

Meta/Facebook(在俄羅斯聯邦被禁止)推出了一種新的音訊編解碼器 EnCodec,它使用機器學習方法來提高壓縮比而不損失品質。 此編解碼器既可用於即時串流傳輸音頻,也可用於編碼以便稍後保存在檔案中。 EnCodec 參考實作是使用 PyTorch 框架用 Python 編寫的,並根據 CC BY-NC 4.0(知識共享署名-非商業)許可證獲得許可,僅供非商業用途。
提供兩個現成的型號可供下載:
- 使用 24 kHz 取樣率的因果模型,僅支援單聲道音頻,並在不同的音頻資料上進行訓練(適合語音編碼)。 此模型可用於打包音訊數據,以 1.5、3、6、12 和 24 kbps 的位元率進行傳輸。
- 使用 48 kHz 取樣率的非因果模型,支援立體聲音訊並僅針對音樂進行訓練。 此型號支援 3、6、12 和 24 kbps 的位元率。
對於每個模型,都準備了一個額外的語言模型,這使您可以在不損失品質的情況下實現壓縮比的顯著提高(高達 40%)。 與先前開發的使用機器學習方法進行音訊壓縮的專案不同,EnCodec不僅可以用於語音打包,還可以用於取樣率為48kHz的音樂壓縮,對應音訊CD的水平。 據新編解碼器的開發人員稱,與 MP64 格式相比,當以 3 kbps 的比特率傳輸時,他們能夠將音訊壓縮程度提高約十倍,同時保持相同的品質等級(例如,當使用MP3,需要64kbps的頻寬,在EnCodec中傳輸相同品質的6kbps就足夠了)。
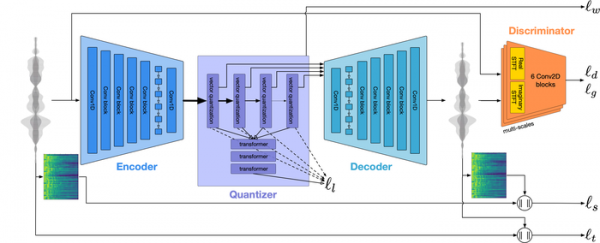
編解碼器架構建立在具有「變壓器」架構的神經網路之上,並基於四個連結:編碼器、量化器、解碼器和鑑別器。 編碼器提取語音資料的參數並將打包流轉換為較低的幀速率。 量化器(RVQ,殘差向量量化器)將編碼器輸出的流轉換為資料包集,並根據所選位元率壓縮資訊。 量化器的輸出是資料的壓縮表示,適合透過網路傳輸或儲存到磁碟。
解碼器對資料的壓縮表示進行解碼並重建原始聲波。 考慮到人類聽覺感知的模型,鑑別器提高了生成樣本的品質。 無論品質和位元率等級如何,用於編碼和解碼的模型都具有相當適度的資源需求(即時操作所需的計算在單一 CPU 核心上執行)。
來源: opennet.ru
