

你好,我正在為 DBMS 建立應用程式 是Mail.ru Group開發的一個平台,結合了高效能DBMS和Lua語言的應用伺服器。 基於 Tarantool 的解決方案之所以能夠實現高速,尤其是因為它支援 DBMS 的記憶體模式,並且能夠在單一位址空間中使用資料執行應用程式業務邏輯。 同時,使用ACID事務保證資料持久性(在磁碟上維護WAL日誌)。 Tarantool 內建了對複製和分片的支援。 從2.1版本開始,支援SQL語言查詢。 Tarantool 是開源的,並根據 Simplified BSD 許可證獲得許可。 還有一個商業企業版。

感受到力量! (……又名享受表演)
所有上述因素使 Tarantool 成為創建與資料庫一起使用的高負載應用程式的有吸引力的平台。 在此類應用中,經常需要資料複製。
如上所述,Tarantool 具有內建的資料複製功能。 其操作原理是在副本上順序執行主日誌(WAL)中包含的所有交易。 通常這樣的複製(我們進一步稱之為 低級)用於確保應用程式容錯和/或在叢集節點之間分配讀取負載。
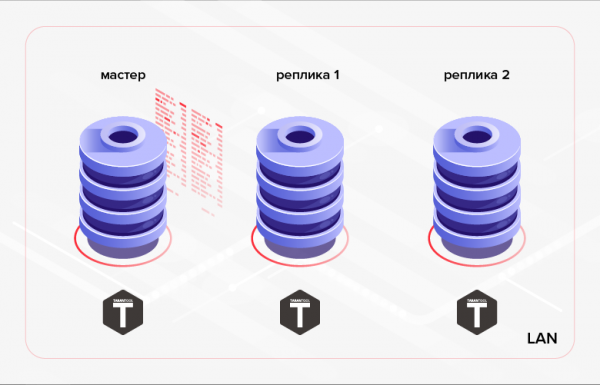
米。 1. 集群內複製
另一個場景的範例是將一個資料庫中建立的資料傳輸到另一個資料庫進行處理/監控。 在後一種情況下,更方便的解決方案可能是使用 高水準 複製 - 應用程式業務邏輯層級的資料複製。 那些。 我們不使用 DBMS 中內建的現成解決方案,而是在我們正在開發的應用程式中自行實現複製。 這種方法既有優點也有缺點。 讓我們列出優點。
1、節省流量:
- 您不能傳輸全部數據,而只能傳輸部分數據(例如,您可以只傳輸某些表、其中的某些列或滿足特定條件的記錄);
- 與以非同步(在當前版本的 Tarantool - 1.10 中實現)或同步(在後續版本的 Tarantool 中實現)模式連續執行的低階複製不同,高級複製可以在會話中執行(即,應用程式首先同步資料- 交換會話數據,然後複製暫停,之後發生下一個交換會話,等等);
- 如果記錄已更改多次,則只能傳輸其最新版本(與低階複製不同,在低階複製中,在主伺服器上所做的所有變更都將在副本上按順序回放)。
2. 實作HTTP交換沒有任何困難,它允許您同步遠端資料庫。
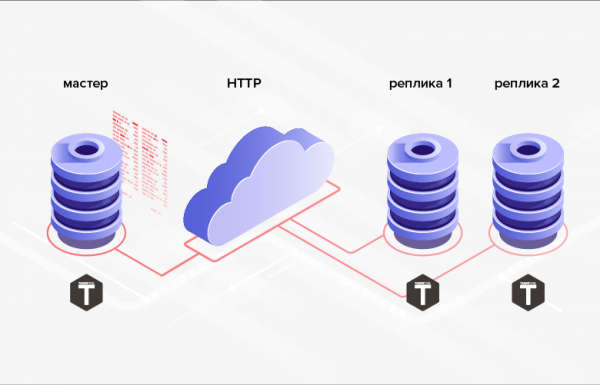
米。 2. 透過 HTTP 複製
3. 資料傳輸的資料庫結構不必相同(而且,一般情況下,甚至可以使用不同的DBMS、程式語言、平台等)。
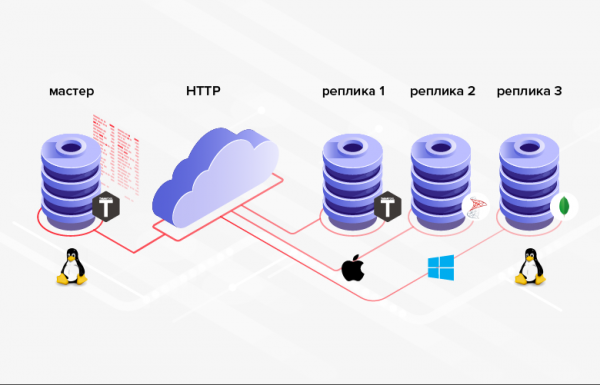
米。 3. 異構系統中的複製
缺點是,平均而言,程式設計比配置更困難/成本更高,而且您必須實現自己的功能,而不是自訂內建功能。
如果在您的情況下,上述優點至關重要(或必要條件),那麼使用進階複製就很有意義。 讓我們來看看在 Tarantool DBMS 中實作高階資料複製的幾種方法。
流量最小化
因此,高級複製的優點之一是節省流量。 為了充分發揮這一優勢,有必要最大限度地減少每次交換會話期間傳輸的資料量。 當然,我們不應該忘記,在會話結束時,資料接收方必須與來源同步(至少對於複製涉及的那部分資料)。
如何最大限度地減少進階複製期間傳輸的資料量? 一個簡單的解決方案可能是按日期和時間選擇資料。 為此,您可以使用表格中已存在的日期時間欄位(如果存在)。 例如,「訂單」文件可能有一個欄位「所需的訂單執行時間」 - delivery_time。 此解決方案的問題在於該欄位中的值不必按照訂單建立的順序排列。 所以我們記不住最大欄位值 delivery_time,在上一個交換會話期間傳輸,並在下一個交換會話期間選擇具有較高欄位值的所有記錄 delivery_time。 交換會話之間可能新增了欄位值較低的記錄 delivery_time。 此外,順序可能會發生變化,但這並不影響該領域 delivery_time。 在這兩種情況下,變更都不會從來源傳輸到目標。 為了解決這些問題,我們需要「重疊」地傳輸資料。 那些。 在每個交換會話中,我們將傳輸帶有欄位值的所有數據 delivery_time,超過過去的某個點(例如,距離當下時刻 N 小時)。 然而,很明顯,對於大型系統來說,這種方法是高度冗餘的,並且可以使我們努力節省的流量化為泡影。 此外,正在傳輸的表可能沒有與日期時間關聯的欄位。
