,我們區分了兩類流量:高優先權生產流量和低優先權批量/空閒流量。因此,傳出流量的配置如下:
這裡 1:0 是 hsfc 規則的「根 qdisc」; 1:1——子類別 hsfc,總吞吐量限制為 8 Gbit/s,所有容器的子類別都放置在該類別下; 1:2 — 所有批次和空閒任務所共有的子類別 hsfc,具有「動態」限制,如下所述。其餘的 hsfc 子類是目前正在運行的生產容器的專用類,其限制與其清單相對應 - 450 和 400 Mbit/s。根據 Linux 核心版本,每個 hsfc 類別都分配有一個 qdisc 佇列 fq 或 fq_codel,以避免在流量突發期間遺失資料包。
通常,tc 規則僅用於確定傳出流量的優先順序。但我們也希望對傳入流量進行優先排序 - 畢竟,某些批次任務可以輕鬆選擇整個傳入通道,例如接收用於 map&reduce 的大量輸入資料包。為此我們使用模組 ,它為每個網路接口創建一個虛擬 ifbX 接口,並將來自該接口的傳入流量重定向到傳出 ifbX。此外,對於 ifbX,所有相同的規則都用於控制傳出流量,其 hsfc 配置非常相似:
在實驗過程中,我們發現,當 1:2 類非優先權批次/空閒流量在 minion 機器上限制為不超過一些可用頻寬時,hsfc 會顯示出最佳效果。否則,非優先權流量會對生產任務延遲產生太大影響。 miniond 每秒透過測量該 minion 的所有 prod-task 的平均流量消耗來確定目前空閒頻寬的值。  並從網路介面頻寬中減去它
並從網路介面頻寬中減去它  以較小的幅度,即
以較小的幅度,即

頻段是針對傳入和傳出流量單獨定義的。並且根據新的值,miniond重新配置非優先權類別1:2的限制。
因此,我們實作了所有三個隔離類別:prod、batch 和idle。這些類別對任務執行特性有很大的影響。因此,我們決定將此功能放在層次結構的頂部,以便在查看分層佇列的名稱時,可以立即清楚我們正在處理什麼:
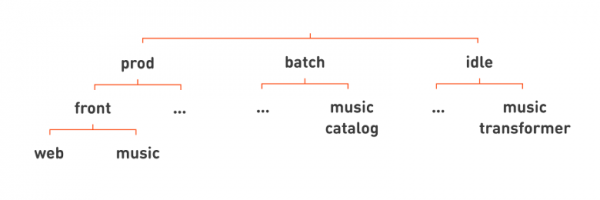
我們所有的朋友 捲筒紙 и 音樂 然後將前端放置在產品下的層次結構中。例如,我們將一個服務放在批次下 音樂目錄,它會定期從上傳到 Odnoklassniki 的一組 mp3 檔案中彙編曲目目錄。處於空閒狀態的服務範例如下 音樂轉換器,使音樂音量正常化。
透過再次刪除多餘的行,我們可以透過將任務隔離類別附加到完整服務名稱的末尾來更平坦地編寫我們的服務名稱: web.front.prod, 目錄.音樂.批次, 變壓器.音樂.空閒.
現在,透過查看服務名稱,我們不僅了解它執行的功能,還了解它的隔離等級,從而了解它的關鍵性等。
一切都很美好,但有一個殘酷的事實。完全隔離在同一台機器上運行的任務是不可能的。
我們已經實現了:如果批量消耗大量 僅 處理器資源,然後是內建的 CPU 調度器 Linux 它能很好地完成自己的任務,幾乎不會對生產任務造成任何影響。然而,如果這個批次任務開始頻繁使用內存,相互影響就會顯現出來。這是因為生產任務的處理器記憶體快取會被“清空”,導致快取未命中率增加,處理器處理生產任務的速度也會變慢。這樣的批次任務可能會使我們典型的生產容器的延遲增加 10%。
由於現代網路卡具有內部資料包佇列,因此隔離流量變得更加困難。如果批次任務的資料包首先到達那裡,那麼它將首先通過電纜傳輸,並且您對此無能為力。
此外,到目前為止,我們只設法解決了 TCP 流量優先順序的問題:對於 UDP,hsfc 方法不起作用。即使在 TCP 流量的情況下,如果批次任務產生大量流量,這也會導致生產任務的延遲增加約 10%。
容錯
開發單雲的目標之一是提高Odnoklassniki的容錯能力。因此,我想進一步更詳細地考慮可能發生故障和事故的情況。讓我們從一個簡單的場景開始——容器故障。
容器本身可能會以多種方式發生故障。這可能是清單中的一些實驗、錯誤或錯誤,導致生產任務消耗的資源比清單中指定的資源要多。我們遇到過一個案例:一位開發人員實現了一個複雜的演算法,多次修改,過度勞累,最終變得非常困惑,以至於任務最終以一種非常不平凡的方式循環。由於 prod 任務比同一 minions 上的所有其他任務具有更高的優先級,因此它開始消耗所有可用的處理器資源。在這種情況下,隔離,或者更準確地說是處理器時間配額,挽救了局面。如果為某個任務分配了配額,則該任務將不會消耗更多。因此在同一台機器上運行的批次和其他生產任務沒有註意到任何事情。
第二個可能出現的問題是容器掉落。在這裡重啟策略拯救了我們,每個人都知道它們,Docker 可以很好地應對它們。幾乎所有生產任務都有始終重啟策略。有時我們會使用 on_failure 來執行批次任務或偵錯生產容器。
如果整個 Minion 都不可用,該怎麼辦?
