


لقد عثرت على بعض المواد المثيرة للاهتمام حول الذكاء الاصطناعي في الألعاب. مع شرح للأشياء الأساسية حول الذكاء الاصطناعي باستخدام أمثلة بسيطة، ويوجد بداخله العديد من الأدوات والأساليب المفيدة لتطويره وتصميمه بشكل مناسب. كيف وأين ومتى استخدامها موجود أيضًا.
تتم كتابة معظم الأمثلة بالكود الزائف، لذلك لا يلزم معرفة برمجة متقدمة. يوجد أسفل المقطع 35 ورقة نصية تحتوي على صور وصور متحركة، لذا استعد.
محدث. أعتذر، لكنني قمت بالفعل بترجمة هذا المقال عن حبري . يمكنك قراءة نسخته ولكن لسبب ما مررت المقالة (استخدمت البحث، ولكن حدث خطأ ما). وبما أنني أكتب على مدونة مخصصة لتطوير الألعاب، فقد قررت ترك نسختي من الترجمة للمشتركين (يتم تنسيق بعض النقاط بشكل مختلف، وتم حذف بعضها عمدا بناء على نصيحة المطورين).
ما هو الذكاء الاصطناعي؟
تركز لعبة AI على الإجراءات التي يجب أن يقوم بها الكائن بناءً على الظروف التي يوجد فيها. يُشار إلى هذا عادةً باسم إدارة "الوكيل الذكي"، حيث يكون الوكيل عبارة عن شخصية لاعب، أو مركبة، أو روبوت، أو في بعض الأحيان شيء أكثر تجريدًا: مجموعة كاملة من الكيانات أو حتى حضارة. وفي كل حالة، فهو شيء يجب أن يرى بيئته، ويتخذ القرارات بناءً عليها، ويتصرف وفقًا لها. وهذا ما يسمى بدورة الإحساس/التفكير/الفعل:
- الإحساس: يجد الوكيل أو يتلقى معلومات حول أشياء في بيئته قد تؤثر على سلوكه (التهديدات القريبة، العناصر التي يجب جمعها، الأماكن المثيرة للاهتمام التي يجب استكشافها).
- فكر: يقرر العميل كيفية الرد (مع الأخذ في الاعتبار ما إذا كان جمع العناصر آمنًا بدرجة كافية أو ما إذا كان يجب عليه القتال/الاختباء أولاً).
- الفعل: يقوم الوكيل بإجراءات تنفيذ القرار السابق (يبدأ بالتحرك نحو العدو أو الكائن).
- ...الآن تغير الوضع بسبب تصرفات الشخصيات، لذا تتكرر الدورة ببيانات جديدة.
يميل الذكاء الاصطناعي إلى التركيز على الجزء الحسي من الحلقة. على سبيل المثال، تلتقط السيارات ذاتية القيادة صورًا للطريق، وتدمجها مع بيانات الرادار والليدار، وتفسرها. ويتم ذلك عادةً عن طريق التعلم الآلي، الذي يعالج البيانات الواردة ويعطيها معنى، ويستخرج المعلومات الدلالية مثل "هناك سيارة أخرى أمامك بمسافة 20 ياردة". هذه هي ما يسمى مشاكل التصنيف.
لا تحتاج الألعاب إلى نظام معقد لاستخراج المعلومات لأن معظم البيانات هي بالفعل جزء لا يتجزأ منها. ليست هناك حاجة لتشغيل خوارزميات التعرف على الصور لتحديد ما إذا كان هناك عدو أمامك، فاللعبة تعرف بالفعل المعلومات وتغذيها مباشرة في عملية صنع القرار. ولذلك، فإن الجزء الخاص بالإدراك من الدورة غالبًا ما يكون أبسط بكثير من الجزء الخاص بالتفكير والتصرف.
حدود لعبة الذكاء الاصطناعي
لدى الذكاء الاصطناعي عدد من القيود التي يجب مراعاتها:
- لا يحتاج الذكاء الاصطناعي إلى التدريب مسبقًا، كما لو كان خوارزمية للتعلم الآلي. ليس من المنطقي كتابة شبكة عصبية أثناء التطوير لمراقبة عشرات الآلاف من اللاعبين ومعرفة أفضل طريقة للعب ضدهم. لماذا؟ لأن اللعبة لم يتم إصدارها ولا يوجد لاعبين.
- يجب أن تكون اللعبة ممتعة ومليئة بالتحديات، لذلك لا ينبغي للوكلاء العثور على أفضل طريقة ضد الأشخاص.
- يحتاج الوكلاء إلى الظهور بمظهر واقعي حتى يشعر اللاعبون وكأنهم يلعبون ضد أناس حقيقيين. لقد تفوق برنامج AlphaGo على البشر، لكن الخطوات التي تم اختيارها كانت بعيدة جدًا عن الفهم التقليدي للعبة. إذا كانت اللعبة تحاكي خصمًا بشريًا، فلا ينبغي أن يكون هذا الشعور موجودًا. تحتاج الخوارزمية إلى التغيير حتى تتمكن من اتخاذ قرارات معقولة بدلاً من القرارات المثالية.
- يجب أن يعمل الذكاء الاصطناعي في الوقت الفعلي. وهذا يعني أن الخوارزمية لا يمكنها احتكار استخدام وحدة المعالجة المركزية لفترات طويلة من الوقت لاتخاذ القرارات. حتى 10 مللي ثانية تعتبر طويلة جدًا، لأن معظم الألعاب تحتاج فقط إلى 16 إلى 33 مللي ثانية للقيام بكل المعالجة والانتقال إلى إطار الرسومات التالي.
- من الناحية المثالية، يجب أن يكون جزء من النظام على الأقل قائمًا على البيانات، حتى يتمكن غير المبرمجين من إجراء التغييرات والتعديلات بسرعة أكبر.
دعونا نلقي نظرة على أساليب الذكاء الاصطناعي التي تغطي دورة الإحساس/التفكير/الفعل بأكملها.
اتخاذ القرارات الأساسية
لنبدأ بأبسط لعبة - بونج. الهدف: حرك المضرب بحيث ترتد الكرة عنه بدلاً من التحليق فوقه. إنه مثل التنس، حيث تخسر إذا لم تضرب الكرة. هنا لدى الذكاء الاصطناعي مهمة سهلة نسبيًا - تحديد الاتجاه الذي سيحرك فيه النظام الأساسي.

عبارات شرطية
بالنسبة للذكاء الاصطناعي في لعبة Pong، الحل الأكثر وضوحًا هو محاولة وضع المنصة دائمًا تحت الكرة.
خوارزمية بسيطة لهذا، مكتوبة بالكود الكاذب:
كل إطار/تحديث أثناء تشغيل اللعبة:
إذا كانت الكرة على يسار المجداف:
تحرك مجداف اليسار
وإلا إذا كانت الكرة على يمين المجداف:
تحرك مجداف الحق
إذا كانت المنصة تتحرك بسرعة الكرة، فهذه هي الخوارزمية المثالية للذكاء الاصطناعي في لعبة بونغ. ليست هناك حاجة لتعقيد أي شيء إذا لم يكن هناك الكثير من البيانات والإجراءات الممكنة للوكيل.
هذا النهج بسيط جدًا لدرجة أن دورة الإحساس/التفكير/الفعل بأكملها بالكاد تكون ملحوظة. لكنه هناك:
- الجزء Sense موجود في عبارات if. تعرف اللعبة مكان وجود الكرة ومكان المنصة، لذلك يبحث عنها الذكاء الاصطناعي للحصول على تلك المعلومات.
- يتم أيضًا تضمين جزء "التفكير" في عبارات if. إنهم يجسدون حلين، وهما في هذه الحالة متنافيان. ونتيجة لذلك، يتم تحديد أحد الإجراءات الثلاثة - حرك المنصة إلى اليسار، أو حركها إلى اليمين، أو لا تفعل شيئًا إذا كانت في موضعها الصحيح بالفعل.
- تم العثور على جزء "التصرف" في عبارات Move Paddle Left وMove Paddle Right. اعتمادًا على تصميم اللعبة، يمكنهم تحريك المنصة على الفور أو بسرعة محددة.
تسمى هذه الأساليب رد الفعل - هناك مجموعة بسيطة من القواعد (في هذه الحالة إذا كانت البيانات في الكود) تتفاعل مع الوضع الحالي للعالم وتتخذ إجراءً.
شجرة القرار
إن مثال Pong يعادل في الواقع مفهومًا رسميًا للذكاء الاصطناعي يسمى شجرة القرار. تمر الخوارزمية عبرها للوصول إلى "الورقة" - وهي قرار بشأن الإجراء الذي يجب اتخاذه.
لنقم بعمل رسم تخطيطي لشجرة القرار لخوارزمية منصتنا:
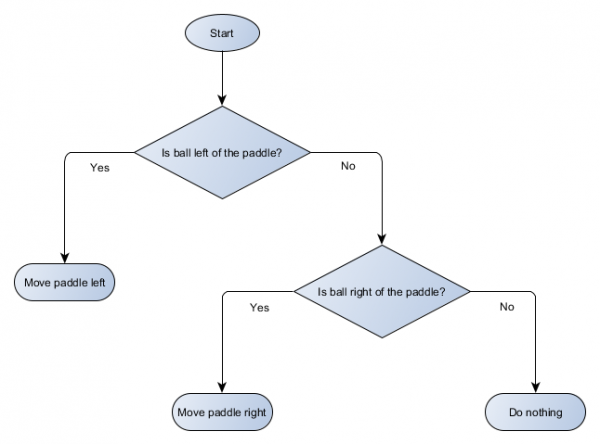
يُطلق على كل جزء من الشجرة اسم العقدة، ويستخدم الذكاء الاصطناعي نظرية الرسم البياني لوصف مثل هذه الهياكل. هناك نوعان من العقد:
- عقد القرار: الاختيار بين بديلين بناء على اختبار بعض الشروط، حيث يتم تمثيل كل بديل كعقدة منفصلة.
- عقد النهاية: الإجراء المطلوب تنفيذه والذي يمثل القرار النهائي.
تبدأ الخوارزمية من العقدة الأولى ("جذر" الشجرة). فهو إما يتخذ قرارًا بشأن العقدة الفرعية التي سيذهب إليها، أو ينفذ الإجراء المخزن في العقدة ويخرج.
ما فائدة وجود شجرة قرارات تؤدي نفس وظيفة عبارات if في القسم السابق؟ يوجد هنا نظام عام حيث يكون لكل قرار شرط واحد فقط ونتيجتان محتملتان. يتيح ذلك للمطور إنشاء الذكاء الاصطناعي من البيانات التي تمثل القرارات في الشجرة دون الحاجة إلى ترميزها. لنعرضها على شكل جدول:
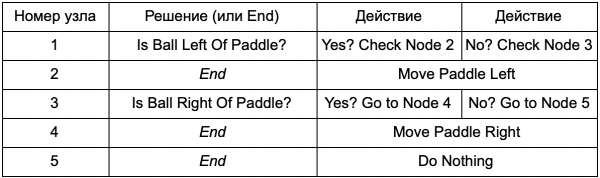
على جانب التعليمات البرمجية سوف تحصل على نظام لقراءة السلاسل. أنشئ عقدة لكل منها، وقم بتوصيل منطق القرار بناءً على العمود الثاني، والعقد الفرعية بناءً على العمودين الثالث والرابع. لا تزال بحاجة إلى برمجة الشروط والإجراءات، ولكن الآن سيكون هيكل اللعبة أكثر تعقيدًا. يمكنك هنا إضافة قرارات وإجراءات إضافية، ثم تخصيص الذكاء الاصطناعي بالكامل بمجرد تحرير الملف النصي لتعريف الشجرة. بعد ذلك، تقوم بنقل الملف إلى مصمم اللعبة، الذي يمكنه تغيير السلوك دون إعادة ترجمة اللعبة أو تغيير التعليمات البرمجية.
