

В 我們討論了時間序列預測。合乎邏輯的延續將是一篇關於識別異常的文章。
應用
異常檢測用於以下領域:
1)設備故障預測
因此,2010年,伊朗離心機遭到震網病毒的攻擊,導致設備運作模式非最優,加速磨損,造成部分設備無法使用。
如果設備使用了異常檢測演算法,就可以避免故障狀況。

尋找設備運作中的異常不僅用於核工業,還用於冶金和飛機渦輪機的運作。在其他領域,使用預測診斷比發生不可預測的故障時可能造成的損失更便宜。
2)詐欺活動的預測
如果您從在阿爾巴尼亞波多利斯克使用的卡片中提取資金,則交易可能需要額外的驗證。
3)識別異常消費模式
如果您的某些客戶表現出異常行為,則可能存在您尚未意識到的問題。
4)異常需求和負載的識別
如果快速消費品商店的銷售額低於預測置信區間,則值得找出發生這種情況的原因。
檢測異常的方法
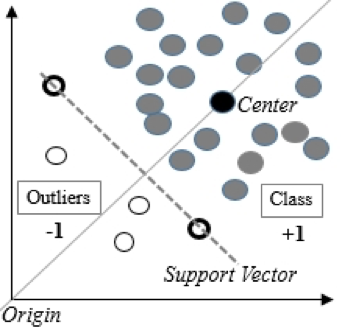
1)單類SVM
當訓練集資料遵循常態分佈,而測試集包含異常時適用。
一類支援向量機圍繞原點建構非線性曲面。可以為被視為異常的資料設定截止值。
根據我們DATA4團隊的經驗,One-Class SVM是解決異常檢測問題最常用的演算法。
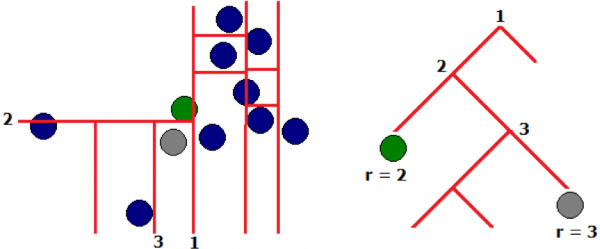
2)隔離森林法
採用「隨機」方法建構樹,排放將在早期階段(樹的較淺深度)落入葉子中,即排放更容易「隔離」。異常值的選擇發生在演算法的第一次迭代期間。
3)橢圓包絡與統計方法
當資料呈常態分佈時使用。測量值越接近混合分佈的尾部,數值就越異常。
其他統計方法也可以包含在此類中。
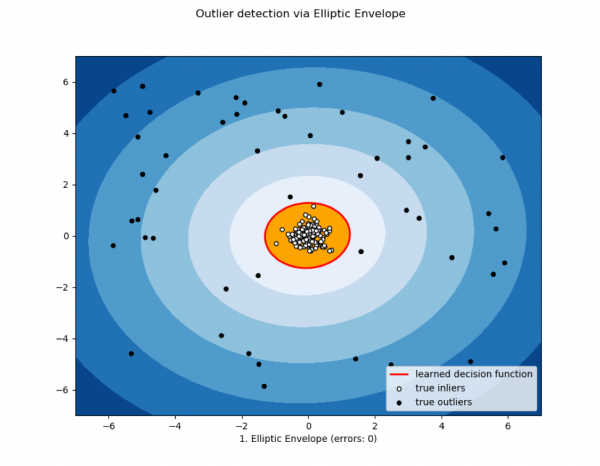
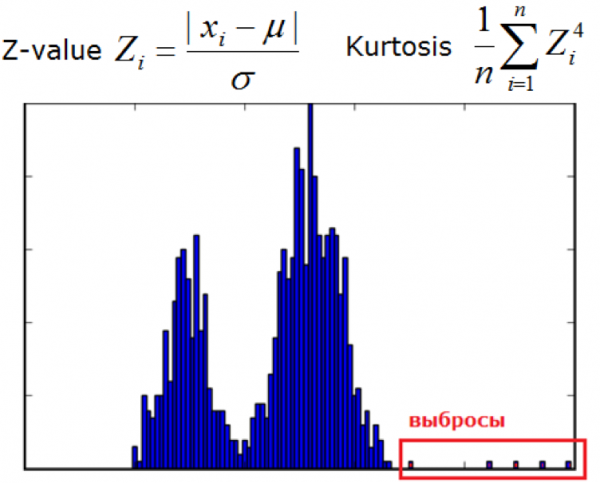
圖片來自dyakonov.org
4)度量方法
這些方法包括 k 最近鄰、k-th 最近鄰、ABOD(基於角度的異常值檢測)或 LOF(局部異常值因子)等演算法。