另一種解決方案在實施上更為複雜,是確認資料的接收。 在這種情況下,在每個交換會話期間,傳輸所有數據,但接收方尚未確認其接收。 要實現此目的,您需要在來源表中新增一個布林列(例如, is_transferred)。 如果接收方確認收到記錄,則對應欄位的值為 true,之後該條目不再參與交換。 該實施方案有以下缺點。 首先,對於傳輸的每筆記錄,必須產生並發送確認。 粗略地說,這相當於將傳輸的資料量加倍,並導致往返次數加倍。 其次,不可能將相同的記錄傳送給多個接收者(第一個接收者將為其自己和所有其他接收者確認接收)。
沒有上述缺點的方法是向傳輸表添加一列以追蹤其行中的變更。 這樣的列可以是日期時間類型,並且必須由應用程式在每次新增/更改記錄時(以原子方式新增/變更)將其設定/更新為當前時間。 作為範例,我們將該列稱為 update_time。 透過保存傳輸記錄的該列的最大欄位值,我們可以使用該值開始下一個交換會話(選擇具有該欄位值的記錄 update_time,超過先前儲存的值)。 後一種方法的問題是資料變更可能會批量發生。 由於列中的欄位值 update_time 可能不是唯一的。 因此,該列不能用於分段(逐頁)資料輸出。 要逐頁顯示數據,您將不得不發明額外的機制,這些機制很可能效率非常低(例如,從資料庫中檢索具有該值的所有記錄) update_time 高於給定的記錄並從樣本開頭的某個偏移量開始產生一定數量的記錄)。
您可以透過稍微改進之前的方法來提高資料傳輸的效率。 為此,我們將使用整數類型(長整數)作為列字段值來追蹤變更。 讓我們為該列命名 row_ver。 每次建立/修改記錄時,仍必須設定/更新此列的欄位值。 但在這種情況下,該欄位不會被分配當前日期時間,而是某些計數器的值,增加一。 結果,專欄 row_ver 將包含唯一值,不僅可用於顯示「增量」資料(自上一次交換工作階段結束以來已新增/變更的資料),還可用於簡單有效地將其分解為頁面。
在我看來,最後提出的在高階複製框架內最小化傳輸資料量的方法是最優化和通用的。 讓我們更詳細地看看它。
使用行版本計數器傳遞數據
伺服器/主控部分的實現
在 MS SQL Server 中,有一個特殊的列類型來實作這種方法 - rowversion。 每個資料庫都有一個計數器,每次在具有如下列的表中新增/更改記錄時,該計數器都會增加XNUMX rowversion。 此計數器的值會自動指派給已新增/變更的記錄中該列的欄位。 Tarantool DBMS 沒有類似的內建機制。 不過,在 Tarantool 中手動實現並不困難。 讓我們看看這是如何完成的。
首先,介紹一點名詞:Tarantool 中的表稱為空間,記錄稱為元組。 在 Tarantool 中,您可以建立序列。 序列只不過是有序整數值的命名產生器。 那些。 這正是我們達到目的所需要的。 下面我們將建立這樣一個序列。
在 Tarantool 中執行任何資料庫操作之前,您需要執行以下命令:
box.cfg{}因此,Tarantool 將開始將資料庫快照和交易日誌寫入目前目錄。
讓我們建立一個序列 row_version:
box.schema.sequence.create('row_version',
{ if_not_exists = true })
選項 if_not_exists 允許多次執行建立腳本:如果物件存在,Tarantool 將不會嘗試再次建立它。 此選項將在後續的所有 DDL 命令中使用。
讓我們創建一個空間作為範例。
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
},
{
name = 'row_ver',
type = 'unsigned'
}
},
