


你又有一項目標偵測任務。首要任務是保證速度和可接受的準確率。你採用 YOLOv3 架構重新訓練。準確率 (mAp75) 超過了 0.95。但運行速度仍然很慢。真糟糕。
今天我們將繞過量化。在切割下,我們將考慮 模型剪枝 — 剪掉網路中多餘的部分,以加快推理速度,同時又不失去準確度。直觀地展示剪掉的位置、程度和方法。我們將分析如何手動執行此操作以及在哪些情況下可以自動化執行。最後,我們將提供一個 keras 程式碼庫。
介紹
在我之前的工作 Perm Macroscop 中,我養成了一個習慣——總是監控演算法的執行時間。並且始終透過充分性過濾器檢查網路運行時間。通常,生產環境中最先進的演算法無法通過這個過濾器,這讓我想到了剪枝。
修剪是一個老話題, 2017年。其主要想法是透過移除各種節點來縮減訓練網路的規模,同時不損失準確率。聽起來很酷,但我很少聽說它的用途。可能是因為實現不夠多,沒有俄文文章,或是大家只是把修剪當成一種技術訣竅,就保持沉默。
但很難弄清楚
生物學一瞥
我喜歡將生物學的理念融入深度學習。它們就像進化一樣,值得信賴(你知道嗎?ReLU 與 ?)
模型剪枝過程也與生物學密切相關。網路的反應可以與大腦的可塑性進行比較。書中有幾個有趣的例子 :
- 天生只有一半大腦的女性的大腦已經重新編程,以執行缺少一半大腦的功能。
- 這傢伙切除了腦中負責視覺的部分。隨著時間的推移,大腦的其他部分接管了這些功能。 (我們不再贅述)
因此,你可以從模型中剪掉一些較弱的束。在極端情況下,剩餘的束可以用來替換被剪掉的束。
你喜歡遷移學習嗎?還是從頭開始學習?
選項一。 您可以在 Yolov3、Retina、Mask-RCNN 或 U-Net 上使用遷移學習。但通常我們不需要像 COCO 那樣辨識 80 個類別的物體。在我的實踐中,所有類別都限制在 1-2 個類別。可以假設 80 個類別的架構在這裡是多餘的。這個想法本身就顯示應該要精簡架構。而且,我希望在不失去現有預訓練權重的情況下做到這一點。
選項二。 也許你擁有大量資料和運算資源,或者只是需要一個超級客製化的架構。這沒關係。但你正在從頭開始訓練網路。通常的做法是查看資料結構,選擇一個效能冗餘的架構,並避免過度擬合導致的dropout。 Karl,我看過0.6個dropout的狀況。
在這兩種情況下,網路都可以被精簡。動機來了。現在我們來弄清楚哪種剪枝才是真正的剪枝
通用演算法
我們決定把折疊去掉。看起來相當簡單:
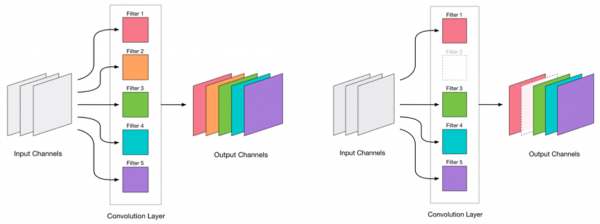
移除任何卷積都會對網路造成壓力,通常會導致誤差增加。一方面,誤差的成長可以顯示我們移除卷積的正確程度(例如,誤差的大幅增加表示我們操作錯誤)。但小幅的誤差增加是可以接受的,通常可以透過後續使用小規模學習器進行輕度再訓練來消除。我們新增了一個再訓練步驟:
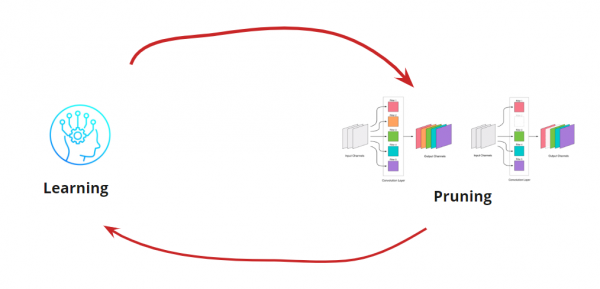
