


儘管現在幾乎到處都有大量數據,但分析資料庫仍然相當新穎。人們對它們的了解甚少,而且有效利用率甚至更低。許多人繼續使用為其他場景設計的 MySQL 或 PostgreSQL“吃仙人掌”,在 NoSQL 方面受苦,或為商業解決方案支付過高的費用。 ClickHouse 改變了遊戲規則,大大降低了進入分析型 DBMS 領域的門檻。
演講來自 BackEnd Conf 2018,並經演講者許可發布。


我是誰?為什麼我要談 ClickHouse?我是 LifeStreet 的開發總監,該公司使用 ClickHouse。我也是 Altinity 的創辦人。這是 Yandex 的合作夥伴,負責推廣 ClickHouse 並幫助 Yandex 讓 ClickHouse 取得更大的成功。我也準備好分享有關 ClickHouse 的知識。

我也不是 Petya Zaitsev 的兄弟。我常被問到這個問題。不,我們不是兄弟。

「大家都知道」ClickHouse:
- 非常快,
- 非常方便,
- 用於 Yandex。
人們對它有哪些公司使用以及如何使用還不太了解。

除了 Yandex 之外,我還會告訴您為什麼、在哪裡以及如何使用 ClickHouse。
我會告訴你不同的公司是如何借助 ClickHouse 解決具體任務的,你可以使用哪些 ClickHouse 工具來完成你的任務,以及它們在不同的公司是如何使用的。
我選擇了三個從不同角度展示 ClickHouse 的範例。我認為這會很有趣。

第一個問題是:「我們為什麼需要 ClickHouse?」這個問題似乎很明顯,但答案卻不只一個。

- 第一個答案是為了性能。 ClickHouse 很快。 ClickHouse 上的分析也非常快。它通常用於其他事物運行非常緩慢或非常差的情況。
- 第二個答案是成本。首先,是擴充的成本。例如,Vertica 是一個非常優秀的資料庫。如果您沒有很多 TB 的數據,它會非常有效。但是當我們談論數百 TB 或 PB 時,許可證和支援的成本就變得相當高。而且價格昂貴。而且 ClickHouse 是免費的。
- 第三個答案是交易成本。這是一種從稍微不同的角度來採取的方法。 RedShift 是一個很好的替代方案。在 RedShift 上您可以非常快速地做出決定。它會運作得很好,但是你每小時、每天、每月都要向亞馬遜支付相當多的費用,因為這是一項非常昂貴的服務。 Google BigQuery 也是如此。如果有人使用過它,他們就會知道,你可以執行幾個查詢,然後突然收到數百美元的帳單。
ClickHouse 沒有這些問題。

ClickHouse 現在在哪裡使用?除了 Yandex 之外,ClickHouse 也被許多不同的企業和公司使用。
- 首先,這是網頁應用程式分析,即來自 Yandex 的用例。
- 許多廣告科技公司使用 ClickHouse。
- 許多公司需要分析來自不同來源的操作日誌。
- 有些公司使用 ClickHouse 來監控安全日誌。他們將其上傳到 ClickHouse,建立報告,並獲得所需的結果。
- 企業開始將其用於財務分析,即大企業也逐漸接近ClickHouse。
- CloudFlare。如果有人有在關注 ClickHouse,他們可能聽過這家公司的名字。這是來自社區的重要貢獻者之一。他們有一個非常嚴肅的 ClickHouse 安裝。例如,他們為ClickHouse製作了Kafka Engine。
- 電信公司已經開始使用它。有多家公司使用 ClickHouse 作為概念驗證或已投入生產。
- 一家公司使用 ClickHouse 來監控製造流程。他們測試微電路,寫下一堆參數,大約有 2 個特性。然後他們分析這個聚會是好是壞。
- 區塊鏈分析。有一家俄羅斯公司叫 Bloxy.info。這是對以太坊網路的分析。他們也在 ClickHouse 上這麼做了。

規模大小並不重要。很多公司只用一台小型伺服器就能解決他們的問題。而更多的公司則使用由多台伺服器組成的大型叢集。 服務器 或者幾十台伺服器。
如果你看一下記錄,那麼:
- Yandex:擁有 500 多台伺服器,每天儲存 25 億筆記錄。
- LifeStreet:60 台伺服器,每天約 75 億筆記錄。與 Yandex 相比,伺服器更少,記錄更多。
- CloudFlare:36 台伺服器,每天儲存 200 億筆記錄。他們擁有的伺服器更少,但儲存的資料更多。
- 彭博:102 服務器每天約有萬億筆記錄。創紀錄保持者。
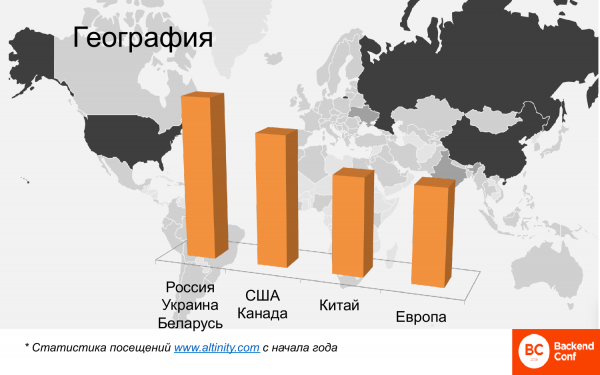
從地理位置上看,也很多。該地圖顯示了全球範圍內使用 ClickHouse 的熱圖。俄羅斯、中國和美國在此脫穎而出。歐洲國家很少。並且可以區分出 4 個簇。
這是一個比較分析;沒有必要尋找絕對數字。這是對在 Altinity 網站上閱讀英文資料的訪客的分析,因為那裡沒有俄文資料。其中俄羅斯、烏克蘭、白俄羅斯,也就是俄語社群的部分,是使用者最多的國家。接下來是美國和加拿大。中國正在迅速追趕。六個月前,中國在那裡幾乎不存在,但現在中國已經超越歐洲,而且還在持續成長。歐洲老太太也不甘落後,奇怪的是,ClickHouse 的使用領先者竟然是法國。

