


我們在項目中使用微服務架構。 當出現性能瓶頸時,大量時間花費在監控和解析日誌上。 當將各個操作的計時記錄到日誌文件時,通常很難理解是什麼導致了這些操作的調用,也很難跟踪操作的順序或不同服務中一個操作相對於另一個操作的時間偏移。
為了最大限度地減少體力勞動,我們決定使用其中一種跟踪工具。 關於如何以及為什麼可以使用跟踪以及我們是如何做到的,將在本文中討論。
溯源可以解決哪些問題
- 查找單個服務內以及所有參與服務之間的整個執行樹中的性能瓶頸。 例如:
- 服務之間的許多短的連續調用,例如地理編碼或數據庫。
- 長時間 I/O 等待,例如網絡傳輸或磁盤讀取。
- 長數據解析。
- 需要CPU的長時間操作。
- 獲得最終結果不需要的代碼部分可以被刪除或延遲。
- 清楚地了解按什麼順序調用什麼以及執行操作時會發生什麼。

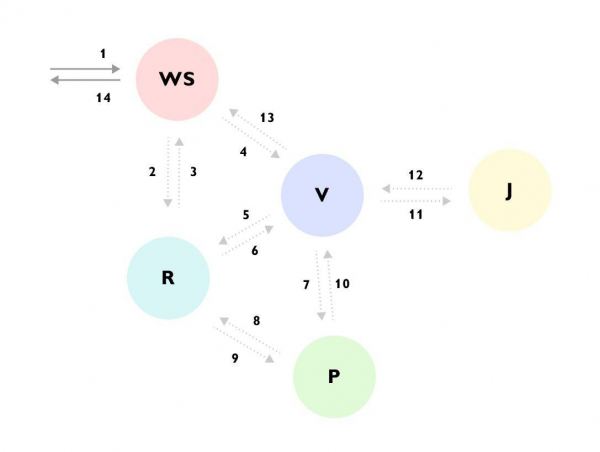
可以看到,比如Request來到WS服務->WS服務通過R服務補充數據->然後向V服務發送請求->V服務從R服務加載了很多數據R 服務-> 轉到P 服務-> P 服務再次轉到服務R -> 服務V 忽略結果並轉到服務J -> 然後才將響應返回到服務WS,同時繼續計算其他內容的背景。
如果沒有整個過程的跟踪或詳細文檔,第一次查看代碼時很難理解發生了什麼,並且代碼分散在不同的服務中並隱藏在一堆 bin 和接口後面。 - 收集有關執行樹的信息以供後續延遲分析。 在執行的每個階段,您可以將信息添加到該階段可用的跟踪中,然後找出哪些輸入數據導致了類似的場景。 例如:
- 用戶身份
- 權利
- 所選方法的類型
- 日誌或執行錯誤
- 將跟踪轉換為指標的子集,並以指標的形式進行進一步分析。
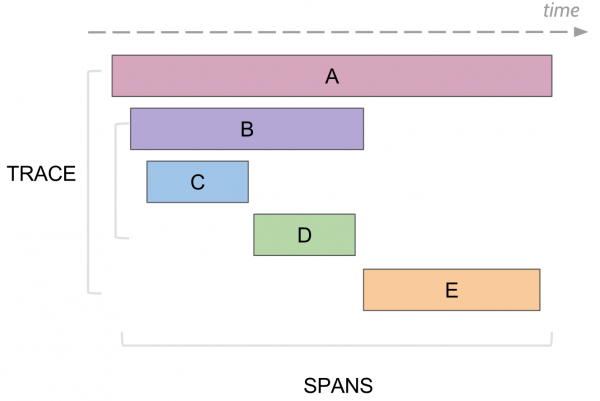
可以記錄什麼痕跡。 跨度
在跟踪中存在跨度的概念,這類似於控制台的一個日誌。 水療中心擁有:
- 名稱,通常是執行的方法的名稱
- 生成跨度的服務的名稱
- 擁有唯一的ID
- 某種元信息,其形式為已登錄的鍵/值。 例如,方法參數或方法是否以錯誤結束
- 此跨度的開始和結束時間
- 父跨度 ID
每個跨度都會被發送到跨度收集器,以存儲在數據庫中,以便在執行完成後立即進行查看。 將來,您可以通過parent id連接來構建所有span的樹。 例如,在分析時,您可以找到某個服務中花費超過一段時間的所有跨度。 此外,通過轉到特定跨度,可以查看該跨度上方和下方的整個樹。
Opentrace、Jagger 以及我們如何在項目中實施它
有一個共同的標準 ,它描述了應該如何收集以及收集什麼內容,而不會被跟踪到任何語言的特定實現所束縛。 例如,在 Java 中,所有跟踪工作都是通過公共 Opentrace API 進行的,並且在其下,例如 Jaeger 或不執行任何操作的空默認實現可以被隱藏。
我們正在使用 作為 Opentrace 的實現。 它由幾個組件組成:
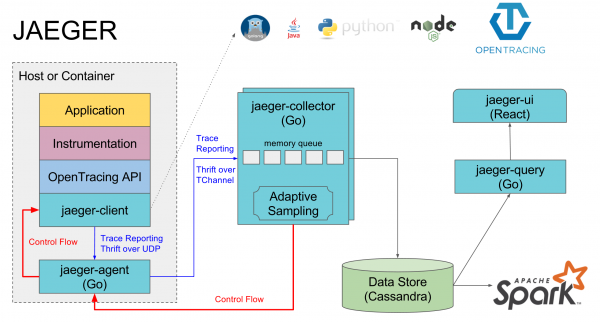
- Jaeger-agent 是一個本地代理,通常安裝在每台機器上,服務通過本地默認端口登錄到它。 如果沒有代理,那麼該機器上所有服務的痕跡通常都會被禁用
- Jaeger-collector - 所有代理將收集的跟踪發送給它,並將它們放入選定的數據庫中
- 數據庫是他們首選的 cassandra,但我們使用 Elasticsearch,還有一些其他數據庫的實現以及不將任何內容保存到磁盤的內存中實現
- Jaeger-query 是一項訪問數據庫並返回已收集的跟踪以供分析的服務
- Jaeger-ui 是一個用於搜索和查看痕蹟的 Web 界面,它轉到 jaeger-query
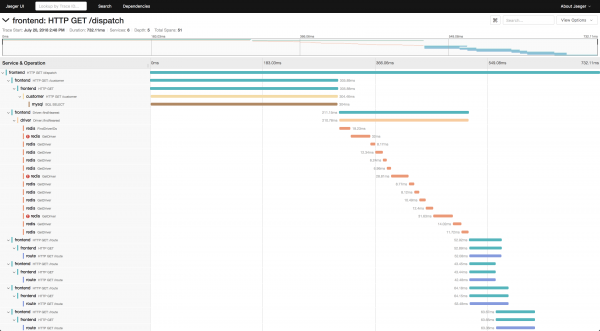
一個單獨的組件可以稱為opentrace jaeger針對特定語言的實現,通過它將span發送到jaeger-agent。
歸根結底是實現 io.opentracing.Tracer 接口,之後通過它的所有跟踪都將飛向真正的代理。
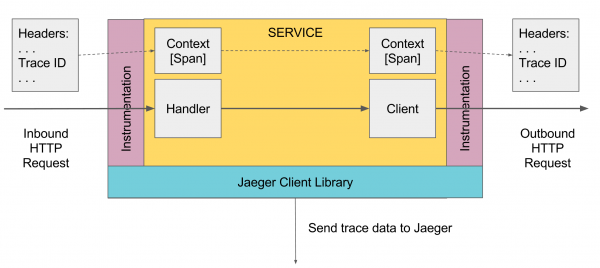
同樣對於彈簧組件,您可以連接 以及 Jaeger 的實施 它將自動配置對通過這些組件的所有內容的跟踪,例如對控制器的 http 請求、通過 jdbc 對數據庫的請求等。
跟踪 Java 中的日誌記錄
在頂層的某個地方,必須創建第一個 Span,這可以自動完成,例如,在收到請求時由 spring 控制器完成,或者如果沒有請求則手動完成。 然後通過下面的範圍進行傳輸。 如果下面的任何方法想要添加一個 Span,它會從 Scope 中獲取當前的 activeSpan,創建一個新的 Span 並表示其父級是生成的 activeSpan,並使新的 Span 處於活動狀態。 當調用外部服務時,當前活動的跨度被傳遞給它們,並且這些服務參考這個跨度創建新的跨度。
所有工作都經過Tracer實例,可以通過DI機制獲取,如果DI機制不起作用的話,也可以將GlobalTracer.get()作為全局變量。 默認情況下,如果跟踪器尚未初始化,NoopTracer 將返回,但不執行任何操作。
進一步,通過 ScopeManager 從跟踪器中獲取當前作用域,從當前作用域創建一個新作用域並綁定新的作用域,然後關閉創建的作用域,即關閉創建的作用域並返回之前的作用域活躍狀態。 Scope 是綁定在一個線程上的,所以在多線程編程時,一定不要忘記將活動的 Span 轉移到另一個線程,以便參考這個 Span 進一步激活另一個線程的 Scope。
io.opentracing.Tracer tracer = ...; // GlobalTracer.get()
void DoSmth () {
try (Scope scope = tracer.buildSpan("DoSmth").startActive(true)) {
...
}
}