تكون أشجار القرار مفيدة جدًا عندما يتم إنشاؤها تلقائيًا من مجموعة كبيرة من الأمثلة (على سبيل المثال، باستخدام خوارزمية ID3). وهذا يجعلها أداة فعالة وعالية الأداء لتصنيف المواقف بناءً على البيانات التي تم الحصول عليها. ومع ذلك، فإننا نتجاوز مجرد نظام بسيط للوكلاء لاختيار الإجراءات.
السيناريوهات
قمنا بتحليل نظام شجرة القرار الذي يستخدم الشروط والإجراءات التي تم إنشاؤها مسبقًا. يستطيع الشخص الذي يصمم الذكاء الاصطناعي تنظيم الشجرة كيفما يشاء، لكن لا يزال عليه الاعتماد على المبرمج الذي برمجها كلها. ماذا لو تمكنا من منح المصمم الأدوات اللازمة لإنشاء شروطه أو إجراءاته الخاصة؟
حتى لا يضطر المبرمج إلى كتابة كود للشروط هل الكرة على يسار المجذاف وهل الكرة على يمين المجذاف، يمكنه إنشاء نظام يكتب فيه المصمم الشروط للتحقق من هذه القيم. ثم ستبدو بيانات شجرة القرار كما يلي:
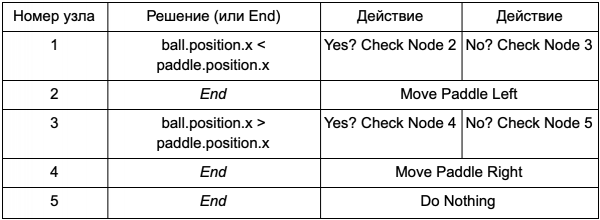
هذا هو نفسه كما في الجدول الأول، ولكن الحلول في حد ذاتها لها كود خاص بها، يشبه إلى حد ما الجزء الشرطي من عبارة if. على جانب الكود، سيتم قراءة هذا في العمود الثاني لعقد القرار، ولكن بدلاً من البحث عن شرط محدد للتنفيذ (هل الكرة على يسار المجذاف)، فإنه يقوم بتقييم التعبير الشرطي وإرجاع صحيح أو خطأ وفقًا لذلك. ويتم ذلك باستخدام لغة البرمجة النصية Lua أو Angelscript. باستخدامها، يمكن للمطور أن يأخذ كائنات في لعبته (الكرة والمجداف) وينشئ المتغيرات التي ستكون متاحة في البرنامج النصي (ball.position). كما أن لغة البرمجة النصية أبسط من لغة C++. لا يتطلب الأمر مرحلة تجميع كاملة، لذا فهو مثالي لضبط منطق اللعبة بسرعة ويسمح "لغير المبرمجين" بإنشاء الوظائف الضرورية بأنفسهم.
في المثال أعلاه، يتم استخدام لغة البرمجة النصية فقط لتقييم التعبير الشرطي، ولكن يمكن استخدامها أيضًا للإجراءات. على سبيل المثال، يمكن أن تصبح البيانات Move Paddle Right بيانًا نصيًا (ball.position.x += 10). بحيث يتم تعريف الإجراء أيضًا في البرنامج النصي، دون الحاجة إلى برمجة Move Paddle Right.
يمكنك الذهاب إلى أبعد من ذلك وكتابة شجرة القرار بأكملها بلغة البرمجة النصية. سيكون هذا رمزًا في شكل عبارات شرطية مشفرة، ولكنها ستكون موجودة في ملفات نصية خارجية، أي أنه يمكن تغييرها دون إعادة ترجمة البرنامج بأكمله. يمكنك غالبًا تحرير ملف البرنامج النصي أثناء اللعب لاختبار استجابات الذكاء الاصطناعي المختلفة بسرعة.
الاستجابة للحدث
الأمثلة المذكورة أعلاه مثالية لـ Pong. إنهم يديرون باستمرار دورة الإحساس/التفكير/الفعل ويتصرفون بناءً على أحدث حالة في العالم. ولكن في الألعاب الأكثر تعقيدا، تحتاج إلى الرد على الأحداث الفردية، وليس تقييم كل شيء في وقت واحد. بونغ في هذه الحالة هو بالفعل مثال سيء. دعونا نختار واحدة أخرى.
تخيل مطلق النار حيث يكون الأعداء بلا حراك حتى يكتشفوا اللاعب، وبعد ذلك يتصرفون اعتمادًا على "تخصصهم": سوف يركض شخص ما إلى "الاندفاع"، وسيهاجم شخص ما من بعيد. لا يزال نظام رد الفعل أساسيًا - "إذا تم رصد لاعب، فافعل شيئًا ما" - ولكن يمكن تقسيمه منطقيًا إلى حدث تمت رؤيته للاعب ورد فعل (حدد استجابة وقم بتنفيذها).
وهذا يعيدنا إلى دورة الإحساس/التفكير/الفعل. يمكننا ترميز جزء Sense الذي سيتحقق من كل إطار ما إذا كان الذكاء الاصطناعي يرى اللاعب. إذا لم يكن الأمر كذلك، فلن يحدث شيء، ولكن إذا تم رؤيته، فسيتم إنشاء حدث "مشاهدة اللاعب". سيحتوي الكود على قسم منفصل يقول "عند حدوث حدث مشاهدة اللاعب، افعل" حيث يكون الرد الذي تحتاجه لمعالجة أجزاء التفكير والتصرف. وبالتالي، ستقوم بإعداد ردود أفعال على حدث "مشاهدة اللاعب": للشخصية "المتسارعة" - ChargeAndAttack، وللقناص - HideAndSnipe. يمكن إنشاء هذه العلاقات في ملف البيانات للتحرير السريع دون الحاجة إلى إعادة الترجمة. يمكن استخدام لغة البرمجة النصية هنا أيضًا.
اتخاذ القرارات الصعبة
على الرغم من أن أنظمة التفاعل البسيطة قوية جدًا، إلا أن هناك العديد من المواقف التي لا تكون فيها كافية. في بعض الأحيان تحتاج إلى اتخاذ قرارات مختلفة بناءً على ما يفعله الوكيل حاليًا، ولكن من الصعب تخيل ذلك كشرط. في بعض الأحيان يكون هناك عدد كبير جدًا من الشروط لتمثيلها بشكل فعال في شجرة القرار أو البرنامج النصي. في بعض الأحيان تحتاج إلى تقييم مسبق لكيفية تغير الوضع قبل اتخاذ قرار بشأن الخطوة التالية. هناك حاجة إلى أساليب أكثر تطورا لحل هذه المشاكل.
آلة الدولة المحدودة
آلة الحالة المحدودة أو FSM (آلة الحالة المحدودة) هي طريقة للقول إن وكيلنا موجود حاليًا في إحدى الحالات المحتملة العديدة، وأنه يمكنه الانتقال من حالة إلى أخرى. هناك عدد معين من هذه الحالات، ومن هنا جاءت تسميتها. أفضل مثال من الحياة هو إشارة المرور. هناك تسلسلات مختلفة من الأضواء في أماكن مختلفة، ولكن المبدأ هو نفسه - كل حالة تمثل شيئًا ما (توقف، مشيًا، وما إلى ذلك). تكون إشارة المرور في حالة واحدة فقط في أي وقت، وتنتقل من حالة إلى أخرى بناءً على قواعد بسيطة.
إنها قصة مماثلة مع الشخصيات غير القابلة للعب في الألعاب. على سبيل المثال، لنأخذ حارسًا بالحالات التالية:
- الدوريات.
- مهاجمة.
- الفرار.
وهذه شروط تغيير حالته:
- إذا رأى الحارس العدو فإنه يهاجم.
- إذا هاجم الحارس لكنه لم يعد يرى العدو، فإنه يعود إلى الدورية.
- إذا هاجم أحد الحراس لكنه أصيب بجروح بالغة، فإنه يهرب.
يمكنك أيضًا كتابة عبارات if باستخدام متغير حالة الوصي وعمليات التحقق المختلفة: هل يوجد عدو قريب، وما هو مستوى صحة الشخصية غير القابلة للعب، وما إلى ذلك. دعنا نضيف بعض الحالات الأخرى:
- الخمول - بين الدوريات.
- البحث - عندما يختفي العدو الذي تم رصده.
- العثور على المساعدة - عندما يتم رصد عدو، ولكنه أقوى من أن يقاتل بمفرده.
الاختيار لكل واحد منهم محدود - على سبيل المثال، لن يذهب الحارس للبحث عن عدو مخفي إذا كانت صحته منخفضة.
بعد كل شيء، هناك قائمة ضخمة من "ifs" ، الذي - التي "يمكن أن تصبح مرهقة للغاية، لذلك نحن بحاجة إلى إضفاء الطابع الرسمي على طريقة تسمح لنا بوضع الدول والتحولات بين الدول في الاعتبار. للقيام بذلك، نأخذ في الاعتبار جميع الدول، وتحت كل دولة نكتب في القائمة جميع التحولات إلى الدول الأخرى، إلى جانب الشروط اللازمة لها.
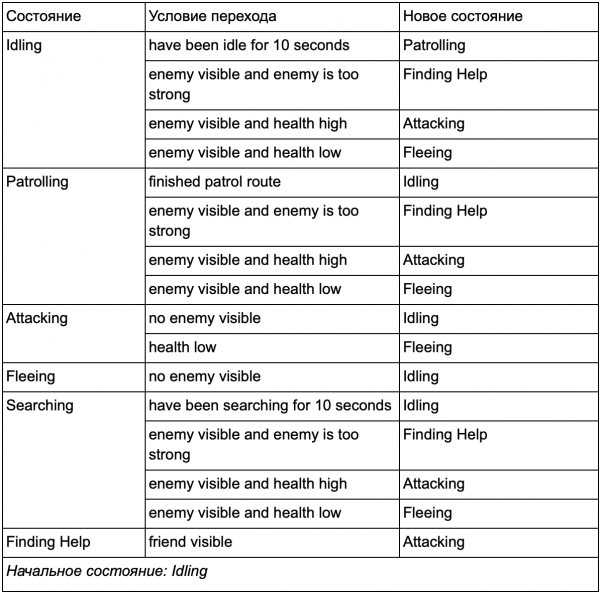
هذا جدول انتقال الدولة - طريقة شاملة لتمثيل ولايات ميكرونيزيا الموحدة. لنرسم مخططًا ونحصل على نظرة عامة كاملة حول كيفية تغير سلوك الشخصيات غير القابلة للعب.
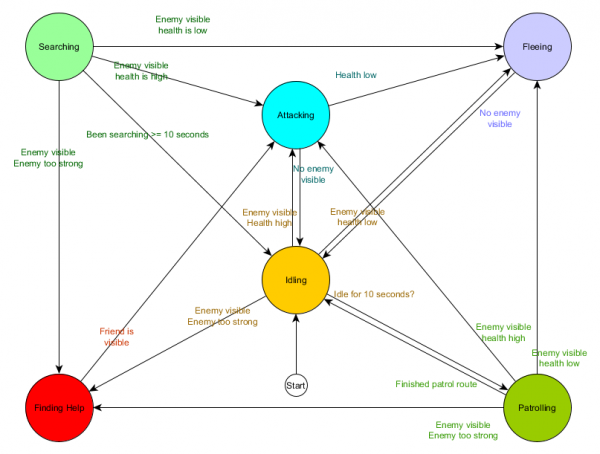
يعكس الرسم البياني جوهر اتخاذ القرار لهذا الوكيل بناءً على الوضع الحالي. علاوة على ذلك، يُظهر كل سهم انتقالًا بين الحالات إذا كان الشرط المجاور له صحيحًا.