我為什麼要告訴你這些?說明ClickHouse正在成為大數據分析的標準解決方案,並且已經在許多地方使用。 如果您使用它,那麼您就走在了正確的趨勢上。如果您還沒有使用它,那麼您不必擔心您會孤軍奮戰,沒有人會幫助您,因為很多人已經在這樣做了。

這些都是 ClickHouse 在多家公司中被使用的真實範例。
- 第一個例子是廣告網路:從 Vertica 遷移到 ClickHouse。我知道有幾家公司已經轉換或正在轉換 Vertica。
- 第二個範例是 ClickHouse 上的事務儲存。這是一個基於反模式建構的範例。根據開發人員的建議,所有不應該在 ClickHouse 中完成的事情都在這裡完成。而且它做得非常有效,確實有效。而且它的效果比典型的交易解決方案好得多。
- 第三個例子是ClickHouse上的分散式計算。有一個問題是關於如何將 ClickHouse 整合到 Hadoop 生態系統中。我將展示一個範例,說明一家公司如何在 ClickHouse 上製作類似 map reduce 容器的東西,監控資料本地化等,以計算一個非常不簡單的任務。

- LifeStreet-這是一家廣告科技公司,擁有經營廣告網路所需的所有技術。
- 她從事廣告優化、程序化競價工作。
- 大量數據:每天約有 10 億個事件。在這種情況下,事件可以分為幾個子事件。
- 這些數據的客戶有很多,不只是人,還有更多——參與程序化競價的各種演算法。

該公司走過了一條漫長而又充滿荊棘的道路。我在 HighLoad 上談論了這個問題。 LifeStreet 最初從 MySQL(在 Oracle 上短暫停留)遷移到 Vertica。您還可以找到有關它的故事。
一切都很好,但很快就發現數據正在成長,而 Vertica 的價格昂貴。因此,人們尋求各種替代方案。這裡列出了其中一些。事實上,我們對 13 年至 16 年市場上幾乎所有在功能方面大致合適的資料庫進行了概念驗證或效能測試。我也在 HighLoad 上談論了其中的一些。

由於資料不斷增長,因此首要任務是從 Vertica 遷移。並且幾年來,它們呈指數級增長。然後他們就被放到了貨架上,但儘管如此。預測這種成長,即業務對需要進行某種分析的資料量的需求,很明顯很快就會出現PB層級的資料量。而且支付 PB 級的費用已經非常昂貴,因此他們尋找替代方案。
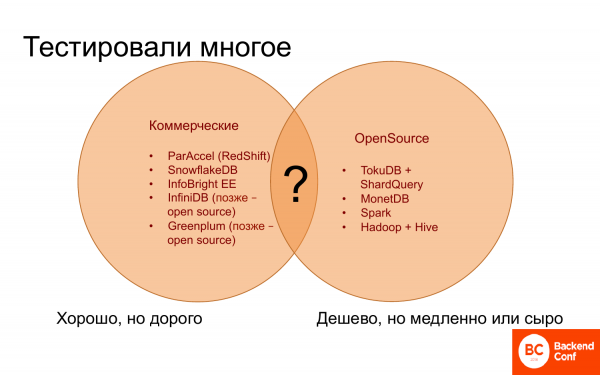
去哪裡?而且在很長一段時間內,我們完全不清楚該往哪裡走,因為一方面有商業資料庫,它們似乎運作良好。有些工作效果幾乎與 Vertica 一樣好,有些則不太好。但它們都很貴,我找不到更便宜或更好的。
另一方面,也有開源解決方案,但數量不多,也就是說,對於分析來說,屈指可數。而且它們是免費的或便宜的,但工作速度很慢。而且它們通常缺乏必要且有用的功能。
並且沒有任何東西能夠將商業資料庫中的優點和開源中所有免費的東西結合起來。

