

Артыкул складаецца з дзвюх частак:
- Кароткае апісанне некаторых архітэктур сетак па выяўленні аб'ектаў на малюнку і сегментацыі малюнкаў з самымі зразумелымі для мяне спасылкамі на рэсурсы. Імкнуўся выбіраць відэа тлумачэнні і пажадана на рускай мове.
- Другая частка складаецца ў спробе ўсвядоміць кірунак развіцця архітэктур нейронавых сетак. І тэхналогій на іх аснове.

Малюнак 1 – Разумець архітэктуры нейросетей няпроста
Все началось с того, что сделал два демонстрационных приложения по классификации и обнаружению объектов на телефоне Android:
- , калі дадзеныя апрацоўваюцца на сэрвэры і перадаюцца на тэлефон. Класіфікацыя відарысаў (image classification) трох тыпаў мядзведзяў: бурага, чорнага і плюшавага.
- , калі дадзеныя апрацоўваюцца на самым тэлефоне. Выяўленне аб'ектаў (object detection) трох тыпаў: фундук, інжыр і фінік.
Ёсць розніца паміж задачамі па класіфікацыі малюнкаў, выяўленні аб'ектаў на малюнку і . Таму з'явілася неабходнасць даведацца, якія архітэктуры нейросетей выяўляюць аб'екты на выявах і якія могуць сегментаваць. Знайшоў наступныя прыклады архітэктур з самымі зразумелымі для мяне спасылкамі на рэсурсы:
- Серыя архітэктур на аснове R-CNN (Regions with Convolution Neural Networks features): R-CNN, Fast R-CNN, , . Для выяўлення аб'екта на малюнку з дапамогай механізму Region Proposal Network (RPN) вылучаюцца абмежаваныя рэгіёны (2000). ўнутраную сетку AlexNet. З-за відавочных цыклаў «for» запавольваецца хуткасць апрацоўкі малюнкаў.
- (You Oтолькі Lтаксама Once) - першая нейронавая сетка, якая распазнавала аб'екты ў рэальным часе на мабільных прыладах. Адметная асаблівасць: распазнаванне аб'ектаў за адзін прагон (досыць адзін раз паглядзець). Гэта значыць у архітэктуры YOLO няма відавочных цыклаў "for", з-за чаго сетка працуе хутка. Напрыклад, такая аналогія: у NumPy пры аперацыях з матрыцамі таксама няма відавочных цыклаў "for", якія ў NumPy рэалізуюцца на ніжэйшых узроўнях архітэктуры праз мову праграмавання З. YOLO выкарыстоўвае сетку з загадзя зададзеных вокнаў. Каб адзін і той жа аб'ект не вызначаўся шматкроць, выкарыстоўваецца каэфіцыент перакрыцця вокнаў (IoU, Intersection oвер Union). Дадзеная архітэктура працуе ў шырокім дыяпазоне і валодае высокай : мадэль можа быць навучана на фатаграфіях, але пры гэтым добра працаваць на маляваных карцінах.
- (Sагонь у ачагу Shot MultiBox Detector) – выкарыстоўваюцца найболей удалыя «хакі» архітэктуры YOLO (напрыклад, non-maximum suppression) і дадаюцца новыя, каб нейросетка хутчэй і дакладней працавала. Адметная асаблівасць: адрозніванне аб'ектаў за адзін прагон з дапамогай зададзенай сеткі вокнаў (default box) на пірамідзе малюнкаў. Піраміда малюнкаў закадавана ў скруткавых тэнзарах пры паслядоўных аперацыях скруткі і пулінга (пры аперацыі max-pooling прасторавая памернасць меншае). Такім чынам вызначаюцца як вялікія, так і маленькія аб'екты за адзін прагон сеткі.
- MobileSSD (мабільныNetV2 + SSD) - камбінацыя з двух архітэктур нейросетей. Першая сетка працуе хутка і павялічвае дакладнасць распазнання. MobileNetV2 прымяняецца замест VGG-16, якая першапачаткова выкарыстоўвалася ў . Другая сетка SSD вызначае месцазнаходжанне аб'ектаў на малюнку.
- - Вельмі маленькая, але дакладная нейросетка. Сама па сабе не вырашае задачу выяўлення аб'ектаў. Аднак можа прымяняцца пры камбінацыі розных архітэктур. І выкарыстоўвацца ў мабільных прыладах. Адметнай асаблівасцю з'яўляецца тое, што спачатку дадзеныя сціскаюцца да чатырох 1×1 скруткавых фільтраў, а затым пашыраюцца да чатырох 1×1 і чатырох 3×3 скруткавых фільтраў. Адна такая ітэрацыя сціску-пашырэння дадзеных завецца "Fire Module".