في كل تحديث نقوم بالتحقق من الحالة الحالية للوكيل، وننظر في قائمة التحولات، وإذا تم استيفاء شروط الانتقال، فإنه يقبل الحالة الجديدة. على سبيل المثال، يتحقق كل إطار من انتهاء صلاحية مؤقت الـ 10 ثوانٍ، وإذا كان الأمر كذلك، ينتقل الحارس من حالة الخمول إلى الدورية. بنفس الطريقة، تتحقق الحالة المهاجمة من صحة العميل - إذا كانت منخفضة، فإنه ينتقل إلى حالة الهروب.
هذا هو التعامل مع التحولات بين الدول، ولكن ماذا عن السلوك المرتبط بالدول نفسها؟ فيما يتعلق بتنفيذ السلوك الفعلي لحالة معينة، يوجد عادةً نوعان من "الربط" حيث نقوم بتعيين إجراءات إلى FSM:
- الإجراءات التي نقوم بها بشكل دوري للحالة الحالية.
- الإجراءات التي نتخذها عند الانتقال من حالة إلى أخرى.
أمثلة على النوع الأول. ستقوم دولة الدورية بتحريك العميل على طول مسار الدورية في كل إطار. ستحاول الحالة المهاجمة بدء الهجوم في كل إطار أو الانتقال إلى الحالة التي يكون فيها ذلك ممكنًا.
بالنسبة للنوع الثاني، فكر في الانتقال “إذا كان العدو مرئيًا وكان العدو قويًا جدًا، فانتقل إلى حالة البحث عن المساعدة. يجب على الوكيل اختيار المكان الذي يذهب إليه للحصول على المساعدة وتخزين هذه المعلومات حتى تعرف حالة البحث عن المساعدة إلى أين تذهب. بمجرد العثور على المساعدة، يعود العميل إلى الحالة المهاجمة. عند هذه النقطة، سيرغب في إخبار الحليف بالتهديد، لذلك قد يتم تنفيذ الإجراء NotifyFriendOfThreat.
مرة أخرى، يمكننا أن ننظر إلى هذا النظام من خلال عدسة دورة الإحساس/التفكير/الفعل. يتجسد المعنى في البيانات التي يستخدمها منطق الانتقال. فكر - التحولات المتاحة في كل ولاية. ويتم تنفيذ الفعل من خلال الإجراءات التي يتم تنفيذها بشكل دوري داخل الدولة أو عند التحولات بين الولايات.
في بعض الأحيان قد تكون ظروف الانتقال للاقتراع المستمر مكلفة. على سبيل المثال، إذا قام كل عميل بإجراء حسابات معقدة في كل إطار لتحديد ما إذا كان يمكنه رؤية الأعداء وفهم ما إذا كان يمكنه الانتقال من حالة الدورية إلى حالة الهجوم، فسيستغرق ذلك الكثير من وقت وحدة المعالجة المركزية.
يمكن اعتبار التغيرات المهمة في حالة العالم بمثابة أحداث ستتم معالجتها عند حدوثها. بدلاً من التحقق من FSM لشرط الانتقال "هل يمكن لوكيلي رؤية اللاعب؟" في كل إطار، يمكن تكوين نظام منفصل للتحقق بشكل أقل تكرارًا (على سبيل المثال، 5 مرات في الثانية). والنتيجة هي إصدار Player Seen عند مرور الشيك.
يتم تمرير هذا إلى FSM، والذي يجب أن ينتقل الآن إلى حالة استلام حدث Player Seen ويستجيب وفقًا لذلك. السلوك الناتج هو نفسه باستثناء تأخير غير محسوس تقريبًا قبل الاستجابة. لكن الأداء تحسن نتيجة فصل الجزء Sense إلى جزء منفصل من البرنامج.
آلة الحالة الهرمية المحدودة
ومع ذلك، فإن العمل مع ولايات ميكرونيزيا الموحدة الكبيرة ليس مناسبًا دائمًا. إذا أردنا توسيع حالة الهجوم لفصل MeleeAttacking و RangedAttacking، فسيتعين علينا تغيير التحولات من جميع الحالات الأخرى التي تؤدي إلى حالة الهجوم (الحالية والمستقبلية).
ربما لاحظت أنه في مثالنا يوجد الكثير من التحولات المكررة. تتطابق معظم التحولات في حالة الخمول مع التحولات في حالة الدورية. وسيكون من الجيد ألا نكرر أنفسنا، خاصة إذا أضفنا المزيد من الحالات المشابهة. من المنطقي أن يتم تجميع التباطؤ والدوريات تحت التصنيف العام "غير القتالية"، حيث توجد مجموعة واحدة فقط مشتركة من التحولات إلى الدول القتالية. إذا فكرنا في هذه التسمية كدولة، فإن التباطؤ والدوريات يصبحان دولتين فرعيتين. مثال على استخدام جدول انتقال منفصل لحالة فرعية جديدة غير قتالية:
الدول الرئيسية:
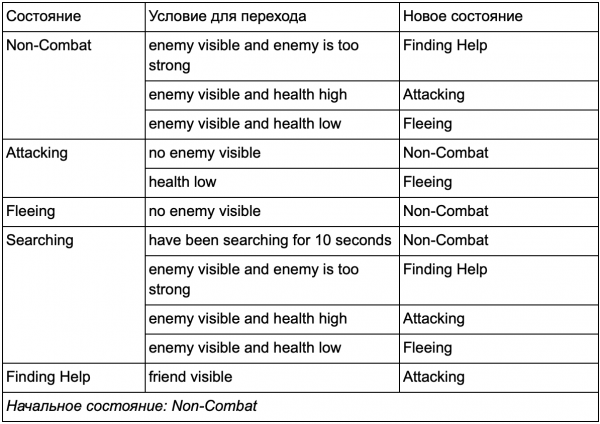
حالة الخروج من القتال:

وعلى شكل رسم بياني:
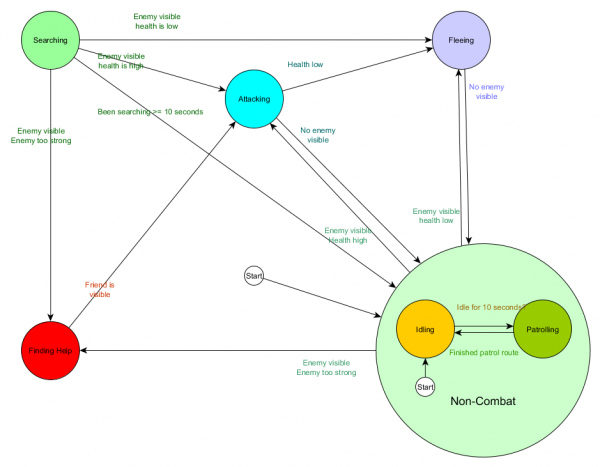
إنه نفس النظام، ولكن مع حالة جديدة غير قتالية تتضمن التباطؤ والدوريات. مع كل حالة تحتوي على ولايات ميكرونيزيا الموحدة مع حالات فرعية (وهذه الحالات الفرعية، بدورها، تحتوي على ولايات ميكرونيزيا الموحدة الخاصة بها - وهكذا للمدة التي تحتاجها)، نحصل على آلة حالة هرمية محدودة أو HFSM (آلة حالة هرمية محدودة). من خلال تجميع الدولة غير القتالية، قمنا بقطع مجموعة من التحولات الزائدة عن الحاجة. ويمكننا أن نفعل الشيء نفسه بالنسبة لأي دولة جديدة ذات تحولات مشتركة. على سبيل المثال، إذا قمنا في المستقبل بتوسيع حالة الهجوم إلى حالتي MeleeAttacking وMissileAttacking، فستكون حالات فرعية تنتقل بين بعضها البعض بناءً على المسافة إلى العدو وتوافر الذخيرة. ونتيجة لذلك، يمكن تمثيل السلوكيات المعقدة والسلوكيات الفرعية مع الحد الأدنى من التحولات المكررة.
شجرة السلوك
مع HFSM، يتم إنشاء مجموعات معقدة من السلوكيات بطريقة بسيطة. ومع ذلك، هناك صعوبة طفيفة في أن اتخاذ القرار في شكل قواعد انتقالية يرتبط ارتباطًا وثيقًا بالوضع الحالي. وهذا هو المطلوب بالضبط في العديد من الألعاب. والاستخدام الدقيق للتسلسل الهرمي للحالة يمكن أن يقلل من عدد تكرارات الانتقال. لكن في بعض الأحيان تحتاج إلى قواعد صالحة بغض النظر عن الولاية التي تعيش فيها، أو تنطبق على أي ولاية تقريبًا. على سبيل المثال، إذا انخفضت صحة العميل إلى 25%، فسوف تريده أن يهرب بغض النظر عما إذا كان في القتال أو خاملاً أو يتحدث - سيتعين عليك إضافة هذا الشرط إلى كل حالة. وإذا أراد المصمم الخاص بك لاحقًا تغيير عتبة الصحة المنخفضة من 25% إلى 10%، فسيتعين عليك القيام بذلك مرة أخرى.
ومن الناحية المثالية، يتطلب هذا الوضع نظاماً تكون فيه القرارات بشأن "ما هي الدولة التي سنكون فيها" خارج الدول نفسها، من أجل إجراء التغييرات في مكان واحد فقط وعدم المساس بشروط التحول. تظهر هنا أشجار السلوك.
هناك عدة طرق لتنفيذها، ولكن الجوهر هو نفسه تقريبًا بالنسبة للجميع ويشبه شجرة القرار: تبدأ الخوارزمية بعقدة "جذر"، وتحتوي الشجرة على العقد التي تمثل القرارات أو الإجراءات. هناك بعض الاختلافات الرئيسية على الرغم من:
- تُرجع العقد الآن إحدى القيم الثلاث: ناجحة (إذا اكتملت المهمة)، أو فاشلة (إذا تعذر البدء)، أو قيد التشغيل (إذا كانت لا تزال قيد التشغيل ولا توجد نتيجة نهائية).
- لم تعد هناك عقد قرار للاختيار بين بديلين. بدلاً من ذلك، فهي عقد ديكور، والتي تحتوي على عقدة فرعية واحدة. إذا نجحوا، فسيقومون بتنفيذ العقدة الفرعية الوحيدة الخاصة بهم.
- تقوم العقد التي تنفذ الإجراءات بإرجاع قيمة قيد التشغيل لتمثيل الإجراءات التي يتم تنفيذها.