什麼都沒有發生,直到 Yandex 突然像魔術師從帽子裡變出一隻兔子一樣將 ClickHouse 拿了出來。這是一個出人意料的決定,人們仍然會問:「為什麼?」但無論如何。
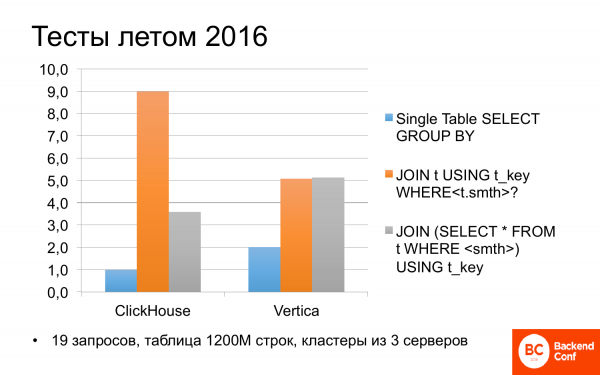
2016 年夏天,我們就開始研究 ClickHouse 是什麼。事實證明,它有時比 Vertica 更快。我們針對不同的查詢測試了不同的場景。如果查詢只使用一個表,即沒有任何連接,那麼 ClickHouse 的速度是 Vertica 的兩倍。
我並不懶惰,前幾天我看了 Yandex 的測驗。那裡也是一樣:ClickHouse 的速度是 Vertica 的兩倍,所以他們經常談論它。
但如果查詢中有連接,那麼一切都變得不是很清楚。而 ClickHouse 的速度可能是 Vertica 的兩倍。如果您稍微修正並重寫查詢,那麼它們將大致相等。不錯。而且是免費的。

在收到測試結果並從不同角度進行審查後,LifeStreet 選擇了 ClickHouse。

今年已經是第16年了,讓我提醒一下。這就像那個關於老鼠的笑話,老鼠哭了,自己被刺了,但仍然繼續吃仙人掌。對此進行了詳細的描述,有相關影片等等。

這就是為什麼我不會詳細討論它,我只會談論結果和一些我當時沒有談論的有趣的事情。
結果是:
- 遷移成功,系統已投入生產運作一年多。
- 生產力和靈活性都提高了。以前,LifeStreet 每天只能儲存 10 億筆記錄,而且儲存時間不長。而現在,LifeStreet 每天可以儲存 75 億筆記錄,而且可以儲存 3 個月甚至更長。如果以峰值計算,那麼每秒可以保存多達一百萬個事件。每天有超過一百萬個 SQL 查詢到達該系統,其中大部分來自各種機器人。
- 儘管 ClickHouse 開始使用比 Vertica 更多的伺服器,但在硬體上也節省了成本,因為 Vertica 使用了相當昂貴的 SAS 磁碟。 ClickHouse 使用 SATA。為什麼?因為在Vertica中插入是同步的。而且同步要求磁碟速度不要太慢,而且網路速度也不要太慢,也就是說,這是一項相當昂貴的操作。並且在 ClickHouse 中插入是異步的。此外,您始終可以在本地寫入所有內容,無需額外費用,因此 ClickHouse 中的資料插入速度比 Vertika 快得多,即使在不是最快的磁碟上也是如此。對於閱讀來說也差不多。在 SATA 上讀取,如果它們處於 RAID 中,那麼一切都會非常快。
- 不受許可證限制,即 3 台伺服器中的 60PB 資料(20 台伺服器為一個副本)和事實和聚合中的 6 兆筆記錄。 Vertica 無法提供這樣的服務。

現在我來談談這個例子中的實際內容。
- 一是方案有效。很大程度取決於方案。
- 第二是產生高效率的SQL。
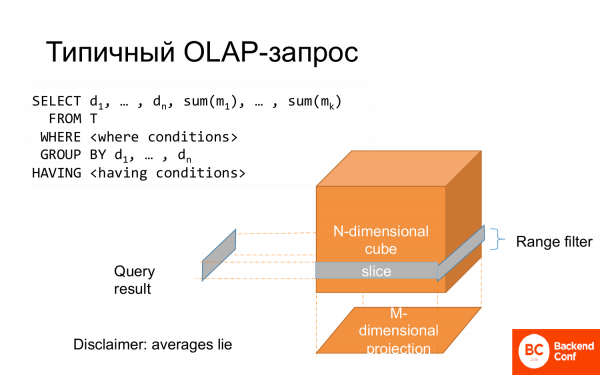
典型的 OLAP 查詢是選擇。有些列用於分組,有些列用於聚合函數。有一個地方,可以想像成立方體的一片。整個分組可以被認為是一個投影。這就是它被稱為多元資料分析的原因。

通常,這是以星圖的形式建模的,其中有一個中心事實,並且沿著射線在側面上有該事實的特徵。

從物理設計的角度來看,它如何適合表格,你通常做的是規範化的表示。您可以進行非規範化,但這會佔用大量磁碟空間,並且查詢效率也不太高。因此,他們通常會做出一個規範化的表示,即一個事實表和許多維度表。
但在 ClickHouse 中它不能很好地工作。原因有二:
- 首先是因為 ClickHouse 沒有很好的連接,即有連接,但很糟糕。到目前為止一切都很糟糕。
- 第二個是表格沒有更新。通常在星圖周圍的這些表中,需要進行一些更改。例如客戶姓名、公司名稱等。而且不起作用。
ClickHouse 中有解決這個問題的方法。甚至兩個:
- 首先是字典的使用。外部字典有助於解決星型模式、更新等 99% 的問題。
- 第二種是使用陣列。數組還有助於解決連接和規範化問題。

- 不需要連接。
- 可更新。自 2018 年 XNUMX 月以來,出現了一個未記錄的功能(您不會在文件中找到它)來部分更新字典,即那些已更改的條目。實際上,它就像一張桌子。
- 始終在記憶體中,因此與字典的連接比在磁碟上的表連接速度更快,而且它不在快取中,很可能不是。