顯然,在另一台機器上運行容器。這裡有趣的是分配給容器的 IP 位址會發生什麼。
我們可以為容器分配與運行這些容器的 minion 機器相同的 IP 位址。然後,當你在另一台機器上啟動一個容器時,它的 IP 位址會發生變化,並且所有用戶端都必須了解該容器已經移動,現在它們需要轉到不同的位址,這需要單獨的服務發現服務。
服務發現很方便。市場上有許多用於組織服務註冊表的解決方案,它們具有不同程度的容錯能力。通常,此類解決方案實現負載平衡器邏輯、以 KV 儲存形式儲存附加配置等。
但是,我們希望避免實施單獨的註冊表,因為這意味著引入生產中所有服務使用的關鍵系統。這意味著這是一個潛在的故障點,您需要選擇或開發一個容錯能力極強的解決方案,這顯然非常困難、耗時且昂貴。
另一個很大的缺點是:為了使我們的舊基礎設施能夠與新的基礎設施協同工作,我們必須重寫所有任務以使用某種服務發現系統。有很多工作要做,而且在某些地方,當涉及到在作業系統核心層級或直接與硬體一起工作的低階設備時,這是不可能的。使用已建立的解決方案模式來實現此功能,例如 這意味著在某些地方會有額外的負載,而在其他地方則意味著更複雜的操作和更多的故障情況。我們不想讓事情變得更加複雜,所以我們決定讓服務發現的使用成為可選項。
在單一雲中,IP跟隨容器,這表示每個任務實例都有自己的IP位址。此位址是「靜態的」:當服務首次傳送到雲端時,它會被指派給每個實例。如果服務在其生命週期內具有不同數量的實例,那麼最終將為其分配與最大實例數量相同的 IP 位址。
這些地址之後不會改變:它們被分配一次並在生產服務的整個生命週期中持續存在。 IP 位址跟隨容器穿越網路。如果容器被移到另一個 minion,位址也會跟著移動。
因此,服務名稱到其 IP 位址清單的對應很少改變。如果我們再次查看文章開頭提到的服務實例的名稱(1.ok-web.group1.web.front.prod, 2.ok-web.group1.web.front.prod, …),我們會注意到它們類似於 DNS 中使用的 FQDN。沒錯,我們使用 DNS 協定在服務執行個體的 IP 位址中顯示服務執行個體名稱。此外,此 DNS 傳回所有容器的所有保留 IP 位址 - 包括正在運行的和已停止的容器(假設使用了三個副本,並且我們在那裡保留了五個位址 - 所有五個位址都將被傳回)。客戶端收到此資訊後,將嘗試與所有五個副本建立連接,從而確定哪些副本正在運行。這個確定可用性的選項更加可靠;它不涉及DNS或服務發現,這意味著在保證資訊的相關性和這些系統的容錯性方面不存在難以解決的問題。此外,在整個入口網站運作所依賴的關鍵服務中,我們根本無法使用 DNS,而只是簡單地在設定中輸入 IP 位址。
跨容器實現 IP 傳輸可能比較棘手 - 我們將透過以下範例展示其工作原理:
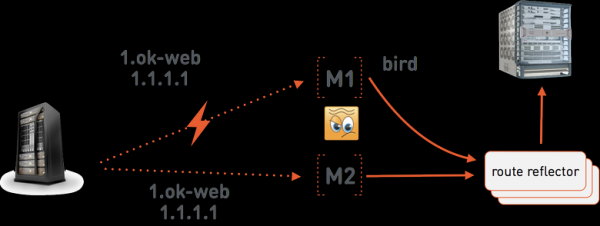
假設 One-Cloud Master 向 Minion M1 發出啟動指令 1.ok-web.group1.web.front.prod 地址為 1.1.1.1。它適用於 minion ,向特殊伺服器公佈該位址 後者與網路硬體建立 BGP 會話,並將位址 1.1.1.1 的路由廣播給 M1。 M1 使用 BGP 將封包路由到容器中。 LinuxOne-Cloud 基礎架構包含三台路由反射器伺服器,它們是其中的關鍵組成部分——缺少它們,One-Cloud 網路將無法運作。為了降低三台伺服器同時發生故障的風險,我們將它們放置在不同的機架中,最好是資料中心的不同機房內。
