

在本文中,我想談談全快閃 AccelStor 陣列與最受歡迎的虛擬化平台之一 VMware vSphere 配合使用的功能。 特別要注意那些可以幫助您從使用全快閃記憶體這樣強大的工具中獲得最大效果的參數。

AccelStor NeoSapphire™ 全快閃陣列 或 基於 SSD 驅動器的節點設備,採用完全不同的方法來實現資料儲存的概念並使用專有技術組織對其的訪問 而不是非常流行的 RAID 演算法。 陣列透過光纖通道或 iSCSI 介面提供對主機的區塊存取。 公平地說,我們注意到具有 ISCSI 介面的型號還具有文件存取功能,這是一個不錯的好處。 但在本文中,我們將重點放在使用區塊協定作為全快閃記憶體最高效的方式。
速源陣列與VMware vSphere虛擬化系統連動的部署及後續配置的整個過程可以分為幾個階段:
- SAN網路連接拓撲和配置的實作;
- 設置全快閃陣列;
- 配置ESXi主機;
- 設定虛擬機器。
AccelStor NeoSapphire™ 光纖通道陣列和 iSCSI 陣列用作範例硬體。 基礎軟體是VMware vSphere 6.7U1。
在部署本文所述的系統之前,強烈建議您閱讀 VMware 提供的有關效能問題的文件 ( )和 iSCSI 設定()
連接拓撲和 SAN 網路配置
SAN 網路的主要元件是 ESXi 主機中的 HBA、SAN 交換器和陣列節點。 此類網路的典型拓撲如下所示:
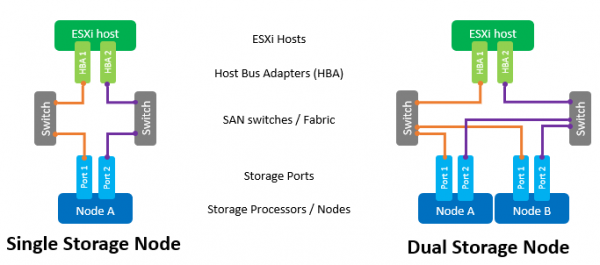
這裡的術語「交換器」既指單獨的實體交換器或一組交換器(Fabric),也指不同服務之間共享的設備(光纖通道中的 VSAN 和 iSCSI 中的 VLAN)。 使用兩個獨立的交換器/結構將消除可能的故障點。
儘管支援將主機直接連接到陣列,但強烈不建議這樣做。 全快閃陣列的性能相當高。 為了獲得最大速度,必須使用陣列的所有連接埠。 因此,主機和 NeoSapphire™ 之間至少存在一個交換器是強制性的。
主機 HBA 上存在兩個連接埠也是實現最大效能和確保容錯的強制要求。
使用光纖通道介面時,必須配置分區以消除啟動器和目標之間可能發生的衝突。 區域的建置原則是「一個啟動器連接埠 - 一個或多個陣列連接埠」。
如果您在使用與其他服務共用的交換器的情況下使用透過 iSCSI 的連接,則必須在單獨的 VLAN 內隔離 iSCSI 流量。 也強烈建議啟用對巨型幀 (MTU = 9000) 的支持,以增加網路上資料包的大小,從而減少傳輸過程中的開銷資訊量。 然而,值得記住的是,為了正確操作,有必要更改「發起者-交換器-目標」鏈上所有網路元件上的 MTU 參數。
設定全快閃陣列
該陣列交付給已經組成團體的客戶 。 因此,無需採取任何措施將驅動器組合到單一結構中。 您只需建立所需大小和數量的磁碟區。
為了方便起見,可以一次批量創建多個給定大小的捲。 預設情況下,會建立精簡卷,因為這樣可以更有效地使用可用儲存空間(包括對空間回收的支援)。 在性能方面,「薄」捲和「厚」卷之間的差異不超過1%。 但是,如果您想從陣列中“榨取所有汁液”,則始終可以將任何“薄”卷轉換為“厚”卷。 但應該記住,這樣的操作是不可逆的。
接下來,仍然是「發布」建立的捲,並使用 ACL(iSCSI 的 IP 位址和 FC 的 WWPN)和陣列連接埠的實體隔離從主機設定對它們的存取權。 對於 iSCSI 模型,這是透過建立目標來完成的。
對於 FC 型號,透過為陣列的每個連接埠建立 LUN 來進行發布。
為了加快設定過程,可以將主機組合成群組。 此外,如果主機使用多連接埠 FC HBA(這種情況在實際中最常發生),則由於 WWPN 相差 XNUMX,系統會自動確定此類 HBA 的連接埠屬於單一主機。 這兩個介面還支援批量建立目標/LUN。
使用 iSCSI 介面時的一個重要注意事項是一次為磁碟區建立多個目標以提高效能,因為目標上的佇列無法變更並且實際上會成為瓶頸。
配置 ESXi 主機
在ESXi主機端,根據完全預期的場景進行基本配置。 iSCSI 連線過程:
- 添加軟體 iSCSI 轉接器(如果已添加,或如果您正在使用硬體 iSCSI 轉接器,則不需要);
- 建立 iSCSI 流量將通過的 vSwitch,並向其添加實體上行鏈路和 VMkernal;
- 將數組位址加入動態發現;
- 資料儲存創建
一些重要的注意事項:
- 當然,在一般情況下,您可以使用現有的 vSwitch,但在單獨的 vSwitch 的情況下,管理主機設定會容易得多。
- 有必要將管理和 iSCSI 流量分離到單獨的實體連結和/或 VLAN 上,以避免效能問題。
- 同樣由於效能問題,VMkernal 的 IP 位址和全快閃陣列的對應連接埠必須位於同一子網路內。
- 為了確保 VMware 規則容錯,vSwitch 必須至少有兩個實體上行鏈路
- 如果使用巨型幀,則需要更改 vSwitch 和 VMkernal 的 MTU
- 需要提醒您的是,根據 VMware 對用於處理 iSCSI 流量的實體適配器的建議,有必要配置分組和故障轉移。 特別是,每個 VMkernal 必須只透過一個上行鏈路工作,第二個上行鏈路必須切換到未使用模式。 為了實現容錯,您需要新增兩個 VMkernal,每個 VMkernal 將透過其自己的上行鏈路工作。
VMkernel 適配器 (vmk#)
實體網路介面卡 (vmnic#)
vmk1(存儲01)
有源適配器
虛擬網卡2
未使用的適配器
虛擬網卡3
vmk2(存儲02)
有源適配器
虛擬網卡3
未使用的適配器
虛擬網卡2
透過光纖通道連接不需要任何預備步驟。 您可以立即建立資料儲存。
建立資料儲存後,您需要確保目標/LUN 路徑的循環策略被用作最高效能。
預設情況下,VMware 設定會根據方案提供此策略的使用:透過第一條路徑的 1000 個請求,透過第二條路徑的接下來的 1000 個請求,依此類推。 主機和雙控制器陣列之間的這種交互作用將是不平衡的。 因此,我們建議透過 Esxcli/PowerCLI 設定 Round Robin 策略 = 1 參數。
參數
對於 Esxcli:
- 列出可用的 LUN
esxcli儲存nmp設備列表
- 複製設備名稱
- 更改循環策略
esxcli storage nmp psp roundrobin deviceconfig set —type=iops —iops=1 —device=“Device_ID”
大多數現代應用程式都設計用於交換大數據包,以最大限度地提高頻寬利用率並減少 CPU 負載。 因此,ESXi 預設以最多 32767KB 的區塊向儲存裝置發出 I/O 請求。 然而,對於某些場景,交換較小的區塊會更有效率。 對於 AccelStor 陣列,有以下場景:
- 虛擬機器使用 UEFI 而不是 Legacy BIOS
- 使用 vSphere Replication
對於此類場景,建議將Disk.DiskMaxIOSize參數的值變更為4096。
對於 iSCSI 連接,建議將登入逾時參數變更為 30(預設為 5),以提高連接穩定性並停用轉送封包確認的 DelayedAck 延遲。 這兩個選項都位於 vSphere Client 中:主機 → 配置 → 儲存 → 儲存適配器 → iSCSI 適配器的進階選項
一個相當微妙的問題是用於資料儲存的捲的數量。 顯然,為了便於管理,希望為陣列的整個磁碟區建立一個大磁碟區。 然而,多個磁碟區的存在以及相應的資料儲存對整體效能有有益的影響(更多關於下面的佇列的資訊)。 因此,我們建議至少創建兩個卷。
直到最近,VMware 還建議限制一個資料儲存上的虛擬機器數量,同樣是為了獲得盡可能高的效能。 不過,現在,尤其是隨著VDI的普及,這個問題就不再那麼嚴重了。 但這並沒有取消長期存在的規則──將需要密集IO的虛擬機器分佈在不同的資料儲存上。 要確定每個磁碟區的最佳虛擬機器數量,沒有什麼比 在其基礎設施內。
設定虛擬機
設定虛擬機器時沒有特殊要求,或者說很普通:
- 使用盡可能高的VM版本(相容性)