- 也不需要連接。
- 這是一個緊湊的一對多表示。
- 在我看來,陣列是為極客設計的。這些是 lambda 函數等等。
這不僅僅是一句口號。這是一個非常強大的功能,可以讓您非常簡單、優雅地做很多事情。

有助於解決數組的典型範例。這些例子很簡單,而且很有說明性:
- 按標籤搜尋。如果您有主題標籤並且想要透過主題標籤來尋找一些貼文。
- 按鍵值對搜尋。還有一些有意義的屬性。
- 儲存需要翻譯成其他內容的按鍵的清單。
所有這些問題都可以不用數組來解決。標籤可以放在某行並使用正規表示式或在單獨的表中進行選擇,但隨後您必須進行連接。

而在 ClickHouse 中您不需要做任何事情,只需為主題標籤描述一個字串數組或為鍵值類型系統創建一個嵌套結構就足夠了。
嵌套結構也許不是最好的名稱。這兩個陣列的名稱中有共同的部分,並且具有一些相關的特徵。
而且透過標籤搜尋非常容易。有一個函數 has,檢查數組中是否有元素。就是這樣,我們找到了與我們的會議相關的所有記錄。
透過 subid 搜尋稍微複雜一些。我們首先需要找到鍵索引,然後取出具有該索引的元素並檢查該值是否是我們需要的。但儘管如此,它還是非常簡單和緊湊。
如果您必須將所有這些儲存在一行中,那麼您要編寫的正規表示式首先會很笨重。其次,它的工作時間比兩個陣列長得多。

另一個例子。您有一個用於儲存 ID 的陣列。你可以將它們翻譯成名字。功能 arrayMap。這是一個典型的 lambda 函數。您在那裡傳遞 lambda 表達式。對於每個 ID,它會從字典中提取名稱值。
您可以按照類似的方式進行搜尋。傳遞一個謂詞函數來檢查元素對應的內容。

這些東西大大簡化了方案並解決了許多問題。
但我想提一下我們遇到的下一個問題是高效查詢。
- ClickHouse 沒有查詢計劃器。一點也不。
- 然而,複雜的查詢仍然需要規劃。在什麼情況下?
- 如果查詢中有多個連接,則可以將它們包裝在子選擇中。並且完成這些事情的順序很重要。
- 其次,如果請求是分散式的。因為在分散式查詢中,只有最內層的子選擇是分散式執行的,而其他所有內容都傳遞到您連接並在那裡執行的單一伺服器。因此,如果您有包含許多連接的分散式查詢,則需要選擇順序。
即使在更簡單的情況下,有時也應該完成規劃器的工作並稍微重寫查詢。

這是一個例子。左側是顯示前 5 個國家的查詢。我認為它需要 2,5 秒。右側是相同的查詢,但稍微重寫了。我們不再按行分組,而是按鍵(int)分組。而且速度更快。然後我們將字典與結果連結起來。該請求的執行時間不是 2,5 秒,而是 1,5 秒。這很好。

重寫過濾器的類似範例。這是對俄羅斯的請求。需要5秒才能完成。如果我們以這樣的方式重寫它,即我們不再比較字串,而是比較與俄羅斯相關的一些鍵的數字,那麼它會快得多。

諸如此類的伎倆還有很多。它們可以顯著加快您認為已經運行很快的查詢速度,或者相反,運行很慢的查詢速度。它們可以製造得更快。

- 分散式模式下的最大工作量。
- 以最小類型排序,就像我按整數排序一樣。
- 如果有任何連接或字典,最好最後執行它們,當您已經至少有部分分組的資料時,連接操作或字典呼叫的次數就會更少,速度也會更快。
- 更換過濾器。
除了我所示範的技術之外,還有其他技術。有時,它們都能讓你大幅加快查詢的執行速度。

讓我們繼續下一個範例。來自美國的X公司。她在做什麼?
任務是:
- 線下連結廣告交易。
- 對不同的綁定模型進行建模。

場景是怎麼樣的?
例如,一個普通的訪客每個月會透過不同的廣告造訪該網站 20 次,或者有時不會透過任何廣告造訪該網站,因為他記住了這個網站。查看一些產品,將它們放入籃子,將它們從籃子中取出。最後,他還是買了一些東西。
合理的問題:「如果有必要,誰應該為廣告付費?」以及「哪些廣告對他產生了影響,如果有的話?」就是他為什麼要買,怎麼才能讓這個人這樣的人也買呢?
為了解決這個問題,您需要以正確的方式連接網站上發生的事件,即以某種方式在它們之間建立聯繫。然後將它們轉移到DWH進行分析。並基於此分析,建立向誰展示何種廣告的模型。

廣告交易是一組相關的使用者事件,首先顯示廣告,然後發生某件事,然後可能發生購買,然後可能發生購買中的購買。例如,如果它是一個行動應用程式或行動遊戲,那麼通常應用程式的安裝是免費的,但如果在那裡做了進一步的事情,那麼可能需要為此付費。用戶在應用程式上花費的越多,應用程式的價值就越高。但為此你需要連接一切。