يمكن دمج هذه المجموعة الصغيرة من العقد لإنشاء عدد كبير من السلوكيات المعقدة. لنتخيل حارس HFSM من المثال السابق كشجرة سلوك:
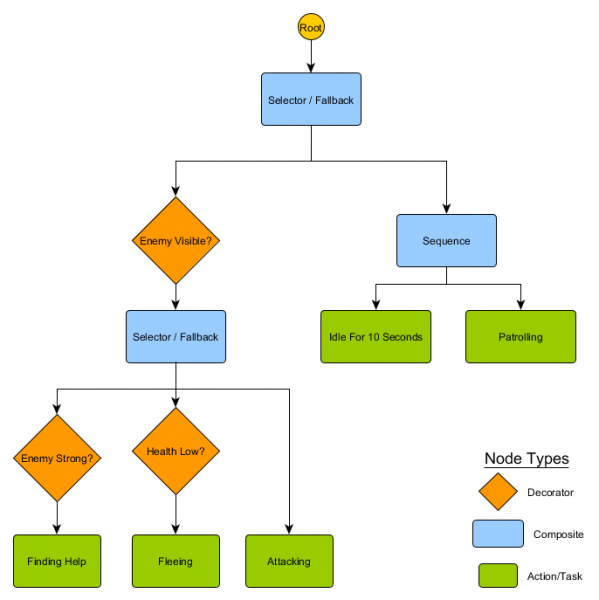
مع هذا الهيكل، لا ينبغي أن يكون هناك انتقال واضح من حالات التباطؤ/المراقبة إلى حالة الهجوم أو أي حالة أخرى. إذا كان العدو مرئيًا وكانت صحة الشخصية منخفضة، فسيتوقف التنفيذ عند عقدة الهروب، بغض النظر عن العقدة التي كان ينفذها سابقًا - الدورية أو التباطؤ أو الهجوم أو أي عقدة أخرى.
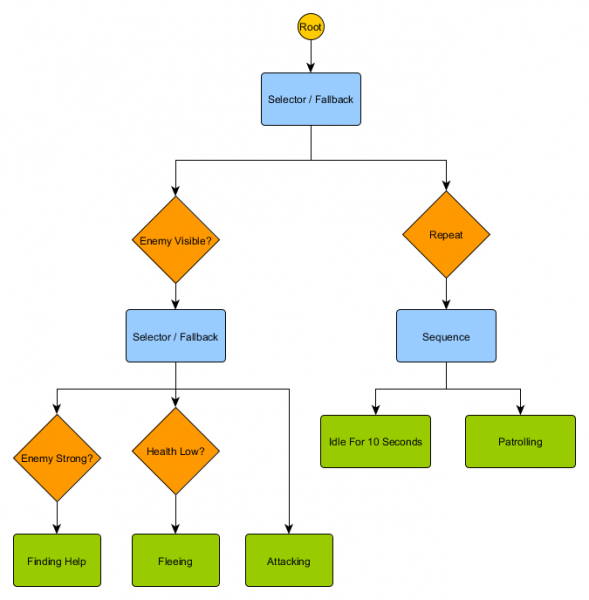
تعتبر أشجار السلوك معقدة، فهناك العديد من الطرق لتكوينها، وقد يكون العثور على المجموعة الصحيحة من عناصر الديكور والعقد المركبة أمرًا صعبًا. هناك أيضًا أسئلة حول عدد مرات فحص الشجرة - هل نريد فحص كل جزء منها أم فقط عندما يتغير أحد الشروط؟ كيف نقوم بتخزين الحالة المتعلقة بالعقد - كيف نعرف متى كنا في وضع الخمول لمدة 10 ثوانٍ، أو كيف نعرف العقد التي تم تنفيذها في المرة الأخيرة حتى نتمكن من معالجة التسلسل بشكل صحيح؟
ولهذا السبب هناك العديد من التطبيقات. على سبيل المثال، استبدلت بعض الأنظمة العقد المزخرفة بعناصر مزخرفة مضمنة. يقومون بإعادة تقييم الشجرة عندما تتغير ظروف الديكور، ويساعدون في ربط العقد، ويقدمون تحديثات دورية.
النظام القائم على المنفعة
تحتوي بعض الألعاب على العديد من الآليات المختلفة. ومن المرغوب فيه أن يحصلوا على جميع فوائد قواعد الانتقال البسيطة والعامة، ولكن ليس بالضرورة في شكل شجرة سلوك كاملة. فبدلاً من وجود مجموعة واضحة من الاختيارات أو شجرة من الإجراءات المحتملة، من الأسهل فحص جميع الإجراءات واختيار الإجراء الأكثر ملاءمة في الوقت الحالي.
سيساعد النظام القائم على الأداة المساعدة في هذا الأمر. هذا هو النظام الذي يكون لدى الوكيل فيه مجموعة متنوعة من الإجراءات ويختار الإجراءات التي يجب تنفيذها بناءً على المنفعة النسبية لكل منها. حيث تكون المنفعة مقياسًا تعسفيًا لمدى أهمية أو رغبة الوكيل في تنفيذ هذا الإجراء.
الأداة المساعدة المحسوبة للإجراء بناءً على الحالة والبيئة الحالية، يمكن للوكيل التحقق من الحالة الأخرى الأكثر ملاءمة واختيارها في أي وقت. وهذا يشبه ولايات ميكرونيزيا الموحدة، باستثناء الحالات التي يتم فيها تحديد التحولات من خلال تقدير لكل حالة محتملة، بما في ذلك الحالة الحالية. يرجى ملاحظة أننا نختار الإجراء الأكثر فائدة للمضي قدمًا (أو البقاء إذا كنا قد أكملناه بالفعل). لمزيد من التنوع، يمكن أن يكون هذا اختيارًا متوازنًا ولكن عشوائيًا من قائمة صغيرة.
يقوم النظام بتعيين نطاق عشوائي من قيم المنفعة - على سبيل المثال، من 0 (غير مرغوب فيه على الإطلاق) إلى 100 (مرغوب فيه تمامًا). يحتوي كل إجراء على عدد من المعلمات التي تؤثر على حساب هذه القيمة. وبالعودة إلى مثال ولي أمرنا:

إن التحولات بين الإجراءات غامضة، حيث يمكن لأي دولة أن تتبع أي دولة أخرى. تم العثور على أولويات العمل في قيم الأداة المساعدة التي تم إرجاعها. إذا كان العدو مرئيًا، وكان ذلك العدو قويًا، وكانت صحة الشخصية منخفضة، فسيقوم كل من Fleeing وFindingHelp بإرجاع قيم عالية غير صفرية. في هذه الحالة، سيكون FindingHelp أعلى دائمًا. وبالمثل، فإن الأنشطة غير القتالية لا تعود أبدًا بأكثر من 50، لذلك ستكون دائمًا أقل من الأنشطة القتالية. يجب أن تأخذ ذلك في الاعتبار عند إنشاء الإجراءات وحساب فائدتها.
في مثالنا، تُرجع الإجراءات إما قيمة ثابتة ثابتة أو إحدى القيمتين الثابتتين. قد يقوم النظام الأكثر واقعية بإرجاع تقدير من نطاق مستمر من القيم. على سبيل المثال، يُرجع إجراء الهروب قيم فائدة أعلى إذا كانت صحة العميل منخفضة، ويعيد إجراء الهجوم قيم فائدة أقل إذا كان العدو قويًا جدًا. ولهذا السبب، فإن إجراء الهروب له الأسبقية على الهجوم في أي موقف يشعر فيه العميل بأنه لا يتمتع بالصحة الكافية لهزيمة العدو. وهذا يسمح بتحديد أولويات الإجراءات بناءً على أي عدد من المعايير، مما يجعل هذا النهج أكثر مرونة وتنوعًا من شجرة السلوك أو ولايات ميكرونيزيا الموحدة.
كل إجراء له العديد من الشروط لحساب البرنامج. يمكن كتابتها بلغة البرمجة النصية أو كسلسلة من الصيغ الرياضية. تضيف لعبة The Sims، التي تحاكي الروتين اليومي للشخصية، طبقة إضافية من الحسابات - يتلقى الوكيل سلسلة من "الدوافع" التي تؤثر على تقييمات المنفعة. إذا كانت الشخصية جائعة، فسوف تصبح أكثر جوعًا بمرور الوقت، وستزداد قيمة المنفعة لإجراء EatFood حتى تنفذه الشخصية، مما يقلل مستوى الجوع ويعيد قيمة EatFood إلى الصفر.
إن فكرة اختيار الإجراءات بناءً على نظام التصنيف بسيطة للغاية، لذا يمكن استخدام النظام القائم على المنفعة كجزء من عمليات صنع القرار في الذكاء الاصطناعي، وليس كبديل كامل لها. قد تطلب شجرة القرار تقييم المنفعة لعقدتين فرعيتين واختيار العقدة الأعلى. وبالمثل، يمكن أن تحتوي شجرة السلوك على عقدة مساعدة مركبة لتقييم فائدة الإجراءات لتحديد الطفل الذي سيتم تنفيذه.
الحركة والملاحة
في الأمثلة السابقة، كان لدينا منصة نحركها يسارًا أو يمينًا، وحارسًا يقوم بدوريات أو مهاجمة. ولكن كيف نتعامل بالضبط مع حركة الوكيل على مدى فترة من الزمن؟ كيف نضبط السرعة، وكيف نتجنب العوائق، وكيف نخطط للمسار عندما يكون الوصول إلى الوجهة أكثر صعوبة من مجرد التحرك في خط مستقيم؟ دعونا ننظر إلى هذا.
إدارة
في المرحلة الأولية، سنفترض أن كل عامل لديه قيمة سرعة، والتي تتضمن مدى سرعة تحركه وفي أي اتجاه. ويمكن قياسها بالأمتار في الثانية، أو الكيلومترات في الساعة، أو البكسل في الثانية، وما إلى ذلك. وبتذكر حلقة Sense/Think/Act، يمكننا أن نتخيل أن جزء Think يحدد السرعة، وأن جزء Act يطبق تلك السرعة على الوكيل. عادةً ما تحتوي الألعاب على نظام فيزيائي يقوم بهذه المهمة نيابةً عنك، حيث يتعلم قيمة سرعة كل كائن ويعدلها. لذلك، يمكنك ترك الذكاء الاصطناعي بمهمة واحدة - تحديد السرعة التي يجب أن يتمتع بها الوكيل. إذا كنت تعرف المكان الذي يجب أن يكون فيه العميل، فأنت بحاجة إلى تحريكه في الاتجاه الصحيح وبسرعة محددة. معادلة تافهة جداً:
Destination_travel = Destination_position – Agent_position
تخيل عالمًا ثنائي الأبعاد. الوكيل عند النقطة (-2،-2)، والوجهة في مكان ما في الشمال الشرقي عند النقطة (2، 30)، والمسار المطلوب للوصول إلى هناك هو (20، 32). لنفترض أن هذه المواضع تُقاس بالأمتار - إذا اعتبرنا أن سرعة العامل هي 22 أمتار في الثانية، فسنقوم بقياس متجه الإزاحة ونحصل على سرعة تقريبًا (5، 4.12). باستخدام هذه المعلمات، سيصل العميل إلى وجهته خلال 2.83 ثوانٍ تقريبًا.
يمكنك إعادة حساب القيم في أي وقت. إذا كان العامل في منتصف الطريق إلى الهدف، فستكون الحركة نصف الطول، ولكن بما أن السرعة القصوى للعميل هي 5 م/ث (قررنا ذلك أعلاه)، فستكون السرعة هي نفسها. يعمل هذا أيضًا مع الأهداف المتحركة، مما يسمح للعميل بإجراء تغييرات صغيرة أثناء تحركه.
لكننا نريد المزيد من التنوع - على سبيل المثال، زيادة السرعة ببطء لمحاكاة شخصية تتحرك من الوقوف إلى الجري. ويمكن فعل الشيء نفسه في النهاية قبل التوقف. تُعرف هذه الميزات بسلوكيات التوجيه، ولكل منها أسماء محددة: البحث، والفرار، والوصول، وما إلى ذلك. والفكرة هي أنه يمكن تطبيق قوى التسارع على سرعة العميل، بناءً على مقارنة موقع العميل وسرعته الحالية مع الوجهة في من أجل استخدام أساليب مختلفة للانتقال إلى الهدف.