- (Semantic Image Segmentation with Deep Convolutional Nets) - сегментацыя аб'ектаў на малюнку. Адметнай асаблівасцю архітэктуры з'яўляецца разраджаная (dilated convolution) скрутка, якая захоўвае прасторавы дазвол. Затым варта стадыя постапрацоўкі вынікаў з выкарыстаннем графічнай імавернаснай мадэлі (conditional random field), што дазваляе прыбраць невялікія шумы ў сегментацыі і палепшыць якасць адсегментаванай выявы. За грознай назвай "графічная імавернасная мадэль" хаваецца звычайны фільтр Гаўса, які апраксімаваны па пяці кропках.
- Спрабаваў разабрацца ў прыладзе (Single-Shot удасканаліцьment Neural Network for Object Detection), але мала чаго зразумеў.
- Таксама паглядзеў, як працуе тэхналогія "ўвага" (attention): , , . Адметнай асаблівасцю архітэктуры "ўвага" з'яўляецца аўтаматычнае выдзяленне рэгіёнаў павышанай увагі на малюнку (RoI, Rэгіёны of Interest) з дапамогай нейрасеткі пад назвай Attention Unit. Рэгіёны павышанай увагі падобныя да абмежаваных рэгіёнаў (bounding boxes), але ў адрозненне ад іх не зафіксаваны на малюнку і могуць мець размытыя межы. Затым з рэгіёнаў падвышанай увагі вылучаюцца прыкметы (фічы), якія "скормліваюцца" рэкурэнтным нейрасецям з архітэктурамі. Рэкурэнтныя нейрасеці ўмеюць аналізаваць узаемаадносіны прыкмет у паслядоўнасці. и .
Па меры вывучэння гэтых архітэктур я зразумеў, што нічога не разумею. І справа не ў тым, што ў маёй нейрасеці ёсць праблемы з механізмам увагі. Стварэнне ўсіх гэтых архітэктур падобна на нейкі вялізны хакатон, дзе аўтары спаборнічаюць у хаках. Хак (hack) - хуткае рашэнне цяжкай праграмнай задачы. Гэта значыць, паміж усімі гэтымі архітэктурамі няма бачнай і зразумелай лагічнай сувязі. Усё, што іх аб'ядноўвае - гэта набор найболей удалых хакаў, якія яны запазычаюць сябар у сябра, плюс агульная для ўсіх (зваротнае распаўсюджванне памылкі, backpropagation). Не ! Не зразумела, што мяняць і як аптымізаваць існуючыя дасягненні.
Як вынік адсутнасці лагічнай сувязі паміж хакамі, іх надзвычай цяжка запомніць і прымяніць на практыцы. Гэта фрагментаваныя веды. У лепшым выпадку запамінаюцца некалькі цікавых і нечаканых момантаў, але большасць з зразуметага і незразумелага знікае з памяці ўжо праз некалькі дзён. Будзе добра, калі праз тыдзень успомніцца хаця б назва архітэктуры. А бо на чытанне артыкулаў і прагляд аглядных відэа было выдаткавана некалькі гадзін і нават дзён працоўнага часу!
Малюнак 2 –
Большасць аўтараў навуковых артыкулаў, на маю асабістую думку, робяць усё магчымае, каб нават гэтыя фрагментаваныя веды былі не зразуметыя чытачом. Але дзеепрыслоўныя абароты ў дзесяці радковых сказах з формуламі, якія ўзяты "са столі" - гэта тэма для асобнага артыкула (праблема ).
Па гэтай прычыне з'явілася неабходнасць сістэматызаваць інфармацыю па нейрасецях і, такім чынам, павялічыць якасць разумення і запамінання. Таму асноўнай тэмай разбору асобных тэхналогій і архітэктур штучных нейронавых сетак стала наступная задача: даведацца, куды гэта ўсё рухаецца, а не прылада нейкай канкрэтнай нейрасеці ў асобнасці.
Куды ўсё гэта рухаецца.
- Колькасць стартапаў у галіне машыннага навучання ў апошнія два гады . Магчымая прычына: "нейронныя сеткі перасталі быць чымсьці новым".
- Кожны зможа стварыць працуючую нейросетку для рашэння простай задачы. Для гэтага возьме гатовую мадэль з «заапарка мадэляў» (model zoo) і натрэніруе апошні пласт нейрасеткі () на гатовых дадзеных з або з у бясплатным .