if_not_exists = true
})
這裡我們設定空間的名稱(goods)、欄位名稱及其類型。
Tarantool 中的自動遞增欄位也是使用序列建立的。 我們來建立一個按字段自增的主鍵 id:
box.schema.sequence.create('goods_id',
{ if_not_exists = true })
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})Tarantool 支援多種類型的索引。 最常用的索引是TREE和HASH類型,它們是基於名稱對應的結構。 TREE 是最通用的索引類型。 它允許您以有組織的方式檢索資料。 但相等選擇,HASH更適合。 因此,建議使用 HASH 作為主鍵(我們就是這樣做的)。
使用色譜柱 row_ver 要傳輸更改的數據,需要將序列值綁定到該列的字段 row_ver。 但與主鍵不同的是,列字段值 row_ver 不僅在新增記錄時應該加一,而且在更改現有記錄時也應該加一。 您可以為此使用觸發器。 Tarantool 有兩種類型的空間觸發器: before_replace и on_replace。 每當空間中的資料發生變化時就會觸發觸發器(對於受變化影響的每個元組,都會啟動一個觸發器函數)。 不像 on_replace, before_replace-triggers 允許您修改執行觸發器的元組的資料。 因此,最後一種類型的觸發器適合我們。
box.space.goods:before_replace(function(old, new)
return box.tuple.new({new[1], new[2], new[3],
box.sequence.row_version:next()})
end)
以下觸發器替換欄位值 row_ver 儲存元組到序列的下一個值 row_version.
為了能夠從太空中提取數據 goods 按列 row_ver,讓我們建立一個索引:
box.space.goods:create_index('row_ver', {
parts = { 'row_ver' },
unique = true,
type = 'TREE',
if_not_exists = true
})
索引類型-樹(TREE), 因為我們需要按列中值的升序提取數據 row_ver.
讓我們為空間添加一些數據:
box.space.goods:insert{nil, 'pen', 123}
box.space.goods:insert{nil, 'pencil', 321}
box.space.goods:insert{nil, 'brush', 100}
box.space.goods:insert{nil, 'watercolour', 456}
box.space.goods:insert{nil, 'album', 101}
box.space.goods:insert{nil, 'notebook', 800}
box.space.goods:insert{nil, 'rubber', 531}
box.space.goods:insert{nil, 'ruler', 135}
因為第一個欄位是一個自動遞增計數器;我們傳遞 nil 來代替。 Tarantool 將自動替換下一個值。 同樣,作為列字段的值 row_ver 您可以傳遞 nil - 或根本不指定該值,因為此列佔據空間的最後一個位置。
我們來檢查一下插入結果:
tarantool> box.space.goods:select()
---
- - [1, 'pen', 123, 1]
- [2, 'pencil', 321, 2]
- [3, 'brush', 100, 3]
- [4, 'watercolour', 456, 4]
- [5, 'album', 101, 5]
- [6, 'notebook', 800, 6]
- [7, 'rubber', 531, 7]
- [8, 'ruler', 135, 8]
...