كل سلوك له غرض مختلف قليلا. يعد البحث والوصول من الطرق لنقل الوكيل إلى الوجهة. يقوم تجنب العوائق والفصل بضبط حركة العميل لتجنب العوائق في الطريق إلى الهدف. المحاذاة والتماسك يبقيان الوكلاء يتحركون معًا. يمكن تلخيص أي عدد من سلوكيات التوجيه المختلفة لإنتاج متجه مسار واحد مع أخذ جميع العوامل في الاعتبار. وكيل يستخدم سلوكيات الوصول والفصل وتجنب العوائق للابتعاد عن الجدران والوكلاء الآخرين. يعمل هذا الأسلوب بشكل جيد في الأماكن المفتوحة دون تفاصيل غير ضرورية.
في الظروف الأكثر صعوبة، تعمل إضافة سلوكيات مختلفة بشكل أسوأ - على سبيل المثال، يمكن أن يعلق العميل في الحائط بسبب التعارض بين الوصول وتجنب العوائق. ولذلك، تحتاج إلى النظر في الخيارات الأكثر تعقيدًا من مجرد إضافة كافة القيم. الطريقة هي كما يلي: بدلاً من جمع نتائج كل سلوك، يمكنك التفكير في التحرك في اتجاهات مختلفة واختيار الخيار الأفضل.
ومع ذلك، في بيئة معقدة ذات طرق مسدودة وخيارات حول الطريق الذي يجب أن نسلكه، سنحتاج إلى شيء أكثر تقدمًا.
إيجاد طريق
تعتبر سلوكيات التوجيه رائعة بالنسبة للحركة البسيطة في منطقة مفتوحة (ملعب كرة قدم أو ساحة) حيث يكون الوصول من A إلى B عبارة عن مسار مستقيم مع تحويلات بسيطة فقط حول العوائق. بالنسبة للطرق المعقدة، نحتاج إلى اكتشاف المسار، وهو وسيلة لاستكشاف العالم وتحديد طريق عبره.
أبسطها هو تطبيق شبكة على كل مربع بجوار العميل وتقييم أي منهم مسموح له بالتحرك. إذا كان أحدهم وجهة، فاتبع الطريق من كل مربع إلى المربع الذي قبله حتى تصل إلى البداية. هذا هو الطريق. بخلاف ذلك، كرر العملية مع المربعات الأخرى القريبة حتى تجد وجهتك أو تنفد المربعات (مما يعني عدم وجود طريق محتمل). هذا ما يُعرف رسميًا باسم بحث العرض الأول أو BFS (خوارزمية بحث العرض الأول). في كل خطوة ينظر في كل الاتجاهات (ومن هنا اتساع "العرض"). مساحة البحث تشبه واجهة الموجة التي تتحرك حتى تصل إلى الموقع المطلوب - تتسع مساحة البحث في كل خطوة حتى يتم تضمين نقطة النهاية، وبعد ذلك يمكن إرجاعها إلى البداية.
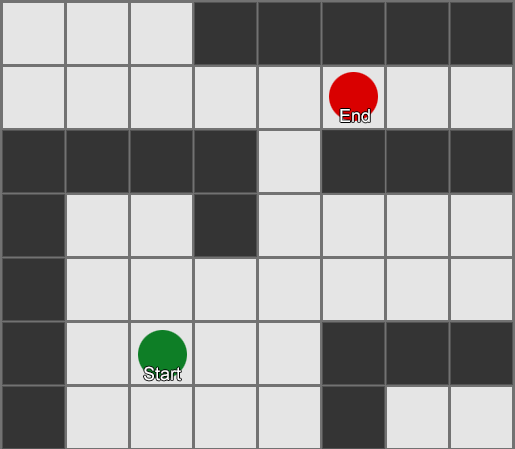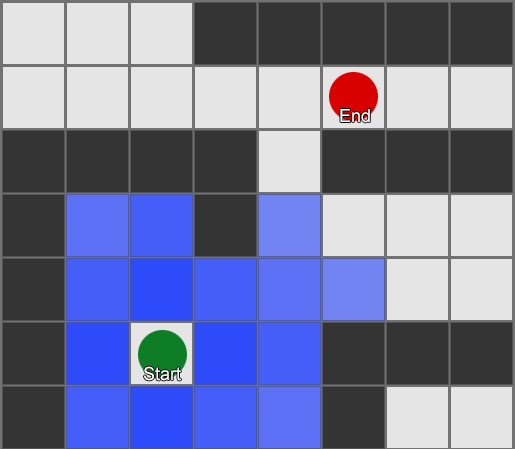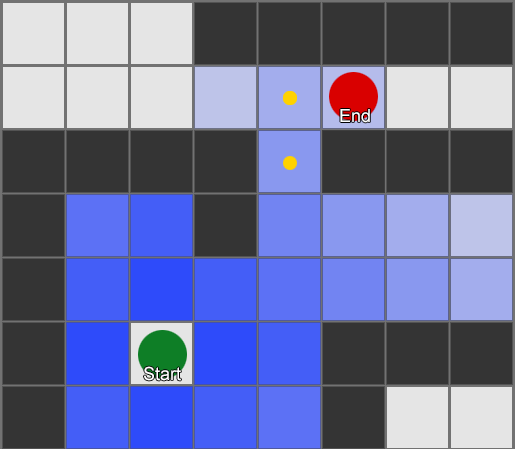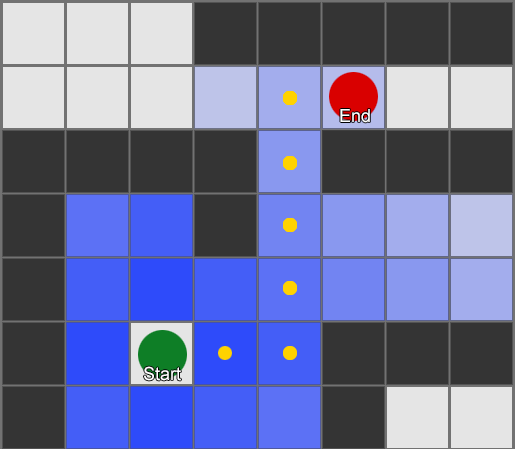
نتيجة لذلك، ستتلقى قائمة بالمربعات التي يتم من خلالها تجميع المسار المطلوب. هذا هو المسار (وبالتالي العثور على المسار) - قائمة الأماكن التي سيزورها الوكيل أثناء متابعة الوجهة.
نظرًا لأننا نعرف موضع كل مربع في العالم، فيمكننا استخدام سلوكيات التوجيه للتحرك على طول المسار - من العقدة 1 إلى العقدة 2، ثم من العقدة 2 إلى العقدة 3، وهكذا. أبسط خيار هو التوجه نحو مركز المربع التالي، لكن الخيار الأفضل هو التوقف في منتصف الحافة بين المربع الحالي والمربع التالي. ولهذا السبب، سيكون الوكيل قادرًا على قطع الزوايا عند المنعطفات الحادة.
لخوارزمية BFS أيضًا عيوب - فهي تستكشف عددًا من المربعات في الاتجاه "الخاطئ" كما هو الحال في الاتجاه "الصحيح". هذا هو المكان الذي تلعب فيه خوارزمية أكثر تعقيدًا تسمى A * (نجمة). إنه يعمل بنفس الطريقة، ولكن بدلاً من الفحص الأعمى لمربعات الجوار (ثم جيران الجيران، ثم جيران جيران الجيران، وما إلى ذلك)، فهو يجمع العقد في قائمة ويفرزها بحيث تكون العقدة التالية التي تم فحصها هي دائمًا العقدة التالية. الذي يؤدي إلى أقصر الطرق. يتم فرز العقد على أساس إرشادي يأخذ في الاعتبار شيئين - "تكلفة" الطريق الافتراضي إلى المربع المطلوب (بما في ذلك أي تكاليف سفر) وتقدير مدى بعد هذا المربع عن الوجهة (تحيز البحث في الاتجاه الصحيح).
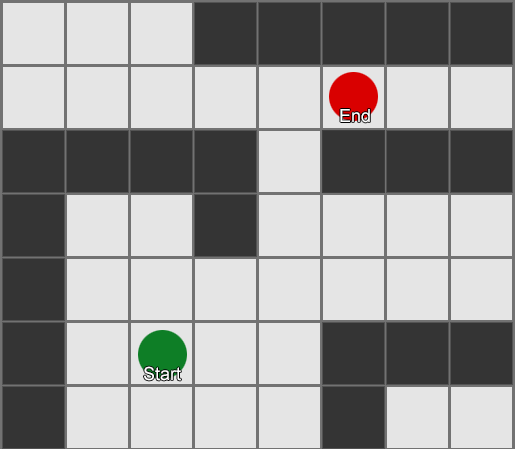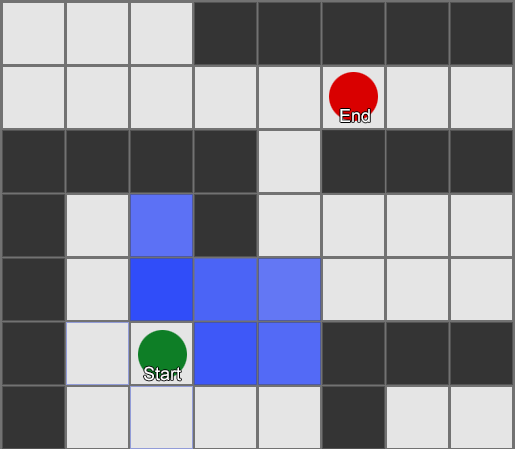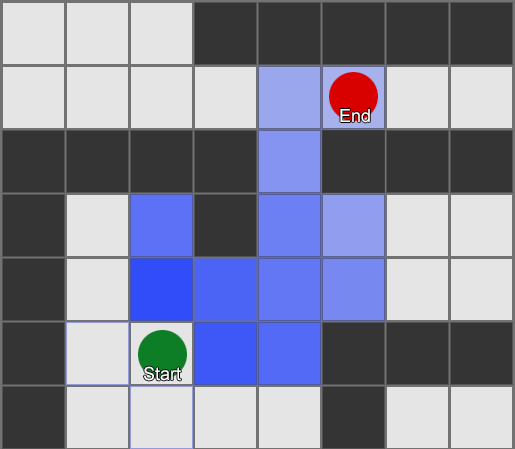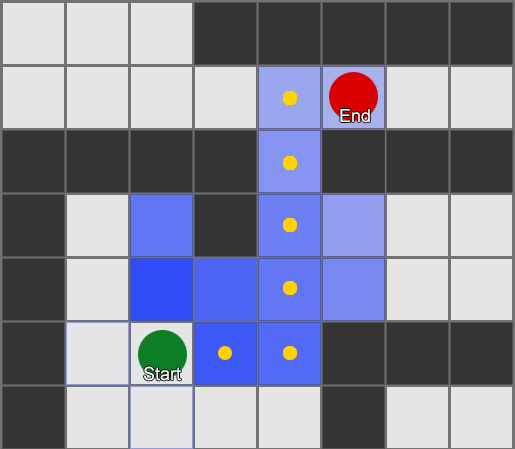
يوضح هذا المثال أن الوكيل يستكشف مربعًا واحدًا في كل مرة، وفي كل مرة يختار المربع المجاور الأكثر وعدًا. المسار الناتج هو نفس مسار BFS، ولكن تم أخذ عدد أقل من المربعات في الاعتبار أثناء العملية - وهو ما له تأثير كبير على أداء اللعبة.
الحركة بدون شبكة
لكن معظم الألعاب لا يتم وضعها على شبكة، وغالبًا ما يكون من المستحيل القيام بذلك دون التضحية بالواقعية. هناك حاجة إلى حلول وسط. ما الحجم الذي يجب أن تكون عليه المربعات؟ كبيرة جدًا ولن تكون قادرة على تمثيل الممرات أو المنعطفات الصغيرة بشكل صحيح، صغيرة جدًا وسيكون هناك الكثير من المربعات للبحث عنها، الأمر الذي سيستغرق الكثير من الوقت في النهاية.