- Буйныя вытворцы нейрасетак пачалі ствараць «заапаркі мадэляў» (model zoo). З дапамогай іх можна хутка зрабіць камерцыйнае прыкладанне: для TensorFlow, для PyTorch, для Caffe2, для Chainer і .
- Нейрасеткі, якія працуюць у рэальным часе (real-time) на мабільных прыладах. Ад 10 да 50 кадраў за секунду.
- Ужыванне нейрасетак у тэлефонах (TF Lite), у браўзэрах (TF.js) і ў (IoT, Iternet of Things). Асабліва ў тэлефонах, якія ўжо падтрымліваюць нейрасеці на ўзроўні «жалеза» (нейраакселератары).
- «Кожная прылада, прадметы адзення і, магчыма, нават ежа будуць мець IP-v6 адрас і паведамляцца паміж сабой» – .
- Рост колькасці публікацый па машынным навучанні пачаў (падваенне кожныя два гады) з 2015 года. Відавочна, патрэбныя нейрасеці па аналізе артыкулаў.
- Набіраюць папулярнасць наступныя тэхналогіі:
- PyTorch папулярнасць расце імкліва і, падобна, абганяе TensorFlow.
- Аўтаматычны падбор гіперпараметраў AutoML - папулярнасць расце плаўна.
- Паступовае памяншэнне дакладнасці і павелічэнне хуткасці вылічэнняў: , алгарытмы , Недакладныя (набліжаныя) вылічэнні, квантызацыя (калі вагі нейросетки перакладаюцца ў цэлыя лікі і квантуюцца), нейроакселераторы.
- пераклад и .
- стварэнне , зараз ужо ў рэальным часе.
- Асноўнае ў DL - гэта шмат дадзеных, але сабраць і размеціць іх няпроста. Таму развіваецца аўтаматызацыя разметкі () для нейросетей з дапамогай нейросетей.
- З нейрасецямі Computer Science раптам стала эксперыментальнай навукай і ўзнік .
- ІТ-грошы і папулярнасць нейрасетак паўсталі адначасова, калі вылічэнні сталі рынкавай каштоўнасцю. Эканоміка з золатавалютнай становіцца золата-валютна-вылічальнай. Глядзіце мой артыкул па і прычыны з'яўлення IT-грошай.
Паступова з'яўляецца новая (Machine Learning & Deep Learning), якая заснавана на прадстаўленні праграмы, як сукупнасці навучаных нейросетевых мадэляў.
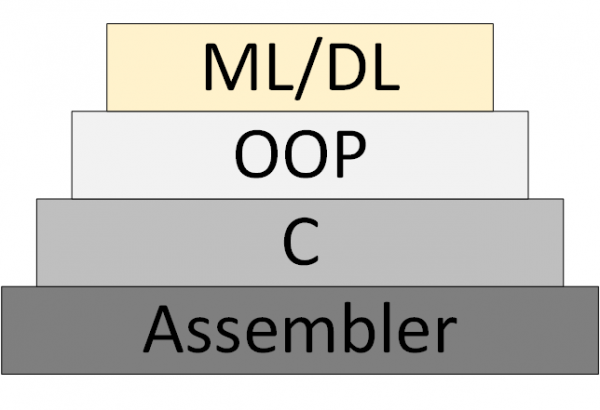
Малюнак 3 - ML/DL як новая метадалогія праграмавання
Аднак так і не зьявілася "тэорыі нейрасетак", у рамках якой можна думаць і працаваць сістэмна. Што зараз называецца «тэорыяй» насамрэч эксперыментальныя, эўрыстычныя алгарытмы.
Спасылкі на мае і не толькі рэсурсы:
- Рассылка навін па Data Science. У асноўным, па апрацоўцы відарысаў. Хто хоча атрымліваць, няхай дасылае e-mail (foobar167<гаф-гаф>gmail<кропка>com). Спасылкі на артыкулы і відэа рассылаю па меры назапашвання матэрыялу.
- Агульны , якія прайшоў і якія хацеў бы прайсці.
- , З якіх варта пачынаць вывучаць нейросетки. .
- , дзе кожны знойдзе нешта цікавае для сябе.
- Вельмі карыснымі аказаліся відэаканалы па разборы навуковых артыкулаў па Data Science. Знаходзьце, падпісвайцеся на іх і перадавайце спасылкі сваім калегам і мне таксама. Прыклады:
- браценік з пакрокавымі інструкцыямі і адкрытым зыходным кодам.
Дзякуй за ўвагу!
Крыніца: habr.com