綁定的模型有很多種。
最受歡迎的有:
- 最後一次互動,其中互動是點擊或展示。
- 首次互動,即使用者造訪網站的第一件事。
- 線性組合-每個人平等分配。
- 褪色。
- 等等。
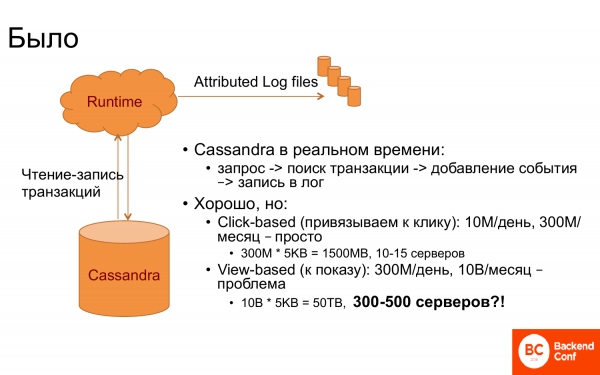
最初這一切是如何運作的呢?有 Runtime 和 Cassandra。 Cassandra 被用作交易存儲,即所有相關交易都存儲在其中。當運行時發生某些事件時,例如顯示某些頁面或其他內容,就會向 Cassandra 發出請求——無論是否存在這樣的人。然後檢索與其相關的交易。綁定就完成了。
如果您夠幸運,請求有一個交易 ID,那麼這很容易。但通常情況下,並沒有這樣的運氣。因此有必要找到最後一筆交易或最後一次點擊的交易等。
只要連結到最後一次點擊,一切都會運行得很好。因為如果你設定一個月的窗口,那麼每天就有 10 萬次點擊,每月就有 300 億次點擊。由於 Cassandra 中的所有內容都必須放在記憶體中才能快速運行,因為運行時需要快速回應,所以它需要大約 10-15 台伺服器。
但當他們想將交易與顯示器聯繫起來時,事情就變得沒那麼有趣了。為什麼?顯然,需要儲存 30 倍以上的事件。因此,需要增加 30 倍的伺服器。事實證明這是一個天文數字。為了進行連結而保留最多 500 台伺服器,考慮到運行時中的伺服器數量明顯較少,那麼這是一個錯誤的數字。他們開始思考該怎麼辦。

我們來到了 ClickHouse。如何在 ClickHouse 上執行此操作?乍一看,這似乎是一組反模式。
- 交易不斷增長,我們將越來越多的新事件掛接到其中,即它是可變的,而 ClickHouse 不能很好地處理可變對象。
- 當訪客來到我們這裡時,我們需要透過他的訪問 ID 按鍵來提取他的交易。這也是一個點查詢,ClickHouse 不會這麼做。通常 ClickHouse 有大量的掃描,但這裡我們需要取得多筆記錄。也是一種反模式。
- 此外,交易是 JSON 格式的,但他們不想重寫它,所以他們想以非結構化的方式儲存 JSON,並在必要時從中提取一些東西。這也是一種反模式。
也就是一組反模式。
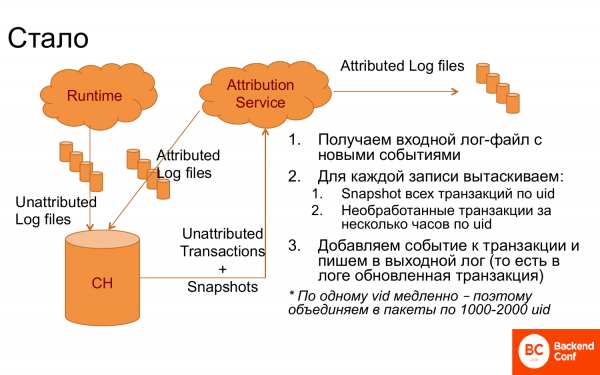
但儘管如此,我們還是成功創建了一個運作良好的系統。
做了什麼? ClickHouse出現了,日誌被丟進去,分解成記錄。出現了一個從 ClickHouse 接收日誌的歸因服務。之後,對於每個按訪問 ID 列出的條目,我都會收到可能尚未處理的交易,以及快照,即已經連結的交易,即先前工作的結果。我已經從中得出了邏輯,選擇了正確的交易,並連接了新的事件。我又把它記在日誌裡了。日誌又回到ClickHouse,也就是說它是一個不斷循環的系統。此外,我還去了 DWH 那裡進行分析。
以那種形式,效果不太好。為了讓 ClickHouse 更輕鬆,當有按訪問 ID 發出的請求時,我們會將這些請求分組為 1-000 個訪問 ID 的區塊,並提取 2-000 人的所有交易。然後一切就都成功了。
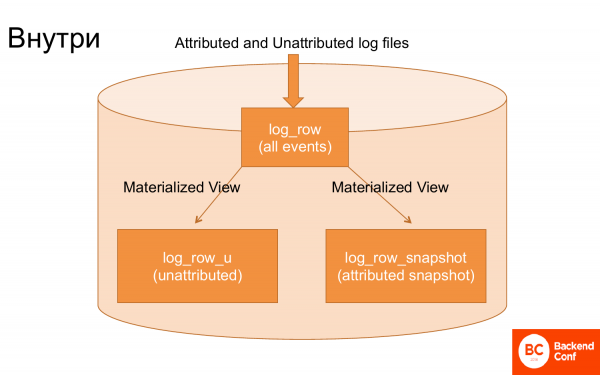
如果你查看 ClickHouse 內部,你會發現只有 3 個主表可以處理所有這些內容。
第一個上傳日誌的表,日誌其實沒有經過任何處理就上傳了。
第二張桌子。透過物化視圖,從這些日誌中提取尚未歸因的事件,即不相關的事件。並透過物化視圖從這些日誌中提取交易來建立快照。即建立一個特殊的物化視圖快照,即事務的最後累積狀態。
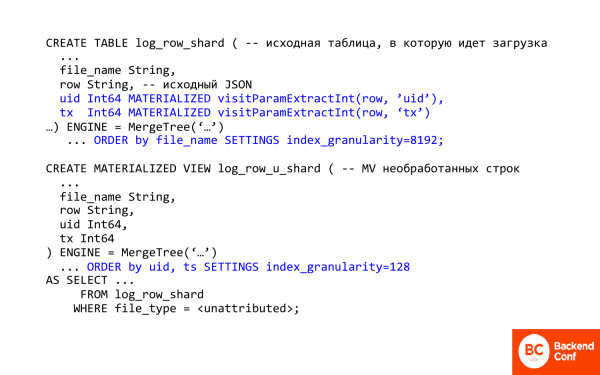
這是用 SQL 編寫的文字。我想對其中的幾個重要的事情進行評論。
首先重要的是在 ClickHouse 中從 json 中提取列和字段的能力。也就是說ClickHouse有一些處理json的方法。它們非常非常原始。
visitParamExtractInt 可讓您從 json 中提取屬性,即第一次命中有效。透過這種方式,您可以提取交易 ID 或存取 ID。這是一個。
其次,這裡巧妙地運用了物化場。這是什麼意思?這意味著您不能將其插入表中,即它沒有插入,而是在插入時計算並儲存。當您貼上時,ClickHouse 會為您完成工作。並且您稍後需要的內容已經從 json 中提取出來了。
在這種情況下,物化視圖用於原始行。並且使用第一個包含實際原始日誌的表。它起什麼作用?首先,它改變了排序,即現在按訪問 ID 排序,因為我們需要快速提取特定人的交易。
第二個重要的事情是index_granularity。如果您見過 MergeTree,那麼 index_granularity 的預設值通常為 8。這是什麼?這是索引稀疏性參數。在 ClickHouse 中,索引是稀疏的,它永遠不會索引每筆記錄。每 192 次就會發生一次此情況。當有大量資料需要計算時,這種方法很好,但當只有少量資料時,這種方法就不好了,因為開銷太大。如果我們降低索引粒度,那麼我們就可以減少開銷。將其減少到一個是不可能的,因為可能沒有足夠的記憶體。索引始終儲存在記憶體中。

