

系統越複雜,各種警報越多。 並且需要對這些相同的警報做出反應,匯總它們並可視化它們。 我認為這種情況對很多人來說都很熟悉,甚至到了緊張的程度。
將要討論的解決方案並不是最出乎意料的,但搜尋並沒有返回有關該主題的完整文章。
因此,我決定分享 FunCorp 的經驗,並討論值班流程的結構、誰打電話、為什麼以及如何看待這一切。

什麼是 PagerDuty?
因此,為了解決所有這些問題,我們開始尋找一個方便的工具。 經過一番搜索,我們選擇了 PagerDuty。 在我們看來,PD 是一個相當完整和簡潔的解決方案,具有大量的整合和設定。 她喜歡什麼?
簡而言之,PagerDuty是一個事件處理平台,可以透過各種整合處理傳入的事件,設定值班指令,然後根據事件的層級向值班工程師發出警報(高等級-呼叫,低階-來自應用程式/簡訊的推播)。
值班人員是誰?
這可能是開始設定 PD 的第一個地方。
與其他公司一樣,FunCorp 也設有值班人員的榮譽職位。 它每天在工程師之間傳送一次。 對來自 PagerDuty 的警報器有所謂的第一行和第二行響應。 假設一個高優先級警報到達,如果從第一條線路呼叫值班人員 10 分鐘後沒有反應(即,沒有轉入確認或已解決狀態),則呼叫轉到第二條線路值班工程師。 這是透過升級策略在 PagerDuty 本身中配置的。
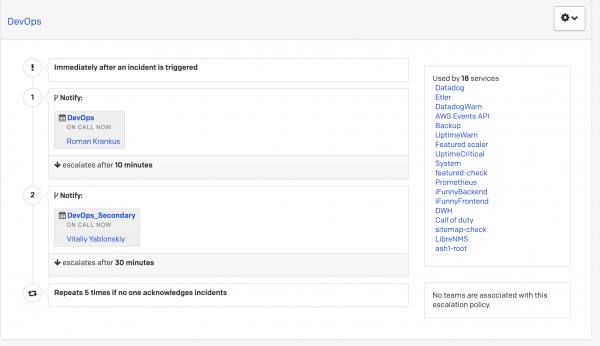
如果第二值班人員沒有回應,通知將返回到 主要的 給值班人員。
因此,任何傳入的高優先級警報都無法保持未處理狀態。
現在讓我們看看事件可能來自哪裡。
我們使用什麼整合?
PD 從不同的服務部門收到許多不同的事件。 我們目前擁有大約 25 個此類服務,為了處理它們,我們使用了一些現成的整合。
- 普羅米修斯
主要的指標收集系統是Prometheus。 Habré 上已經寫了很多關於它的文章,我只想說我們有幾個針對不同環境的指標:一個從虛擬機器和Docker 收集指標,另一個從Amazon 服務收集指標,第三個從硬體機器收集指標。 Telegraf 主要用作指標導出器。
- 邮箱
我認為,從標題中也可以清楚看出一切。 此整合用於從 cron 執行的某些腳本發送通知。 PD 會提供您一個您可以寄信的特定地址。 建立具有此類整合的服務時,您可以設定優先順序、處理傳入事件的順序、準確建立警報的方式(針對每個傳入信件、針對傳入信件 + 特定規則等)。

- 鬆弛
在我看來,這是一個非常有趣的整合。 有時會發生一些事情,但沒有被事件所涵蓋。 因此,我們添加了 Slack 的整合來建立事件。 也就是說,你可以寫信給企業Slack /callofduty 一切都很慢並且很快就會崩潰 PD 將進行處理並將事件發送給值班工程師。
我們的確是:

我們看:

- API
HTTP 整合。 事實上,這裡沒有什麼特別有趣的,只是一個帶有 JSON 格式的 body 的 POST 請求。 例如,一些有趣的事情:我們使用它進行外部監控 。 該服務檢查我們網站在世界不同地區的可訪問性。 如果我們收到不可接受的回應代碼(例如 502),則會建立事件,然後一切都遵循上述鏈。 StatusCake 本身能夠監控內部 URL、SSL 憑證或網域過期。
- 自由網路管理系統
這是另一個監控系統,您可以在他們的網站上閱讀更多相關信息 。 在它的幫助下,我們可以從伺服器監控網路介面和 iDRAC。
還有 Datadog、CloudWatch 等整合。 您可以更多地了解他們發生的事情 .
可視化
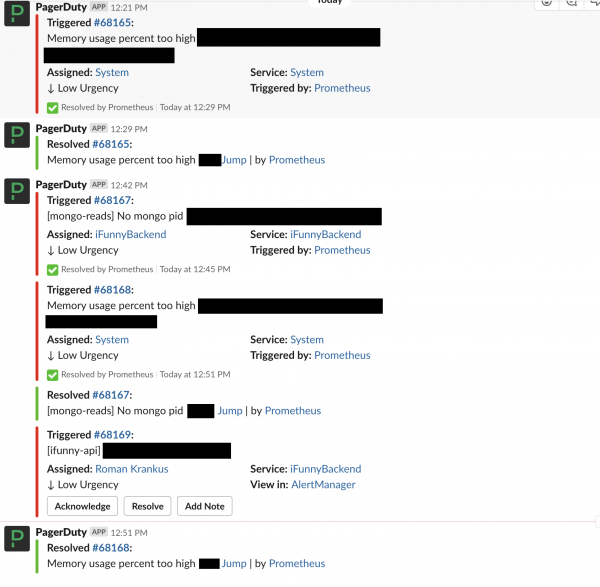
主要的事件報告系統是 Slack。 所有進入 PD 的事件都會寫入一個特殊的聊天室,如果其狀態發生變化,也會顯示在聊天室中。
當有機會在天花板上懸掛的顯示器螢幕上顯示有用的數據時,我們突然意識到我們(在 DevOps 部門)沒有任何東西可以在它們上顯示。 有一個很棒的 Grafana,但它並不能涵蓋所有內容,員工會對警報做出反應,而不是圖表。
在 GitHub 上徹底但未成功搜尋簡潔且資訊豐富的 PD「板」後,我們決定編寫自己的 - 只包含我們需要的內容。 雖然一開始也有把PD介面本身顯示出來的想法,但看起來更不方便。
要寫入它,您所需要做的就是從具有唯讀權限的 PD 取得金鑰。
這就是我們得到的:
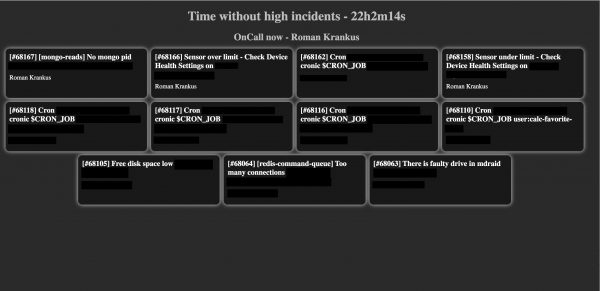
螢幕顯示目前未處理的事件、所選計畫中目前值班工程師的姓名以及沒有高優先事件的時間(具有高優先級事件的面板將以紅色突出顯示)。
.
因此,我們收到了一個方便的儀表板來查看所有事件。 如果你們中的一些人發現我們的經驗有用,我會很高興。
來源: www.habr.com
