

有時,開發人員需要 將一組參數甚至整個選擇傳遞給請求 “在入口”。 有時這個問題有非常奇怪的解決方案。
讓我們“從相反的方向”看看如何不這樣做、為什麼不這樣做以及如何做得更好。
在請求體中直接“插入”值
它通常看起來像這樣:
query = "SELECT * FROM tbl WHERE id = " + value...或者像這樣:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)關於這種方法,據說,書面和 足夠的:

幾乎總是這樣 SQL注入的直接路徑 以及業務邏輯的額外負載,它被迫“粘合”您的查詢字符串。
僅在必要時才可以部分證明這種方法的合理性。 使用分區 在 PostgreSQL 版本 10 及以下以獲得更有效的計劃。 在這些版本中,掃描部分的列表是在不考慮傳輸參數的情況下確定的,僅基於請求正文。
$n 個參數
使用 參數不錯,可以讓你用 ,減少了業務邏輯(查詢字符串只形成和傳輸一次)和數據庫服務器(不需要為每個請求實例重新解析和規劃)的負載。
可變數量的參數
當我們想提前傳遞未知數量的參數時,問題就在等著我們:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...如果您以這種形式留下請求,那麼雖然它可以使我們免於潛在的注入,但它仍然會導致需要粘合/解析請求 對於參數數量中的每個選項. 已經比每次都這樣做要好,但你可以沒有它。
只傳遞一個參數就足夠了 數組的序列化表示:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'唯一的區別是需要將參數顯式轉換為所需的數組類型。 但這不會造成問題,因為我們事先已經知道我們要解決的問題。
樣品轉移(矩陣)
通常這些是傳輸數據集以“在一個請求中”插入數據庫的各種選項:
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...除了上面描述的請求“重新粘貼”的問題之外,這還可以導致我們 內存不足 和服務器崩潰。 原因很簡單 - PG 為參數保留額外的內存,並且集合中的記錄數量僅受業務邏輯應用程序 Wishlist 的限制。 在特別的臨床病例中,有必要看到 大於 $9000 的“編號”參數 - 不要這樣做。
讓我們重寫查詢,已經應用 “兩級”連載:
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
是的,對於數組中的“複雜”值,它們需要用引號括起來。
很明顯,通過這種方式,您可以使用任意數量的字段“擴展”選擇。
不安, 不安, …
有時有一些選項可以傳遞我提到的幾個“列數組”而不是“數組數組” :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;使用這種方法,如果在為不同的列生成值列表時出錯,很容易得到完整的 意想不到的結果,這也取決於服務器版本:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
從 9.3 版開始,PostgreSQL 具有處理 json 類型的完整功能。 因此,如果您的輸入參數是在瀏覽器中定義的,您可以在那里和表單 用於 SQL 查詢的 json 對象:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'對於以前的版本,同樣的方法可以用於 每個(hstore),但是通過轉義 hstore 中的複雜對象來正確“折疊”可能會導致問題。
json_populate_recordset
如果你事先知道來自“輸入”json 數組的數據將填充到某個表中,你可以在“取消引用”字段和使用 json_populate_recordset 函數轉換為所需類型方面節省很多:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
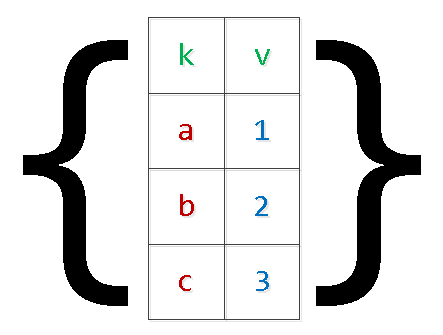
這個函數將簡單地將傳遞的對像數組“擴展”為一個選擇,而不依賴於表格格式:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2臨時表
但是如果傳輸的樣本中的數據量非常大,那麼將其扔到一個序列化參數中是很困難的,有時甚至是不可能的,因為它需要一次性 大內存分配. 比如,你需要從外部系統收集一大批事件數據,時間很長很長,然後你想在數據庫端一次性處理。
在這種情況下,最好的解決方案是使用 :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз
...
-- тут делаем что-то полезное со всей этой таблицей целиком
方法不錯 用於不經常傳輸大量數據 數據。
從描述其數據結構的角度來看,臨時表與“常規”表的區別僅在於一個特徵。 在 pg_class 系統表中,並在 pg_type, pg_depend, pg_attribute, pg_attrdef, ... ——什麼也沒有。
因此,在每個都有大量短連接的web系統中,這樣的表每次都會產生新的系統記錄,當與數據庫的連接關閉時,這些記錄將被刪除。 最終, 不受控制地使用 TEMP TABLE 導致 pg_catalog 中的表“膨脹” 並減慢許多使用它們的操作。
當然,這可以與 定期通過 VACUUM FULL 根據系統目錄表。
會話變量
假設前一個案例中的數據處理對於單個 SQL 查詢來說相當複雜,但您希望經常這樣做。 也就是說,我們要在 , 但通過臨時表使用數據傳輸將過於昂貴。
我們也不能使用 $n-parameters 傳遞給匿名塊。 會話變量和函數將幫助我們擺脫困境。 當前設置.
在版本 9.2 之前,您必須預先配置 自定義變量類 對於“他們的”會話變量。 在當前版本中,您可以這樣寫:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3在其他受支持的過程語言中還有其他可用的解決方案。
知道更多方法? 在評論中分享!
來源: www.habr.com