- 當虛擬機器密集放置時,例如在 VDI 中,設定 RAM 大小會更加謹慎(因為預設情況下,啟動時會創建與 RAM 大小相當的頁面文件,這會消耗有用容量並影響系統效能)最終表演)
- 使用 IO 方面最高效的適配器版本:網路類型 VMXNET 3 和 SCSI 類型 PVSCSI
- 使用厚置備置零磁碟類型以獲得最大效能,使用精簡置備來獲得最大儲存空間利用率
- 如果可能,使用虛擬磁碟限制限制非 I/O 關鍵電腦的操作
- 一定要安裝VMware Tools
隊列注意事項
佇列(或未完成的 I/O)是特定裝置/應用程式在任何給定時間等待處理的輸入/輸出請求(SCSI 命令)的數量。 如果佇列溢出,則會發出 QFULL 錯誤,最終導致延遲參數增加。 當使用磁碟(主軸)儲存系統時,理論上,隊列越高,其效能越高。 但是,您不應該濫用它,因為它很容易遇到 QFULL。 就全快閃系統而言,一方面,一切都比較簡單:畢竟,陣列的延遲要低幾個數量級,因此,大多數情況下,不需要單獨調節佇列的大小。 但另一方面,在某些使用情境下(特定虛擬機器的IO需求強烈傾斜、測試最大效能等)是必要的,如果不改變佇列的參數,那麼至少要了解哪些指標能不能實現,主要是透過什麼方式實現。
AccelStor 全快閃陣列本身沒有磁碟區或 I/O 連接埠方面的限制。 如果需要,即使是單一磁碟區也可以接收陣列的所有資源。 佇列的唯一限制是 iSCSI 目標。 正是出於這個原因,上面指出需要為每個卷創建多個(理想情況下最多 8 個)目標來克服此限制。 我們也要重申一下,AccelStor 陣列是非常有效率的解決方案。 因此,您應該使用系統的所有介面連接埠以達到最大速度。
在ESXi主機端,情況完全不同。 主辦單位本身採用所有參與者平等存取資源的做法。 因此,客戶作業系統和 HBA 有單獨的 IO 佇列。 到客戶作業系統的佇列由到虛擬 SCSI 適配器和虛擬磁碟的佇列組合而成:
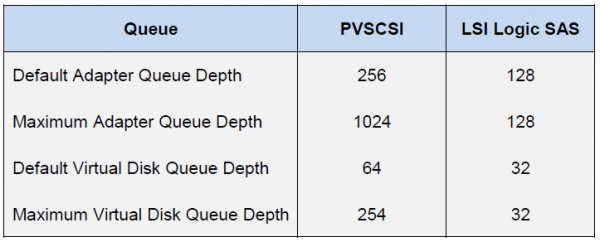
HBA 的佇列取決於特定類型/供應商:
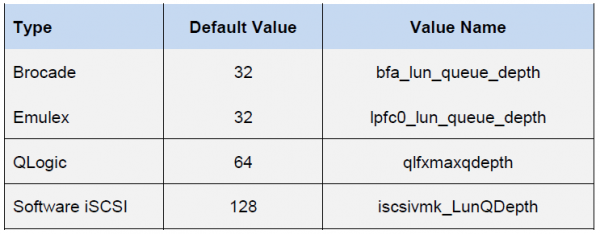
虛擬機器的最終效能將由主機元件中的最低佇列深度限制決定。
借助這些值,我們可以評估在特定配置中可以獲得的效能指標。 例如,我們想知道延遲為0.5ms的虛擬機器(沒有區塊綁定)的理論效能。 那麼它的 IOPS = (1,000/延遲) * 未完成的 I/O (佇列深度限制)
Примеры
例如1
- FC Emulex HBA 轉接器
- 每個資料儲存一台虛擬機
- VMware 準虛擬 SCSI 適配器
這裡隊列深度限制由 Emulex HBA 決定。 因此IOPS = (1000/0.5)*32 = 64K
例如2
- VMware iSCSI 軟體適配器
- 每個資料儲存一台虛擬機
- VMware 準虛擬 SCSI 適配器
這裡的佇列深度限制已經由準虛擬 SCSI 適配器決定。 因此IOPS = (1000/0.5)*64 = 128K
全快閃 AccelStor 陣列的頂級型號(例如, )能夠在 700K 區塊上提供 4K IOPS 寫入效能。 對於這樣的區塊大小,很明顯單一虛擬機器無法載入這樣的陣列。 為此,您將需要 11 個(例如 1 個)或 6 個(例如 2 個)虛擬機器。
因此,透過正確配置虛擬資料中心的所有描述的組件,您可以獲得非常令人印象深刻的效能結果。
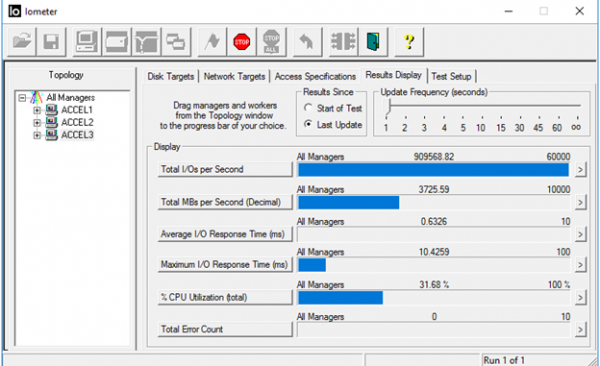
4K 隨機,70% 讀取/30% 寫入
事實上,現實世界比用簡單的公式描述的要複雜得多。 一台主機始終承載多個具有不同配置和 IO 要求的虛擬機器。 I/O處理由主機處理器處理,其能力不是無限的。 因此,要釋放相同的全部潛力 實際上,您將需要三個主機。 另外,在虛擬機器內執行的應用程式會自行調整。 因此,為了精確確定尺寸,我們提供 全快閃陣列 在客戶的基礎設施內部處理目前的實際任務。
來源: www.habr.com