快照也使用了一些其他有趣的 ClickHouse 功能。
首先是AggregatingMergeTree。並且在 AggregatingMergeTree 中儲存了 argMax,即與最新時間戳對應的交易狀態。不斷為該訪客產生新的交易。在這個交易的最後狀態,我們新增了一個事件並得到了一個新的狀態。它回到了 ClickHouse。並且透過這個物化視圖中的argMax我們隨時可以獲得當前狀態。

- 綁定與運行時分離。
- 每月儲存和處理多達 3 億筆交易。這比 Cassandra(即典型的交易系統)高出一個數量級。
- 2x5 ClickHouse 伺服器叢集。 5 台伺服器,每台伺服器都有一個副本。這甚至比 Cassandra 中進行基於點擊的歸因還要少,而這裡我們是基於印象的。也就是說,伺服器數量不是增加30倍,而是減少了XNUMX倍。

最後一個例子是金融公司Y,該公司分析了股票價格變動的相關性。
任務如下:
- 大約有5股。
- 每 100 毫秒公佈一次報價。
- 這些數據已經累積了10多年。顯然,對某些公司來說,這個數字較多,而對某些公司來說,這個數字則較少。
- 總共有大約100億條線。
並且需要計算變化的相關性。
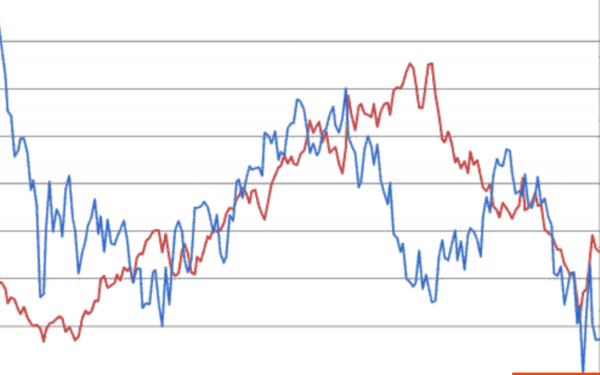
這裡有兩隻股票及其報價。如果一個上漲,另一個也上漲,那麼這就是正相關,也就是一個成長,另一個也成長。如果一個上漲(如圖的末尾所示),而另一個下跌,那麼這就是負相關,即當一個上漲時,另一個下跌。
透過分析這些相互的變化,人們可以對金融市場做出預測。