現在我們需要確定何時停止「學習<->剪枝」循環。這裡可能會有一些特殊的選項,例如,當我們需要將網路規模縮減到一定規模並達到一定的運行速度時(例如,針對行動裝置)。然而,最常見的選擇是繼續循環,直到誤差超過可接受範圍。讓我們新增一個條件:
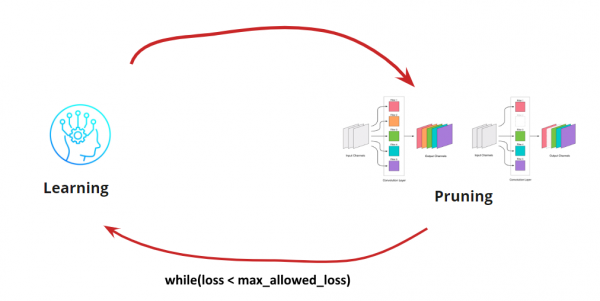
這樣,演算法就清晰了。剩下的就是如何確定需要移除的捲積。
搜尋可刪除的 bundles
我們需要刪除一些 bundles。雖然突破並「射擊」任何一個 bundles 都行不通,但這並不是個好主意。不過,如果你有腦子,可以思考並嘗試選擇「弱」的 bundles 進行刪除。這裡有幾種選擇:
- 具有較小權重值的捲積對最終決策的貢獻很小
- 考慮平均值和標準差的最小 L1 測度。我們對其進行了補充,以評估分佈的性質。
- . 更準確地檢測不重要的捲積,但非常耗時且耗資源。
- 他人
每個選項都有其存在的權利和各自的實現特性。這裡我們將考慮 L1 度量最小的選項
YOLOv3 的手動流程
原始架構包含殘差塊。雖然它們對於深度網路來說很酷,但它們也有點礙事。棘手的是,你無法移除這些層中的跨索引比較:
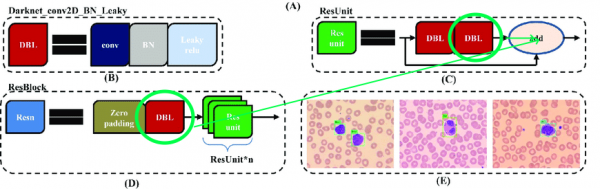
因此,讓我們選擇可以自由刪除檢查的圖層:

現在讓我們建立一個工作週期:
- 解除安裝啟用
- 讓我們算一下要削減多少
- 我們剪掉了
- 我們學習了 10 個 epoch,LR=1e-4
- 測試
卸載折疊有助於估算在特定步驟中可以移除多少折疊。卸載範例:
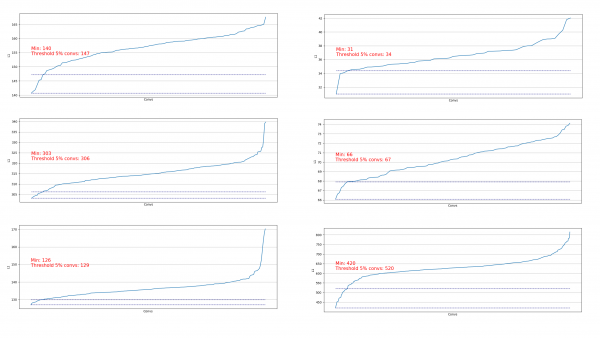
我們發現,幾乎所有地方都有 5% 的捲積具有非常低的 L1 範數,我們可以將其移除。在每個步驟中,我們都重複進行這樣的卸載,並評估哪些層以及可以移除多少。
整個過程分為 4 個步驟(此處以及所有地方的數字均針對 RTX 2060 Super):
| 步驟 | mAp75 | 參數數量,百萬 | 網路規模,MB | 從原文來看,% | 運轉時間,毫秒 | 包皮環切情況 |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | 佔全部的 5% |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | 佔全部的 5% |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 對於卷積層超過 15 個的情況,降低 400% |
| 4 | 0.9555 | 31 | 124 | 51 | 146 | 對於卷積層超過 10 個的情況,降低 100% |
步驟 2 增加了一個正面的影響:批量大小 4 適合內存,這顯著加快了額外訓練的過程。
在步驟 4 中,該過程停止,因為即使長期的額外訓練也無法將 mAp75 提高到舊值。
因此,我們設法透過以下方式加快推理速度 ,減少尺寸 並且不會失去準確性。
更簡單的架構自動化
對於更簡單的網路架構(沒有條件添加、連接和殘差塊),完全可以集中處理所有捲積層並自動化卷積的切割過程。
我實現了這個選項 .