如果特徵中的值之間的距離相等或標準化(以便不會測量鸚鵡中的蟒蛇),則適用。
k-最近鄰演算法假設正常值位於多維空間的某個區域內,到異常的距離將大於到分離超平面的距離。
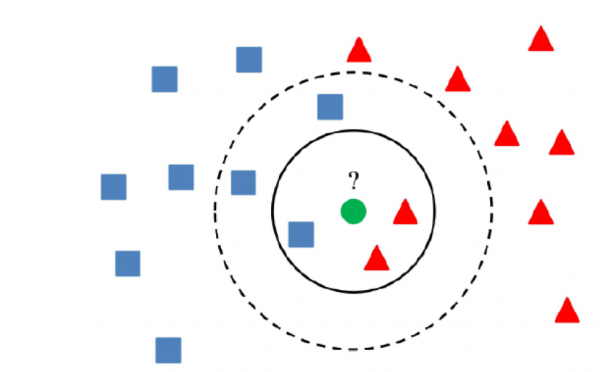
5)聚類方法
聚類方法的本質是,如果一個值與聚類中心的距離超過某一值,則可以認為該值是異常的。
最主要的是使用一種能夠正確聚類資料的演算法,這取決於特定的任務。
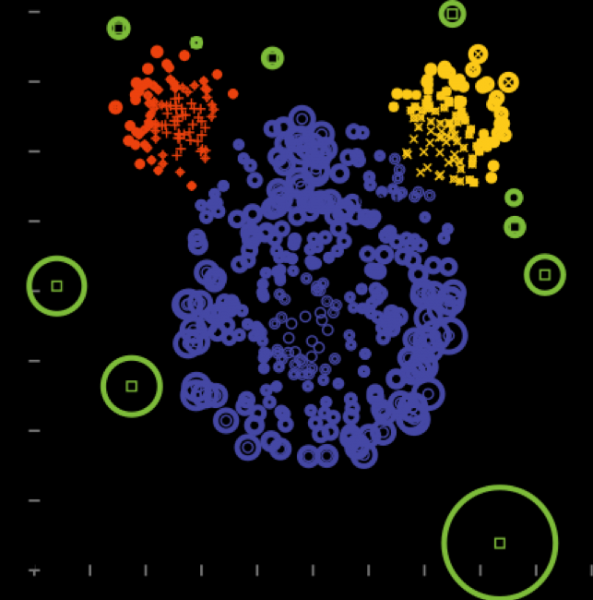
6)主成分方法
適用於區分色散變化最大的方向。
7)基於時間序列預測的演算法
這個想法是,如果一個值超出預測置信區間,則該值被視為異常值。使用三重平滑、S(ARIMA)、提升等演算法來預測時間序列。
上一篇文章討論了時間序列預測演算法。
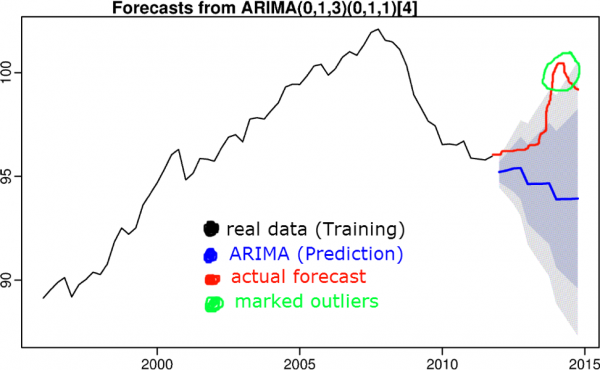
8)監督學習(迴歸、分類)
如果資料允許,我們會使用從線性迴歸到循環網路的演算法。讓我們測量預測值和實際值之間的差異,並得出數據偏離標準值的程度的結論。重要的是演算法具有足夠的泛化能力並且訓練樣本不包含異常值。
9)模型試驗
讓我們將發現異常的問題視為尋找建議的問題。我們將使用 SVD 或因式分解機來分解我們的特徵矩陣,新矩陣中與原始矩陣有顯著差異的值將被視為異常。
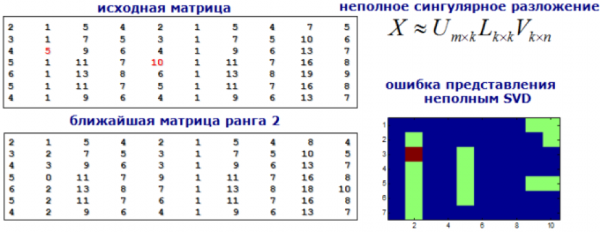
圖片來自dyakonov.org
結論
在本文中,我們介紹了異常檢測的主要方法。
從很多方面來說,發現異常都可以被視為一門藝術。不存在可以解決所有問題的理想演算法或方法。更多的時候,是用一套方法來解決一個具體的案例。異常檢測使用一類支援向量機、隔離森林、度量和聚類方法以及主成分和時間序列預測來執行。
如果您知道其他方法,請在文章的評論中寫下來。
來源: www.habr.com