أول شيء يجب أن نفهمه هو أن الشبكة تعطينا رسمًا بيانيًا للعقد المتصلة. تعمل خوارزميات A* وBFS فعليًا على الرسوم البيانية ولا تهتم بشبكتنا على الإطلاق. يمكننا وضع العقد في أي مكان في عالم اللعبة: طالما أن هناك اتصال بين أي عقدتين متصلتين، وكذلك بين نقطتي البداية والنهاية وواحدة على الأقل من العقد، فإن الخوارزمية ستعمل تمامًا كما كانت من قبل. يُطلق على هذا غالبًا اسم نظام إحداثية، نظرًا لأن كل عقدة تمثل موقعًا مهمًا في العالم يمكن أن يكون جزءًا من أي عدد من المسارات الافتراضية.
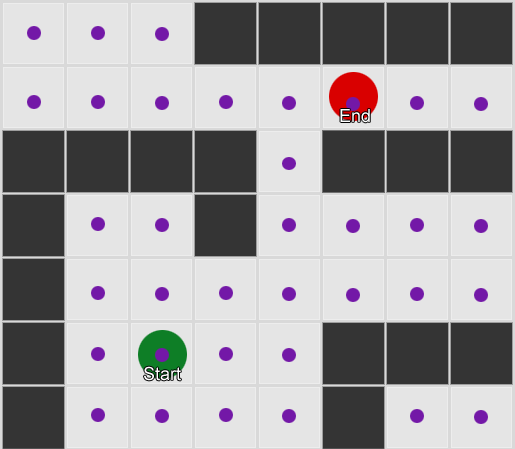
مثال 1: عقدة في كل مربع. يبدأ البحث من العقدة التي يوجد بها الوكيل وينتهي عند عقدة المربع المطلوب.
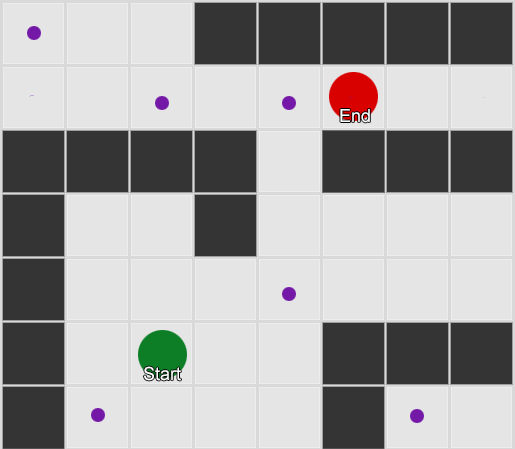
مثال 2: مجموعة أصغر من العقد (الإحداثيات). يبدأ البحث في مربع الوكيل، ويمر بالعدد المطلوب من العقد، ثم يستمر إلى الوجهة.
هذا نظام مرن وقوي تمامًا. ولكن هناك حاجة إلى بعض العناية عند تحديد مكان وكيفية وضع نقطة الطريق، وإلا فقد لا يتمكن الوكلاء ببساطة من رؤية أقرب نقطة ولن يتمكنوا من بدء المسار. سيكون من الأسهل أن نتمكن من وضع نقاط الطريق تلقائيًا بناءً على هندسة العالم.
هذا هو المكان الذي تظهر فيه شبكة التنقل أو شبكة التنقل (شبكة التنقل). عادةً ما تكون هذه شبكة ثنائية الأبعاد من المثلثات المتراكبة على هندسة العالم - أينما يُسمح للوكيل بالسير. يصبح كل مثلث في الشبكة عقدة في الرسم البياني، وله ما يصل إلى ثلاثة مثلثات متجاورة تصبح عقدًا متجاورة في الرسم البياني.
هذه الصورة هي مثال من محرك Unity - حيث قام بتحليل الهندسة في العالم وأنشأ شبكة تنقل (في لقطة الشاشة باللون الأزرق الفاتح). كل مضلع في شبكة التنقل هو منطقة يمكن للوكيل الوقوف فيها أو الانتقال من مضلع إلى مضلع آخر. في هذا المثال، تكون المضلعات أصغر من الطوابق التي تقع عليها - ويتم ذلك من أجل أخذ حجم الوكيل في الاعتبار، والذي سيمتد إلى ما هو أبعد من موضعه الاسمي.

يمكننا البحث عن طريق عبر هذه الشبكة، مرة أخرى باستخدام خوارزمية A*. سيعطينا هذا طريقًا مثاليًا تقريبًا في العالم، والذي يأخذ في الاعتبار جميع الأشكال الهندسية ولا يتطلب عقدًا غير ضرورية وإنشاء نقاط طريق.
يعد البحث عن المسار موضوعًا واسعًا جدًا بحيث لا يكفي قسم واحد من المقالة له. إذا كنت ترغب في دراستها بمزيد من التفصيل، فسيساعدك ذلك .
تخطيط
لقد تعلمنا من خلال اكتشاف المسار أنه في بعض الأحيان لا يكفي مجرد اختيار الاتجاه والتحرك - بل يتعين علينا اختيار طريق والقيام ببعض المنعطفات للوصول إلى وجهتنا المطلوبة. يمكننا تعميم هذه الفكرة: إن تحقيق الهدف ليس مجرد الخطوة التالية، بل هو تسلسل كامل حيث تحتاج أحيانًا إلى النظر إلى الأمام عدة خطوات لمعرفة ما يجب أن تكون عليه الخطوة الأولى. وهذا ما يسمى التخطيط. يمكن اعتبار اكتشاف المسار أحد الامتدادات العديدة للتخطيط. فيما يتعلق بدورة الإحساس/التفكير/الفعل، هذا هو المكان الذي يخطط فيه جزء التفكير لأجزاء متعددة من الفعل في المستقبل.
دعونا نلقي نظرة على مثال لعبة اللوحة Magic: The Gathering. نبدأ أولاً بمجموعة البطاقات التالية في أيدينا:
- المستنقع - يعطي 1 مانا أسود (بطاقة الأرض).
- الغابة - تعطي 1 مانا أخضر (بطاقة الأرض).
- الساحر الهارب - يتطلب 1 مانا زرقاء للاستدعاء.
- Elvish Mystic - يتطلب 1 مانا أخضر للاستدعاء.
نتجاهل البطاقات الثلاث المتبقية لتسهيل الأمر. وفقًا للقواعد، يُسمح للاعب بلعب بطاقة أرض واحدة في كل دور، ويمكنه "النقر" على هذه البطاقة لاستخراج المانا منها، ثم إلقاء التعويذات (بما في ذلك استدعاء مخلوق) وفقًا لكمية المانا. في هذه الحالة، يعرف اللاعب البشري كيفية لعب Forest، والنقر على 1 Green Mana، ثم استدعاء Elvish Mystic. ولكن كيف يمكن للعبة الذكاء الاصطناعي اكتشاف ذلك؟
تخطيط سهل
النهج التافه هو تجربة كل إجراء على حدة حتى لا يتبقى أي إجراء مناسب. من خلال النظر إلى البطاقات، يرى الذكاء الاصطناعي ما يمكن أن يلعبه Swamp. وهو يلعب بها. هل هناك أي إجراءات أخرى تركت هذا المنعطف؟ لا يمكنه استدعاء Elvish Mystic أو Fugitive Wizard، حيث يتطلبان المانا الخضراء والزرقاء على التوالي لاستدعائهما، بينما يوفر Swamp المانا السوداء فقط. ولن يكون قادرا على لعب الغابة، لأنه لعب بالفعل في المستنقع. وهكذا، اتبعت لعبة الذكاء الاصطناعي القواعد، لكنها فعلت ذلك بشكل سيء. يمكن تحسينه.
يمكن أن يجد التخطيط قائمة بالإجراءات التي تصل باللعبة إلى الحالة المطلوبة. مثلما كان لكل مربع على المسار جيران (في تحديد المسار)، فإن كل إجراء في الخطة له أيضًا جيران أو خلفاء. ويمكننا أن نبحث عن هذه الإجراءات والإجراءات اللاحقة حتى نصل إلى الحالة المطلوبة.
في مثالنا، النتيجة المرغوبة هي "استدعاء مخلوق إن أمكن". في بداية الدور، نرى فقط إجراءين محتملين تسمح بهما قواعد اللعبة:
1. العب المستنقع (النتيجة: المستنقع في اللعبة)
2. العب الغابة (النتيجة: غابة في اللعبة)
كل إجراء يتم اتخاذه يمكن أن يؤدي إلى مزيد من الإجراءات وإغلاق الآخرين، مرة أخرى اعتمادًا على قواعد اللعبة. تخيل أننا لعبنا Swamp - سيؤدي هذا إلى إزالة Swamp كخطوة تالية (لقد لعبناها بالفعل)، وسيؤدي هذا أيضًا إلى إزالة Forest (لأنه وفقًا للقواعد، يمكنك لعب بطاقة أرض واحدة في كل دور). بعد ذلك، يضيف الذكاء الاصطناعي الحصول على 1 مانا أسود كخطوة تالية لأنه لا توجد خيارات أخرى. إذا مضى قدمًا واختار النقر على المستنقع، فسيحصل على وحدة واحدة من المانا السوداء ولن يتمكن من فعل أي شيء بها.
1. العب المستنقع (النتيجة: المستنقع في اللعبة)
1.1 مستنقع "النقر" (النتيجة: مستنقع "النقر"، +1 وحدة من المانا السوداء)
لا توجد إجراءات متاحة - انتهى
2. العب الغابة (النتيجة: غابة في اللعبة)
قائمة الإجراءات كانت قصيرة، وصلنا إلى طريق مسدود. نكرر العملية للخطوة التالية. نحن نلعب لعبة Forest، ونفتح الإجراء "احصل على 1 Green Mana"، والذي بدوره سيفتح الإجراء الثالث - استدعاء Elvish Mystic.
1. العب المستنقع (النتيجة: المستنقع في اللعبة)
1.1 مستنقع "النقر" (النتيجة: مستنقع "النقر"، +1 وحدة من المانا السوداء)
لا توجد إجراءات متاحة - انتهى
2. العب الغابة (النتيجة: غابة في اللعبة)
2.1 "النقر" على الغابة (النتيجة: "النقر على الغابة"، +1 وحدة من المانا الخضراء)
2.1.1 استدعاء Elvish Mystic (النتيجة: Elvish Mystic في اللعب، -1 مانا أخضر)
لا توجد إجراءات متاحة - انتهى
أخيرًا، استكشفنا جميع الإجراءات الممكنة ووجدنا خطة لاستدعاء مخلوق.
هذا مثال مبسط للغاية. يُنصح باختيار أفضل خطة ممكنة، بدلاً من مجرد أي خطة تلبي بعض المعايير. من الممكن عمومًا تقييم الخطط المحتملة بناءً على النتيجة أو الفائدة العامة من تنفيذها. يمكنك تسجيل نقطة واحدة لنفسك عند لعب بطاقة الأرض و1 نقاط عند استدعاء مخلوق. لعب Swamp سيكون عبارة عن خطة مكونة من نقطة واحدة. ولعب الغابة → اضغط على الغابة → استدعاء Elvish Mystic سيمنحك 3 نقاط على الفور.