但任務十分艱鉅。為此我們做了哪些努力?我們有 100 億筆記錄,其中包含:時間、促銷和價格。我們需要先計算100億次運行與價格演算法的差異。 RunningDifference 是 ClickHouse 中的一個函數,用於依序計算兩行之間的差異。
之後,您需要計算相關性,並且需要為每一對計算相關性。 5股就有000萬對。這是一個很大的數字,需要計算這樣的相關函數 12,5 次。
如果有人忘記了,͞x 和 ͞y 是 mat。樣本期望。也就是說,不僅需要計算根和和,還需要計算這些和中的其他和。需要進行12,5萬次大量的計算,而且還需要按小時分組。我們也有很多手錶。你必須在 60 秒內完成。這是個笑話。

我們必須以某種方式做到這一點,因為在 ClickHouse 出現之前,所有這一切都進展得非常非常緩慢。

他們嘗試在 Hadoop、Spark 和 Greenplum 上進行計算。但這一切都非常緩慢且昂貴。也就是說,雖然可以透過某種方式進行計算,但成本很高。
然後 ClickHouse 出現了,一切都變得好多了。
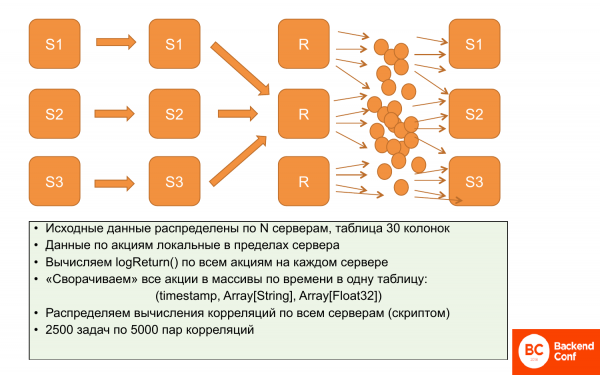
讓我提醒你,我們的問題在於資料的局部性,因此相關性無法局部化。我們不能將一些資料放在一台伺服器上,將一些資料放在另一台伺服器上並進行統計,我們必須將所有資料放在各個地方。
他們做了什麼?最初數據是本地化的。每個伺服器儲存一組特定股票的定價資料。並且它們不相交。因此,可以並行且獨立地計算 logReturn,目前所有這些都是並行且分散式發生的。
接下來,我們決定減少這些數據而不失去其表現力。使用陣列進行減少,即為每個時間間隔建立一個股票數組和一個價格數組。這樣,它佔用的資料空間就少得多。而且使用起來也比較方便。這些幾乎是並行的操作,即我們部分計算,然後並行寫入伺服器。
此後,它就可以被複製。字母“r”表示我們複製了該資料。也就是說,我們在所有三台伺服器上都有相同的數據 - 這些陣列。
然後,使用特殊的腳本,您可以從這組需要計算的 12,5 萬個相關性中建立套件。也就是說,2 個任務有 500 對相關性。而這個任務是在特定的ClickHouse伺服器上進行計算的。他擁有所有數據,因為數據是相同的,他可以按順序計算。
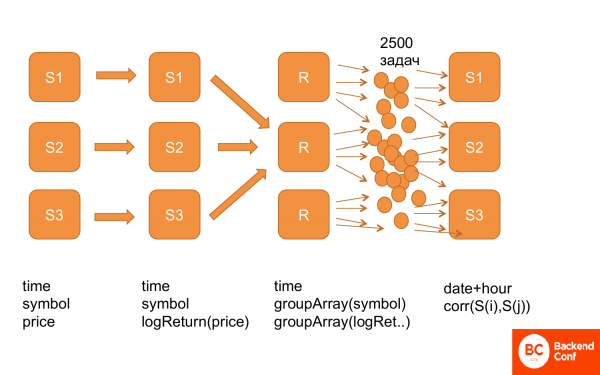
再次,它看起來是這樣的。首先,我們擁有此結構中的所有資料:時間、股票、價格。然後我們計算了 logReturn,也就是相同結構的數據,只不過我們已經有了 logReturn 而不是價格。然後他們重新設計,即我們根據促銷和價格獲得時間和 groupArray。已複製。之後,他們產生了一堆任務並將它們輸入到 ClickHouse 中,以便對其進行計數。並且它有效。

對於概念驗證任務,它是一個子任務,即他們獲取的數據較少。並且僅在三台伺服器上。
前兩個步驟:計算 Log_return 並將其包裝在陣列中,每個步驟大約需要一個小時。
而計算相關性大約需要50個小時。但 50 小時是不夠的,因為之前他們已經工作了數週。這是一個巨大的成功。如果你計算一下,那麼這個集群上的所有事物每秒都會被計算 70 次。
但最重要的是,該系統幾乎沒有瓶頸,即它幾乎可以線性擴展。他們檢查了它。它已成功擴展。

- 正確的計劃是成功的一半。而正確的方案是使用所有必要的ClickHouse技術。
- Summing/AggregatingMergeTrees 是一種允許聚合或將狀態快照視為特例的技術。這使得很多事情變得容易得多。
- 物化視圖允許您繞過一個索引的限制。可能我沒有說清楚,但是我們在載入日誌的時候,原始日誌在一個表裡,有一個索引,屬性日誌在一個表裡,也就是同樣的數據,只是經過了過濾,但是索引完全不同。看起來是相同的數據,但排序不同。如果需要,物化視圖可讓您繞過此 ClickHouse 限制。
- 降低點查詢的索引粒度。
- 並明智地分配數據,盡可能嘗試在伺服器內本地化數據。並儘量確保查詢也盡可能使用本地化。
總結這個簡短的介紹,我們可以說 ClickHouse 現在已經牢牢佔據了商業資料庫和開源資料庫的領域,特別是用於分析。他與這片風景完美契合。而且,它正在慢慢開始取代其他產品,因為有了 ClickHouse,您就不再需要 InfiniDB。如果 Vertika 提供正常的 SQL 支持,那麼它很快就會變得不再必要。享受!