如您所見,第一個和最後一個欄位會自動填入。 現在寫一個逐頁上傳空間變化的函數就很容易了 goods:
local page_size = 5
local function get_goods(row_ver)
local index = box.space.goods.index.row_ver
local goods = {}
local counter = 0
for _, tuple in index:pairs(row_ver, {
iterator = 'GT' }) do
local obj = tuple:tomap({ names_only = true })
table.insert(goods, obj)
counter = counter + 1
if counter >= page_size then
break
end
end
return goods
end
該函數將值作為參數 row_ver,從這裡開始需要卸載更改,並返回更改的資料的一部分。
Tarantool 中的資料採樣是透過索引完成的。 功能 get_goods 按索引使用迭代器 row_ver 接收更改的資料。 迭代器類型為GT(Greater Than,大於)。 這意味著迭代器將從傳入的鍵(欄位值)開始順序遍歷索引值 row_ver).
迭代器返回元組。 為了後續能夠透過HTTP傳輸數據,需要將元組轉換為方便後續序列化的結構。 此範例使用標準函數來實現此目的 tomap。 而不是使用 tomap 你可以編寫自己的函數。 例如,我們可能想要重命名一個字段 name,不要通過該字段 code 並添加一個字段 comment:
local function unflatten_goods(tuple)
local obj = {}
obj.id = tuple.id
obj.goods_name = tuple.name
obj.comment = 'some comment'
obj.row_ver = tuple.row_ver
return obj
end
輸出資料的頁大小(一部分的記錄數)由變數決定 page_size。 範例中的值 page_size 是 5。在實際程序中,頁面大小通常更重要。 這取決於空間元組的平均大小。 最佳頁面大小可以透過測量資料傳輸時間來憑經驗確定。 頁大小越大,發送端和接收端之間的往返次數越少。 這樣您就可以減少下載變更的總時間。 但是,如果頁面大小太大,我們將在伺服器序列化樣本上花費太長時間。 因此,處理傳入伺服器的其他請求可能會出現延遲。 範圍 page_size 可以從設定檔加載。 對於每個傳輸的空間,您可以設定自己的值。 但是,對於大多數空間,預設值(例如 100)可能是合適的。
讓我們執行該函數 get_goods:
tarantool> get_goods(0)
---
- - row_ver: 1
code: 123
name: pen
id: 1
- row_ver: 2
code: 321
name: pencil
id: 2
- row_ver: 3
code: 100
name: brush
id: 3
- row_ver: 4
code: 456
name: watercolour
id: 4
- row_ver: 5
code: 101
name: album
id: 5
...
我們取字段值 row_ver 從最後一行開始並再次呼叫函數:
tarantool> get_goods(5)
---
- - row_ver: 6
code: 800
name: notebook
id: 6
- row_ver: 7
code: 531
name: rubber
id: 7
- row_ver: 8
code: 135
name: ruler
id: 8
...再次:
tarantool> get_goods(8)
---
- []
...
可以看到,這樣使用時,函數會逐頁傳回所有空間記錄 goods。 最後一頁後面是一個空白選擇。
讓我們對空間進行更改:
box.space.goods:update(4, {{'=', 6, 'copybook'}})
box.space.goods:insert{nil, 'clip', 234}
box.space.goods:insert{nil, 'folder', 432}
我們改變了欄位值 name 一個條目並新增了兩個新條目。
讓我們重複最後一個函數呼叫:
tarantool> get_goods(8)
---
- - row_ver: 9
code: 800
name: copybook
id: 6
- row_ver: 10
code: 234
name: clip
id: 9
- row_ver: 11
code: 432
name: folder
id: 10
...