هذه هي الطريقة التي يعمل بها التخطيط في Magic: The Gathering، لكن نفس المنطق ينطبق في مواقف أخرى. على سبيل المثال، تحريك البيدق لإفساح المجال أمام الفيل للتحرك في لعبة الشطرنج. أو احتمي خلف الحائط للتصوير بأمان في XCOM مثل هذا. على العموم وصلتك الفكرة
تحسين التخطيط
في بعض الأحيان يكون هناك عدد كبير جدًا من الإجراءات المحتملة للنظر في كل خيار ممكن. بالعودة إلى المثال مع Magic: The Gathering: لنفترض أنه يوجد في اللعبة وفي يدك العديد من بطاقات الأرض والمخلوقات - يمكن أن يكون عدد المجموعات المحتملة من الحركات بالعشرات. هناك عدة حلول لهذه المشكلة.
الطريقة الأولى هي التسلسل إلى الوراء. بدلاً من تجربة جميع المجموعات، من الأفضل أن تبدأ بالنتيجة النهائية وتحاول إيجاد طريق مباشر. فبدلاً من الانتقال من جذر الشجرة إلى ورقة معينة، نتحرك في الاتجاه المعاكس - من الورقة إلى الجذر. هذه الطريقة أسهل وأسرع.
إذا كان لدى العدو صحة واحدة، فيمكنك العثور على خطة "التعامل مع ضرر واحد أو أكثر". ولتحقيق ذلك يجب استيفاء عدد من الشروط:
1. يمكن أن يحدث الضرر بسبب تعويذة - يجب أن تكون في متناول اليد.
2. لإلقاء تعويذة، تحتاج إلى مانا.
3. للحصول على المانا، عليك أن تلعب بطاقة الأرض.
4. للعب بطاقة الأرض، يجب أن تكون في يدك.
هناك طريقة أخرى وهي البحث الأفضل أولاً. فبدلاً من تجربة كل الطرق، نختار أنسبها. في أغلب الأحيان، توفر هذه الطريقة الخطة المثالية دون تكاليف بحث غير ضرورية. A* هو شكل من أشكال البحث الأول الأفضل - من خلال فحص المسارات الواعدة من البداية، يمكنه بالفعل العثور على أفضل مسار دون الحاجة إلى التحقق من الخيارات الأخرى.
خيار البحث الأفضل الأول المثير للاهتمام والذي يحظى بشعبية متزايدة هو Monte Carlo Tree Search. بدلاً من تخمين الخطط الأفضل من غيرها عند اختيار كل إجراء لاحق، تختار الخوارزمية خلفاء عشوائيين في كل خطوة حتى تصل إلى النهاية (عندما تؤدي الخطة إلى النصر أو الهزيمة). يتم بعد ذلك استخدام النتيجة النهائية لزيادة أو تقليل وزن الخيارات السابقة. من خلال تكرار هذه العملية عدة مرات متتالية، تعطي الخوارزمية تقديرًا جيدًا لأفضل خطوة تالية، حتى لو تغير الوضع (إذا اتخذ العدو إجراءً للتدخل في اللاعب).
لن تكتمل أي قصة حول التخطيط في الألعاب بدون تخطيط العمل الموجه نحو الأهداف أو GOAP (تخطيط العمل الموجه نحو الأهداف). هذه طريقة مستخدمة ومناقشتها على نطاق واسع، ولكن بخلاف بعض التفاصيل المميزة، فهي في الأساس طريقة التسلسل العكسي التي تحدثنا عنها سابقًا. إذا كان الهدف هو "تدمير اللاعب" وكان اللاعب خلف الغطاء، فقد تكون الخطة كما يلي: التدمير بقنبلة يدوية ← احصل عليها ← ارميها.
عادة ما تكون هناك عدة أهداف، ولكل منها الأولوية الخاصة به. إذا تعذر إكمال الهدف ذي الأولوية الأعلى (لا تؤدي مجموعة من الإجراءات إلى إنشاء خطة "قتل اللاعب" لأن اللاعب غير مرئي)، فسيعود الذكاء الاصطناعي إلى الأهداف ذات الأولوية الأقل.
التدريب والتكيف
لقد قلنا بالفعل أن لعبة الذكاء الاصطناعي عادةً لا تستخدم التعلم الآلي لأنها غير مناسبة لإدارة الوكلاء في الوقت الفعلي. لكن هذا لا يعني أنه لا يمكنك استعارة شيء ما من هذه المنطقة. نريد خصمًا في لعبة إطلاق النار يمكننا أن نتعلم منه شيئًا. على سبيل المثال، تعرف على أفضل المواقع على الخريطة. أو خصم في لعبة قتال من شأنه أن يمنع اللاعب من التحركات المجمعة المستخدمة بشكل متكرر، مما يحفزه على استخدام الآخرين. لذلك يمكن أن يكون التعلم الآلي مفيدًا جدًا في مثل هذه المواقف.
الإحصائيات والاحتمالات
قبل أن ندخل في الأمثلة المعقدة، دعونا نرى إلى أي مدى يمكننا الذهاب من خلال أخذ بعض القياسات البسيطة واستخدامها لاتخاذ القرارات. على سبيل المثال، استراتيجية الوقت الفعلي - كيف نحدد ما إذا كان اللاعب يمكنه شن هجوم في الدقائق القليلة الأولى من المباراة وما هو الدفاع الذي يجب الاستعداد ضده؟ يمكننا دراسة تجارب اللاعب السابقة لفهم ردود الفعل المستقبلية. في البداية، ليس لدينا مثل هذه البيانات الأولية، ولكن يمكننا جمعها - في كل مرة يلعب فيها الذكاء الاصطناعي ضد إنسان، يمكنه تسجيل وقت الهجوم الأول. بعد بضع جلسات، سنحصل على متوسط الوقت الذي سيستغرقه اللاعب للهجوم في المستقبل.
هناك أيضًا مشكلة في القيم المتوسطة: إذا اندفع اللاعب 20 مرة ولعب ببطء 20 مرة، فستكون القيم المطلوبة في مكان ما في المنتصف، وهذا لن يقدم لنا أي شيء مفيد. أحد الحلول هو الحد من بيانات الإدخال - حيث يمكن أخذ آخر 20 قطعة في الاعتبار.
يتم استخدام نهج مماثل عند تقدير احتمالية إجراءات معينة من خلال افتراض أن تفضيلات اللاعب السابقة ستكون هي نفسها في المستقبل. إذا هاجمنا أحد اللاعبين خمس مرات بكرة نارية، ومرتين بالبرق، ومرة بالمشاجرة، فمن الواضح أنه يفضل الكرة النارية. دعونا نستقرئ ونرى احتمالية استخدام أسلحة مختلفة: الكرة النارية = 62,5%، البرق = 25%، والمشاجرة = 12,5%. تحتاج لعبتنا AI إلى الاستعداد لحماية نفسها من النار.
هناك طريقة أخرى مثيرة للاهتمام وهي استخدام Naive Bayes Classifier لدراسة كميات كبيرة من البيانات المدخلة وتصنيف الموقف بحيث يتفاعل الذكاء الاصطناعي بالطريقة المطلوبة. تشتهر المصنفات الافتراضية باستخدامها في مرشحات البريد الإلكتروني العشوائي. وهناك يقومون بفحص الكلمات، ومقارنتها بالمكان الذي ظهرت فيه هذه الكلمات من قبل (في البريد العشوائي أم لا)، واستخلاص استنتاجات حول رسائل البريد الإلكتروني الواردة. يمكننا أن نفعل الشيء نفسه حتى مع مدخلات أقل. بناءً على جميع المعلومات المفيدة التي يراها الذكاء الاصطناعي (مثل ما هي وحدات العدو التي يتم إنشاؤها، أو ما هي التعويذات التي يستخدمونها، أو ما هي التقنيات التي بحثوا عنها)، والنتيجة النهائية (الحرب أو السلام، الاندفاع أو الدفاع، وما إلى ذلك) - سنختار سلوك الذكاء الاصطناعي المطلوب.
كل هذه الأساليب التدريبية كافية، لكن يُنصح باستخدامها بناءً على بيانات الاختبار. سيتعلم الذكاء الاصطناعي التكيف مع الاستراتيجيات المختلفة التي استخدمها مختبرو اللعب لديك. قد يصبح الذكاء الاصطناعي الذي يتكيف مع اللاعب بعد إطلاق سراحه قابلاً للتنبؤ به للغاية أو يصعب هزيمته.
التكيف على أساس القيمة
بالنظر إلى محتوى عالم لعبتنا وقواعدها، يمكننا تغيير مجموعة القيم التي تؤثر على اتخاذ القرار، بدلاً من مجرد استخدام البيانات المدخلة. نحن نفعل هذا:
- اسمح للذكاء الاصطناعي بجمع البيانات عن حالة العالم والأحداث الرئيسية أثناء اللعبة (كما هو مذكور أعلاه).
- دعونا نغير بعض القيم المهمة بناءً على هذه البيانات.
- نحن ننفذ قراراتنا بناءً على معالجة أو تقييم هذه القيم.
على سبيل المثال، لدى العميل عدة غرف للاختيار من بينها على خريطة مطلق النار من منظور الشخص الأول. كل غرفة لها قيمتها الخاصة، والتي تحدد مدى الرغبة في زيارتها. يختار الذكاء الاصطناعي بشكل عشوائي الغرفة التي سيذهب إليها بناءً على القيمة. ثم يتذكر العميل الغرفة التي قُتل فيها ويقلل من قيمتها (احتمال عودته إلى هناك). وبالمثل بالنسبة للوضع العكسي - إذا قام العميل بتدمير العديد من المعارضين، فإن قيمة الغرفة تزيد.
نموذج ماركوف
ماذا لو استخدمنا البيانات المجمعة لعمل تنبؤات؟ إذا تذكرنا كل غرفة نرى فيها لاعبًا لفترة زمنية معينة، فسنتوقع الغرفة التي قد يذهب إليها اللاعب. من خلال تتبع وتسجيل تحركات اللاعب عبر الغرف (القيم)، يمكننا التنبؤ بها.
لنأخذ ثلاث غرف: الأحمر والأخضر والأزرق. وأيضاً الملاحظات التي سجلناها أثناء مشاهدة جلسة المباراة:
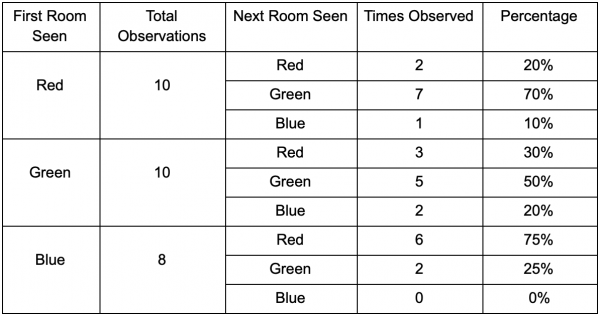
عدد الملاحظات في كل غرفة متساوٍ تقريبًا - ما زلنا لا نعرف أين نصنع مكانًا جيدًا للكمين. يعد جمع الإحصائيات أمرًا معقدًا أيضًا بسبب عودة اللاعبين إلى الحياة، والذين يظهرون بالتساوي في جميع أنحاء الخريطة. لكن البيانات المتعلقة بالغرفة التالية التي يدخلونها بعد ظهورها على الخريطة مفيدة بالفعل.
يمكن ملاحظة أن الغرفة الخضراء تناسب اللاعبين - ينتقل معظم الأشخاص من الغرفة الحمراء إليها، ويبقى 50٪ منهم هناك. على العكس من ذلك، لا تحظى الغرفة الزرقاء بشعبية كبيرة، فلا أحد تقريبًا يذهب إليها، وإذا فعلوا ذلك، فإنهم لا يبقون طويلاً.