感謝您的報告!非常有趣!有沒有與 Apache Phoenix 比較?
- 不,我沒聽過有人比較。我們和 Yandex 嘗試追蹤 ClickHouse 與不同資料庫的所有比較。因為如果突然發現某個東西比 ClickHouse 更快,那麼 Lesha Milovidov 晚上就睡不著覺,並開始快速加速它。我還沒聽過這樣的比較。
(Alexey Milovidov)Apache Phoenix 是 Hbase 上的 SQL 引擎。 Hbase 主要用於鍵值類型工作流程。每行可以有任意數量的列和任意名稱。對於 Hbase、Cassandra 等系統也可以這麼說。而正是繁重的分析查詢無法在它們上面正常運作。或者,如果您沒有使用過 ClickHouse,您可能會認為它們運作良好。
謝謝
下午好,我對這個主題已經很感興趣了,因為我有一個分析子系統。但當我看 ClickHouse 時,我感覺 ClickHouse 非常適合分析事件、可變。如果我需要用一堆大表來分析大量的業務數據,那麼據我所知,ClickHouse 不是非常適合我嗎?特別是如果它們發生變化的話。這是正確的嗎?或者有例子可以反駁它嗎?
這是對的。對於大多數專業分析資料庫來說,情況都是如此。它們專為存在一個或多個可變的大表和許多緩慢變化的小表的情況而設計。也就是說,ClickHouse 不像 Oracle,您可以將所有內容放入其中並建立一些非常複雜的查詢。為了有效地使用 ClickHouse,您需要以在 ClickHouse 中運作良好的方式建立一個方案。即避免過度規範化,使用字典,盡量少做長連結。而如果按照這樣的方案來構建,那麼類似的業務任務在ClickHouse上解決起來會比在傳統的關係型資料庫上高效很多。
感謝您的報告!我對最新的金融案件有疑問。他們有分析。有必要比較一下它們的上升和下降情況。據我了解,您是專門為這個分析建立了這個系統嗎?例如,如果明天他們需要有關這些數據的其他報告,他們是否需要重建圖表並載入數據?也就是對請求做一些預處理得到?
當然,這是使用 ClickHouse 執行非常具體的任務。它可以在 Hadoop 中以更傳統的方式解決。對 Hadoop 來說,這是一項理想的任務。但在 Hadoop 上它非常慢。我的目標是證明 ClickHouse 可以解決通常透過完全不同的方式解決的問題,但同時,它可以更有效率地完成。這是針對特定任務而客製化的。顯然,如果存在類似的問題,那麼就可以用類似的方法解決。
天氣晴朗。您說這需要 50 個小時來處理。這是從一開始,當您加載數據或獲得結果時嗎?
是的是的。
好的,非常感謝。
這是一個由 3 個伺服器組成的叢集。
問候!感謝您的報告!一切都非常有趣。我不會問功能性,而是從穩定性的角度來問使用ClickHouse。也就是說,您是否遇到任何問題,是否必須恢復它們?在這種情況下 ClickHouse 的表現如何?您的台詞是否也曾被漏掉過?例如,我們在使用 ClickHouse 時遇到了一個問題,它仍然超出了限制並崩潰了。
當然,不存在理想的系統。而 ClickHouse 也有自己的問題。但你聽過 Yandex.Metrica 長期無法運作嗎?可能不是。自 2012-2013 年以來,它一直在 ClickHouse 上可靠地運行。我也可以對我的經驗說同樣的話。我們從未遭遇過徹底的失敗。可能會發生一些小事,但它們並不會嚴重到對業務造成嚴重影響。這種事以前從來沒有發生過。 ClickHouse 非常可靠,不會隨機崩潰。沒有必要擔心這一點。這不是一件原始的事情。這一點已經被很多公司證實。
你好!你說你需要馬上好好考慮一下數據方案。如果發生這種情況怎麼辦?我的資料正在源源不絕地湧入。六個月過去了,我明白我不能再這樣生活了,我需要重新上傳資料並用它做點什麼。
當然,這取決於您的系統。有幾種方法可以實現這一點,而且幾乎不需要停機。例如,您可以建立一個物化視圖,如果可以明確地映射,則可以在其中建立不同的資料結構。也就是說,如果它允許使用 ClickHouse 進行映射,即提取一些東西,更改主鍵,更改分區,那麼您就可以建立一個物化視圖。您的舊資料將被重寫在那裡,新資料將自動寫入。然後只需切換到使用物化視圖,然後切換記錄並刪除舊表。這是一個根本不停歇的方法。
謝謝。
來源: www.habr.com