很簡單:您所需要的只是一個損失函數、一個優化器和批量生成器:
import pruning
from keras.optimizers import Adam
from keras.utils import Sequence
train_batch_generator = BatchGenerator...
score_batch_generator = BatchGenerator...
opt = Adam(lr=1e-4)
pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt)
pruner.prune(train_batch, valid_batch)如果需要,您可以變更配置參數:
{
"input_model_path": "model.h5",
"output_model_path": "model_pruned.h5",
"finetuning_epochs": 10, # the number of epochs for train between pruning steps
"stop_loss": 0.1, # loss for stopping process
"pruning_percent_step": 0.05, # part of convs for delete on every pruning step
"pruning_standart_deviation_part": 0.2 # shift for limit pruning part
}此外,也實施了基於標準差的限制。目的是限制被移除的部分,排除那些已經具有「足夠」L1度量的捲積:
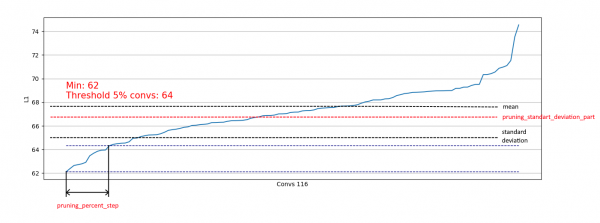
這樣,我們只允許從類似右側分佈的分佈中移除弱卷積,而不會影響從類似左側分佈的分佈中移除:

當分佈趨近於常態時,係數pruning_standart_deviation_part可以從下列選項中選擇:
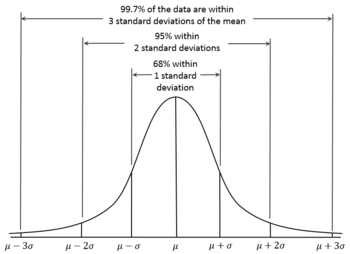
我建議假設為 2 sigma。或者您可以忽略此功能,並將值保留為 < 1.0。
輸出是整個測試的網路規模、損失和網路運行時間的圖表,已歸一化為 1.0。例如,這裡網路規模縮小了近 2 倍,但品質卻沒有損失(一個權重為 100 萬的小型捲積網路):
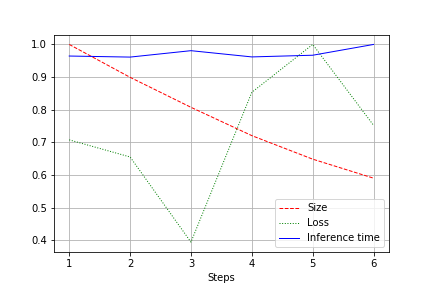
運轉速度有正常波動,基本上保持不變。對此有解釋:
- 卷積的數量從方便的(32、64、128)變為對視訊卡不太方便的 - 27、51 等。我在這裡可能錯了,但很可能它有影響。
- 該架構並不寬,但卻保持一致。透過降低寬度,我們不會影響深度。因此,我們降低了負載,但速度沒有改變。
因此,改進表現為運行期間 CUDA 負載減少 20-30%,但並未表現為運行時間減少。
結果
讓我們反思一下。我們考慮了兩種剪枝方案:一種是針對 YOLOv2(需要手動操作),另一種是針對架構較簡單的網路。顯然,這兩種方案都可以在不損失準確率的情況下,縮減網路規模並提升加速。結果:
- 減小尺寸
- 加速跑
- 減少 CUDA 負載
- 因此,生態友善(我們優化了計算資源的未來使用。有人歡喜有人憂 )
附錄
- 修剪步驟之後,您也可以調整量化(例如使用 TensorRT)
- Tensorflow 提供以下功能 .作品。
- 我希望發展並樂意提供協助
來源: www.habr.com