現在假設單雲主機和 M1 minion 之間的連線遺失了。現在,單雲主機將在 M1 完全失敗的假設下運行。也就是說,它將向 M2 minion 發出啟動命令 web.group1.web.front.prod 具有相同位址 1.1.1.1。現在網路中有兩條針對 1.1.1.1 的衝突路由:到 M1 和到 M2。為了解決此類衝突,我們使用 BGP 公告中指定的多出口鑑別器。這是一個顯示所通告路線權重的數字。在衝突的路由中,將選擇 MED 值較低的路由。單雲主控支援將 MED 作為容器 IP 位址的組成部分。第一次寫出的地址有相當大的 MED = 1。在這種緊急轉移貨櫃的情況下,主船會降低 MED,而 M000 將會收到一條命令,宣布地址為 000,MED = 2。在 M1.1.1.1 上工作的實例將保持無法通訊的狀態,它的進一步命運對我們來說並不重要,直到與主伺服器恢復通訊為止,屆時它將作為舊的副本停止。
事故
所有資料中心管理系統總是能夠以可接受的方式處理小故障。貨櫃懸垂幾乎在所有地方都是常態。
讓我們看看如何處理緊急情況,例如一個或多個資料中心房間發生電源故障。
災難對資料中心管理系統意味著什麼?首先,它是許多機器的大規模一次性故障,控制系統需要同時遷移很多容器。但如果故障規模非常大,則可能會發生所有任務無法重新分配給其他minions的情況,因為資料中心的資源容量會降至負載的100%以下。
事故的發生往往伴隨著控制層的故障。這可能是由於其設備故障而發生的,但更多的時候是由於沒有測試到故障,並且控制層本身因負載增加而失效。
有了這些我們能做什麼呢?
大規模遷移意味著基礎架構中發生大量的操作、遷移和部署。每次遷移都需要一些時間來將容器鏡像傳送和解壓到 minions、啟動和初始化容器等。因此,最好先啟動更重要的任務,然後再啟動不太重要的任務。
讓我們再一次看一下熟悉的服務層次結構,並試著決定我們要先執行哪些任務。
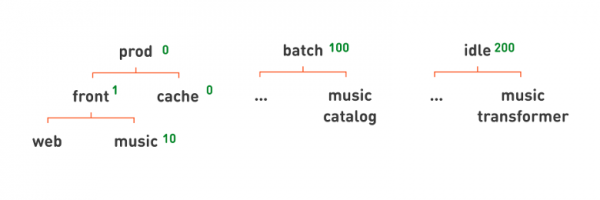
當然,這些都是直接涉及處理使用者請求的流程,即生產。我們藉助 放置優先權 — 可以指派給佇列的號碼。如果某個隊列具有較高的優先級,則其服務將優先處理。
在生產上我們分配更高的優先級,0;批次 - 稍低,100;空閒時 - 甚至更低,200。優先順序是按層次應用的。層次結構下方的所有任務都將具有對應的優先權。如果我們希望 prod 內部的快取在前端之前啟動,我們為 cache = 0 和 front subqueue = 1 分配優先權。例如,如果我們希望主入口網站先從前端啟動,然後才啟動音樂前端,那麼我們可以為後者分配較低的優先權 - 10。
下一個問題是缺乏資源。因此,我們的大量設備出現故障,整個資料中心都出現故障,而且我們推出了太多服務,以至於現在沒有足夠的資源來支援所有服務。我們需要決定犧牲哪些任務來維持核心關鍵服務的運作。
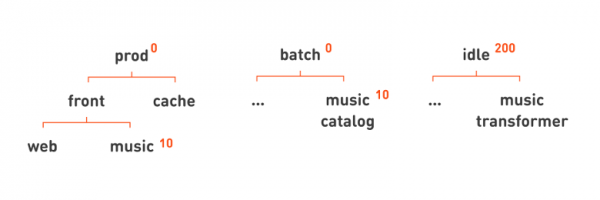
與放置優先順序不同,我們不能不加區別地犧牲所有批次任務,其中一些對於門戶的工作很重要。這就是為什麼我們單獨把它挑出來 搶佔優先級 任務。放置時,如果沒有更多空閒的僕從,則優先順序較高的任務可能會搶佔(即停止)優先級較低的任務。在這種情況下,低優先級任務可能會保持未放置狀態,即不再有具有足夠可用資源的合適下屬。