void DoOther () {
Span span = tracer.buildSpan("someWork").start();
try (Scope scope = tracer.scopeManager().activate(span, false)) {
// Do things.
} catch(Exception ex) {
Tags.ERROR.set(span, true);
span.log(Map.of(Fields.EVENT, "error", Fields.ERROR_OBJECT, ex, Fields.MESSAGE, ex.getMessage()));
} finally {
span.finish();
}
}
void DoAsync () {
try (Scope scope = tracer.buildSpan("ServiceHandlerSpan").startActive(false)) {
...
final Span span = scope.span();
doAsyncWork(() -> {
// STEP 2 ABOVE: reactivate the Span in the callback, passing true to
// startActive() if/when the Span must be finished.
try (Scope scope = tracer.scopeManager().activate(span, false)) {
...
}
});
}
}對於多線程編程,還有TracedExecutorService和類似的包裝器,它們在異步任務啟動時自動將當前span轉發到線程:
private ExecutorService executor = new TracedExecutorService(
Executors.newFixedThreadPool(10), GlobalTracer.get()
);對於外部http請求有
HttpClient httpClient = new TracingHttpClientBuilder().build();我們面臨的問題
- 如果跟踪器未在服務或組件中使用,則 Bean 和 DI 並不總是有效,那麼 Tracer 可能無法工作,您必須使用 GlobalTracer.get()。
- 如果註釋不是組件或服務,或者從同一類的相鄰方法調用該方法,則註釋不起作用。 您必須小心檢查哪些有效,如果 @Traced 不起作用,請使用手動跟踪創建。 您還可以為 java 註釋附加一個額外的編譯器,那麼它們應該可以在任何地方工作。
- 在舊的spring和spring boot中,由於DI中的bug,opentraing spring cloud自動配置不起作用,那麼如果你想讓spring組件中的trace自動工作,你可以類推
- Try with resources 在groovy 中不起作用,您必須使用try finally。