此函數傳回更改和新增的記錄。 所以函數 get_goods 允許您接收自上次呼叫以來已更改的數據,這是正在考慮的複製方法的基礎。
我們將透過 HTTP 以 JSON 形式發布結果超出了本文的範圍。 您可以在這裡閱讀相關內容:
客戶端/從機部分的實現
讓我們看看接收方的實作是什麼樣的。 我們在接收端創建一個空間來儲存下載的資料:
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
}
},
if_not_exists = true
})
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})
此空間的結構類似於來源中的空間結構。 但由於我們不會將接收到的資料傳遞到其他地方,因此該列 row_ver 不在收件者的空間中。 現場 id 來源標識符將被記錄。 因此,在接收方無需使其自動遞增。
另外,我們需要一個空間來保存數值 row_ver:
box.schema.space.create('row_ver', {
format = {
{
name = 'space_name',
type = 'string'
},
{
name = 'value',
type = 'string'
}
},
if_not_exists = true
})
box.space.row_ver:create_index('primary', {
parts = { 'space_name' },
unique = true,
type = 'HASH',
if_not_exists = true
})
對於每個加載的空間(字段 space_name)我們將在這裡保存最後載入的值 row_ver (場地 value)。 該列充當主鍵 space_name.
讓我們創建一個函數來載入空間數據 goods 透過 HTTP。 為此,我們需要一個實作 HTTP 客戶端的函式庫。 以下行載入庫並實例化 HTTP 客戶端:
local http_client = require('http.client').new()我們還需要一個用於json反序列化的函式庫:
local json = require('json')這足以創建一個資料載入函數:
local function load_data(url, row_ver)
local url = ('%s?rowVer=%s'):format(url,
tostring(row_ver))
local body = nil
local data = http_client:request('GET', url, body, {
keepalive_idle = 1,
keepalive_interval = 1
})
return json.decode(data.body)
end
此函數對url位址執行HTTP請求並傳送 row_ver 作為參數並傳回請求的反序列化結果。
保存接收到的資料的函數如下所示:
local function save_goods(goods)
local n = #goods
box.atomic(function()
for i = 1, n do
local obj = goods[i]
box.space.goods:put(
obj.id, obj.name, obj.code)
end
end)
end
將資料保存到空間的循環 goods 放置在交易中(該函數用於此 box.atomic)以減少磁碟操作的次數。
最後是本地空間同步功能 goods 有了來源,你可以像這樣實現它:
local function sync_goods()
local tuple = box.space.row_ver:get('goods')
local row_ver = tuple and tuple.value or 0
—— set your url here:
local url = 'http://127.0.0.1:81/test/goods/list'
while true do
local goods = load_goods(url, row_ver)
local count = #goods
if count == 0 then
return
end
save_goods(goods)
row_ver = goods[count].rowVer
box.space.row_ver:put({'goods', row_ver})
end
end
首先我們讀取之前保存的值 row_ver 對於空間 goods。 如果缺少(第一次交換會話),那麼我們將其視為 row_ver 零。 接下來,在循環中,我們從指定 url 的來源中逐頁下載已更改的資料。 在每次迭代中,我們將接收到的資料保存到適當的局部空間並更新值 row_ver (在太空 row_ver 並在變數中 row_ver) - 取值 row_ver 從載入資料的最後一行開始。
為了防止意外循環(程式中出現錯誤),循環 while 可以替換為 for:
for _ = 1, max_req do ...
執行該函數的結果 sync_goods 空間 goods 接收器將包含所有空間記錄的最新版本 goods 在源中。
顯然,資料刪除不能透過這種方式進行廣播。 如果有這樣的需要,可以使用刪除標記。 添加到空間 goods 布林字段 is_deleted 我們不使用實體刪除記錄,而是使用邏輯刪除 - 我們設定欄位值 is_deleted 進入意義 true。 有時代替布林字段 is_deleted 使用現場更方便 deleted,它儲存記錄邏輯刪除的日期時間。 執行邏輯刪除後,標記為刪除的記錄將從來源傳輸到目的地(根據上面討論的邏輯)。
序列 row_ver 可用於從其他空間傳輸資料:無需為每個傳輸空間建立單獨的序列。
我們研究了使用 Tarantool DBMS 在應用程式中進行高階資料複製的有效方法。
發現
- Tarantool DBMS 是一款極具吸引力、前景看好的產品,可用於創建高負載應用程式。
- 與低階複製相比,進階資料複製具有許多優點。
- 本文中討論的高級複製方法允許您僅傳輸自上次交換會話以來已更改的記錄,從而最大限度地減少傳輸的資料量。
來源: www.habr.com