在我們的層級結構中,透過指定空閒優先級 200,可以輕鬆指定搶佔優先級,這樣生產任務和批次任務就可以搶佔或殺死空閒任務,但不會相互搶佔或殺死空閒任務。就像放置優先順序一樣,我們可以使用我們的層次結構來描述更複雜的規則。例如,如果我們沒有足夠的資源用於主入口網站,我們將透過將對應節點設定為較低的優先權:10 來指定犧牲音樂功能。
華盛頓特區事故全覽
為什麼整個資料中心可能會發生故障?元素。有一篇很好的帖子,例如 。這些因素可以被認為是無家可歸的人,他們曾經燒壞了收集器中的光學器件,並且資料中心與其他站點完全失去了連接。故障也可能由人為因素引起:操作員發出一個命令,導致整個資料中心崩潰。這可能是由於一個重大錯誤而發生的。一般來說,資料中心都會發生故障——這並不罕見。每隔幾個月我們就會遇到一次這樣的情況。
我們這樣做是為了確保沒有人在 Twitter 上發布#oklive。
第一個策略是隔離。每個單雲實例都是隔離的,只能管理來自一個資料中心的機器。也就是說,由於錯誤或錯誤的操作員命令而導致雲端的損失只是一個資料中心的損失。我們已經為此做好了準備:有一個冗餘策略,其中應用程式和資料的副本放置在所有資料中心。我們使用故障轉移資料庫並執行定期故障轉移測試。
由於我們目前有四個資料中心,因此我們也有四個獨立的、完全隔離的單雲實例。
這種方法不僅可以防止物理故障,還可以防止操作員錯誤。
對於人為因素我們還能做些什麼呢?當操作員向雲發出一些奇怪或潛在危險的命令時,它可能會突然被要求解決一個小問題來測試它的思考能力。例如,如果它是大量停止許多副本或只是一個奇怪的命令 - 減少副本數量或更改圖像名稱,而不僅僅是新清單中的版本號。
結果
一雲的顯著特徵:
- 服務和容器的分層和視覺化命名方案,它可以讓您非常快速地找出任務是什麼、與什麼相關、如何工作以及誰負責。
- 我們運用自己的 結合生產和批量技術為了提高機器共享效率,我們在 Minions 上執行任務。我們不使用 CPU 集,而是使用 CPU 配額、份額、CPU 調度策略等。 Linux QoS。
- 在同一台機器上運作的容器之間無法完全隔離,但它們之間的相互影響仍在20%以內。
- 將服務組織成層次結構有助於使用自動災難恢復 安置和流離失所優先事項.
常問問題
為什麼我們不採取現成的解決方案?
- 不同的任務隔離類別在部署到 minions 時需要不同的邏輯。雖然可以透過簡單地預留資源來放置生產任務,但批次和空閒任務需要透過追蹤 minion 機器上的實際資源利用率來放置。
- 需要考慮以下任務所消耗的資源:
- 網路頻寬;
- 磁碟的類型和“主軸”。
- 消除事故時需要指定服務的優先順序、團隊對資源的權利和配額,透過一雲中的分層佇列來解決。
- 需要具有人類可讀的容器命名,以減少對事故和事件的回應時間
- 無法一次廣泛實施服務發現;需要與託管在硬體主機上的任務長期共存——這個問題可以透過跟隨容器的「靜態」IP 位址來解決,因此需要與大型網路基礎設施進行獨特的整合。
所有這些功能都需要對現有解決方案進行大量客製化,在評估工作量後,我們意識到我們可以用大約相同的努力來開發自己的解決方案。但是您自己的解決方案將更易於操作和開發 - 它不包含支援我們不需要的功能的不必要的抽象。
對於那些讀到最後幾行的人,感謝你們的耐心和關注!
來源: www.habr.com