- 每個服務必須有自己的 spring.application.name,跟踪記錄將在該名稱下記錄。 銷售和測試有什麼不同的名稱,以免它們放在一起造成乾擾。
- 如果您使用 GlobalTracer 和 tomcat,那麼在該 tomcat 中運行的所有服務都有一個 GlobalTracer,因此它們都將具有相同的服務名稱。
- 向方法添加跟踪時,需要確保不會在循環中多次調用該方法。 有必要為所有調用添加一個公共跟踪,這保證了總的工作時間。 否則,將會產生過大的負載。
- 有一次在 jaeger-ui 中,對大量跟踪發出了過大的請求,由於沒有等待響應,所以又做了一次。 結果,jaeger-query開始吃掉大量內存並減慢彈性。 通過重新啟動 jaeger-query 來幫助
採樣、存儲和查看痕跡
共有三種類型 :
- Const 發送並保存所有跟踪。
- 概率性,以給定的概率過濾痕跡。
- 速率限制限制每秒的跟踪數。 您可以在客戶端、jaeger-agent 或收集器上配置這些設置。 現在我們在賦值器堆棧中使用 const 1,因為請求不是很多,但需要很長時間。 將來,如果這會對系統造成過大的負載,您可以對其進行限制。
如果您使用 cassandra,那麼默認情況下它僅存儲兩天的痕跡。 我們正在使用 並且痕跡會一直保存,不會被刪除。 每天都會創建一個單獨的索引,例如 jaeger-service-2019-03-04。 以後需要配置自動清理舊痕跡。
為了查看您需要的痕跡:
- 選擇要用來過濾跟踪的服務,例如,tomcat7-default 表示在 tomcat 中運行且不能有自己的名稱的服務。
- 然後選擇操作、時間間隔和最短操作時間,例如從 10 秒開始,以便只執行長時間執行。

- 走到其中一條痕跡處,看看那裡有什麼東西在減速。

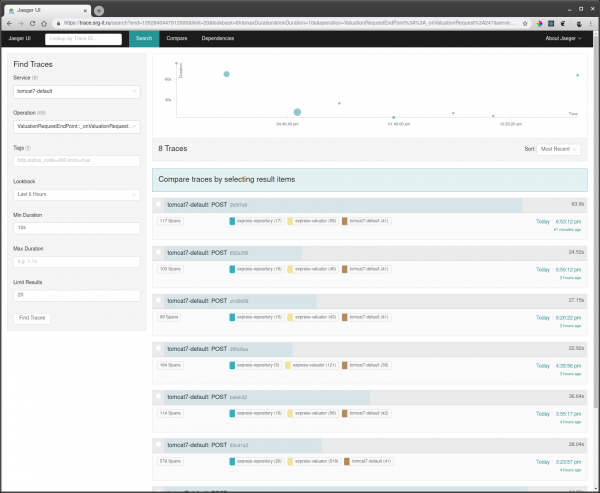
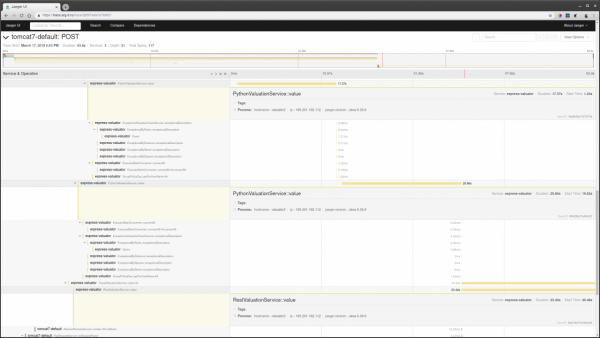
另外,如果某個請求 id 已知,那麼您可以通過標籤搜索找到該 id 的跟踪(如果該 id 記錄在跟踪範圍中)。
Документация
- 開放跟踪文檔
- 傑格文檔
- Jaeger java 連接
- spring 打開跟踪連接
用品
- 真實 PHP 和 Golang 項目中的 Jaeger Opentracing 和微服務
- Uber Engineering 不斷發展的分佈式追踪
- 在裸機上運行 Jaeger Agent
視頻
- 我們如何使用 Jaeger 和 Prometheus 提供閃電般快速的用戶查詢 — Bryan Boreham
- 簡介:Jaeger - Yuri Shkuro、Uber 和 Pavol Loffay、紅帽
- Serghei Iakovlev,“大勝利的小故事:OpenTracing、AWS 和 Jaeger”
來源: www.habr.com