لكن البيانات تخبرنا بشيء أكثر أهمية - عندما يكون اللاعب في غرفة زرقاء، فإن الغرفة التالية التي نراه فيها ستكون حمراء وليست خضراء. على الرغم من أن الغرفة الخضراء أكثر شعبية من الغرفة الحمراء، إلا أن الوضع يتغير إذا كان اللاعب في الغرفة الزرقاء. تعتمد الحالة التالية (أي الغرفة التي سيذهب إليها اللاعب) على الحالة السابقة (أي الغرفة التي يتواجد فيها اللاعب حاليًا). ولأننا نستكشف التبعيات، فسوف نقوم بتنبؤات أكثر دقة مما لو قمنا ببساطة بإحصاء الملاحظات بشكل مستقل.
إن التنبؤ بحالة مستقبلية بناءً على بيانات من حالة سابقة يسمى نموذج ماركوف، وتسمى هذه الأمثلة (مع الغرف) بسلاسل ماركوف. وبما أن الأنماط تمثل احتمالية التغييرات بين الحالات المتعاقبة، يتم عرضها بصريًا على أنها ولايات ميكرونيزيا الموحدة مع احتمال حول كل انتقال. في السابق، استخدمنا FSM لتمثيل الحالة السلوكية التي كان فيها الوكيل، لكن هذا المفهوم يمتد إلى أي حالة، سواء كانت مرتبطة بالعامل أم لا. في هذه الحالة، تمثل الولايات الغرفة التي يشغلها الوكيل:
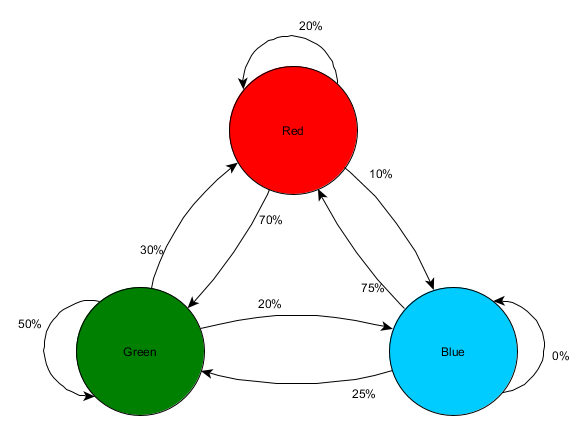
هذه طريقة بسيطة لتمثيل الاحتمالية النسبية لتغييرات الحالة، مما يمنح الذكاء الاصطناعي بعض القدرة على التنبؤ بالحالة التالية. يمكنك توقع عدة خطوات للأمام.
إذا كان اللاعب في الغرفة الخضراء، فهناك احتمال بنسبة 50% أن يبقى هناك في المرة التالية التي تتم مراقبته فيها. ولكن ما هي احتمالات بقائه هناك حتى بعد ذلك؟ ليس هناك احتمال أن يبقى اللاعب في الغرفة الخضراء بعد ملاحظتين فحسب، بل هناك أيضًا احتمال أن يغادر ويعود. وهذا هو الجدول الجديد مع الأخذ في الاعتبار البيانات الجديدة:
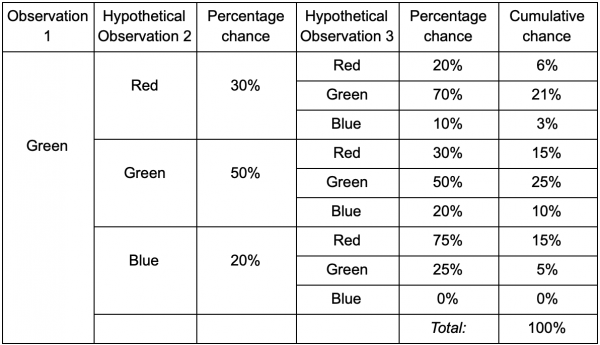
ويظهر أن فرصة رؤية اللاعب في الغرفة الخضراء بعد ملاحظتين ستكون تساوي 51% – 21% أنه سيكون من الغرفة الحمراء، 5% منهم أن اللاعب سيزور الغرفة الزرقاء بينهما، و 25% أن اللاعب لن يغادر الغرفة الخضراء.
الجدول هو مجرد أداة مرئية - الإجراء يتطلب فقط مضاعفة الاحتمالات في كل خطوة. هذا يعني أنه يمكنك التطلع بعيدًا إلى المستقبل بتحذير واحد: نحن نفترض أن فرصة دخول الغرفة تعتمد كليًا على الغرفة الحالية. وهذا ما يسمى خاصية ماركوف - الحالة المستقبلية تعتمد فقط على الحاضر. لكن هذا ليس دقيقًا بنسبة مائة بالمائة. يمكن للاعبين تغيير قراراتهم اعتمادًا على عوامل أخرى: مستوى الصحة أو كمية الذخيرة. ولأننا لا نسجل هذه القيم، فإن توقعاتنا ستكون أقل دقة.
N- غرام
ماذا عن مثال لعبة القتال والتنبؤ بحركات التحرير والسرد للاعب؟ نفس الشيء! ولكن بدلاً من حالة أو حدث واحد، سوف نقوم بفحص التسلسلات الكاملة التي تشكل ضربة التحرير والسرد.
إحدى الطرق للقيام بذلك هي تخزين كل إدخال (مثل Kick أو Punch أو Block) في مخزن مؤقت وكتابة المخزن المؤقت بأكمله كحدث. لذلك يضغط اللاعب بشكل متكرر على Kick، Kick، Punch لاستخدام هجوم SuperDeathFist، ويقوم نظام الذكاء الاصطناعي بتخزين جميع المدخلات في مخزن مؤقت ويتذكر آخر ثلاثة مدخلات مستخدمة في كل خطوة.
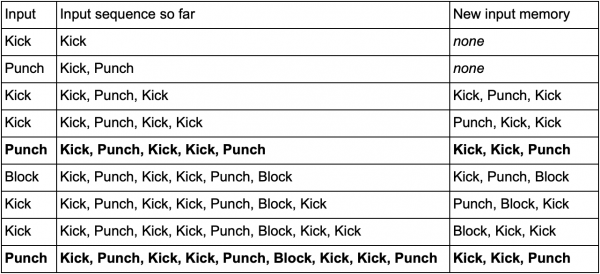
(الخطوط بالخط العريض تظهر عندما يقوم اللاعب بشن هجوم SuperDeathFist.)
سيرى الذكاء الاصطناعي جميع الخيارات عندما يختار اللاعب ركلة، تليها ركلة أخرى، ثم يلاحظ أن الإدخال التالي هو اللكمة دائمًا. سيسمح هذا للوكيل بالتنبؤ بحركة التحرير والسرد لـ SuperDeathFist وحظرها إن أمكن.
تسمى تسلسلات الأحداث هذه N-grams، حيث N هو عدد العناصر المخزنة. في المثال السابق كان 3 جرام (ثلاثي جرام)، مما يعني: يتم استخدام المدخلين الأولين للتنبؤ بالثالث. وفقا لذلك، في 5 جرام، تتنبأ الإدخالات الأربعة الأولى بالخامس وما إلى ذلك.
يحتاج المصمم إلى اختيار حجم N-grams بعناية. يتطلب N الأصغر ذاكرة أقل ولكنه يخزن أيضًا تاريخًا أقل. على سبيل المثال، سيسجل 2 جرام (bigram) Kick أو Kick أو Kick، Punch، لكنه لن يتمكن من تخزين Kick، Kick، Punch، لذلك لن يستجيب الذكاء الاصطناعي لمجموعة SuperDeathFist.
من ناحية أخرى، تتطلب الأرقام الأكبر مساحة أكبر من الذاكرة وسيكون تدريب الذكاء الاصطناعي أكثر صعوبة نظرًا لوجود العديد من الخيارات الممكنة. إذا كان لديك ثلاثة مدخلات محتملة وهي Kick أو Punch أو Block، واستخدمنا 10 جرام، فسيكون ذلك حوالي 60 ألف خيار مختلف.
نموذج البيجرام عبارة عن سلسلة ماركوف بسيطة - كل زوج من الحالة الماضية/الحالة الحالية هو بيجرام، ويمكنك التنبؤ بالحالة الثانية بناءً على الحالة الأولى. يمكن أيضًا اعتبار 3 جرام أو N-grams أكبر كسلاسل ماركوف، حيث تشكل جميع العناصر (ما عدا العنصر الأخير في N-gram) معًا الحالة الأولى والعنصر الأخير في الحالة الثانية. يوضح مثال لعبة القتال فرصة الانتقال من حالة الركلة والركلة إلى حالة الركلة واللكمة. من خلال التعامل مع إدخالات سجل الإدخال المتعددة كوحدة واحدة، فإننا نقوم بشكل أساسي بتحويل تسلسل الإدخال إلى جزء من الحالة بأكملها. وهذا يعطينا خاصية ماركوف، والتي تسمح لنا باستخدام سلاسل ماركوف للتنبؤ بالمدخل التالي وتخمين حركة التحرير والسرد التالية.
اختتام
تحدثنا عن الأدوات والأساليب الأكثر شيوعًا في تطوير الذكاء الاصطناعي. لقد نظرنا أيضًا في المواقف التي يجب استخدامها فيها وأين تكون مفيدة بشكل خاص.
يجب أن يكون هذا كافيًا لفهم أساسيات لعبة الذكاء الاصطناعي. ولكن، بالطبع، هذه ليست كل الأساليب. أقل شعبية، ولكن ليس أقل فعالية ما يلي:
- خوارزميات التحسين بما في ذلك تسلق التلال والنسب التدرج والخوارزميات الجينية
- خوارزميات البحث/الجدولة العدائية (تقليص الحد الأدنى وألفا بيتا)
- طرق التصنيف (الإدراك الحسي والشبكات العصبية وآلات ناقل الدعم)
- أنظمة معالجة الإدراك والذاكرة لدى الوكلاء
- الأساليب المعمارية للذكاء الاصطناعي (الأنظمة الهجينة، وهندسة المجموعات الفرعية وطرق أخرى لتراكب أنظمة الذكاء الاصطناعي)
- أدوات الرسوم المتحركة (التخطيط وتنسيق الحركة)
- عوامل الأداء (مستوى التفاصيل، في أي وقت، وخوارزميات تقسيم الوقت)
موارد الإنترنت حول الموضوع:
1. لدى GameDev.net و .
2. يحتوي على العديد من العروض التقديمية والمقالات حول مجموعة واسعة من المواضيع المتعلقة بتطوير الذكاء الاصطناعي للألعاب.
3. يتضمن موضوعات من GDC AI Summit، والعديد منها متاح مجانًا.
4. يمكن أيضًا العثور على مواد مفيدة على الموقع الإلكتروني .
5. تومي طومسون، باحث في مجال الذكاء الاصطناعي ومطور ألعاب، يصنع مقاطع فيديو على موقع YouTube مع شرح ودراسة الذكاء الاصطناعي في الألعاب التجارية.
الكتب المتعلقة بالموضوع:
1. سلسلة كتب Game AI Pro عبارة عن مجموعة من المقالات القصيرة التي تشرح كيفية تنفيذ ميزات محددة أو كيفية حل مشكلات معينة.
2. سلسلة حكمة برمجة ألعاب الذكاء الاصطناعي هي سلف سلسلة Game AI Pro. فهو يحتوي على أساليب قديمة، ولكن جميعها تقريبا ذات صلة حتى اليوم.
3. يعد أحد النصوص الأساسية لكل من يريد فهم المجال العام للذكاء الاصطناعي. هذا ليس كتابًا عن تطوير الألعاب - فهو يعلم أساسيات الذكاء الاصطناعي.
المصدر: www.habr.com
